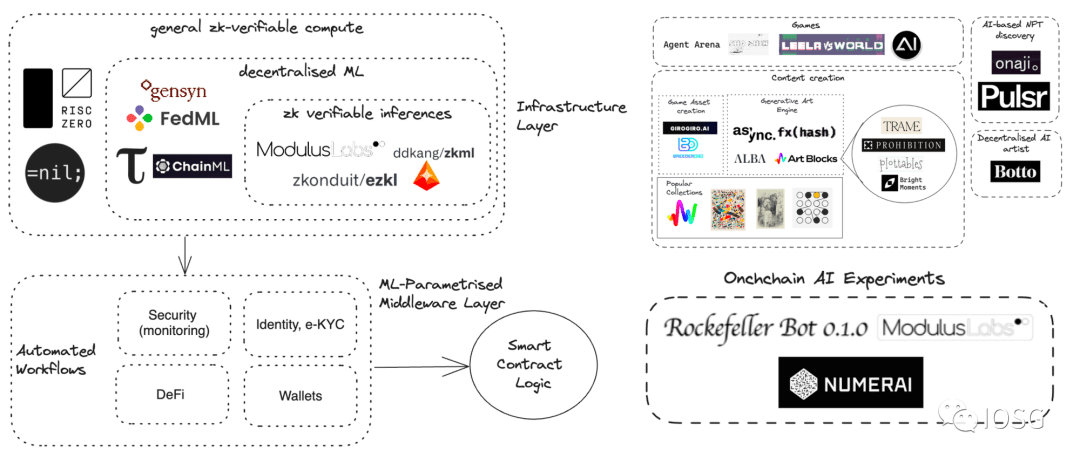

Tác giả: Yiping, IOSG Ventures
viết ở phía trước
Khi các mô hình ngôn ngữ lớn (LLM) ngày càng trở nên phổ biến, chúng ta thấy nhiều dự án tích hợp trí tuệ nhân tạo (AI) và blockchain. Sự kết hợp giữa LLM và blockchain ngày càng tăng và chúng tôi cũng nhìn thấy cơ hội để trí tuệ nhân tạo tái tích hợp với blockchain. Một điều đáng nói là máy học không kiến thức (ZKML).
Trí tuệ nhân tạo và blockchain là hai công nghệ biến đổi với những đặc điểm cơ bản khác nhau. Trí tuệ nhân tạo đòi hỏi sức mạnh tính toán mạnh mẽ, thường được cung cấp bởi các trung tâm dữ liệu tập trung. Mặc dù blockchain cung cấp khả năng tính toán phi tập trung và bảo vệ quyền riêng tư nhưng nó hoạt động kém đối với các tác vụ yêu cầu tính toán và lưu trữ quy mô lớn. Chúng tôi vẫn đang khám phá và nghiên cứu các phương pháp hay nhất để tích hợp trí tuệ nhân tạo và blockchain và cũng sẽ giới thiệu với các bạn một số trường hợp dự án hiện tại kết hợp "AI + blockchain" trong tương lai.
Nguồn: IOSG Ventures
Báo cáo nghiên cứu này được xuất bản thành hai phần. Bài viết này là phần trên. Chúng tôi sẽ tập trung vào ứng dụng LLM trong lĩnh vực mã hóa và khám phá các chiến lược triển khai ứng dụng.
LLM là gì?
LLM (Mô hình ngôn ngữ lớn) là mô hình ngôn ngữ được vi tính hóa bao gồm mạng lưới thần kinh nhân tạo với số lượng lớn tham số (thường là hàng tỷ). Những mô hình này được đào tạo trên một lượng lớn văn bản không được gắn nhãn.
Khoảng năm 2018, sự ra đời của LLM đã làm thay đổi hoàn toàn việc nghiên cứu về xử lý ngôn ngữ tự nhiên. Không giống như các phương pháp trước đây yêu cầu đào tạo một mô hình được giám sát cụ thể cho một nhiệm vụ cụ thể, LLM, với tư cách là một mô hình chung, thực hiện tốt nhiều nhiệm vụ khác nhau. Khả năng và ứng dụng của nó bao gồm:
Hiểu và tóm tắt văn bản: LLM có thể hiểu và tóm tắt một lượng lớn ngôn ngữ và dữ liệu văn bản của con người. Họ có thể trích xuất thông tin quan trọng và tạo ra các bản tóm tắt ngắn gọn.
Tạo nội dung mới: LLM có khả năng tạo nội dung dựa trên văn bản. Bằng cách cung cấp lời nhắc cho mô hình, mô hình có thể trả lời các câu hỏi, văn bản mới được tạo, bản tóm tắt hoặc phân tích cảm tính.
Dịch thuật: LLM có thể được sử dụng để dịch giữa các ngôn ngữ khác nhau. Họ sử dụng các thuật toán học sâu và mạng lưới thần kinh để hiểu ngữ cảnh và mối quan hệ giữa các từ.
Dự đoán và tạo văn bản: LLM có thể dự đoán và tạo văn bản dựa trên nền tảng ngữ cảnh, tương tự như nội dung do con người tạo ra, bao gồm các bài hát, bài thơ, câu chuyện, tài liệu tiếp thị, v.v.
Ứng dụng trong nhiều lĩnh vực: Mô hình ngôn ngữ lớn có khả năng ứng dụng rộng rãi trong các tác vụ xử lý ngôn ngữ tự nhiên. Chúng được sử dụng trong AI đàm thoại, chatbot, chăm sóc sức khỏe, phát triển phần mềm, công cụ tìm kiếm, dạy kèm, công cụ viết, v.v.
Ưu điểm của LLM bao gồm khả năng hiểu lượng lớn dữ liệu, khả năng thực hiện nhiều tác vụ liên quan đến ngôn ngữ và khả năng điều chỉnh kết quả theo nhu cầu của người dùng.
Các ứng dụng mô hình ngôn ngữ quy mô lớn phổ biến
Do khả năng hiểu ngôn ngữ tự nhiên vượt trội, LLM có tiềm năng đáng kể và các nhà phát triển chủ yếu tập trung vào hai khía cạnh sau:
Cung cấp cho người dùng câu trả lời chính xác và cập nhật dựa trên dữ liệu và nội dung theo ngữ cảnh mở rộng
Hoàn thành các nhiệm vụ cụ thể do người dùng giao bằng cách sử dụng các tác nhân và công cụ khác nhau
Chính hai khía cạnh này đã dẫn đến sự mọc lên như nấm của các ứng dụng LLM để trò chuyện với XX. Ví dụ: trò chuyện với tệp PDF, trò chuyện với tài liệu và trò chuyện với các bài báo học thuật.
Sau đó, người ta đã nỗ lực kết hợp LLM với nhiều nguồn dữ liệu khác nhau. Các nhà phát triển đã tích hợp thành công các nền tảng như Github, Notion và một số phần mềm ghi chú với LLM.
Để khắc phục những hạn chế cố hữu của LLM, các công cụ khác nhau được tích hợp vào hệ thống. Công cụ đầu tiên như vậy là công cụ tìm kiếm, cung cấp cho LLM khả năng truy cập kiến thức mới nhất. Tiến bộ hơn nữa sẽ tích hợp các công cụ như WolframAlpha, Google Suites và Etherscan với các mô hình ngôn ngữ lớn.
Kiến trúc của ứng dụng LLM
Hình bên dưới phác thảo luồng ứng dụng LLM trong việc phản hồi các truy vấn của người dùng: Đầu tiên, các nguồn dữ liệu có liên quan được chuyển đổi thành các vectơ nhúng và được lưu trữ trong cơ sở dữ liệu vectơ. Bộ điều hợp LLM sử dụng truy vấn của người dùng và tìm kiếm tương tự để tìm ngữ cảnh có liên quan từ cơ sở dữ liệu vectơ. Ngữ cảnh liên quan được đưa vào Lời nhắc và gửi tới LLM. LLM sẽ thực hiện những lời nhắc này và sử dụng các công cụ để tạo câu trả lời. Đôi khi, LLM được điều chỉnh trên các bộ dữ liệu cụ thể để cải thiện độ chính xác và giảm chi phí.
Quy trình làm việc của một ứng dụng LLM có thể được chia thành ba giai đoạn chính:
Chuẩn bị và nhúng dữ liệu: Giai đoạn này liên quan đến việc lưu giữ thông tin bí mật (chẳng hạn như bản ghi nhớ dự án) để truy cập trong tương lai. Thông thường, các tệp được phân đoạn, xử lý thông qua các mô hình nhúng và được lưu trữ trong một loại cơ sở dữ liệu đặc biệt gọi là cơ sở dữ liệu vectơ.
Xây dựng và trích xuất lời nhắc: Khi người dùng gửi yêu cầu tìm kiếm (trong trường hợp này là tìm kiếm thông tin dự án), phần mềm sẽ tạo một loạt Lời nhắc và nhập chúng vào mô hình ngôn ngữ. Lời nhắc cuối cùng thường chứa mẫu lời nhắc được nhà phát triển phần mềm mã hóa cứng, một ví dụ đầu ra hợp lệ dưới dạng ví dụ về một vài lần chụp và mọi số bắt buộc thu được từ API bên ngoài và các tệp liên quan được trích xuất từ cơ sở dữ liệu vectơ.
Thực thi và suy luận các lời nhắc: Sau khi các lời nhắc được hoàn thành, chúng sẽ được đưa đến mô hình ngôn ngữ có sẵn để suy luận, có thể bao gồm các API mô hình độc quyền, nguồn mở hoặc các mô hình được tinh chỉnh riêng lẻ. Ở giai đoạn này, một số nhà phát triển cũng có thể tích hợp hệ điều hành (chẳng hạn như ghi nhật ký, bộ nhớ đệm và xác thực) vào hệ thống.
Đưa LLM vào mật mã
Mặc dù lĩnh vực mã hóa (Web3) có một số ứng dụng tương tự như Web2, nhưng việc phát triển các ứng dụng LLM tốt trong lĩnh vực mã hóa đòi hỏi sự thận trọng đặc biệt.
Hệ sinh thái tiền điện tử là duy nhất, có văn hóa, dữ liệu và sự hội tụ riêng. LLM được tinh chỉnh trên các bộ dữ liệu bị hạn chế về mặt mật mã này có thể mang lại kết quả vượt trội với chi phí tương đối thấp. Mặc dù dữ liệu có sẵn rất nhiều nhưng lại thiếu rõ rệt các bộ dữ liệu mở trên các nền tảng như HuggingFace. Hiện tại, chỉ có một bộ dữ liệu liên quan đến hợp đồng thông minh chứa 113.000 hợp đồng thông minh.
Các nhà phát triển cũng phải đối mặt với thách thức tích hợp các công cụ khác nhau vào LLM. Những công cụ này khác với những công cụ được sử dụng trong Web2 và cung cấp cho LLM khả năng truy cập dữ liệu liên quan đến giao dịch, tương tác với các ứng dụng phi tập trung (Dapps) và thực hiện giao dịch. Cho đến nay, chúng tôi chưa tìm thấy bất kỳ sự tích hợp Dapps nào trong Langchain.
Mặc dù việc phát triển các ứng dụng LLM mật mã chất lượng cao có thể cần đầu tư bổ sung nhưng LLM hoàn toàn phù hợp với thế giới mật mã. Miền này cung cấp dữ liệu phong phú, rõ ràng và có cấu trúc. Cùng với thực tế là mã Solidity nhìn chung ngắn gọn và rõ ràng, điều này giúp LLM tạo mã chức năng dễ dàng hơn.
Trong "Phần 2", chúng ta sẽ thảo luận về 8 hướng tiềm năng trong đó LLM có thể hỗ trợ lĩnh vực blockchain, chẳng hạn như:
Tích hợp các khả năng AI/LLM tích hợp vào blockchain
Phân tích hồ sơ giao dịch bằng LLM
Xác định các bot tiềm năng bằng LLM
Viết mã bằng LLM
Đọc mã bằng LLM
Giúp đỡ cộng đồng với LLM
Theo dõi thị trường với LLM
Phân tích dự án bằng LLM