
GPT-4 は、さまざまなベンチマークで GPT-3.5 よりも高いスコアを達成しました。これは、機械が本来設計された問題を解決できるだけでなく、大学生よりも優れた能力を発揮できることを証明するものであり、機械にとって大きな進歩です。

この結果を見る際に考慮すべきことがいくつかあります。まず、GPT-4 はこれらの試験のために特別なトレーニングを受けていません。GPT-4 は、公開されている最新のテスト (オリンピックや AP 自由回答問題の場合) を使用するか、2022~2023 年版の模擬試験を購入して試験に臨みました。次に、GPT-4 は異なる一連の原則とアルゴリズムに基づいて動作するため、GPT-4 のパフォーマンスが必ずしも人間の受験者の能力を反映しているとは限らないことに注意することが重要です。
これは、機械が人間のような知能を持つだけでなく、人間を上回ることもできることを示した大きな成果です。これにより、機械がますます複雑なタスクを引き受けられる未来への道が開かれ、最終的には機械が私たちの日常生活を支援できる未来につながります。
 GPT-4 が特定のタスクで人間を上回る能力を持っていることから、人工知能の将来とそれが雇用市場に及ぼす潜在的な影響について疑問が生じます。また、AI が倫理的かつ責任を持って使用されるようにするために、この分野での継続的な研究開発の必要性も浮き彫りになっています。詳しくはこちら: 2023 年に最も期待される 5 つのテキストから画像への AI モデル
GPT-4 が特定のタスクで人間を上回る能力を持っていることから、人工知能の将来とそれが雇用市場に及ぼす潜在的な影響について疑問が生じます。また、AI が倫理的かつ責任を持って使用されるようにするために、この分野での継続的な研究開発の必要性も浮き彫りになっています。詳しくはこちら: 2023 年に最も期待される 5 つのテキストから画像への AI モデル
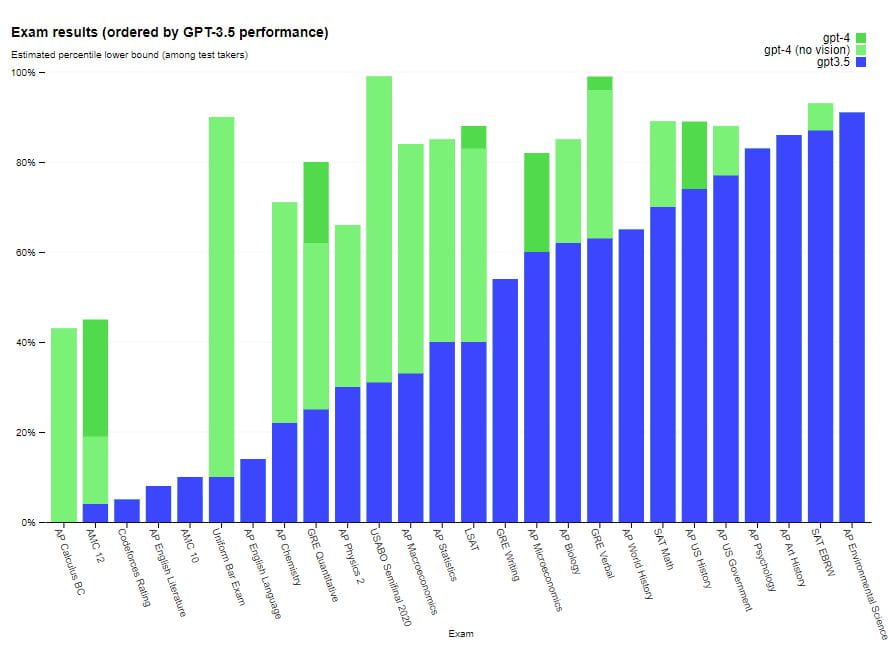
例えば、GPT-4は模擬司法試験で受験者の上位10%のスコアで合格していますが、GPT-3.5のスコアは下位10%でした。GPT-4のこの大幅なパフォーマンス向上は、トレーニングデータの増大とアーキテクチャの改善によるものです。自然言語処理や自動ライティングなど、さまざまな分野で幅広い応用が期待されています。
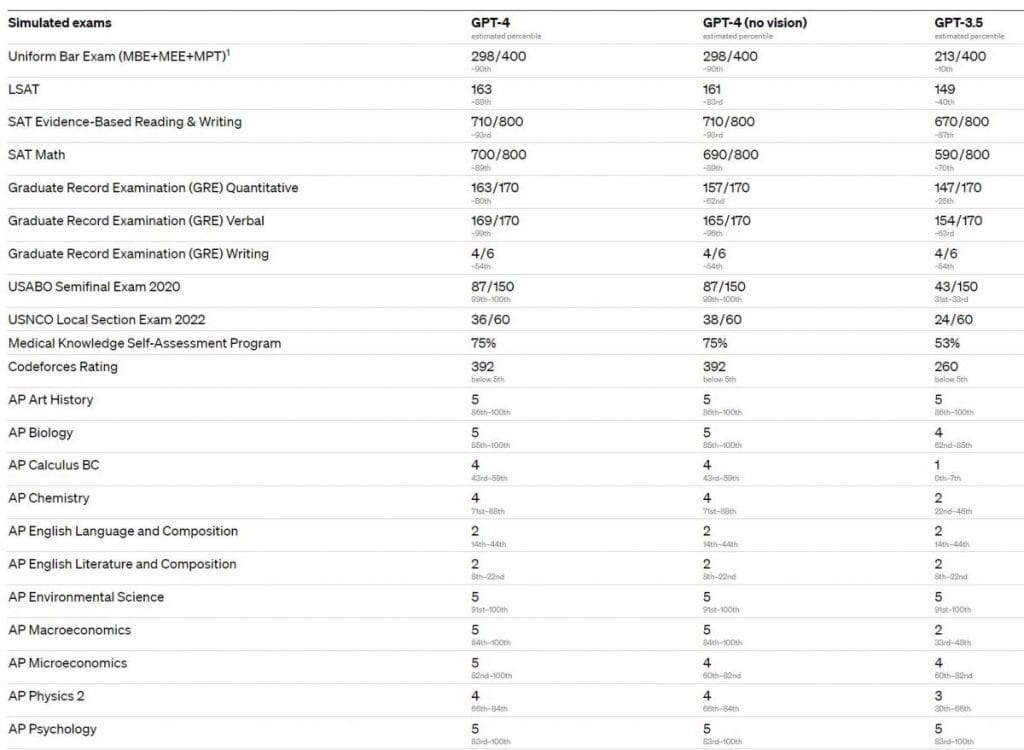 GPT-4 は、これらの専門試験や学術試験のほとんどで人間レベルのパフォーマンスを発揮します。特に、GPT-4 は模擬試験に合格し、受験者の上位 10% のスコアを獲得しました。試験におけるモデルの能力は、主に事前トレーニング プロセスに由来するもので、RLHF による影響は大きくありません。多肢選択問題では、ベース GPT-4 モデルと RLHF モデルの両方が、テストされた試験の開発者全体で平均して同等のパフォーマンスを発揮しました。
GPT-4 は、これらの専門試験や学術試験のほとんどで人間レベルのパフォーマンスを発揮します。特に、GPT-4 は模擬試験に合格し、受験者の上位 10% のスコアを獲得しました。試験におけるモデルの能力は、主に事前トレーニング プロセスに由来するもので、RLHF による影響は大きくありません。多肢選択問題では、ベース GPT-4 モデルと RLHF モデルの両方が、テストされた試験の開発者全体で平均して同等のパフォーマンスを発揮しました。
追加のトレーニング プロトコルやベンチマーク固有の設計を使用する可能性のあるモデルや既存の大規模言語モデルを含む、最先端 (SOTA) モデルの大部分は、GPT-4 によって大幅に上回られています。
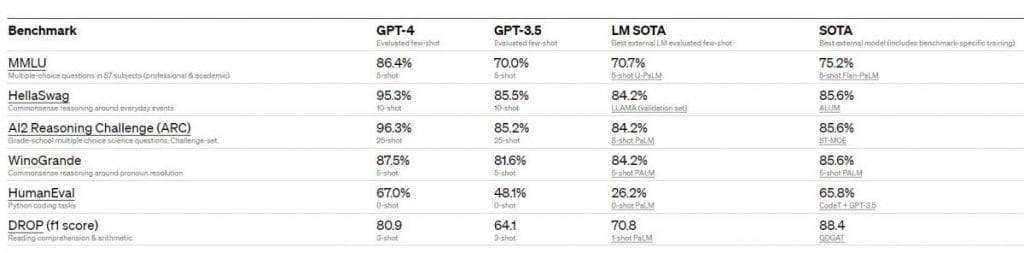 学術基準の観点から見た GPT-4 のパフォーマンス。開発者は、GPT-4 を、LM 評価された少数ショットの最高の SOTA およびベンチマーク固有のトレーニングによる最高の SOTA と比較しています。DROP を除いて、GPT-4 はすべてのベンチマークで現在のすべての LM を上回り、ベンチマーク固有のトレーニングによる SOTA も上回っています。
学術基準の観点から見た GPT-4 のパフォーマンス。開発者は、GPT-4 を、LM 評価された少数ショットの最高の SOTA およびベンチマーク固有のトレーニングによる最高の SOTA と比較しています。DROP を除いて、GPT-4 はすべてのベンチマークで現在のすべての LM を上回り、ベンチマーク固有のトレーニングによる SOTA も上回っています。
社内では、開発者が GPT-4 を利用しており、プログラミング、販売、サポート、コンテンツ モデレーションなどの活動に大きな影響を与えています。現在、開発者がこれを使用して人間による AI の結果のレビューを支援しており、当社の調整方法の第 2 段階が進行中です。
MMLU(Massive Multi-Task Language Understanding)データセットには、さまざまなタスク(数学、生物学、法律、社会科学、人文科学などを含む 57 のドメインにわたる)における言語理解に関する非常に幅広いトピックからの質問が含まれています。質問には 4 つの回答の可能性があり、そのうちの 1 つが正解です。つまり、ランダムに推測すると、25% の正答率の結果が示されます。質問の例と難易度については、下の図を参照してください。平均的な採点者(つまり、科学者でも教授でもなく、マークアップとして副業をしている普通の人)は、質問の 35% に正しく回答しますが、専門家は +/- 90% のスコアに達することができます。
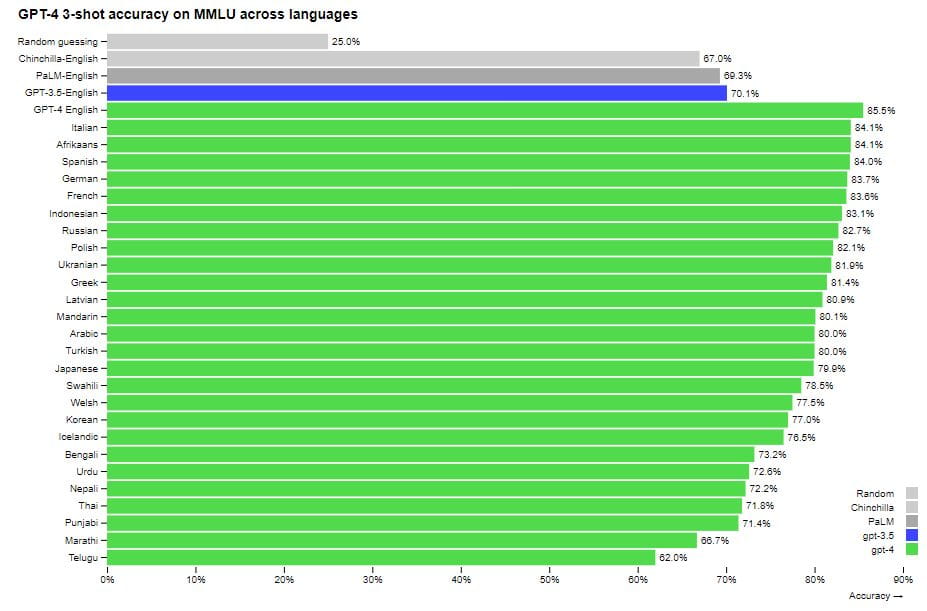 MMLU における英語の以前のモデルと比較した、さまざまな言語での GPT-4 のパフォーマンス。GPT-4 は、ラトビア語、ウェールズ語、スワヒリ語などのリソースの少ない言語を含む、調査した言語の大部分で、既存の言語モデルの英語のパフォーマンスを上回っています。詳細: AI 搭載の Bing を Google よりも使用すべき 5 つの理由
MMLU における英語の以前のモデルと比較した、さまざまな言語での GPT-4 のパフォーマンス。GPT-4 は、ラトビア語、ウェールズ語、スワヒリ語などのリソースの少ない言語を含む、調査した言語の大部分で、既存の言語モデルの英語のパフォーマンスを上回っています。詳細: AI 搭載の Bing を Google よりも使用すべき 5 つの理由
もともと、データセット全体は英語でした。しかし、質問と回答が他の言語、特にあまり一般的でない言語に翻訳されたらどうなるでしょうか? モデルは、それらの言語でも何らかの形で機能するでしょうか? このテストでは、翻訳に Microsoft Azure Translate サービスを使用しました。翻訳は完璧ではなく、重要な情報が失われる場合もあります。ただし、この場合でも、GPT-4 は他の言語でも優れたパフォーマンスを発揮します。MMLU の翻訳バージョンでは、調査した 26 言語のうち 24 言語で、GPT-4 は他の大規模モデル (Google を含む) の英語レベルを上回っています。
さらに、GPT-4 は、ChatGPT が英語で行ったよりも珍しい言語で優れたパフォーマンスを発揮します (ChatGPT は 70.1% のスコアを達成しましたが、新しいモデルのタイ語のスコアは 71.8% でした)。英語でのテストのスコアが最も高く、GPT-4 は、Google の最大の PaLM を含む他のモデルよりも 10% 優れたパフォーマンスを発揮しました。GPT-4 は 86.4% のスコアを達成しましたが、専門家のグループは 90% でした。
2023 年の夏までに、AI は ChatGPT のおかげで新たなレベルのパワーに到達するかもしれません。ChatGPT は、GPT-4 アルゴリズムを使用し、GPT-3 を 570 倍上回るチャットボットです。ChatGPT の成功には、より「人間らしい」設計や、最先端のデータ マイニングと自然言語処理を使用して有効性と精度を高めるなど、さまざまな要素が貢献しています。
Microsoft と OpenAI は 1 月に協力関係の更新と、Bing 検索に AI 強化検索機能を導入する計画を発表しました。非常に洗練された GPT3.5 モデルに代わる GPT4 がリリースされたばかりで、Bing 検索の自然言語クエリの理解能力を大幅に向上させ、より正確な結果を提供できる可能性があります。何か問題が発生した場合に備えて、適切なバックアップ プランを用意しておくことをお勧めします。
関連ニュースをもっと読む:
ChatGPT のご紹介: Google を倒せる AI
ChatGPTがウォートンMBA試験に合格
T9 時代と GPT-1 から ChatGPT までのチャットボットの進化
この記事「GPT-4 はさまざまな研究ベンチマークで GPT-3.5 を全面的に上回る」は、Metaverse Post に最初に掲載されました。