
Tác giả gốc: Ye Zhang
Nguồn gốc: Cuộn CN
Trình biên dịch: F.F
Trong khóa học ZKP Mooc mới nhất, Zhang Ye, người đồng sáng lập Scroll, đã có bài phát biểu về thiết kế, tối ưu hóa và ứng dụng zkEVM. Scroll đang xây dựng Ethereum tương đương với ZK-Rollup, tương thích ở cấp mã byte và hỗ trợ trực tiếp tất cả các công cụ hiện có.
Sau đây là phiên bản được chép lại của video
Bài phát biểu được chia thành bốn phần. Trong phần đầu tiên, Zhang Ye đã giới thiệu bối cảnh phát triển và lý do tại sao chúng ta cần zkEVM ngay từ đầu cũng như lý do tại sao nó lại trở nên phổ biến trong hai năm qua. Phần thứ hai được giải thích thông qua một quy trình hoàn chỉnh. Để xây dựng zkEVM từ đầu bao gồm hệ thống số học hóa và chứng minh, phần thứ ba nói về những vấn đề Scroll gặp phải khi xây dựng zkEVM thông qua một số câu hỏi nghiên cứu thú vị và cuối cùng giới thiệu một số ứng dụng khác sử dụng zkEVM.


Bối cảnh và động lực

Chuỗi khối lớp 1 truyền thống sẽ có một số nút được duy trì cùng nhau thông qua mạng P2P. Khi nhận được giao dịch của người dùng, họ sẽ thực thi nó trong máy ảo EVM, đọc hợp đồng gọi và bộ lưu trữ, đồng thời cập nhật cây trạng thái toàn cầu theo giao dịch.
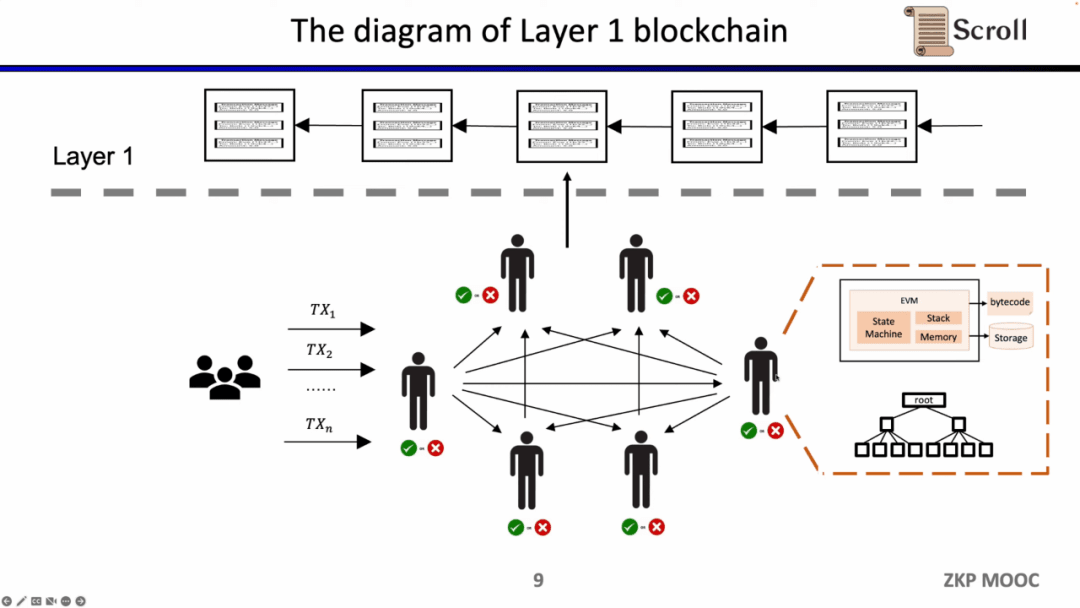
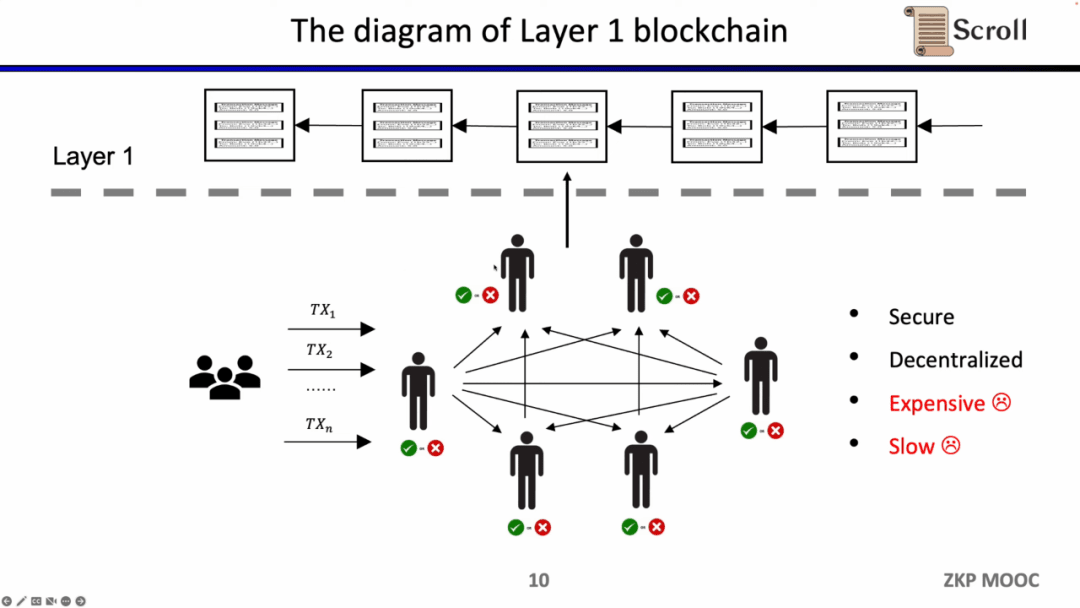
Ưu điểm của kiến trúc như vậy là phân cấp và bảo mật. Nhược điểm là phí giao dịch trên L1 đắt và xác nhận giao dịch chậm.
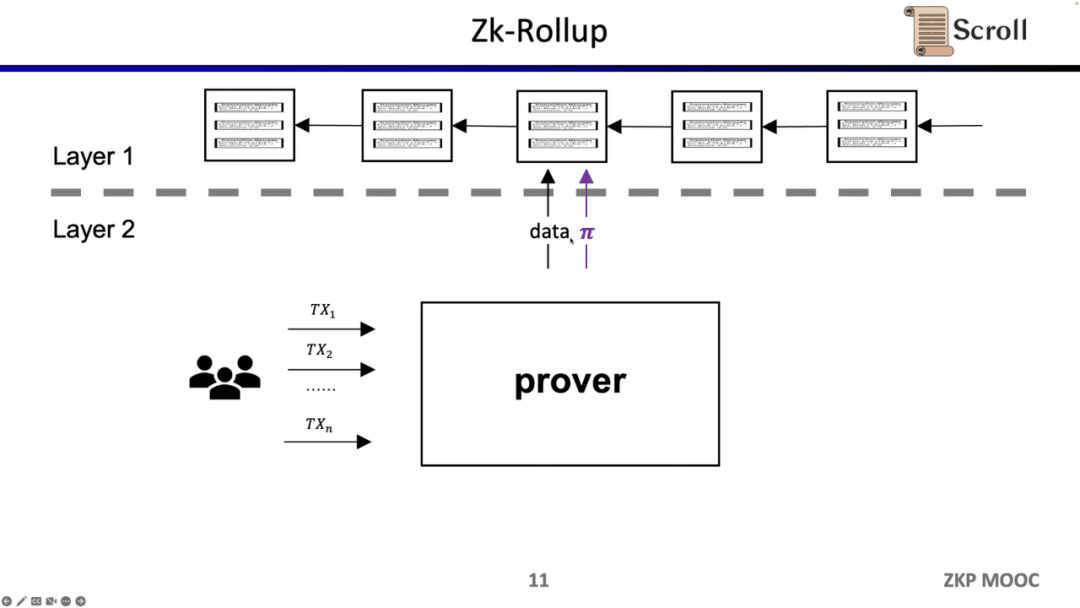
Trong kiến trúc ZK-Rollup, mạng L2 chỉ cần tải dữ liệu và bằng chứng lên để xác minh tính chính xác của dữ liệu lên L1, trong đó bằng chứng được tính toán thông qua mạch chứng minh không có kiến thức.
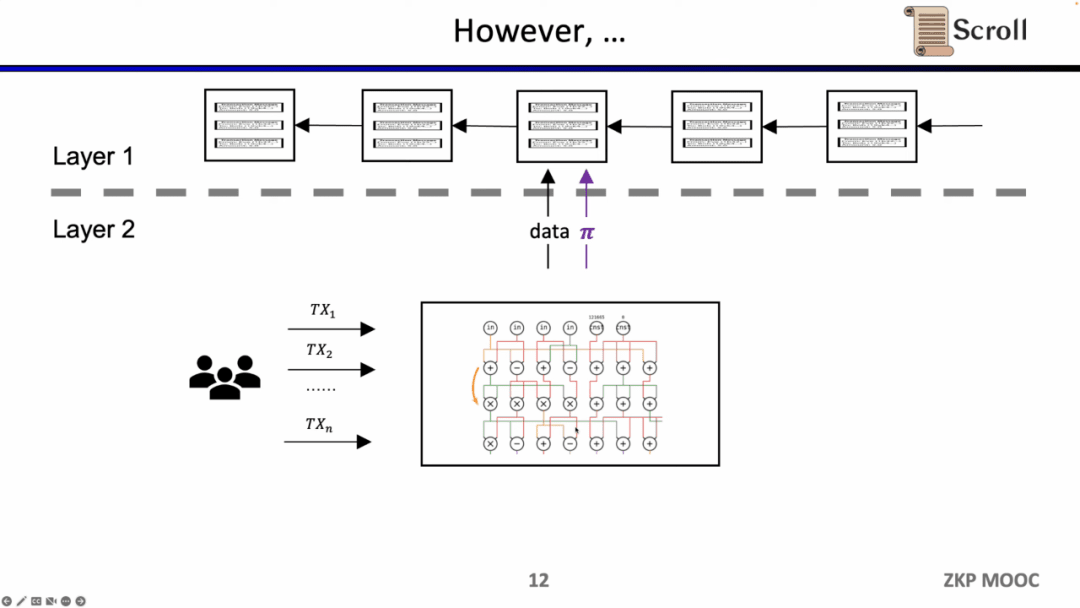
Trong ZK-Rollup ban đầu, mạch được thiết kế cho các ứng dụng cụ thể. Người dùng cần gửi giao dịch đến các bộ chứng minh khác nhau, sau đó ZK-Rollups của các ứng dụng khác nhau sẽ gửi dữ liệu và bằng chứng của riêng họ tới L1. Vấn đề mà điều này mang lại là khả năng kết hợp của hợp đồng L1 ban đầu bị mất.
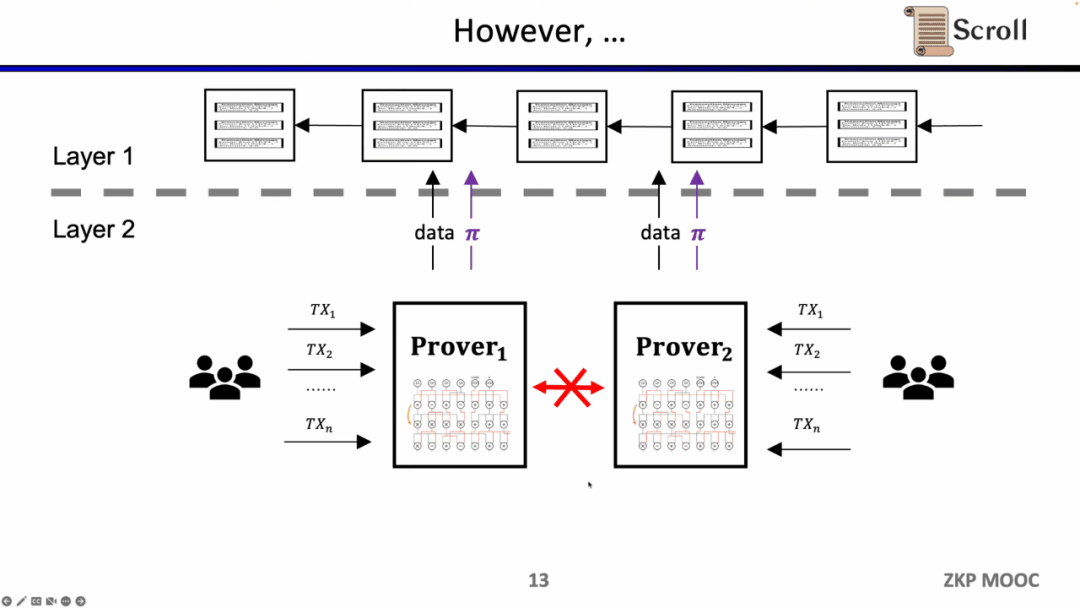
Những gì Scroll làm là một giải pháp zkEVM gốc, là một ZK-Rollup có mục đích chung. Điều này không chỉ thân thiện với người dùng hơn mà còn cung cấp cho các nhà phát triển trải nghiệm phát triển tốt hơn trên L1. Tất nhiên, việc phát triển đằng sau điều này là rất khó khăn và chi phí cho việc tạo ra bằng chứng hiện tại cũng rất cao.
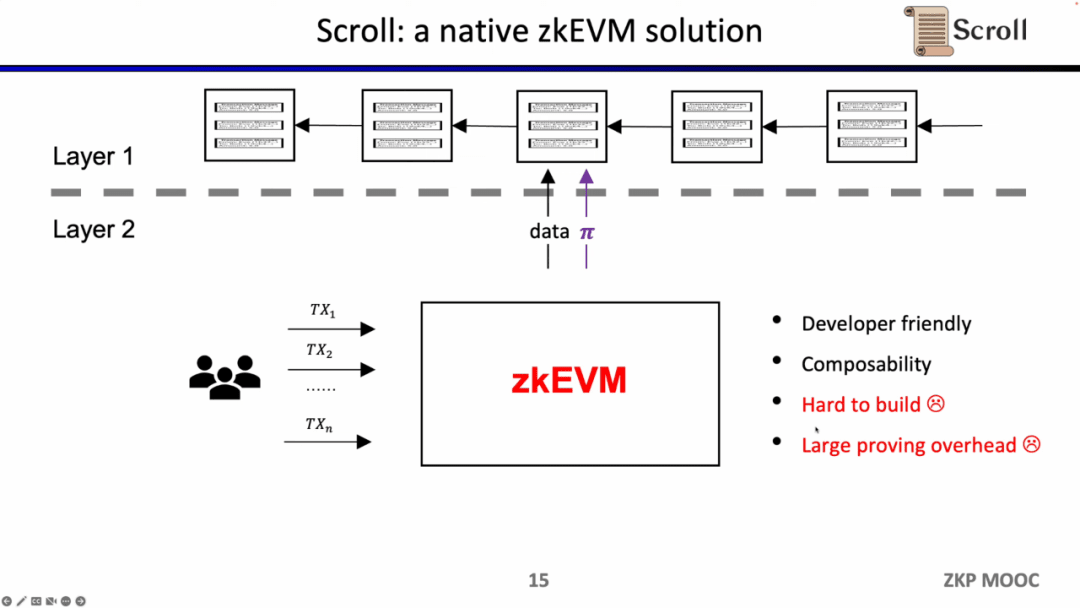
May mắn thay, hiệu quả của việc chứng minh không có kiến thức đã được cải thiện đáng kể trong hai năm qua, đó là lý do tại sao zkEVM đã trở nên phổ biến trong hai năm qua. Có ít nhất bốn lý do khiến nó trở nên khả thi. Đầu tiên là sự xuất hiện của cam kết đa thức Theo hệ thống chứng minh Groth16 ban đầu, quy mô của các ràng buộc rất lớn, nhưng cam kết đa thức có thể hỗ trợ các ràng buộc bậc cao hơn và giảm quy mô của. bằng chứng thứ hai, Sự xuất hiện của bảng tra cứu và cổng tùy chỉnh có thể hỗ trợ các thiết kế linh hoạt hơn và giúp việc chứng minh hiệu quả hơn; thứ ba là những đột phá trong khả năng tăng tốc phần cứng, có thể rút ngắn thời gian chứng minh xuống 1-2 bậc độ lớn thông qua GPU, FPGA và ASIC. . Thứ tư Theo bằng chứng đệ quy, nhiều bằng chứng có thể được nén thành một bằng chứng, làm cho bằng chứng nhỏ hơn và dễ xác minh hơn. Vì vậy, kết hợp bốn yếu tố này, hiệu suất tạo ra các bằng chứng không có kiến thức cao hơn ba bậc so với hai năm trước, đây cũng là nguồn gốc của Scoll.
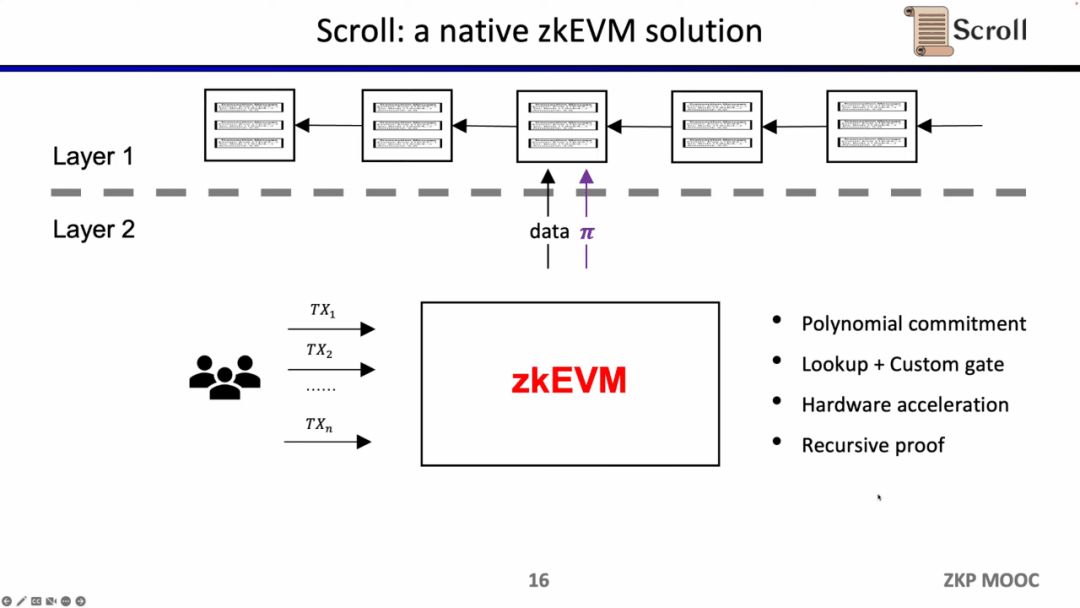
Theo định nghĩa của Justin Drake, zkEVM có thể được chia thành ba loại. Loại thứ nhất là khả năng tương thích ở cấp độ ngôn ngữ. Nguyên nhân chính là EVM không được thiết kế cho ZK và có nhiều opcode không thân thiện với ZK nên sẽ gây ra sự cố. rất nhiều chi phí bổ sung. Do đó, các công ty như Starkware và zkSync chọn biên dịch Solidity hoặc Yul thành các trình biên dịch thân thiện với ZK ở cấp độ ngôn ngữ.
Loại thứ hai là khả năng tương thích cấp độ bytecode mà Scroll đang thực hiện, điều này trực tiếp chứng minh liệu quá trình xử lý bytecode của EVM có chính xác hay không và kế thừa trực tiếp môi trường thực thi của Ethereum. Một số sự cân bằng có thể được thực hiện ở đây là sử dụng gốc trạng thái khác với EVM, chẳng hạn như sử dụng cấu trúc dữ liệu thân thiện với ZK. Hermez và Consensys cũng đang làm điều tương tự.
Loại thứ ba là khả năng tương thích ở mức độ đồng thuận. Sự đánh đổi ở đây là không chỉ cần giữ EVM không thay đổi mà còn bao gồm cấu trúc lưu trữ để đạt được khả năng tương thích hoàn toàn với Ethereum, nhưng phải trả giá bằng thời gian chứng minh lâu hơn. Scroll đang được xây dựng với sự hợp tác của nhóm PSE của Ethereum Foundation để hiện thực hóa ZKization của Ethereum.

Xây dựng zkEVM từ 0 đến 1

Ở phần thứ hai, Zhang Ye đã hướng dẫn mọi người cách xây dựng ZKVM từ đầu.
Quá trình hoàn tất
Trước hết, trong phần giao diện người dùng của ZKP, bạn cần thể hiện các phép tính của mình thông qua số học toán học. Những phép tính được sử dụng phổ biến nhất là R1CS tuyến tính, cũng như Plonkish và AIR. Sau khi có được các ràng buộc thông qua số học, bạn cần chạy thuật toán chứng minh trên phần phụ trợ của ZKP để chứng minh tính đúng đắn của phép tính. Dưới đây là các bằng chứng oracle tương tác đa thức được sử dụng phổ biến nhất (IOP đa thức) và sơ đồ cam kết đa thức (PCS).
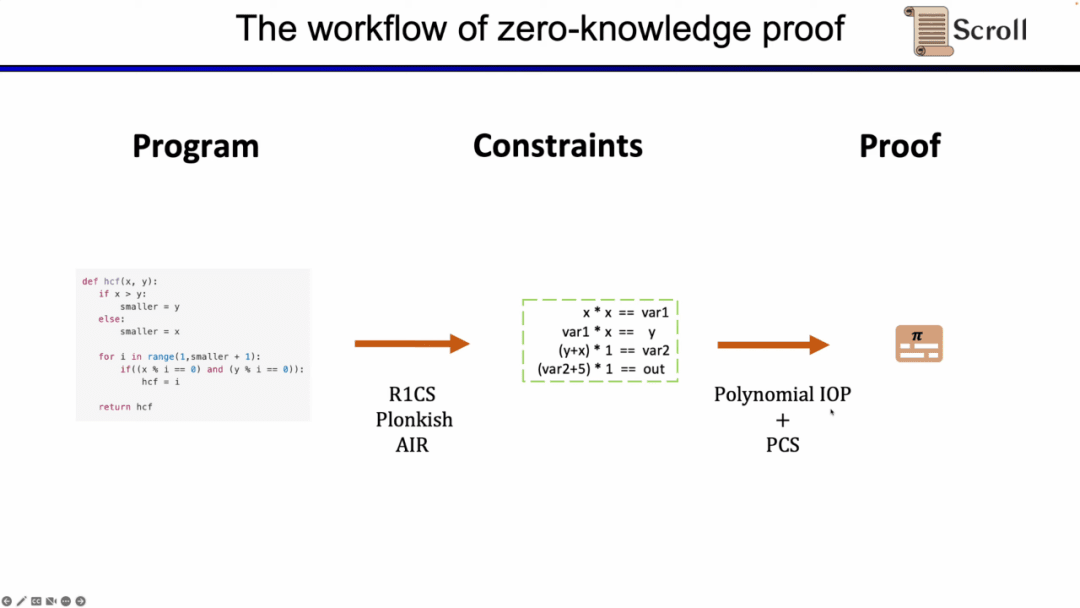
Ở đây chúng ta cần chứng minh rằng zkEVM và Scroll sử dụng kết hợp Plonkish, Plonk IOP và KZG.
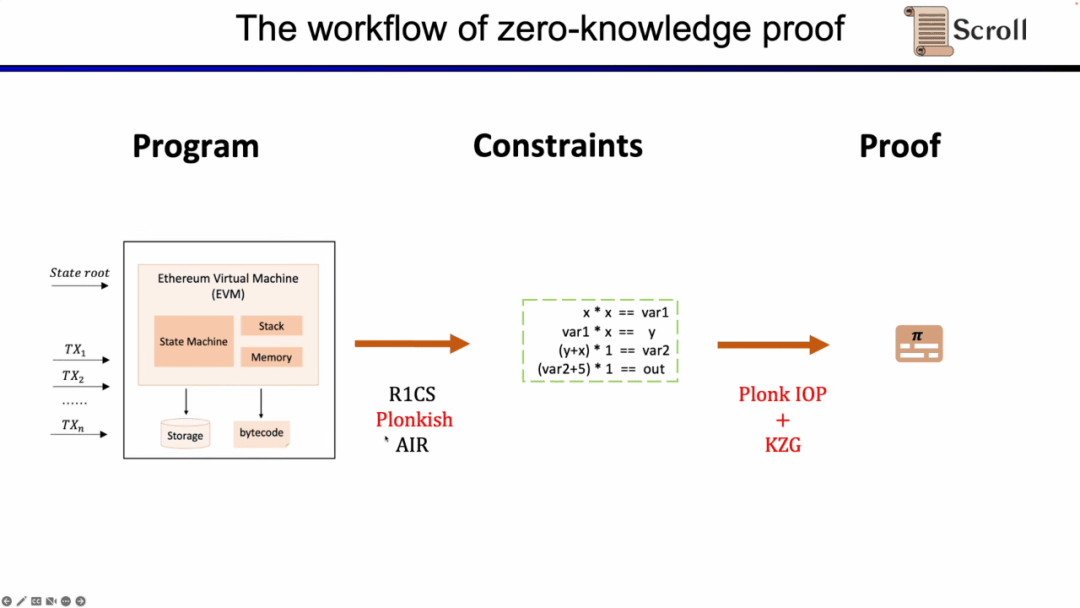
Để hiểu lý do tại sao chúng tôi sử dụng ba giải pháp này. Đầu tiên chúng ta bắt đầu với R1CS đơn giản nhất. Ràng buộc trong R1CS là tổ hợp tuyến tính nhân với tổ hợp tuyến tính bằng tổ hợp tuyến tính. Bạn có thể thêm bất kỳ tổ hợp biến tuyến tính nào mà không cần thêm chi phí, nhưng thứ tự tối đa trong mỗi ràng buộc là 2. Do đó, đối với các hoạt động bậc cao hơn, cần có nhiều ràng buộc hơn.

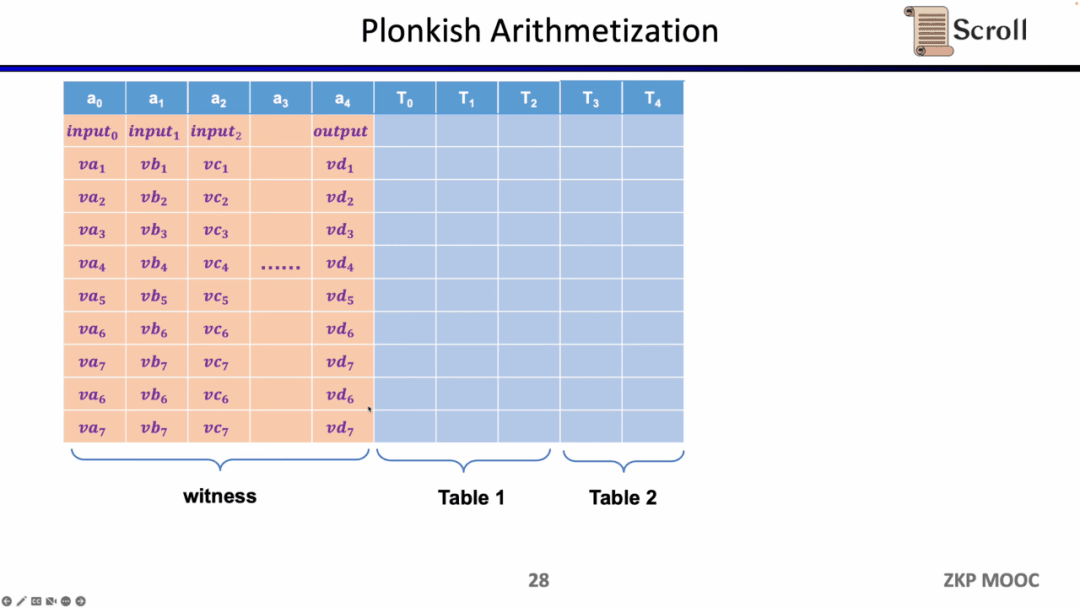
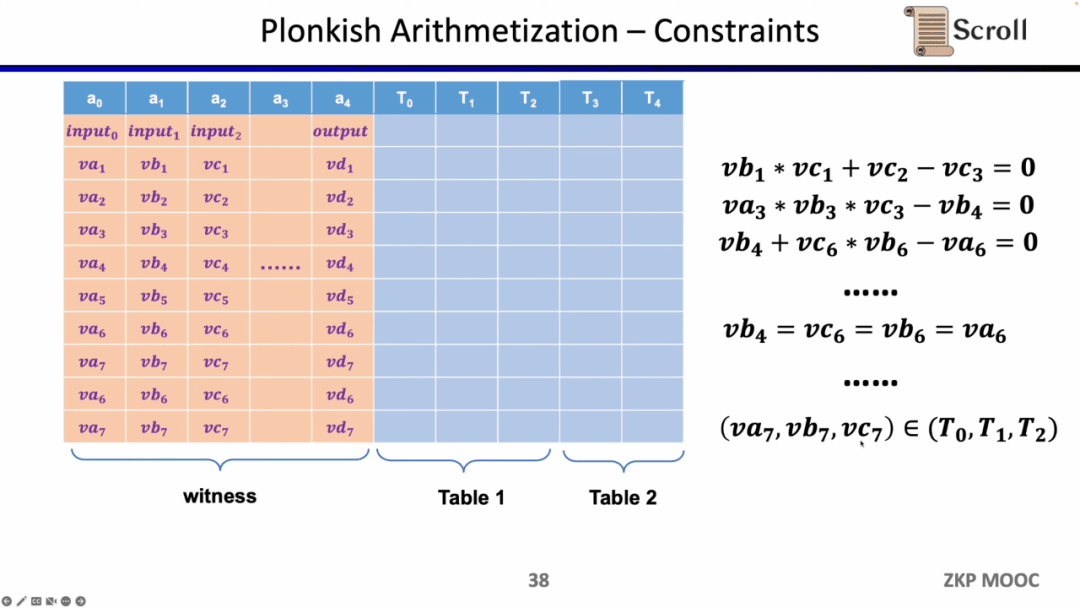
Trong Plonkish, bạn cần điền tất cả các biến vào bảng, bao gồm đầu vào, đầu ra và nhân chứng cho các biến trung gian. Trên hết, bạn có thể xác định các ràng buộc khác nhau. Có ba loại ràng buộc có sẵn trong Plonkish.
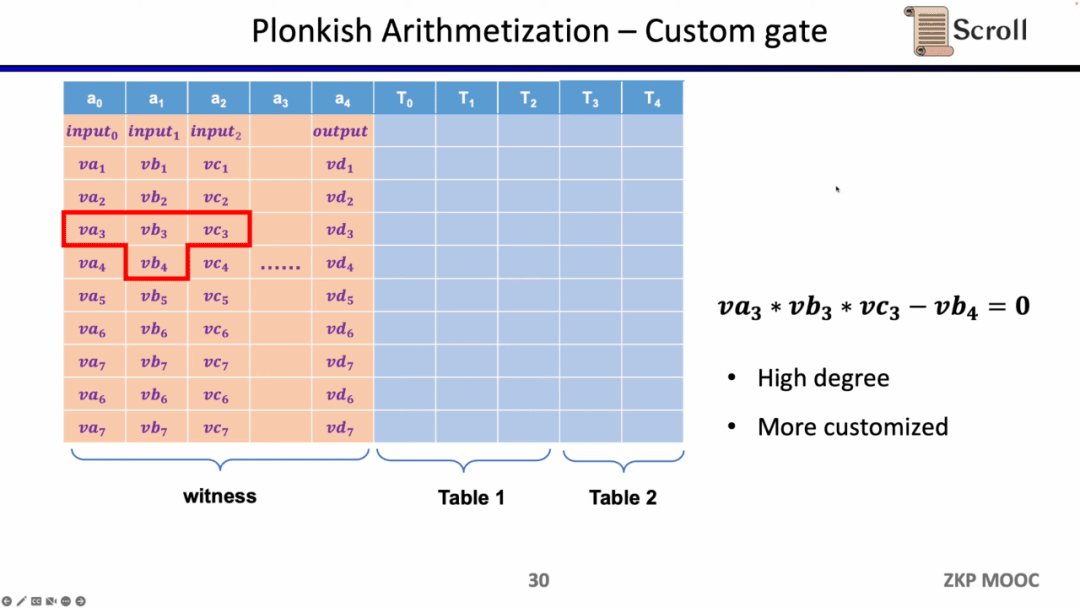
Loại ràng buộc đầu tiên là cổng tùy chỉnh. Bạn có thể xác định mối quan hệ ràng buộc đa thức giữa các ô khác nhau, chẳng hạn như va3 * vb3 * vc3 - vb4 =0. So với R1CS, thứ tự có thể cao hơn vì bạn có thể xác định các ràng buộc trên bất kỳ biến nào và bạn có thể xác định một số ràng buộc rất khác nhau.
Loại ràng buộc thứ hai là Hoán vị hoặc kiểm tra tính bằng nhau. Nó có thể được sử dụng để kiểm tra sự tương đương của các ô khác nhau và thường được sử dụng để liên kết các cổng khác nhau trong một mạch, chẳng hạn như chứng minh rằng đầu ra của cổng trước bằng đầu vào của cổng tiếp theo.

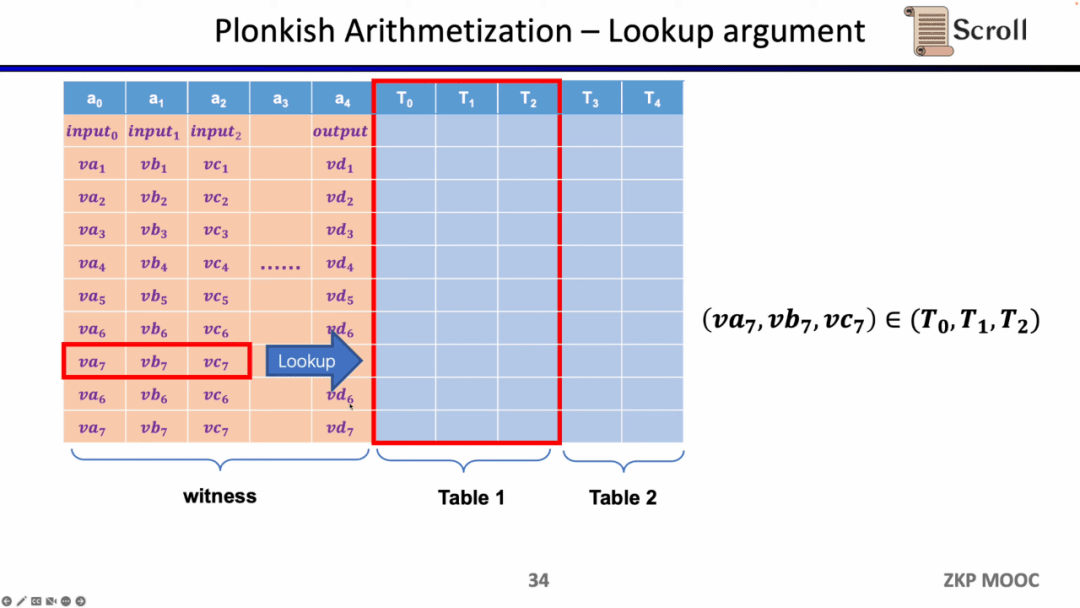
Loại ràng buộc cuối cùng là bảng tra cứu. Chúng ta có thể hiểu bảng tra cứu là mối quan hệ giữa các biến, có thể biểu diễn dưới dạng bảng. Ví dụ: chúng tôi muốn chứng minh rằng vc7 nằm trong phạm vi 0-15. Trong R1CS, trước tiên bạn cần phân tách giá trị này thành nhị phân 4 bit, sau đó chứng minh rằng mỗi bit nằm trong phạm vi 0-1, tức là sẽ yêu cầu bốn ràng buộc. Trong Plonkish, bạn có thể liệt kê tất cả các phạm vi có thể có trong cùng một cột và chỉ cần chứng minh rằng vc7 thuộc cột đó. Điều này rất hiệu quả đối với việc chứng minh phạm vi. Trong zkEVM, các bảng tra cứu rất hữu ích để chứng minh việc đọc và ghi bộ nhớ.
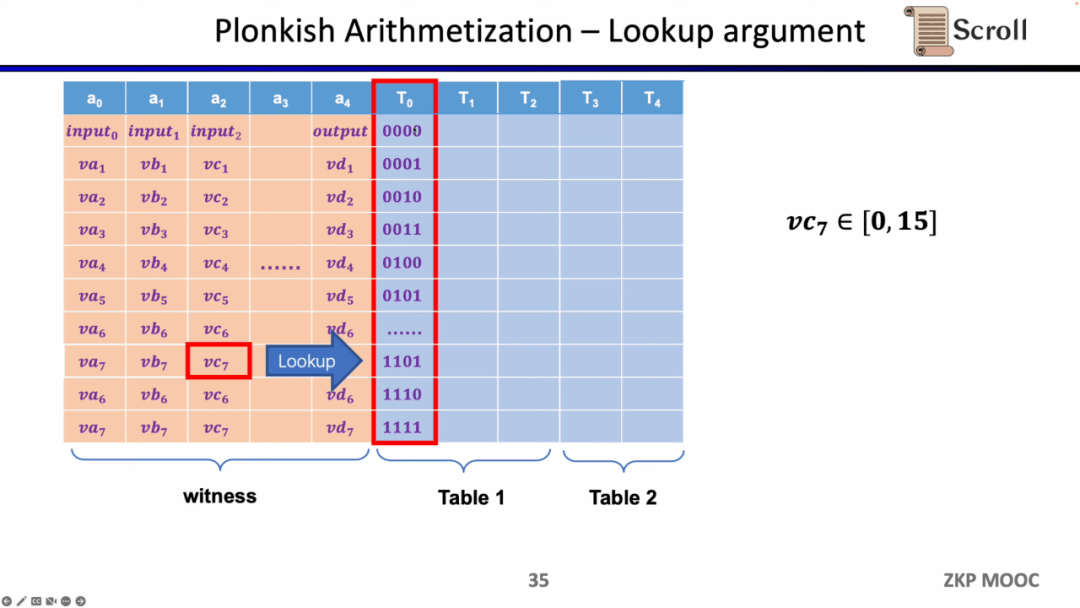
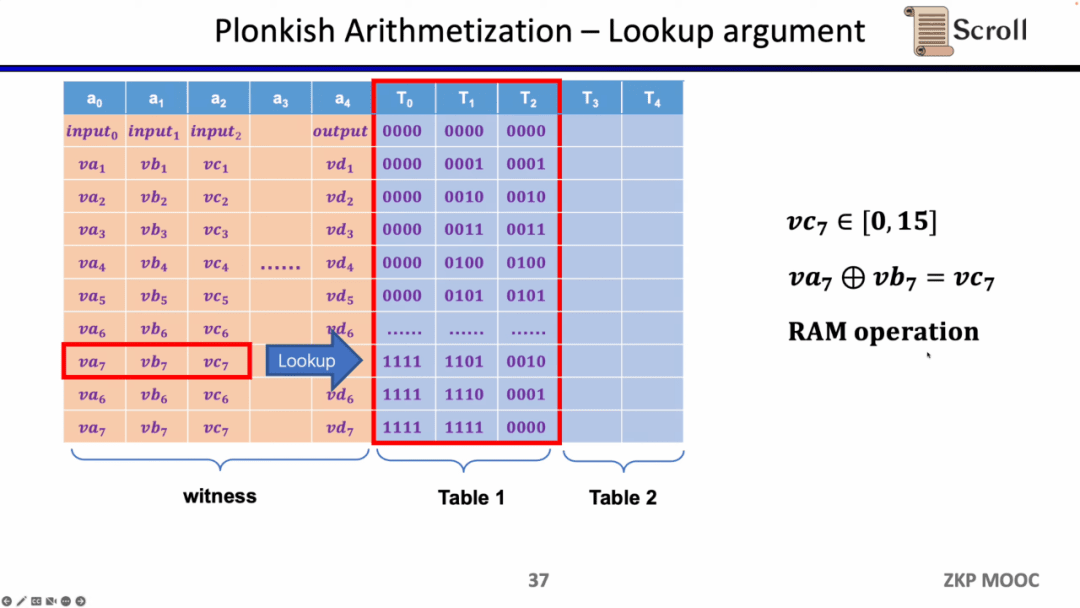
Tóm lại, Plonkish cũng hỗ trợ các cổng tùy chỉnh, kiểm tra tương đương và bảng tra cứu, có thể rất linh hoạt để đáp ứng các nhu cầu mạch khác nhau. Một so sánh đơn giản về STARK. Mỗi hàng trong STARK là một ràng buộc cần thể hiện sự chuyển đổi trạng thái giữa các hàng, nhưng tính linh hoạt của các ràng buộc tùy chỉnh trong Plonkish rõ ràng là cao hơn.
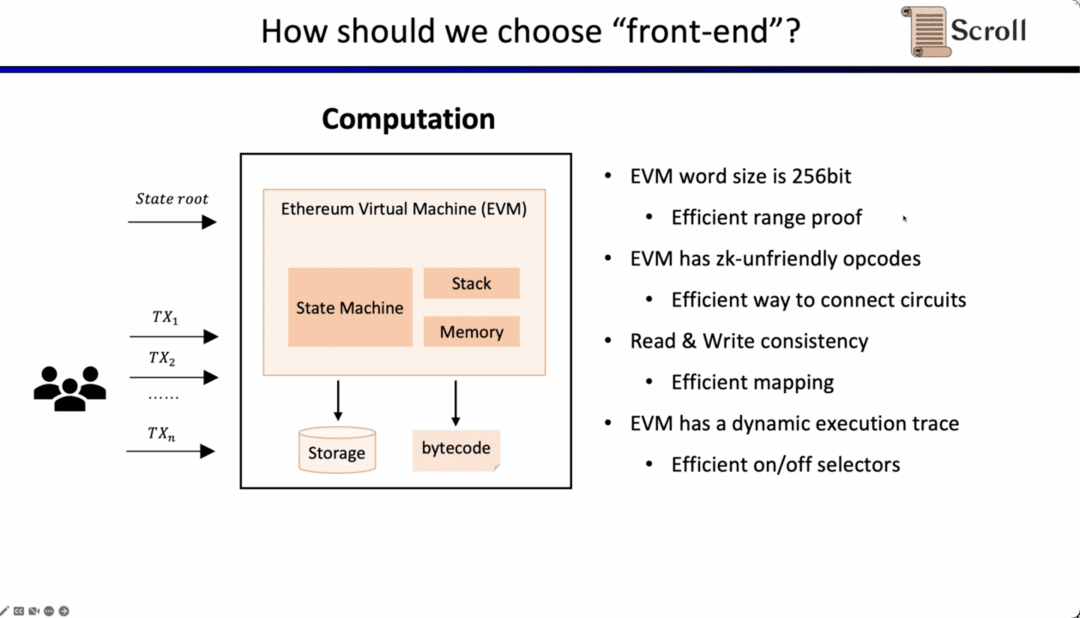
Câu hỏi bây giờ là làm thế nào chúng ta chọn giao diện người dùng trong zkEVM. Có bốn thách thức chính đối với zkEVM. Thách thức đầu tiên là trường EVM là 256 bit, có nghĩa là các biến cần được giới hạn phạm vi một cách hiệu quả; thách thức thứ hai là EVM có nhiều mã hoạt động không thân thiện với ZK, do đó cần có các ràng buộc quy mô rất lớn để chứng minh các hoạt động này. ., chẳng hạn như Keccak-256; thử thách thứ ba là vấn đề đọc và ghi bộ nhớ, bạn cần một số ánh xạ hiệu quả để chứng minh rằng những gì bạn đọc phù hợp với những gì bạn đã viết trước đó; đang thay đổi linh hoạt, vì vậy chúng tôi cần các cổng tùy chỉnh để thích ứng với các dấu vết thực thi khác nhau. Chúng tôi đã chọn Plonkish vì những cân nhắc trên.
Tiếp theo, chúng ta hãy xem toàn bộ quy trình của zkEVM. Dựa trên cây trạng thái toàn cầu ban đầu, sau khi có một giao dịch mới, EVM sẽ đọc mã byte của các hợp đồng được lưu trữ và được gọi, đồng thời tạo ra các dấu vết thực thi tương ứng dựa trên giao dịch, chẳng hạn như PUSH, PUSH, STORE, CALLVALUE, sau đó cập nhật dần dần trạng thái toàn cầu để lấy cây trạng thái toàn cầu sau giao dịch. zkEVM lấy cây trạng thái toàn cầu ban đầu, chính giao dịch và cây trạng thái toàn cầu sau giao dịch làm đầu vào và sử dụng đặc tả EVM để chứng minh tính chính xác của dấu vết thực thi.
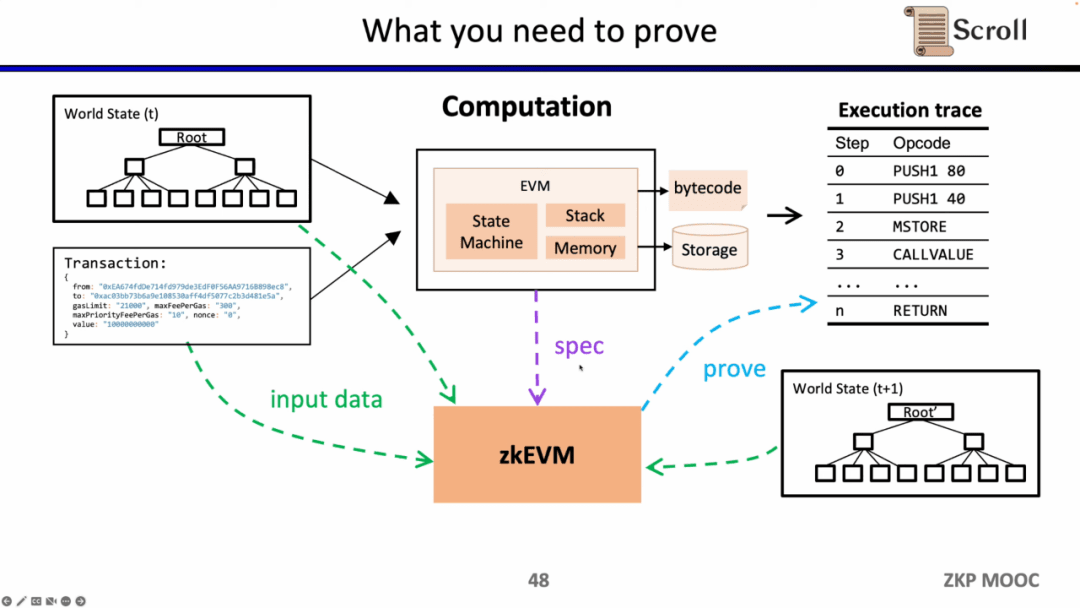
Đi sâu vào chi tiết của mạch EVM, mỗi bước của quá trình thực hiện đều có các ràng buộc mạch tương ứng. Cụ thể, các ràng buộc mạch của từng bước bao gồm Bối cảnh bước, Chuyển đổi trường hợp và Nhân chứng cụ thể về mã hóa. Bối cảnh bước chứa codehash, gas còn lại và bộ đếm tương ứng với dấu vết thực thi; Chuyển đổi trường hợp chứa tất cả các opcode, tất cả các điều kiện lỗi và các hoạt động tương ứng của bước; Nhân chứng cụ thể của Opcode chứa các nhân chứng bổ sung được yêu cầu bởi opcode, chẳng hạn như toán hạng chờ.
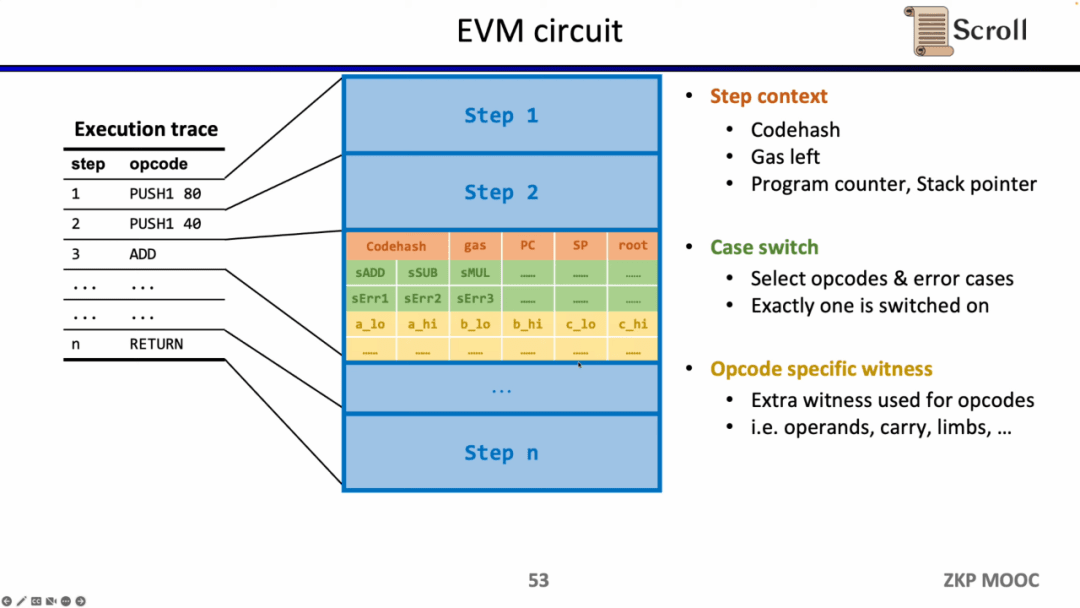
Lấy phép cộng đơn giản làm ví dụ, bạn cần đảm bảo rằng biến điều khiển sADD của opcode phép cộng được đặt thành 1 và các biến điều khiển của các opcode khác đều bằng 0. Trong Bối cảnh bước, lượng khí tiêu thụ bị ràng buộc bằng 3 bằng cách đặt gas' - gas - 3 = 0. Tương tự, bộ đếm bị ràng buộc tích lũy 1 sau bước này; các biến được điều khiển thành 1 thông qua opcode. Để hạn chế bước này là một thao tác bổ sung; trong Opcode Cụ thể Witness, hãy hạn chế việc bổ sung thực tế các toán hạng.
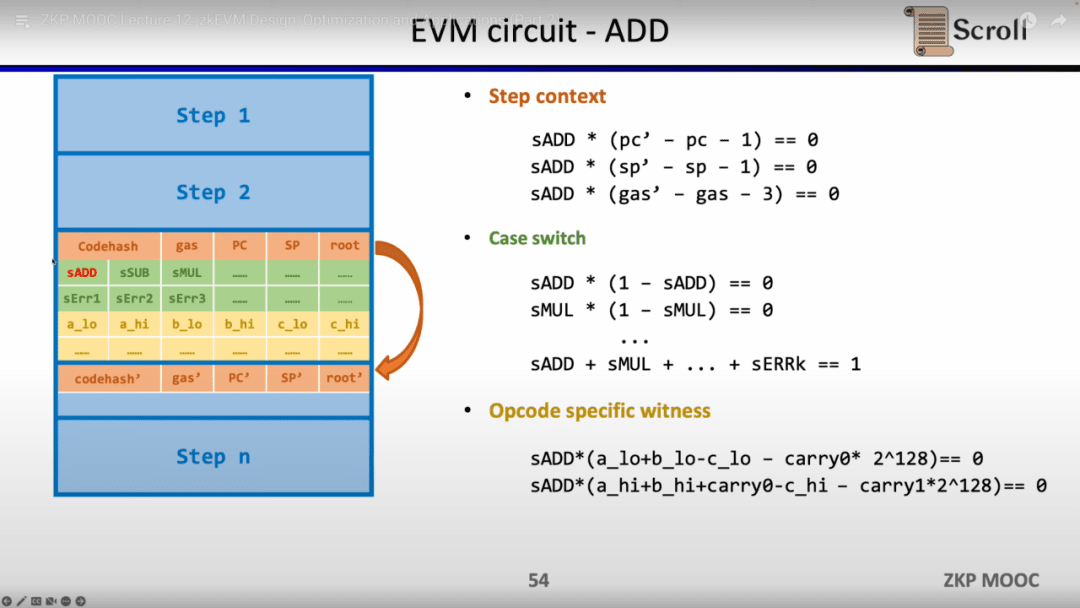
Ngoài ra, cần có các ràng buộc mạch bổ sung để đảm bảo tính chính xác của các toán hạng được đọc từ bộ nhớ. Ở đây trước tiên chúng ta cần xây dựng bảng tra cứu để chứng minh toán hạng thuộc về bộ nhớ. Và xác minh tính đúng đắn của bảng bộ nhớ thông qua mạch bộ nhớ (Mạch RAM).
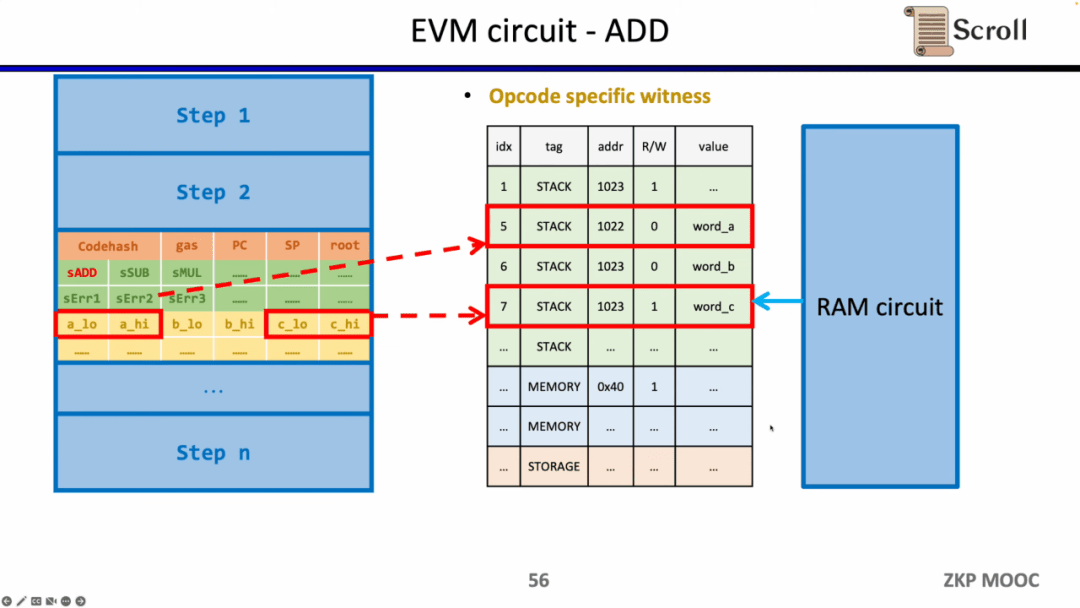
Phương pháp tương tự có thể được áp dụng cho các hàm băm không thân thiện với zk. Xây dựng bảng tra cứu của hàm băm, ánh xạ đầu vào và đầu ra hàm băm trong dấu vết thực thi tới bảng tra cứu và sử dụng mạch băm bổ sung để xác minh Kiểm tra hàm băm. tính chính xác của bảng tra cứu.
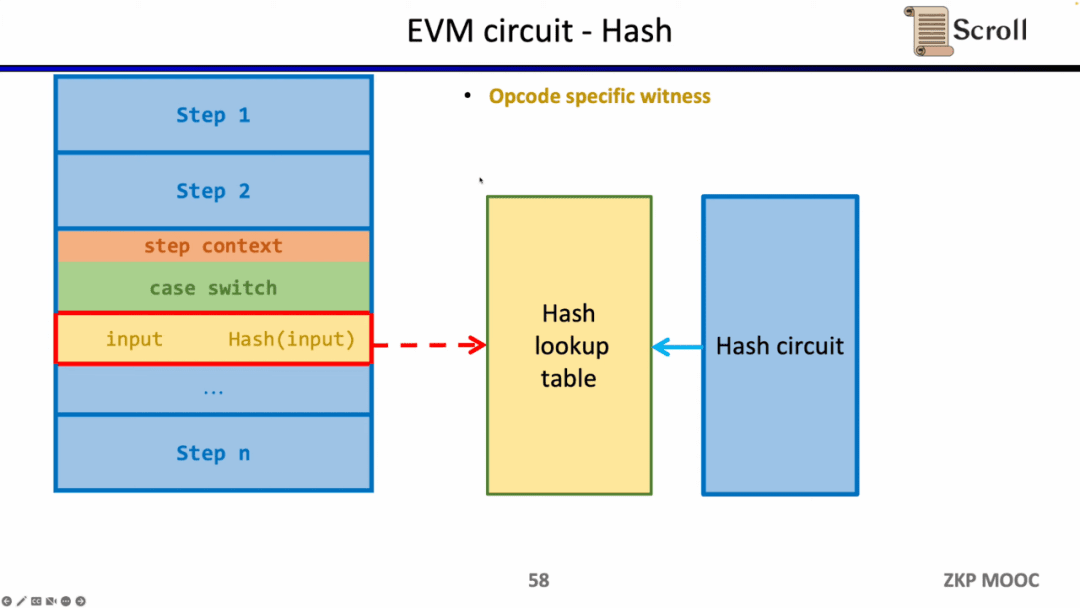
Bây giờ chúng ta hãy xem cấu trúc mạch của zkEVM. Mạch EVM cốt lõi được sử dụng để hạn chế tính chính xác của từng bước của dấu vết thực thi. Ở một số nơi khó ràng buộc mạch EVM, chúng tôi sử dụng các bảng tra cứu để ánh xạ, bao gồm Bảng cố định, Keccak. Bảng, Bảng RAM, Mã byte, Giao dịch, Bối cảnh khối, sau đó sử dụng các mạch riêng biệt để hạn chế các bảng tra cứu này, chẳng hạn như các mạch Keccak để hạn chế các bảng Keccak.
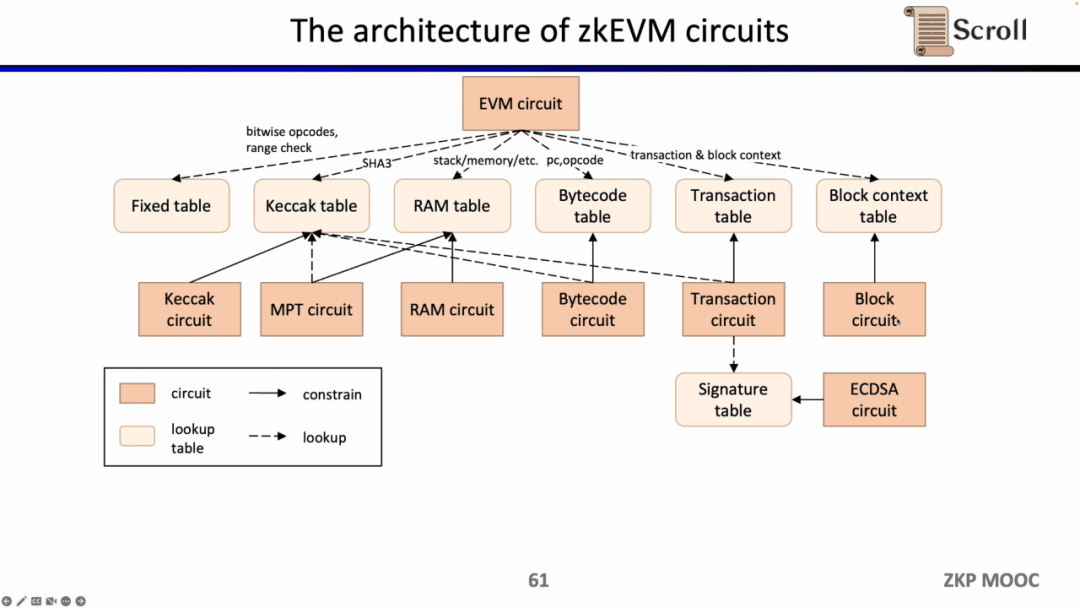
Tóm lại, quy trình làm việc hoàn chỉnh của zkEVM được hiển thị trong hình bên dưới.
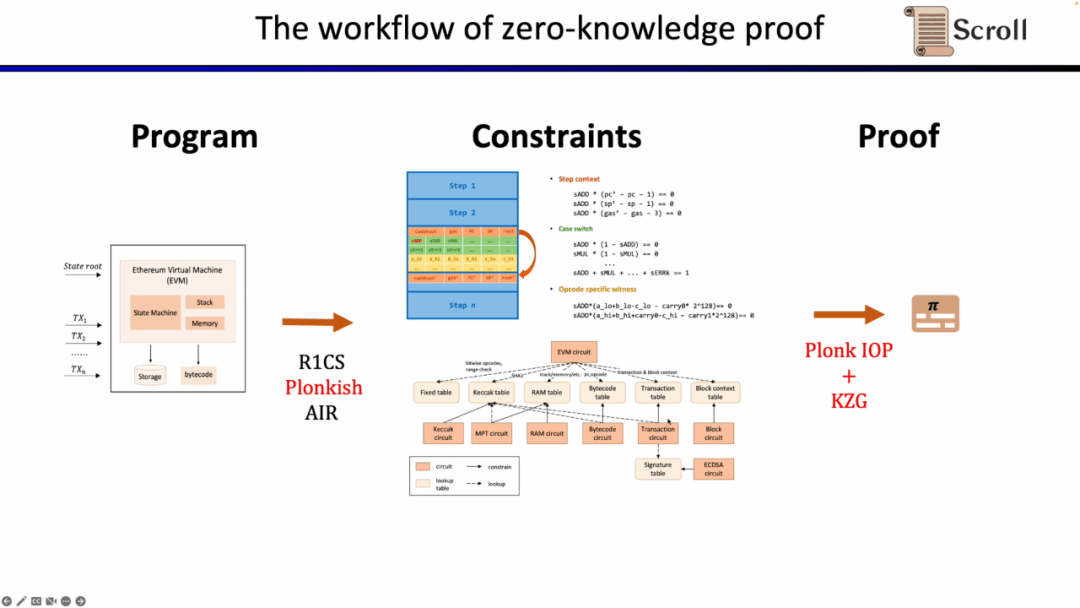
hệ thống chứng minh
Vì việc xác minh trực tiếp các mạch EVM, mạch bộ nhớ, mạch lưu trữ, v.v. nêu trên trên L1 rất tốn kém nên hệ thống chứng minh của Scroll áp dụng kiến trúc hai lớp.
Lớp đầu tiên chịu trách nhiệm trực tiếp chứng minh EVM, đòi hỏi một lượng tính toán lớn để tạo ra bằng chứng. Do đó, hệ thống chứng minh cấp một cần phải hỗ trợ các cổng và bảng tra cứu tùy chỉnh, thân thiện với khả năng tăng tốc phần cứng, tạo các phép tính song song trong bộ nhớ đỉnh thấp và có mạch xác minh nhỏ có thể được xác minh nhanh chóng. Các lựa chọn thay thế đầy hứa hẹn bao gồm Plonky2, Starky và eSTARK về cơ bản đều sử dụng Plonk ở mặt trước, nhưng có thể sử dụng FRI ở mặt sau và tất cả đều đáp ứng bốn đặc điểm trên. Một loại giải pháp thay thế khác bao gồm Halo2 được phát triển bởi Zcash và phiên bản KZG của Halo2.
Ngoài ra còn có một số hệ thống chứng minh mới đầy hứa hẹn, chẳng hạn như HyperPlonk, gần đây đã loại bỏ FFT, và hệ thống chứng minh NOVA có thể đạt được các chứng minh đệ quy nhỏ hơn. Nhưng họ chỉ hỗ trợ R1CS trong nghiên cứu. Nếu sau này họ có thể hỗ trợ Plonkish và áp dụng nó vào thực tế thì sẽ rất thiết thực và hiệu quả.
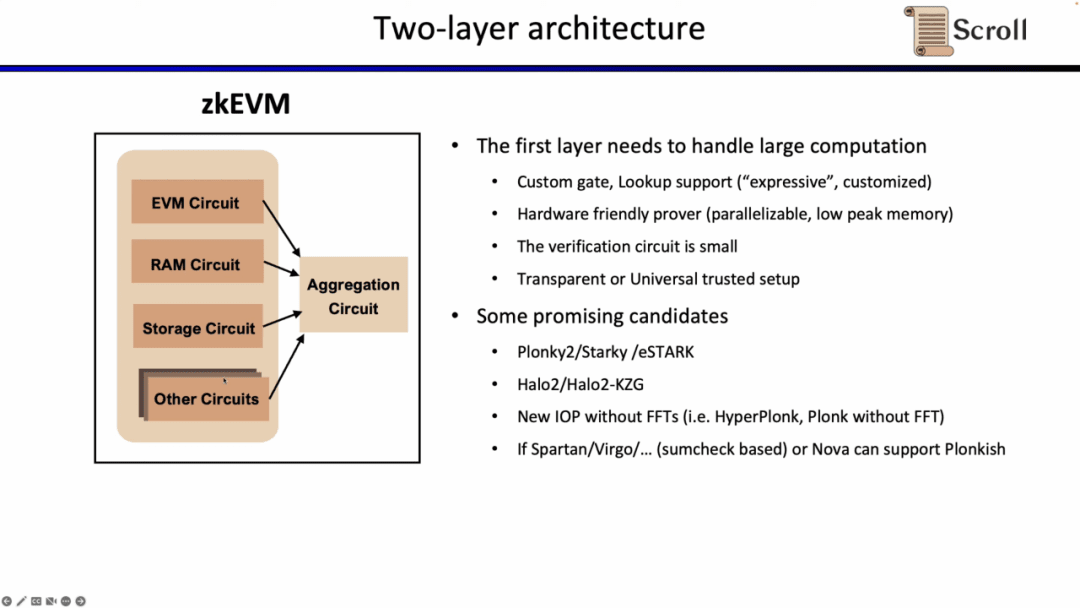
Hệ thống chứng minh cấp độ thứ hai được sử dụng để chứng minh tính chính xác của bằng chứng cấp độ đầu tiên và cần được xác minh một cách hiệu quả trong EVM. Lý tưởng nhất là hệ thống này phải thân thiện với khả năng tăng tốc phần cứng và hỗ trợ thiết lập minh bạch hoặc phổ quát. Các lựa chọn thay thế đầy hứa hẹn bao gồm Groth16 và hệ thống chứng minh Plonkish không có cột. Groth16 vẫn là đại diện cho hiệu quả chứng minh cực kỳ cao trong nghiên cứu hiện tại và hệ thống chứng minh Plonkish cũng có thể đạt được hiệu quả chứng minh cao ngay cả với số lượng cột nhỏ.
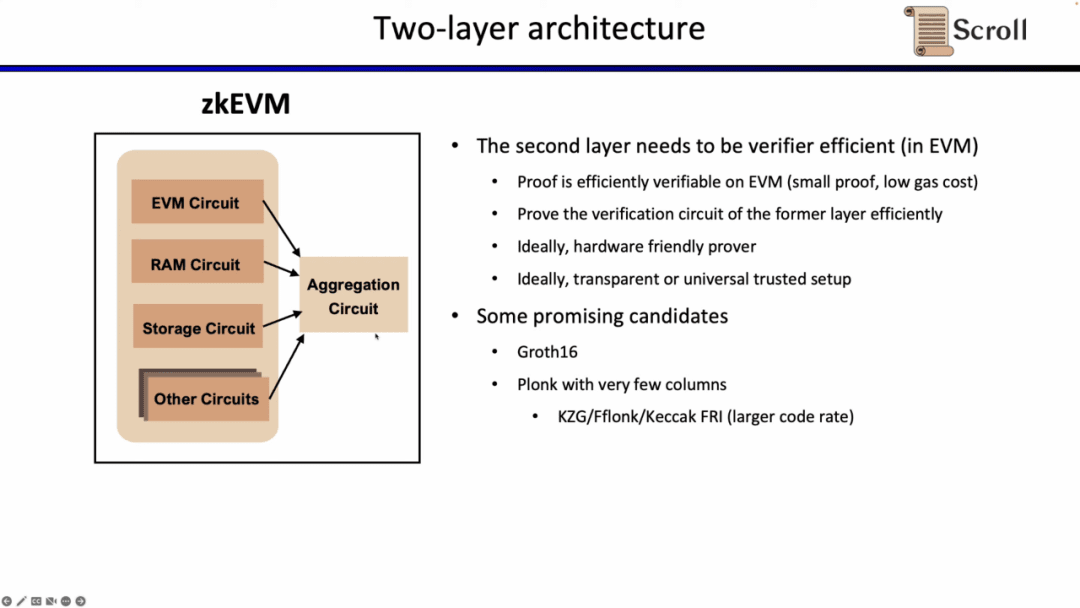
Tại Scroll, chúng tôi sử dụng hệ thống chứng minh Halo2-KZG trong cả hai hệ thống chứng minh hai lớp của mình. Vì Halo2-KZG có thể hỗ trợ các cổng và bảng tra cứu tùy chỉnh nên nó hoạt động tốt dưới khả năng tăng tốc phần cứng GPU và mạch xác minh có kích thước nhỏ và có thể được xác minh nhanh chóng. Sự khác biệt là chúng tôi sử dụng hàm băm Poseidon trong hệ thống chứng minh lớp thứ nhất để cải thiện hơn nữa hiệu quả chứng minh, trong khi hệ thống chứng minh lớp thứ hai vẫn sử dụng hàm băm Keccak vì nó được xác minh trực tiếp trên Ethereum. Scroll cũng đang khám phá khả năng của một hệ thống chứng minh nhiều lớp để tổng hợp thêm các bằng chứng tổng hợp được tạo ra bởi hệ thống chứng minh cấp độ thứ hai.
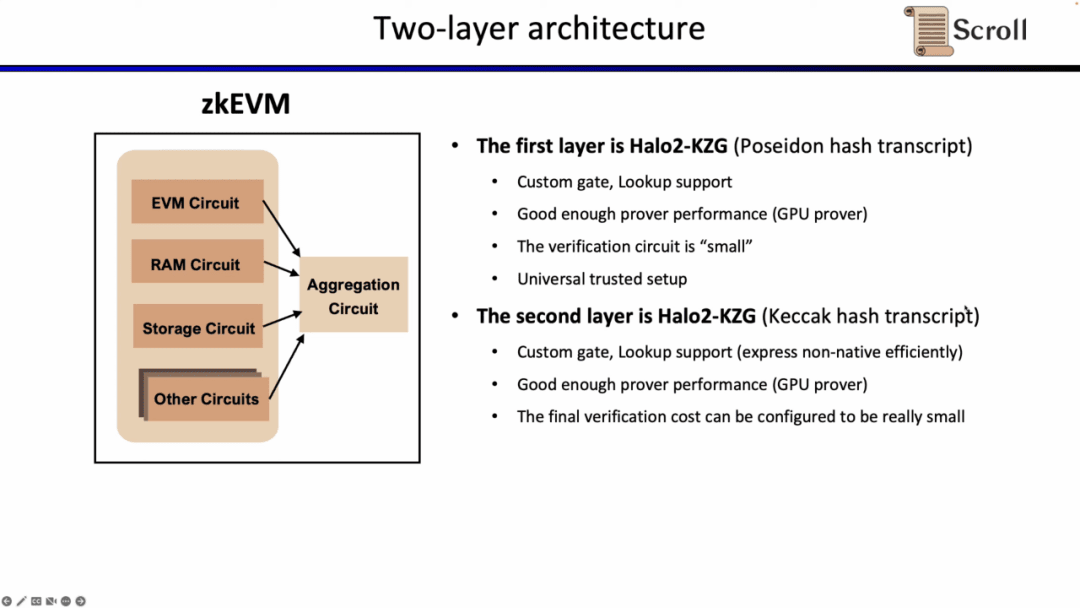
Theo cách triển khai hiện tại, mạch EVM của hệ thống chứng minh cấp một của Scroll có 116 cột, 2496 cổng tùy chỉnh, 50 bảng tra cứu, thứ tự cao nhất là 9 và yêu cầu 2^18 dòng dưới 1M Gas trong khi hệ thống chứng minh cấp hai có The mạch tổng hợp chỉ có 23 cột, 1 cổng tùy chỉnh, 7 bảng tra cứu và thứ tự cao nhất là 5. Để tổng hợp mạch EVM, mạch bộ nhớ và mạch lưu trữ cần có 2^25 hàng.

Scroll cũng đã thực hiện rất nhiều công việc nghiên cứu và tối ưu hóa về khả năng tăng tốc phần cứng GPU. Đối với các mạch EVM, quá trình tối ưu hóa GPU chỉ mất 30 giây, hiệu quả gấp 9 lần so với các mạch tổng hợp chỉ sau khi tối ưu hóa GPU. mất 149 giây, hiệu quả gấp 15 lần so với CPU. Trong các điều kiện tối ưu hóa hiện tại, hệ thống chứng minh cấp độ 1M Gas mất khoảng 2 phút và hệ thống chứng minh cấp độ thứ hai mất khoảng 3 phút.

câu hỏi nghiên cứu thú vị

Trong phần thứ ba, Zhang Ye đã nói về một số vấn đề nghiên cứu thú vị trong quá trình xây dựng zkEVM của Scroll, từ mạch số học front-end đến việc triển khai bộ chứng minh.
mạch điện
Đầu tiên là tính ngẫu nhiên trong mạch Vì trường EVM là 256 bit nên chúng ta cần chia nó thành 32 trường 8 bit để thực hiện kiểm chứng phạm vi hiệu quả hơn. Sau đó, chúng tôi sử dụng phương pháp Kết hợp tuyến tính ngẫu nhiên (RLC) để mã hóa 32 trường thành 1 bằng cách sử dụng số ngẫu nhiên. Chúng tôi chỉ cần xác minh trường này để xác minh trường 256 bit ban đầu. Nhưng vấn đề là số ngẫu nhiên cần được tạo sau khi các trường được phân chia để đảm bảo rằng nó không bị giả mạo.
Do đó, Scroll và nhóm PSE đã đề xuất giải pháp chứng minh nhiều giai đoạn để đảm bảo rằng sau khi tách trường, các số ngẫu nhiên được sử dụng để tạo RLC. Giải pháp này được gói gọn trong Challenge API. RLC có nhiều kịch bản ứng dụng trong zkEVM. Nó không chỉ có thể nén trường EVM thành một trường mà còn mã hóa đầu vào có độ dài thay đổi hoặc tối ưu hóa bố cục của bảng tra cứu. Tuy nhiên, vẫn còn nhiều vấn đề mở cần được giải quyết.

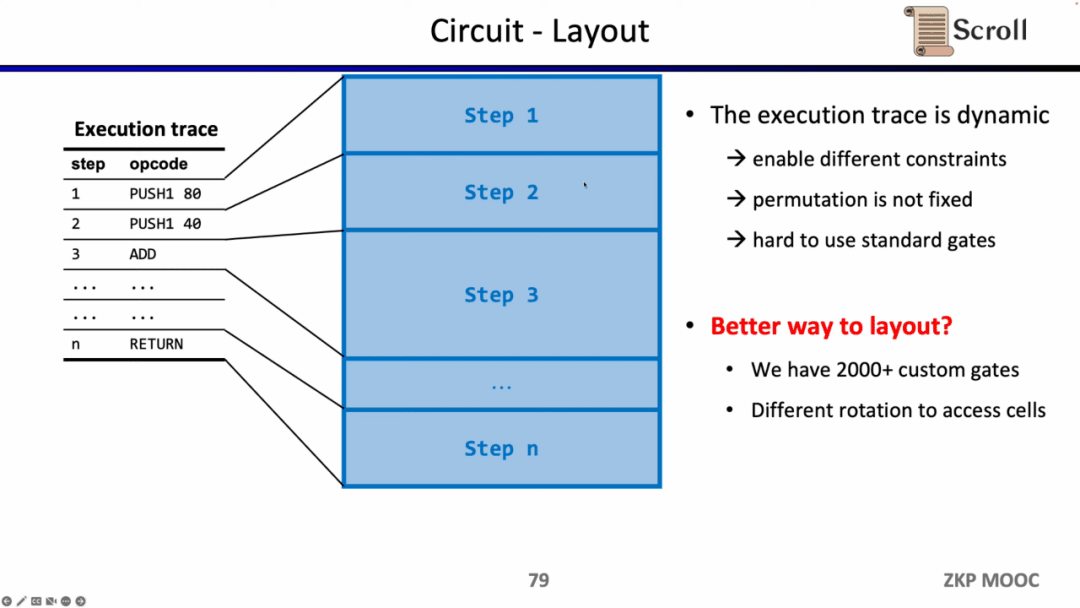
Câu hỏi nghiên cứu thú vị thứ hai về mạch điện là cách bố trí mạch điện. Lý do tại sao giao diện người dùng Scroll sử dụng Plonkish là vì dấu vết thực thi của EVM thay đổi linh hoạt và cần có khả năng hỗ trợ các ràng buộc khác nhau cũng như thay đổi các bài kiểm tra tương đương, đồng thời cổng tiêu chuẩn hóa của R1CS yêu cầu quy mô mạch lớn hơn để triển khai.
Tuy nhiên, Scroll hiện sử dụng hơn 2.000 cổng tùy chỉnh để đáp ứng các dấu vết thực thi thay đổi linh hoạt và cũng đang khám phá cách tối ưu hóa hơn nữa bố cục mạch, bao gồm tách Opcode thành Micro Opcode hoặc sử dụng lại các ô trong cùng một bảng.
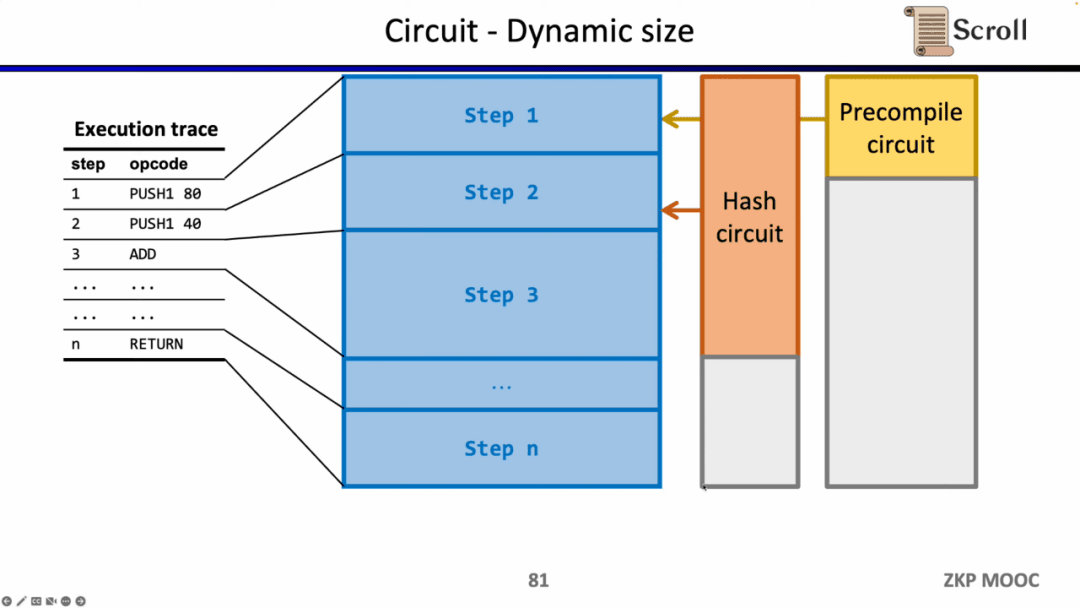
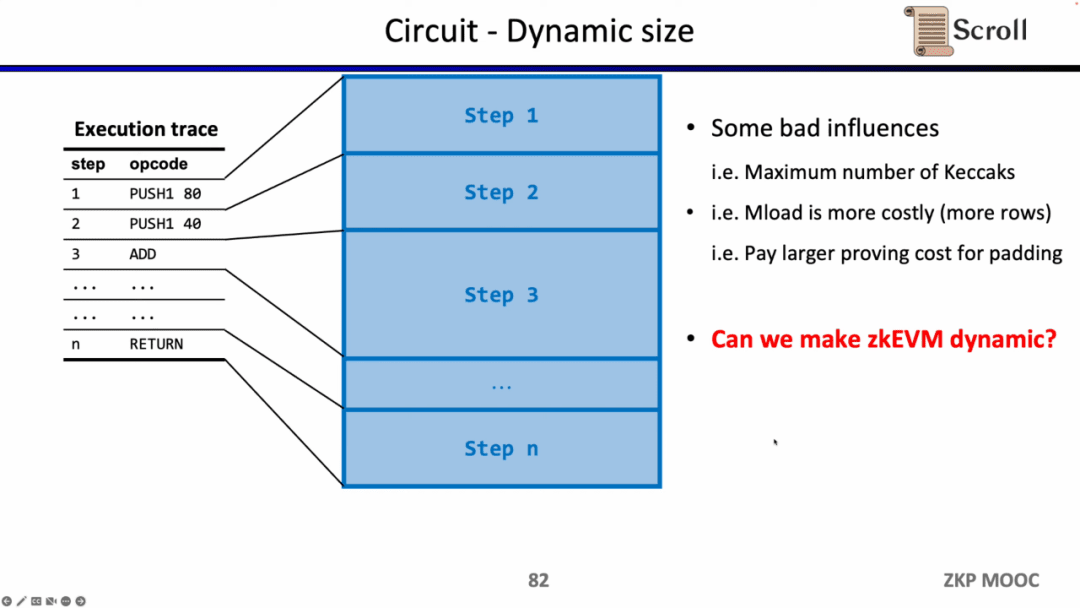
Câu hỏi nghiên cứu thú vị thứ ba về mạch điện là khả năng chia tỷ lệ động. Bởi vì quy mô mạch của các opcode khác nhau là khác nhau, nhưng để đáp ứng dấu vết thực thi thay đổi linh hoạt, opcode của mỗi bước cần phải đáp ứng quy mô mạch tối đa, chẳng hạn như băm Keccak, vì vậy chúng tôi thực sự phải trả thêm chi phí. Giả sử chúng ta có thể làm cho zkEVM thích ứng linh hoạt với các dấu vết thực thi thay đổi linh hoạt, điều này sẽ tiết kiệm chi phí không cần thiết.
câu tục ngữ
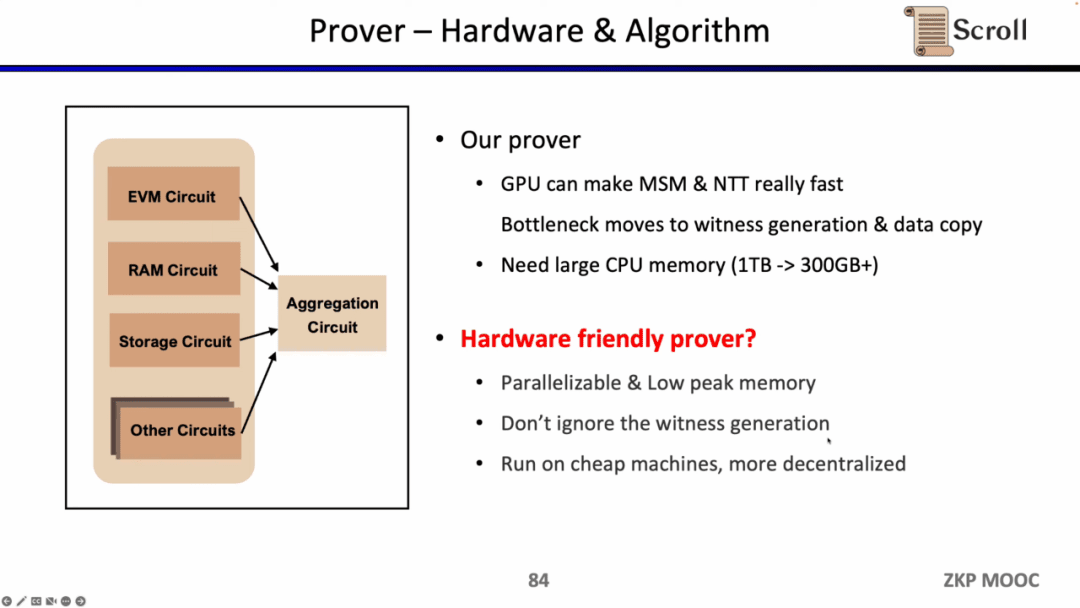
Về mặt chứng minh, Scroll đã thực hiện rất nhiều tối ưu hóa cho MSM và NTT về khả năng tăng tốc GPU, nhưng giờ đây, nút thắt đã chuyển sang việc tạo và sao chép dữ liệu chứng kiến. Bởi vì người ta giả định rằng MSM và NTT chiếm 80% thời gian chứng minh, ngay cả khi khả năng tăng tốc phần cứng có thể cải thiện hiệu quả này lên gấp nhiều lần, thì thời gian chứng minh 20% ban đầu của việc tạo và sao chép dữ liệu sẽ trở thành một nút thắt cổ chai mới. Một vấn đề khác với Prover là nó đòi hỏi nhiều bộ nhớ, vì vậy cần phải khám phá các giải pháp phần cứng rẻ hơn và phi tập trung hơn.
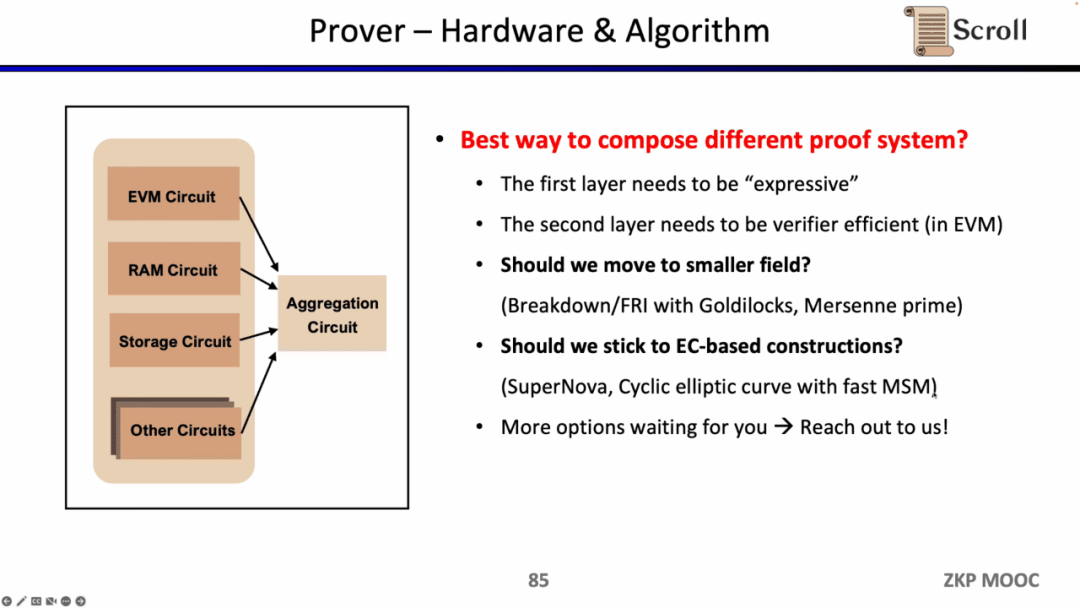
Đồng thời, Scroll cũng đang khám phá các thuật toán chứng minh và tăng tốc phần cứng để nâng cao hiệu quả của người chứng minh. Hiện tại có hai hướng chính, hoặc chuyển sang miền nhỏ hơn, chẳng hạn như sử dụng miền Goldilocks 64-bit, Mersenne Prime 32-bit, v.v., hoặc bám vào hệ thống chứng minh mới dựa trên các đường cong elip (EC). . Tất nhiên, có những con đường khả thi khác và những người bạn có ý tưởng có thể liên hệ trực tiếp với Scroll.
sự an toàn
Khi xây dựng zkEVM, bảo mật là điều tối quan trọng. ZkEVM do PSE và Scroll cùng xây dựng có khoảng 34.000 dòng mã Từ góc độ kỹ thuật phần mềm, các cơ sở mã phức tạp này không thể không có lỗ hổng trong một thời gian dài. Scroll hiện đang xem xét cơ sở mã zkEVM thông qua một số lượng lớn các cuộc kiểm tra, bao gồm cả các công ty kiểm toán hàng đầu trong ngành.


Các ứng dụng khác sử dụng zkEVM

Phần 4 khám phá các ứng dụng khác sử dụng zkEVM.
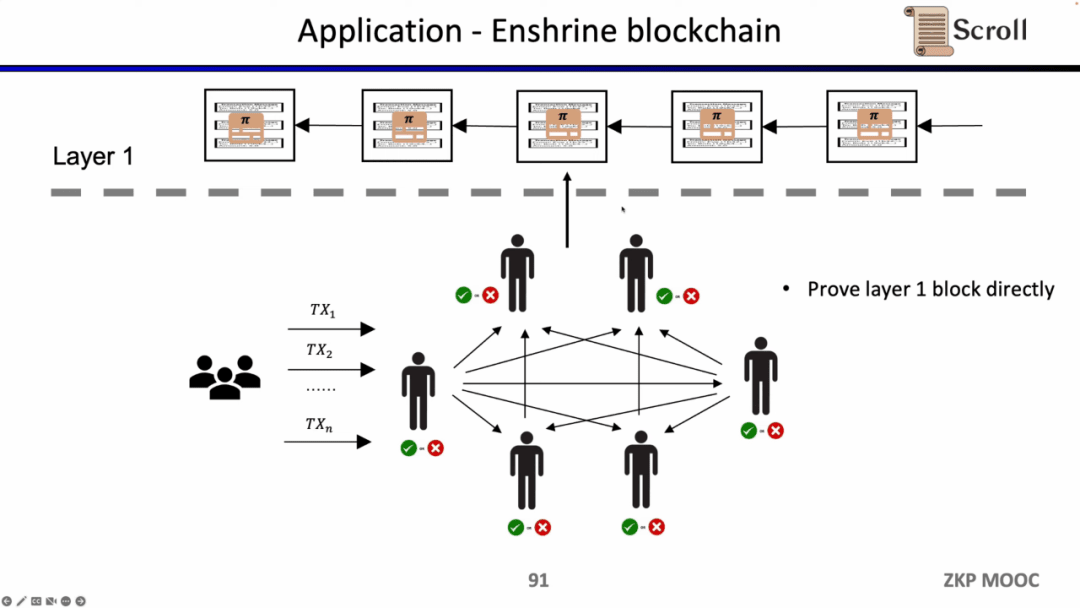
Trong kiến trúc zkRollup, chúng tôi xác minh rằng n giao dịch trên L2 hợp lệ thông qua hợp đồng thông minh trên L1.
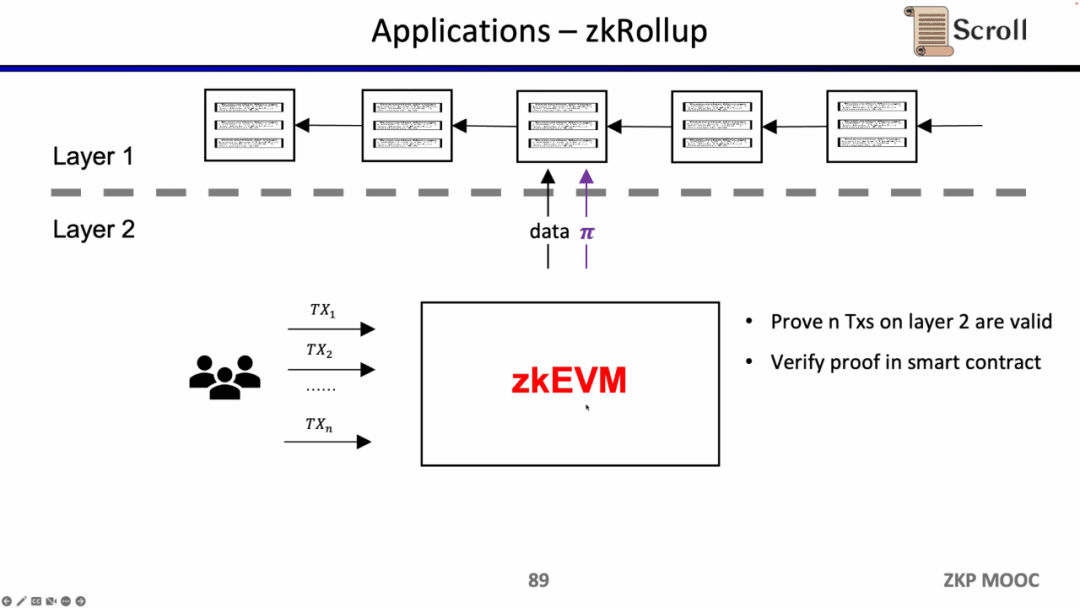
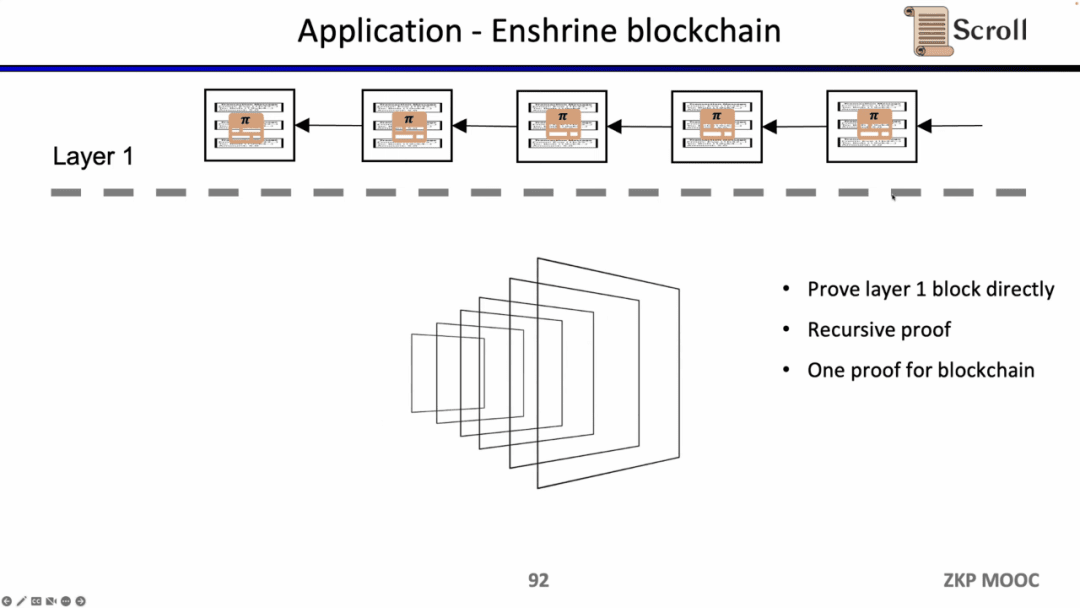
Nếu chúng tôi xác minh trực tiếp khối L1 thì nút L1 không cần thực hiện giao dịch nhiều lần mà chỉ cần xác minh tính hợp lệ của từng chứng chỉ khối. Giải pháp kiến trúc như vậy được gọi là Enshrine Blockchain. Hiện tại, việc triển khai trực tiếp trên Ethereum là rất khó khăn vì toàn bộ khối Ethereum cần được xác minh, sẽ bao gồm việc xác minh một số lượng lớn chữ ký, dẫn đến thời gian xác minh lâu hơn và độ bảo mật thấp hơn. Tất nhiên, đã có một số chuỗi công khai khác sử dụng bằng chứng đệ quy để xác minh toàn bộ chuỗi khối bằng một bằng chứng duy nhất, chẳng hạn như Mina.
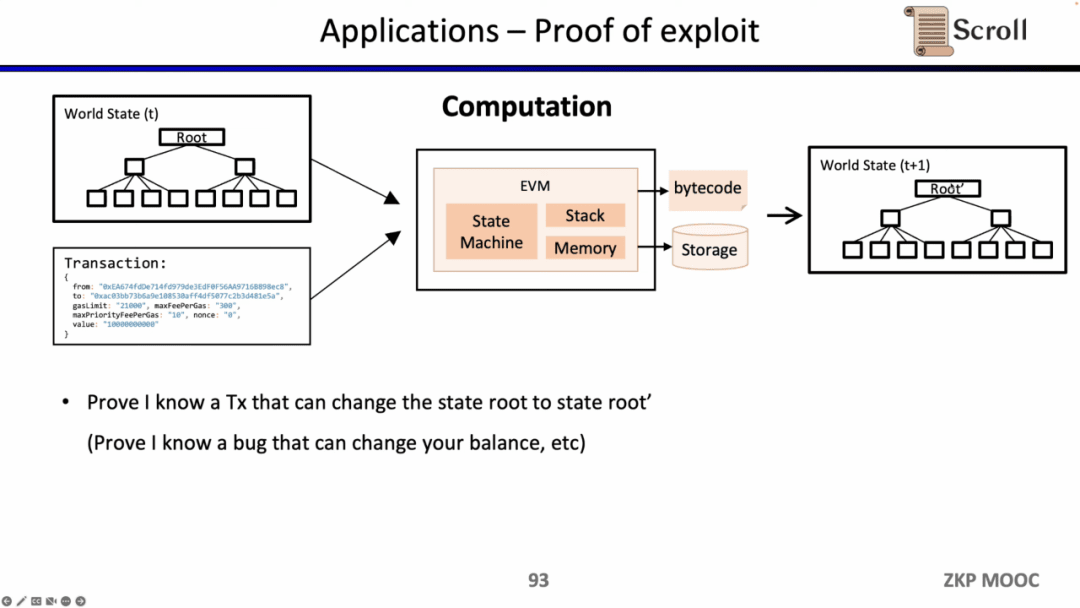
Vì zkEVM có thể chứng minh sự chuyển đổi trạng thái nên nó cũng có thể được mũ trắng sử dụng để chứng minh rằng họ biết các lỗ hổng của một số hợp đồng thông minh nhất định và tìm kiếm tiền thưởng từ các bên dự án.
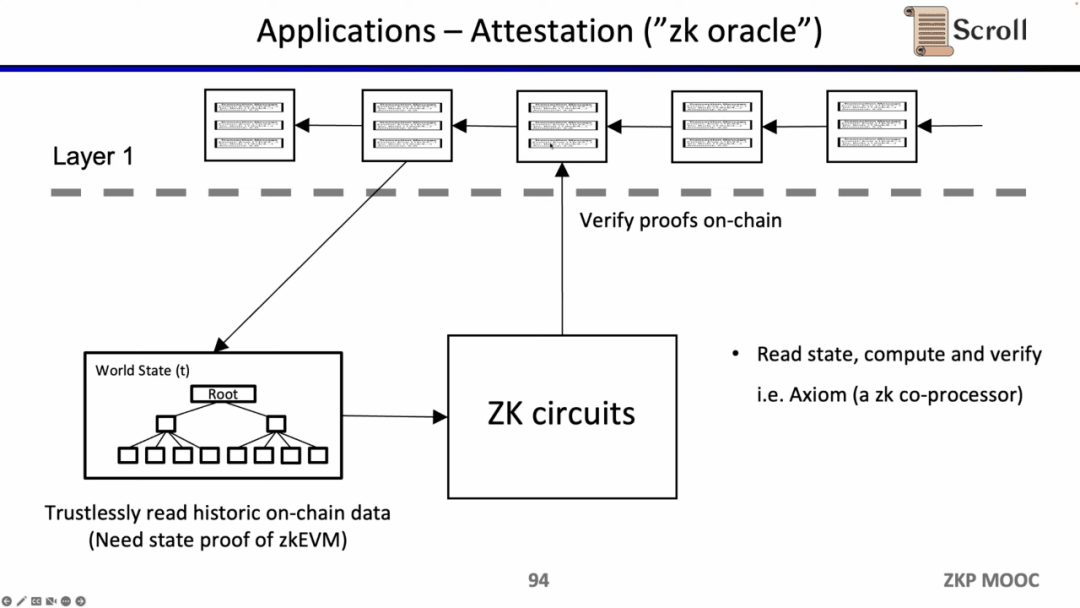
Trường hợp sử dụng cuối cùng là chứng minh các tuyên bố về dữ liệu lịch sử thông qua bằng chứng không có kiến thức và sử dụng nó như một lời tiên tri hiện đang tạo ra các sản phẩm trong lĩnh vực này. Tại ETHBeijing Hackathon gần đây, nhóm GasLockR đã tận dụng tính năng này để chứng minh chi phí Gas lịch sử.
Cuối cùng, Scroll đang xây dựng giải pháp mở rộng quy mô phổ quát của zkRollup cho Ethereum, sử dụng các mạch số học và hệ thống chứng minh rất tiên tiến, đồng thời xây dựng các trình xác minh nhanh thông qua tăng tốc phần cứng để chứng minh đệ quy. Hiện tại, mạng thử nghiệm Alpha đã trực tuyến và hoạt động ổn định từ lâu.
Tất nhiên, vẫn còn một số vấn đề thú vị cần được giải quyết, bao gồm thiết kế giao thức và thiết kế cơ chế, kỹ thuật không cần kiến thức và hiệu quả thực tế. Mọi người đều có thể tham gia Scroll để cùng nhau xây dựng!

Cuộn
Trang web: https://scroll.io/
Twitter: https://twitter.com/Scroll_ZKP
Bất hòa: https://discord.com/invite/scroll
Github: https://github.com/scroll-tech
Youtube: https://www.youtube.com/@Scroll_ZKP