
How Binance Ledger Powers Your Binance Experience
Main Takeaways
Binance’s Ledger stores account balances and transactions, while also enabling services to make transactions.
It creates the conditions needed for high throughput, 24/7 availability, and bit-level data accuracy.
Binance Ledger’s role behind the scenes makes it one of Binance’s most important technologies. Learn exactly how it works and the problems it’s solving in the operation of the world’s largest crypto exchange here.

Ever wondered exactly what makes Binance tick? With the need to process millions of transactions daily across a massive userbase, it’s worth taking a look at what Binance has got under the hood.
Underpinning Binance’s technical operations is its Ledger. The Ledger stores accounts’ balances and transactions while enabling services to make transactions.
Binance Has High Requirements for the Ledger
As you can imagine, the requirements for the Ledger are high for it to meet the massive user demand. There are three major points that need to be considered:
High throughput with the ability for a large amount of TPS (transactions per second) at peak times.
24/7 availability without downtime.
Bit-level data accuracy, with no fund loss or transaction errors.
Let’s look at an example of a basic entry on the Ledger. Here’s a common transaction in which account 1 transfers 1 BTC to account 2.
Balance before the transaction:
table-1
Balance after the transaction:
table-2
In this transaction, there are two commands:
Account 1 -1 BTC
Account 2 +1 BTC
When the transaction is made, two balance logs will be stored for audit and reconciliation.
table-3
The Standard Industry Solution
One standard industry Ledger solution is based on a relational database. Returning to the previous example, the transaction’s two commands can be translated into two SQL statements and executed in a database transaction (table-4).
table-4
The advantages of the solution
It’s quite simple to implement.
It’s easy to apply common database tuning techniques such as read/write splitting and sharding to improve performance.
It’s not hard for the devops to recover from failover, as well as monitor and maintain a commercial database.
The disadvantages of the solution
TPS will drop sharply when there are race conditions due to row locks.
It’s hard to scale horizontally to improve the performance.
The Hot Account Problem
Unfortunately for Binance, the industry solution demonstrated above doesn’t meet its high requirements. When a transaction occurs, it must hold the row locks of every row involved. While some accounts have relatively few transactions to deal with, there are, of course, busy accounts with many concurrent transactions. In this case, only one transaction is able to hold the account’s row lock.
The other transactions can then do nothing but wait for the lock to be released. We call this situation a hot account problem, and internal tests show TPS will drop at least 10 times in this situation. You can see this issue in table 5 below.
Hot account example:
table-5
Binance’s Ledger Solution
How do we solve the hot account problem?
One possible solution to our issue is to innovatively convert the multi-threaded model to a single-threaded mode. This then avoids the race condition problem, and, as a result, there won’t be a hot account issue.
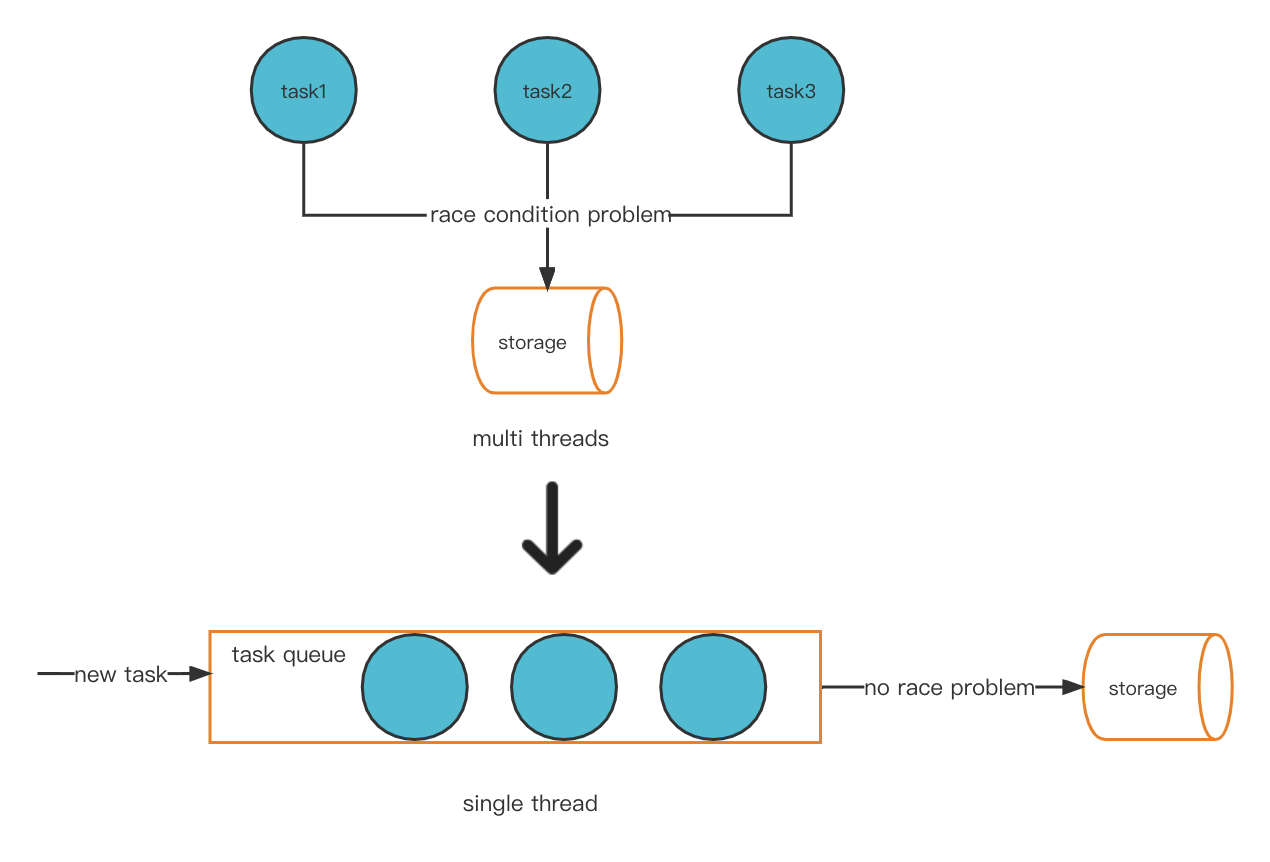
New thread model
Message-based communication
After implementing our new thread model, a communication issue needs to be solved. The state machine layer is single-thread, but the network layer is multi-threaded, so how do we communicate efficiently between the two?
A Disruptor [1] is the next step in the puzzle. It creates a lock-free, high-performance queue based on a ring buffer design.
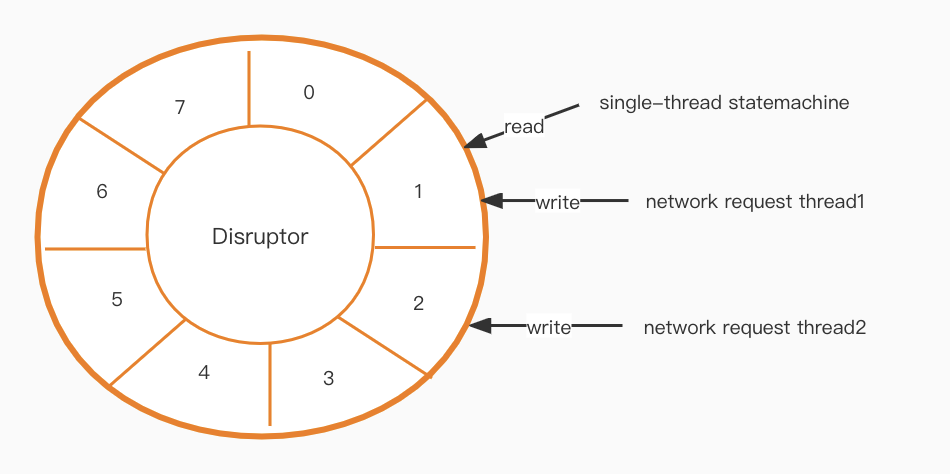
High availability
So far, we have achieved high performance by using an in-memory model and RocksDB [2] local storage. But, once again, a new challenge occurs. Now we need to take care of high data availability.
To ensure data consistency among nodes, we use a Raft Consensus Algorithm [3]. This means that the number of data backups equals the number of non-leader nodes present. The algorithm also ensures the system will still work with at least half of the nodes being healthy, to help provide high service availability.
Raft Domain Roles:
Leader. Leader processes all client requests and replicates the operation to all followers.
Follower. Followers follow the leader for all operations. If the leader fails, one of the followers will be elected as the new leader.
Learner. Learners are non-voting followers that send each idempotent/transaction change record to other services.
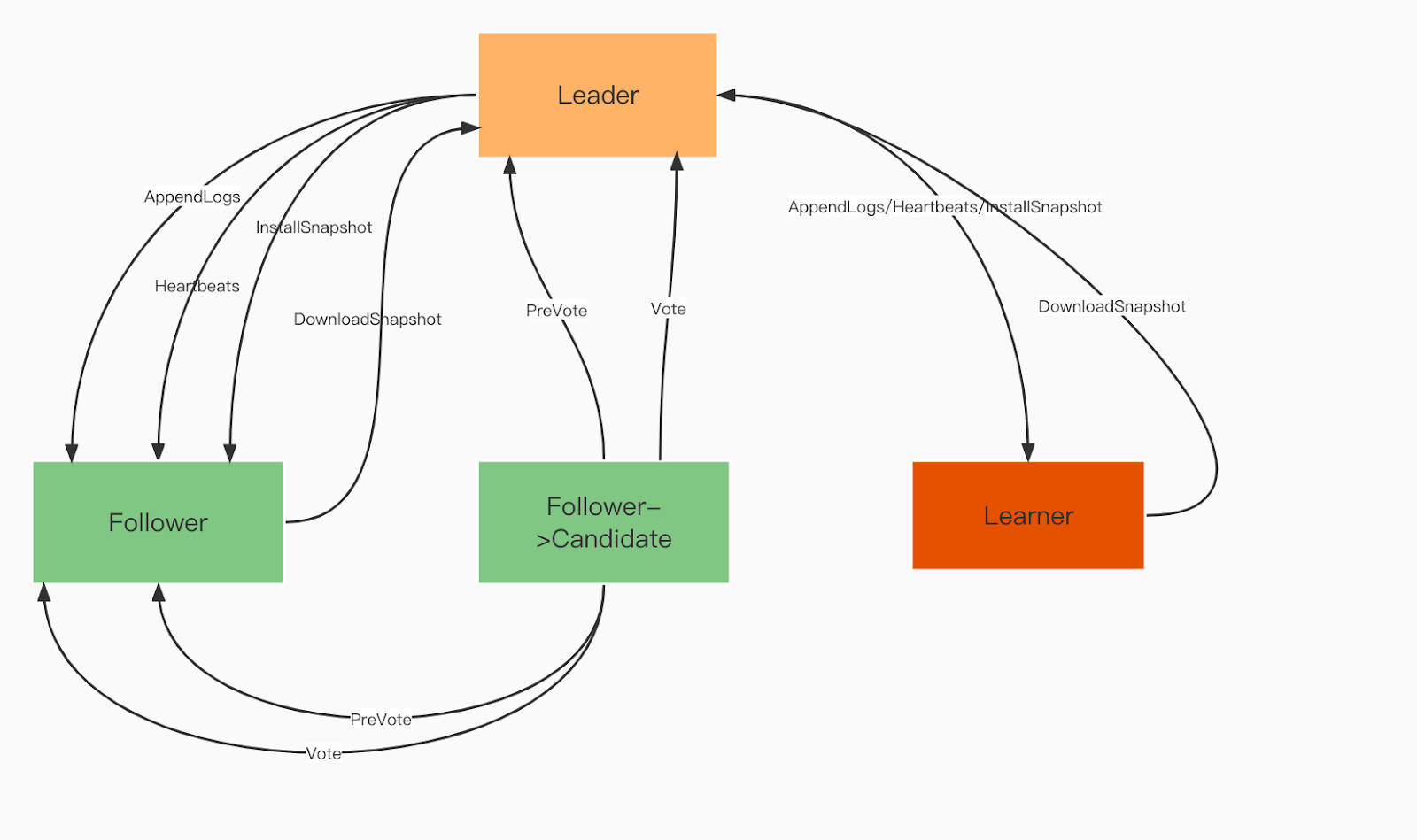
Raft domain roles
CQRS (Command Query Responsibility Segregation)
Another key criteria we want to ensure is the Ledger’s higher write performance and capability for more diverse query conditions. For this, we need to create different domains. The raft domain provides more efficient writing based on rocksdb+raft, and the view domain listens to the messages of the raft domain and saves them to the relational database for external queries. We also can implement command query responsibility segregation at the architectural level.
Ledger architecture
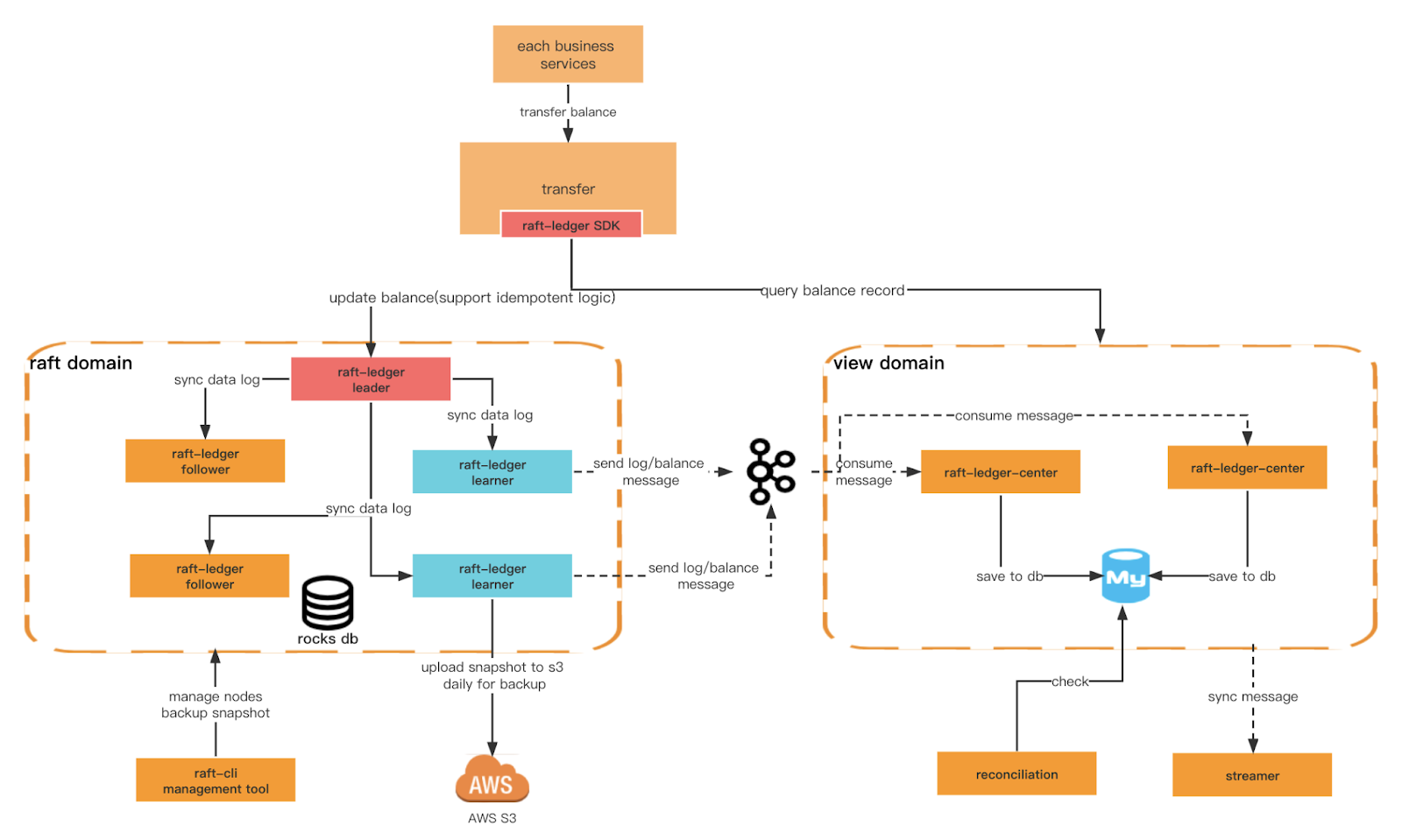
Overall architecture
Terms between Raft and Ledger:
table-6
View Domain Roles
Raft ledger center
Consume the message produced by the learner and store the transaction and balance data in MySQL for querying purposes.
Request processing
A transaction request will first go through the network layer, the ledger layer (request handler), and the raft layer (raft log sync). It will then go back to the ledger layer (state machine), network layer (response handler), and finally return a response to the client.
The data is passed via the queue between the two layers.
Network Layer – Deserialize the rpc request and put it into the request queue.
Ledger Layer – Get the request from the queue and prepare the context. It will then put the request metadata into the raft queue.
Raft Layer – Get the request metadata from the raft queue and synchronize it among all the followers. It will then put the result into the apply queue.
Ledger Layer – Get the data from the apply queue and update the state machine. It will then put the result into the response queue.
Network Layer – Get the result from the response queue and construct and serialize response data before returning it to the client.
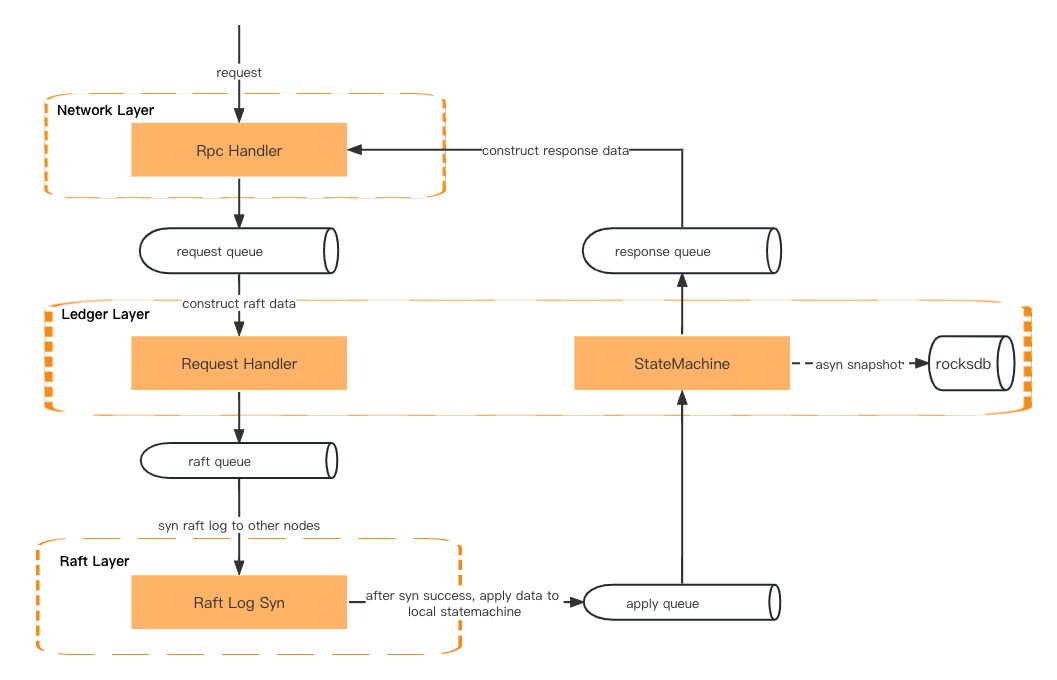
Request processing
Data recovery
Each Ledger node will trigger a generic snapshot based on a time period. Additionally, we also implement a consistent snapshot. Each node is triggered at the same raft log index to ensure that the state machine is exactly the same when each node triggers a snapshot. The snapshot will then be uploaded to S3 for verification by Checker and as a cold backup.
When Ledger restarts, it reads the local snapshot and rebuilds the state machine. Then it replays the local raft log and synchronizes the latest log from the leader until it catches up with the latest index. If the local snapshot or raft log does not exist, it will be obtained from the leader.
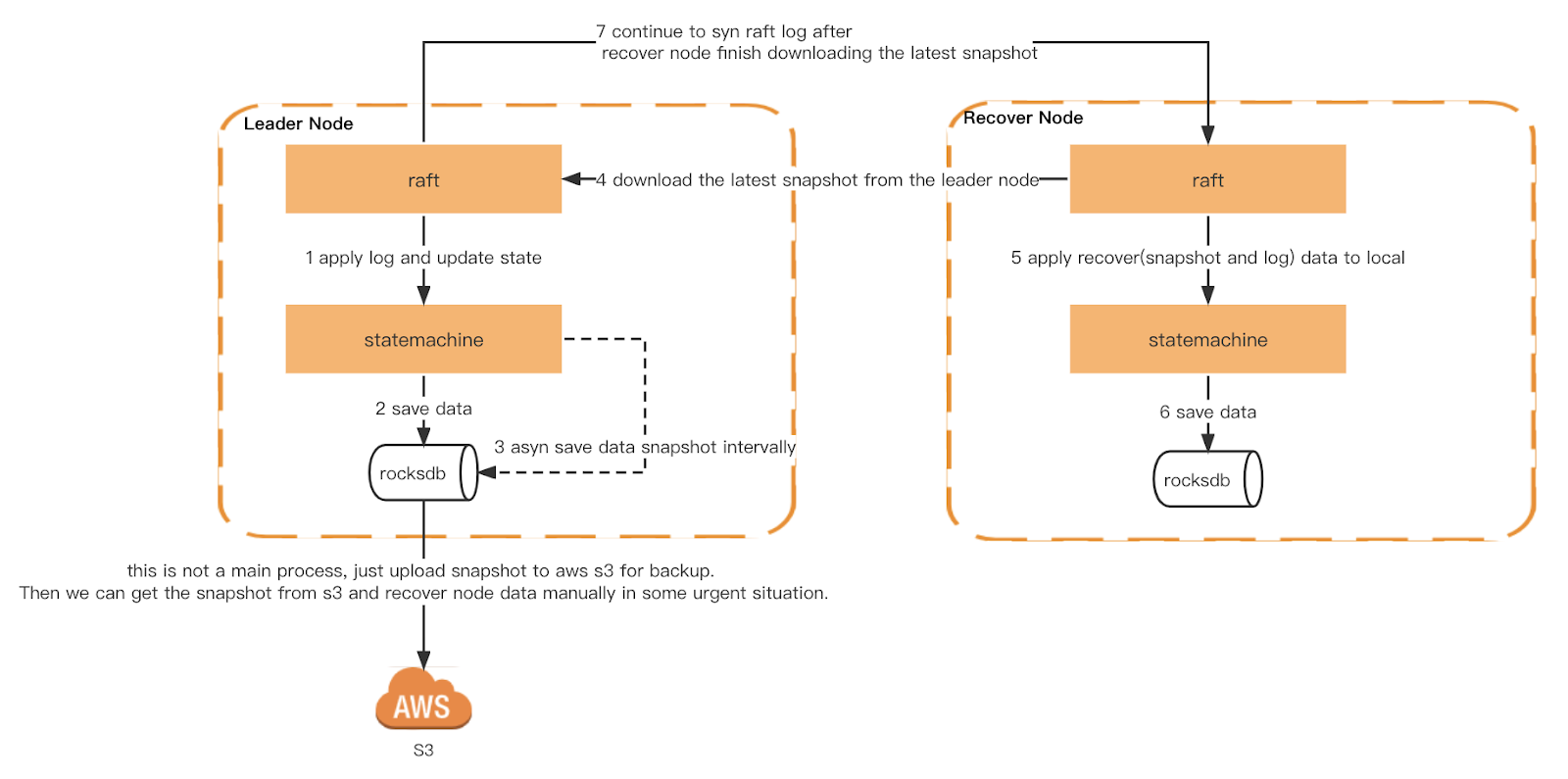
Snapshot & Recovery
Disaster tolerance
To improve availability and fault tolerance, Ledger nodes are deployed in different zones. As long as more than half the nodes are healthy, the data won't be lost and the failover will be completed in one second.
Even if the entire cluster fails, of which there is a very low probability, we can still restore the cluster through the consistent snapshot stored in Amazon S3 and retrieve the latest lost data through the downstream system.
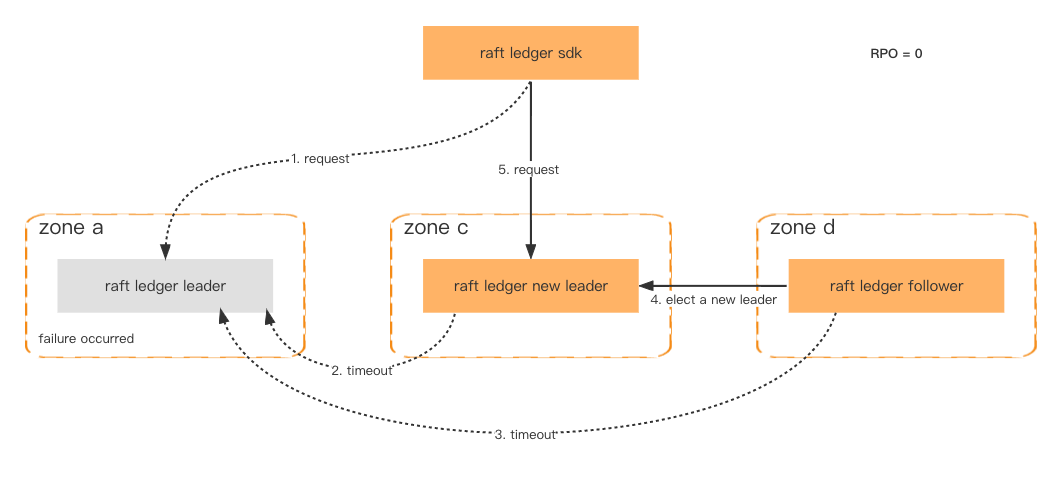
Fault tolerance
Performance
The following table shows the hardware spec for the performance test
Internal tests prove that a 4-node cluster (one leader, two followers and one learner) can process more than 10,000 TPS. By design, the cluster processes all of the transactions one by one. There is no lock and race condition at all. So in the hot account scenario, the TPS is as high as it is in the normal scenarios.
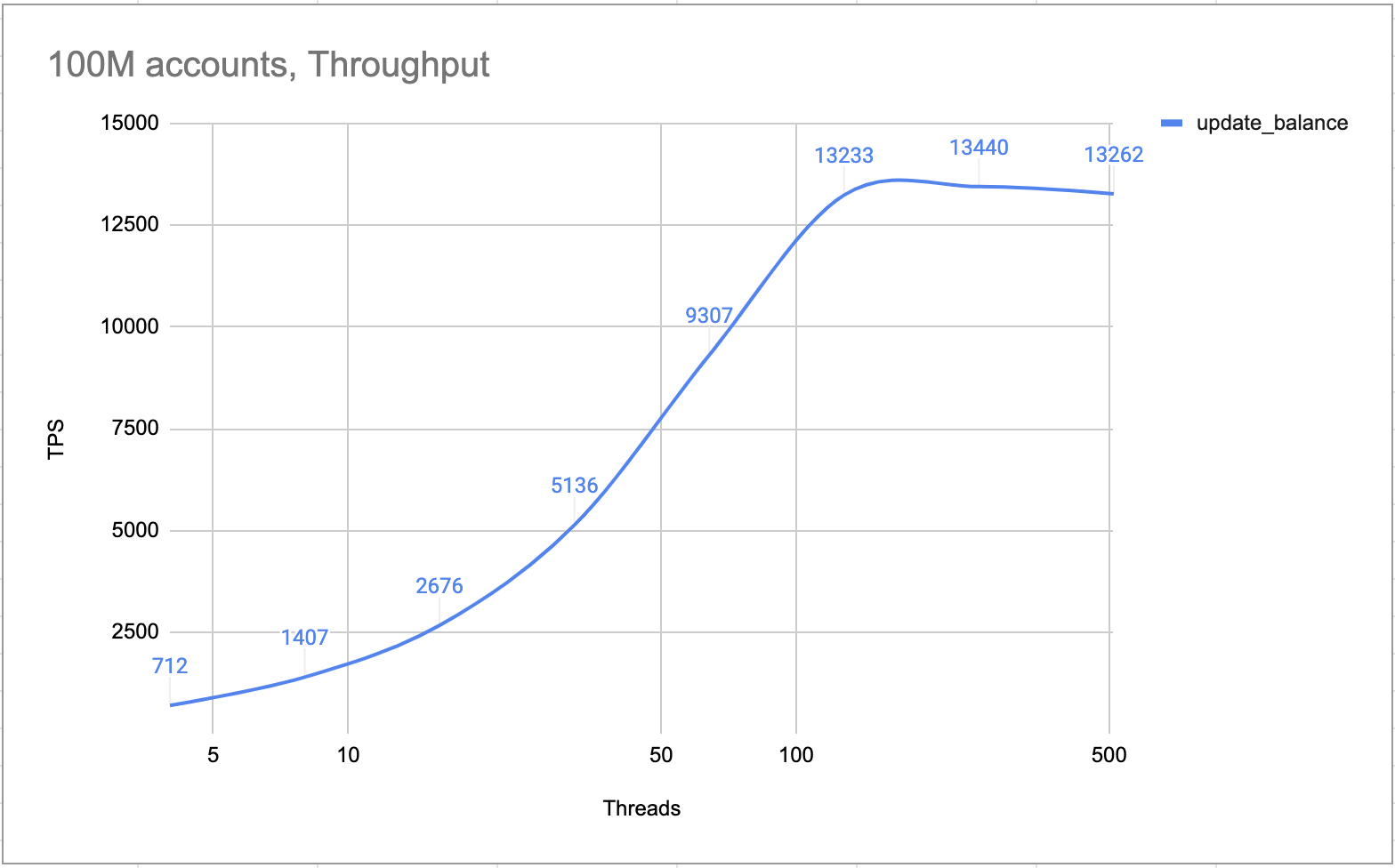
Hot account TPS
The following figure shows the latency of each transaction. Most transactions could be finished within 10 ms. The slower transactions could be finished within 25ms.
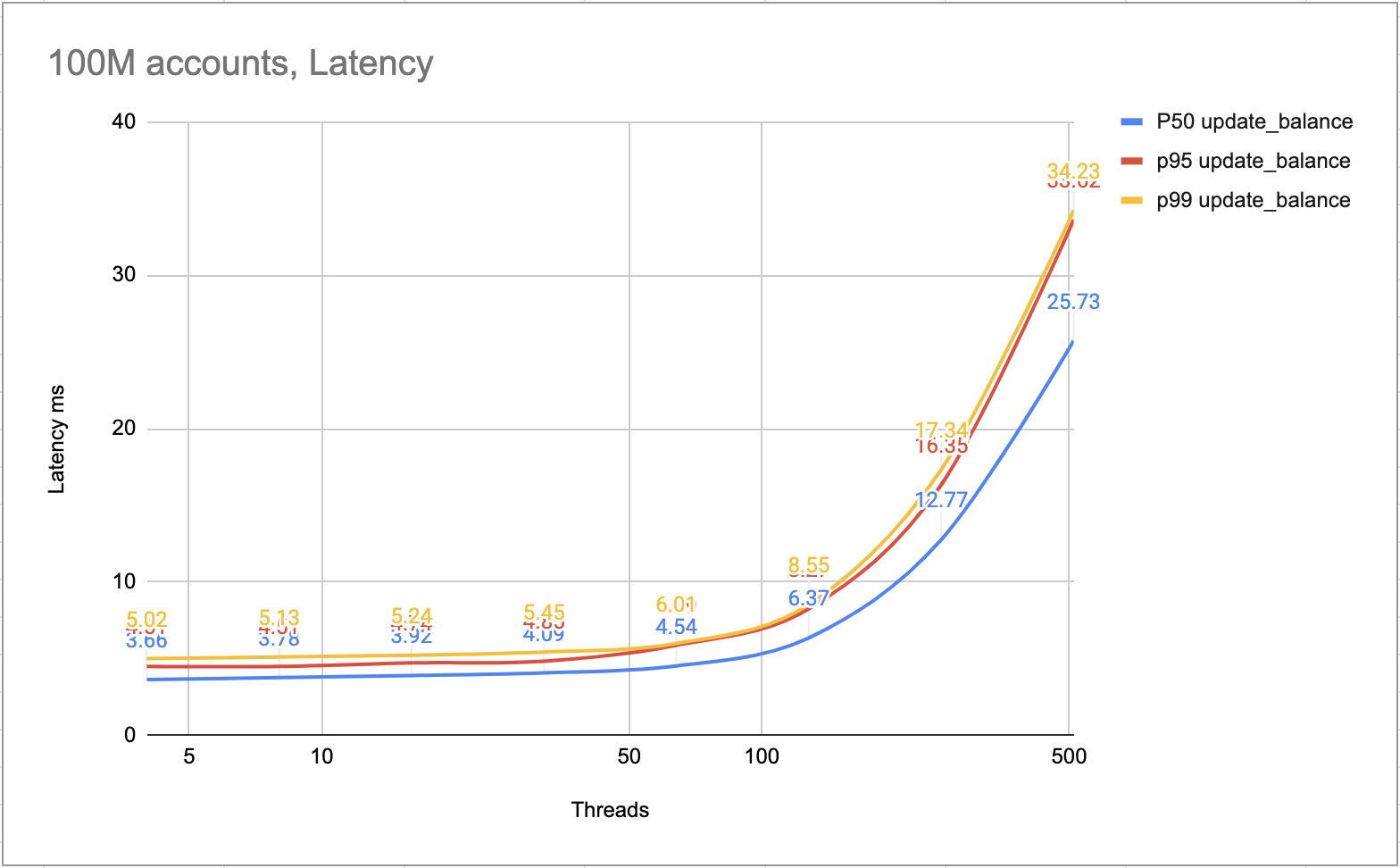
Latency ms
Powering our Services With Binance Ledger
As you’ve seen, the traditional industry’s answer to the hot account problem doesn’t satisfy the needs of Binance and its customers. By using an approach designed specifically for Binance’s infrastructure, we’ve ended up with one of the smoothest exchange and product experiences available. We’re happy to now share with you our experience and hope you understand better just what goes into making a service like Binance work.
Read the following article for more information on our technological infrastructure:
(Binance Blog) Using MLOps to Build a Real-time End-to-End Machine Learning Pipeline
(Binance Blog) Meet The CTO: Rohit Reflects on Crypto, Blockchain, Web3, and His First Month at Binance
References
[1] LMAX Disruptor
[2] RocksDB