
Principais conclusões
O Ledger da Binance armazena saldos de contas e transações, ao mesmo tempo que permite que serviços façam transações.
Ele cria as condições necessárias para alto rendimento, disponibilidade 24 horas por dia, 7 dias por semana e precisão de dados em nível de bit.
O papel da Binance Ledger nos bastidores a torna uma das tecnologias mais importantes da Binance. Aprenda exatamente como funciona e os problemas que está resolvendo na operação da maior exchange de criptomoedas do mundo aqui.

Já se perguntou exatamente o que faz o Binance funcionar? Com a necessidade de processar milhões de transações diariamente em uma enorme base de usuários, vale a pena dar uma olhada no que a Binance tem nos bastidores.
A base das operações técnicas da Binance é o seu Ledger. O Ledger armazena saldos e transações de contas enquanto permite que os serviços façam transações.
Binance tem altos requisitos para o razão
Como você pode imaginar, os requisitos do Ledger são altos para atender à enorme demanda dos usuários. Existem três pontos principais que precisam ser considerados:
Alto rendimento com capacidade para uma grande quantidade de TPS (transações por segundo) em horários de pico.
Disponibilidade 24 horas por dia, 7 dias por semana, sem tempo de inatividade.
Precisão dos dados em nível de bit, sem perda de fundos ou erros de transação.
Vejamos um exemplo de entrada básica no Ledger. Aqui está uma transação comum em que a conta 1 transfere 1 BTC para a conta 2.
Saldo antes da transação:
tabela 1
Saldo após a transação:
mesa 2
Nesta transação, existem dois comandos:
Conta 1 -1 BTC
Conta 2 +1 BTC
Quando a transação for realizada, dois registros de saldo serão armazenados para auditoria e reconciliação.
Tabela 3
A solução padrão da indústria
Uma solução Ledger padrão do setor é baseada em um banco de dados relacional. Voltando ao exemplo anterior, os dois comandos da transação podem ser traduzidos em duas instruções SQL e executados em uma transação de banco de dados (tabela 4).
tabela-4
As vantagens da solução
É bastante simples de implementar.
É fácil aplicar técnicas comuns de ajuste de banco de dados, como divisão e fragmentação de leitura/gravação, para melhorar o desempenho.
Não é difícil para os devops se recuperarem do failover, bem como monitorar e manter um banco de dados comercial.
As desvantagens da solução
O TPS cairá drasticamente quando houver condições de corrida devido a bloqueios de linha.
É difícil dimensionar horizontalmente para melhorar o desempenho.
O problema da conta quente
Infelizmente para a Binance, a solução industrial demonstrada acima não atende aos seus elevados requisitos. Quando ocorre uma transação, ela deve conter os bloqueios de linha de cada linha envolvida. Embora algumas contas tenham relativamente poucas transações para lidar, há, é claro, contas ocupadas com muitas transações simultâneas. Neste caso, apenas uma transação é capaz de manter o bloqueio de linha da conta.
As outras transações não poderão fazer nada além de esperar que o bloqueio seja liberado. Chamamos essa situação de problema de conta quente e testes internos mostram que o TPS cairá pelo menos 10 vezes nessa situação. Você pode ver esse problema na tabela 5 abaixo.
Exemplo de conta quente:
tabela-5
Solução de contabilidade da Binance
Como resolvemos o problema da conta quente?
Uma solução possível para o nosso problema é converter de forma inovadora o modelo multithread para um modo single-thread. Isso evita o problema de condição de corrida e, como resultado, não haverá um problema de conta quente.
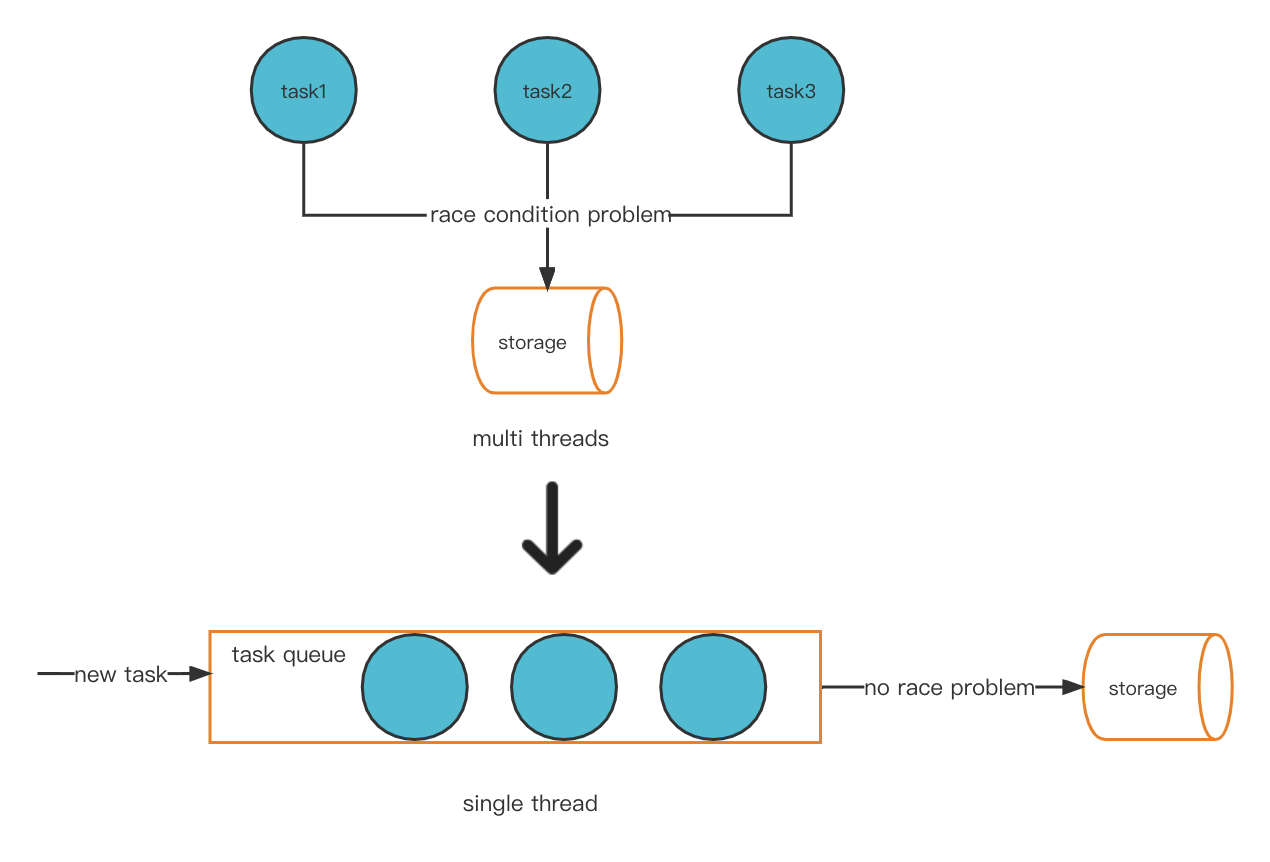
Novo modelo de thread
Comunicação baseada em mensagens
Após implementar nosso novo modelo de thread, um problema de comunicação precisa ser resolvido. A camada da máquina de estado é de thread único, mas a camada de rede é multithread, então como podemos nos comunicar de forma eficiente entre os dois?
Um Disruptor [1] é o próximo passo do quebra-cabeça. Ele cria uma fila de alto desempenho e sem bloqueios com base em um design de buffer em anel.
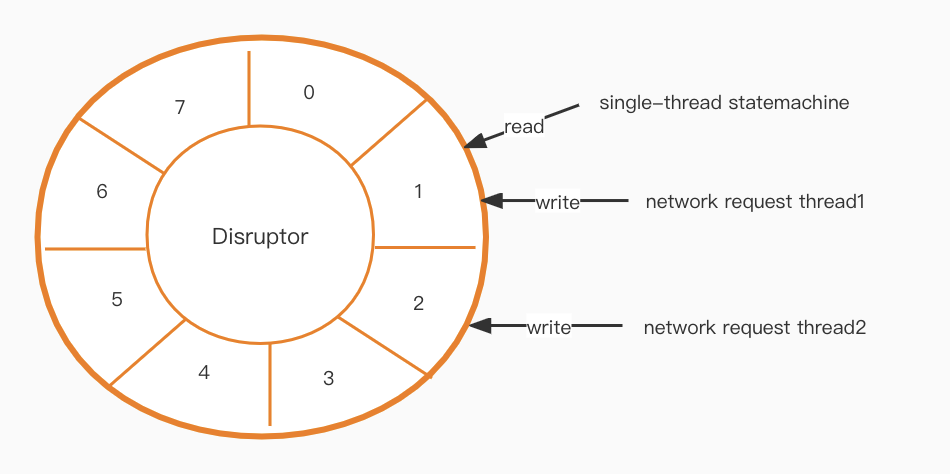
Alta disponibilidade
Até agora, alcançamos alto desempenho usando um modelo em memória e armazenamento local RocksDB [2]. Mas, mais uma vez, surge um novo desafio. Agora precisamos cuidar da alta disponibilidade de dados.
Para garantir a consistência dos dados entre os nós, usamos um Algoritmo de Consenso Raft [3]. Isto significa que o número de backups de dados é igual ao número de nós não líderes presentes. O algoritmo também garante que o sistema ainda funcionará com pelo menos metade dos nós saudáveis, para ajudar a fornecer alta disponibilidade de serviço.
Funções do domínio Raft:
Líder. O Líder processa todas as solicitações do cliente e replica a operação para todos os seguidores.
Seguidor. Os seguidores seguem o líder em todas as operações. Se o líder falhar, um dos seguidores será eleito o novo líder.
Aprendiz. Os alunos são seguidores sem direito a voto que enviam cada registro de alteração idempotente/transação para outros serviços.
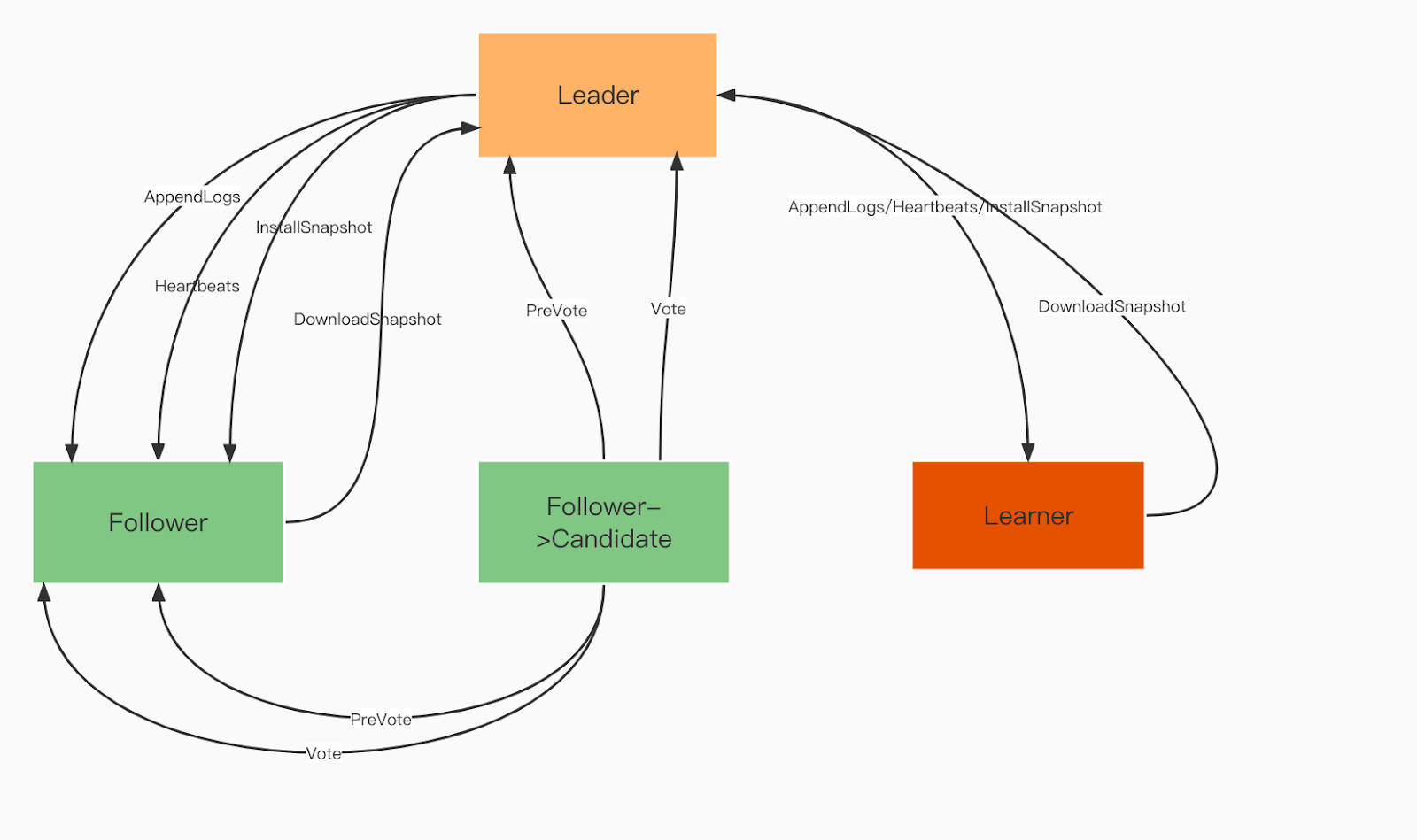
Funções de domínio Raft
CQRS (segregação de responsabilidade de consulta de comando)
Outro critério importante que queremos garantir é o maior desempenho de gravação do Ledger e a capacidade para condições de consulta mais diversas. Para isso, precisamos criar domínios diferentes. O domínio raft fornece escrita mais eficiente baseada em rocksdb+raft, e o domínio view escuta as mensagens do domínio raft e as salva no banco de dados relacional para consultas externas. Também podemos implementar a segregação de responsabilidade de consulta de comando no nível arquitetônico.
Arquitetura de razão
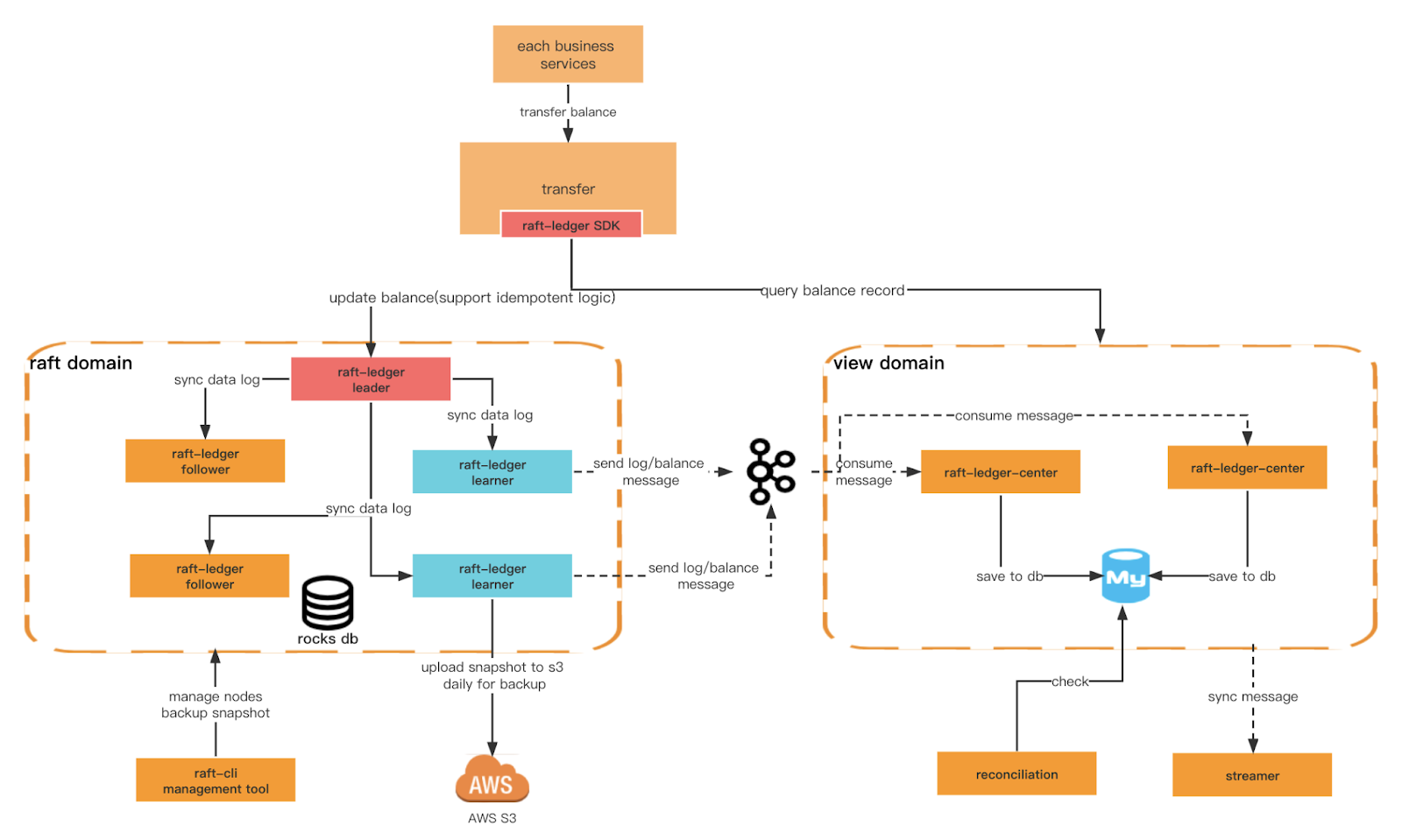
Arquitetura geral
Termos entre Raft e Ledger:
tabela-6
Ver funções de domínio
Centro de registro de jangada
Consumir a mensagem produzida pelo aluno e armazenar os dados de transação e saldo no MySQL para fins de consulta.
Processamento de solicitação
Uma solicitação de transação passará primeiro pela camada de rede, pela camada de razão (manipulador de solicitação) e pela camada de raft (sincronização de log de raft). Em seguida, ele retornará à camada contábil (máquina de estado), à camada de rede (manipulador de resposta) e, finalmente, retornará uma resposta ao cliente.
Os dados são passados pela fila entre as duas camadas.
Camada de Rede – Desserialize a solicitação RPC e coloque-a na fila de solicitações.
Camada Ledger – Obtenha a solicitação da fila e prepare o contexto. Em seguida, ele colocará os metadados da solicitação na fila raft.
Camada Raft – Obtenha os metadados da solicitação da fila raft e sincronize-os entre todos os seguidores. Em seguida, ele colocará o resultado na fila de aplicação.
Camada Ledger – Obtenha os dados da fila de aplicação e atualize a máquina de estado. Em seguida, ele colocará o resultado na fila de resposta.
Camada de rede – Obtenha o resultado da fila de resposta e construa e serialize os dados de resposta antes de devolvê-los ao cliente.
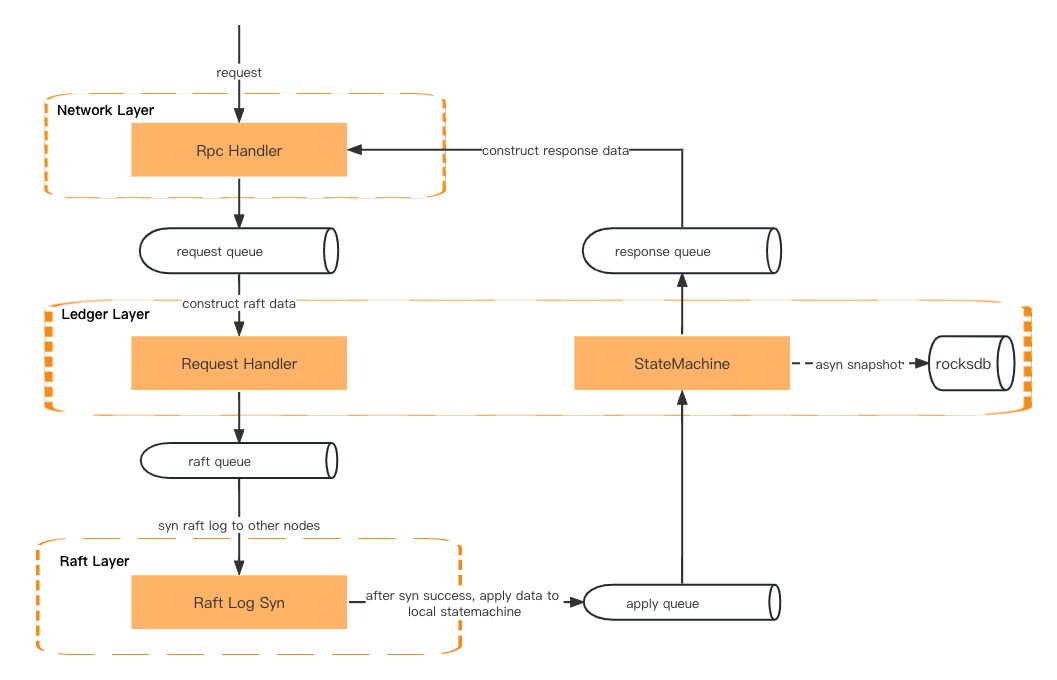
Processamento de solicitação
Recuperação de dados
Cada nó do Ledger acionará um instantâneo genérico com base em um período de tempo. Além disso, também implementamos um instantâneo consistente. Cada nó é acionado no mesmo índice de log de raft para garantir que a máquina de estado seja exatamente a mesma quando cada nó aciona um instantâneo. O instantâneo será então carregado no S3 para verificação pelo Checker e como backup frio.
Quando o Ledger é reiniciado, ele lê o instantâneo local e reconstrói a máquina de estado. Em seguida, ele reproduz o log da balsa local e sincroniza o log mais recente do líder até alcançar o índice mais recente. Se o instantâneo local ou o log da balsa não existir, ele será obtido do líder.
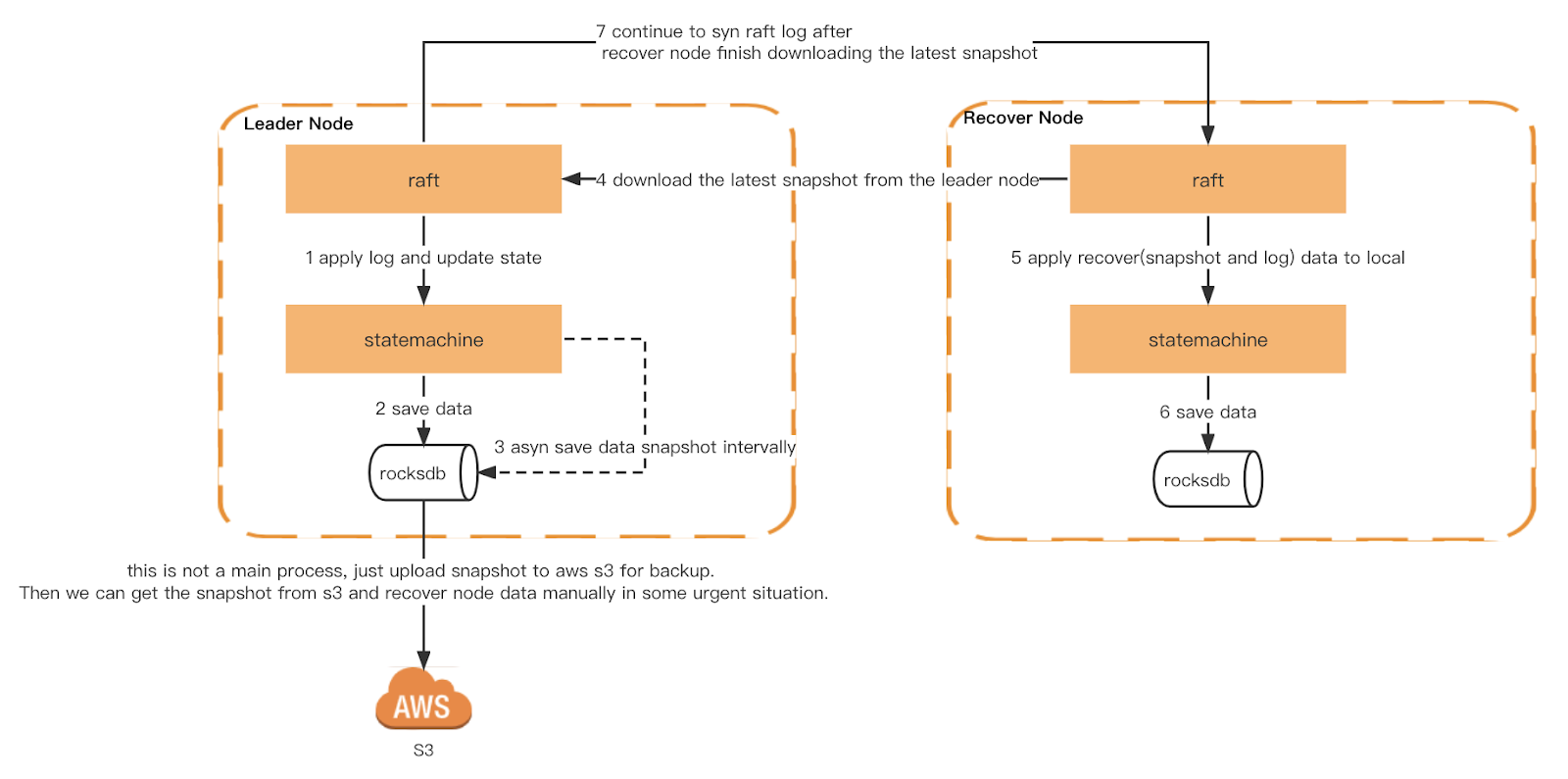
Instantâneo e recuperação
Tolerância a desastres
Para melhorar a disponibilidade e a tolerância a falhas, os nós do Ledger são implantados em zonas diferentes. Contanto que mais da metade dos nós estejam íntegros, os dados não serão perdidos e o failover será concluído em um segundo.
Mesmo que todo o cluster falhe, o que tem uma probabilidade muito baixa, ainda podemos restaurar o cluster por meio do snapshot consistente armazenado no Amazon S3 e recuperar os dados perdidos mais recentes por meio do sistema downstream.
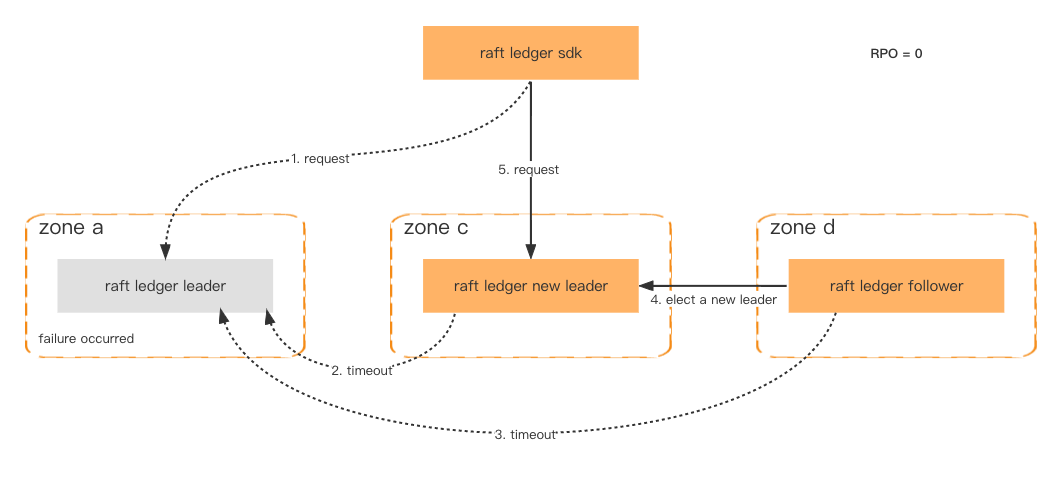
Tolerância ao erro
Desempenho
A tabela a seguir mostra as especificações de hardware para o teste de desempenho
Testes internos comprovam que um cluster de 4 nós (um líder, dois seguidores e um aluno) pode processar mais de 10.000 TPS. Por design, o cluster processa todas as transações, uma por uma. Não há nenhuma condição de bloqueio e corrida. Portanto, no cenário de conta quente, o TPS é tão alto quanto nos cenários normais.
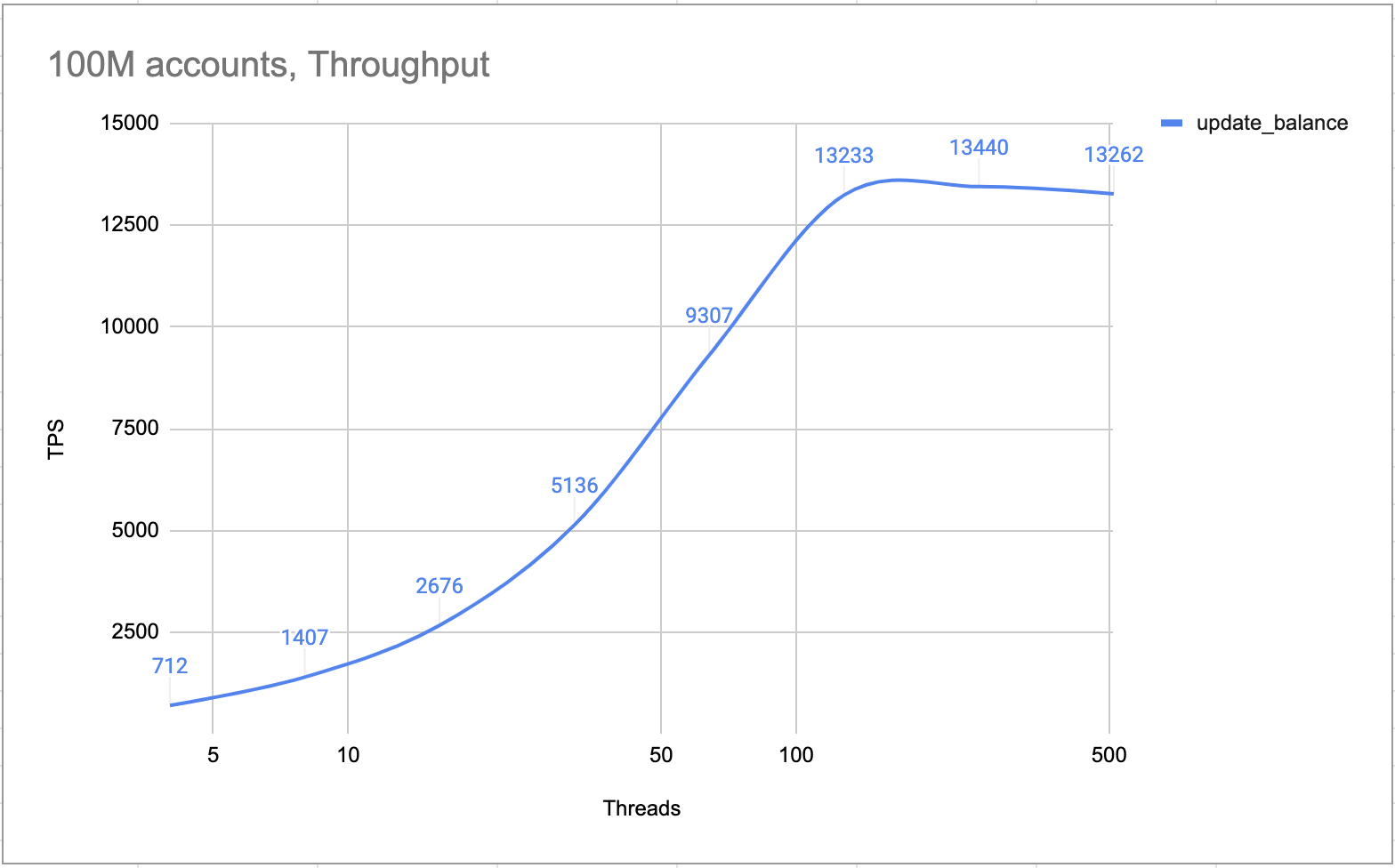
Conta quente TPS
A figura a seguir mostra a latência de cada transação. A maioria das transações pode ser concluída em 10 ms. As transações mais lentas podem ser concluídas em 25 ms.
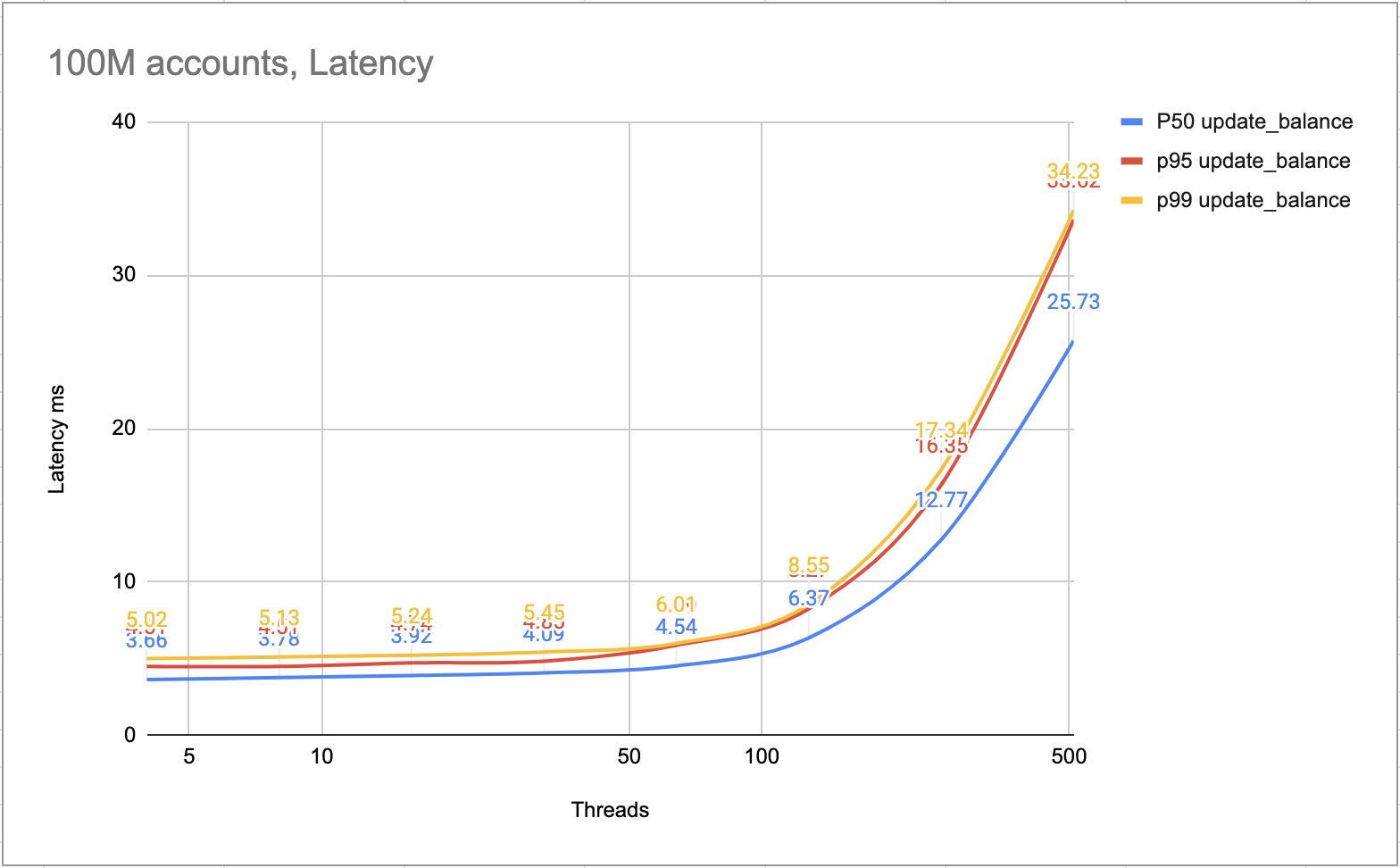
Latência ms
Potenciando nossos serviços com Binance Ledger
Como você viu, a resposta da indústria tradicional ao problema das contas quentes não satisfaz as necessidades da Binance e de seus clientes. Ao usar uma abordagem projetada especificamente para a infraestrutura da Binance, obtivemos uma das trocas e experiências de produto mais tranquilas disponíveis. Estamos felizes em compartilhar com você nossa experiência e esperamos que você entenda melhor o que é necessário para fazer um serviço como o Binance funcionar.
Leia o seguinte artigo para mais informações sobre nossa infraestrutura tecnológica:
(Blog da Binance) Usando MLOps para construir um pipeline de aprendizado de máquina ponta a ponta em tempo real
(Binance Blog) Conheça o CTO: Rohit reflete sobre criptografia, blockchain, Web3 e seu primeiro mês na Binance
Referências
[1] Disruptor LMAX
[2] RocksDB
[3] O Algoritmo de Consenso da Jangada


