
3D アバター拡散は、人間の顔の 2D 画像を 1 枚取得して 3 次元 (3D) アバターを作成できる機械学習アルゴリズムです。その後、アバターを使用して、仮想現実 (VR) または拡張現実 (AR) 体験を作成したり、ゲームやその他の目的で人物の現実的な 3D ビューを提供したりすることができます。
この拡散モデルは Microsoft Research の研究者チームによって開発され、ジャーナル arXiv に掲載された論文で説明されています。

3D アバターの拡散は、拡散モデルと呼ばれる一種の機械学習アルゴリズムに基づいています。拡散モデルは生成モデルです。つまり、トレーニング データに似た新しいデータを生成できます。 2D 画像から 3D 画像を生成するために拡散モデルはこれまでにも使用されてきましたが、ADM は単一の 2D 画像からリアルな 3D アバターを生成できる最初の拡散モデルです。
モデルをトレーニングするために、研究者らは 200,000 を超える 3D 顔モデルのデータセットを使用しました。データセットには、肌の色、髪型、顔の特徴が異なるさまざまな顔が含まれていました。その後、ADM は 2D 画像と 3D 顔モデルの間の関係を学習し、単一の 2D 画像からリアルな 3D アバターを生成することができました。
このモデルを使用して、別の角度から撮影した写真からアバターを生成することもできます。
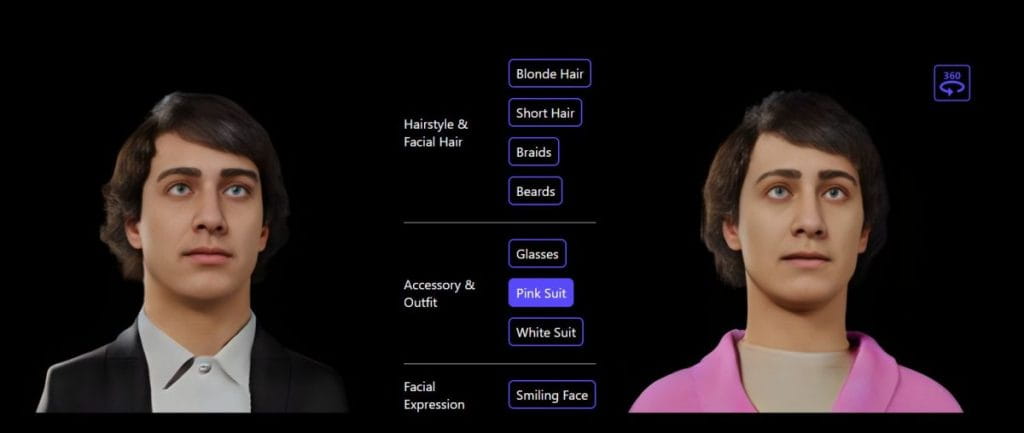 パーソナライズされた 3D アバターの場合、Rodin モデルはテキストガイドによる操作を提供します。自然言語編集は、さまざまな 3D アバターの機能を直感的に変更する方法です。
パーソナライズされた 3D アバターの場合、Rodin モデルはテキストガイドによる操作を提供します。自然言語編集は、さまざまな 3D アバターの機能を直感的に変更する方法です。
この研究では、拡散モデルを使用して神経放射フィールドとして表現される 3D デジタル アバターを自動的に作成する 3D 生成モデルを提案します。 3D に関連するメモリと処理要件は法外であるため、高品質のアバターに必要な豊富な機能を作成することは大きな問題です。開発者は、ロールアウト拡散ネットワーク (Rodin) がこの問題に対処することを提案しています。
 性別、年齢、人種、表情、表情など、世代の多様性に優れたモデルです。
性別、年齢、人種、表情、表情など、世代の多様性に優れたモデルです。
このネットワークは、神経放射フィールドの多数の 2D 特徴マップを単一の 2D 特徴平面に展開し、そこでモデルが 3D 対応の拡散を実行します。 Rodin モデルは 3D 対応の畳み込みを使用しており、3D での元の関係に従って 2D フィーチャ平面に投影されたフィーチャに注目し、3D での拡散の整合性を維持しながら、必要とされる計算効率を提供します。
AI について詳しく読む:
VALL-E: Microsoft の新しいゼロショット テキスト読み上げモデルは、全員の声を 3 秒で複製できる
Microsoft の VALL-E は史上最も危険な詐欺ソフトウェアとみられる
アーティストはアートを保護する盗難防止スクリプトを作成し、AI ジェネレーターと同じウォーターマークを使用します
2023 年の Microsoft と Google: AI 巨人間の今年の主要対決
Microsoftが人物の1枚の写真から3Dアバターを構築できる普及モデルをリリースしたという記事が最初にMetaverse Postに登場した。