

Il walrus appare quando un team è già un po' nervoso riguardo al significato di "dati" nel proprio stack. Non tweet. Non metadati. Veri blob. Quelli che fanno sentire il prodotto pesante nel momento in cui smetti di fingere che la larghezza di banda sia infinita.
In una riunione qualcuno lo dirà come una sentenza... "I dati erano disponibili".
Ho imparato a trattare questa frase come un allarme antincendio. Si attiva solo quando qualcuno cerca di ridurre due problemi diversi in una sola parola confortevole.
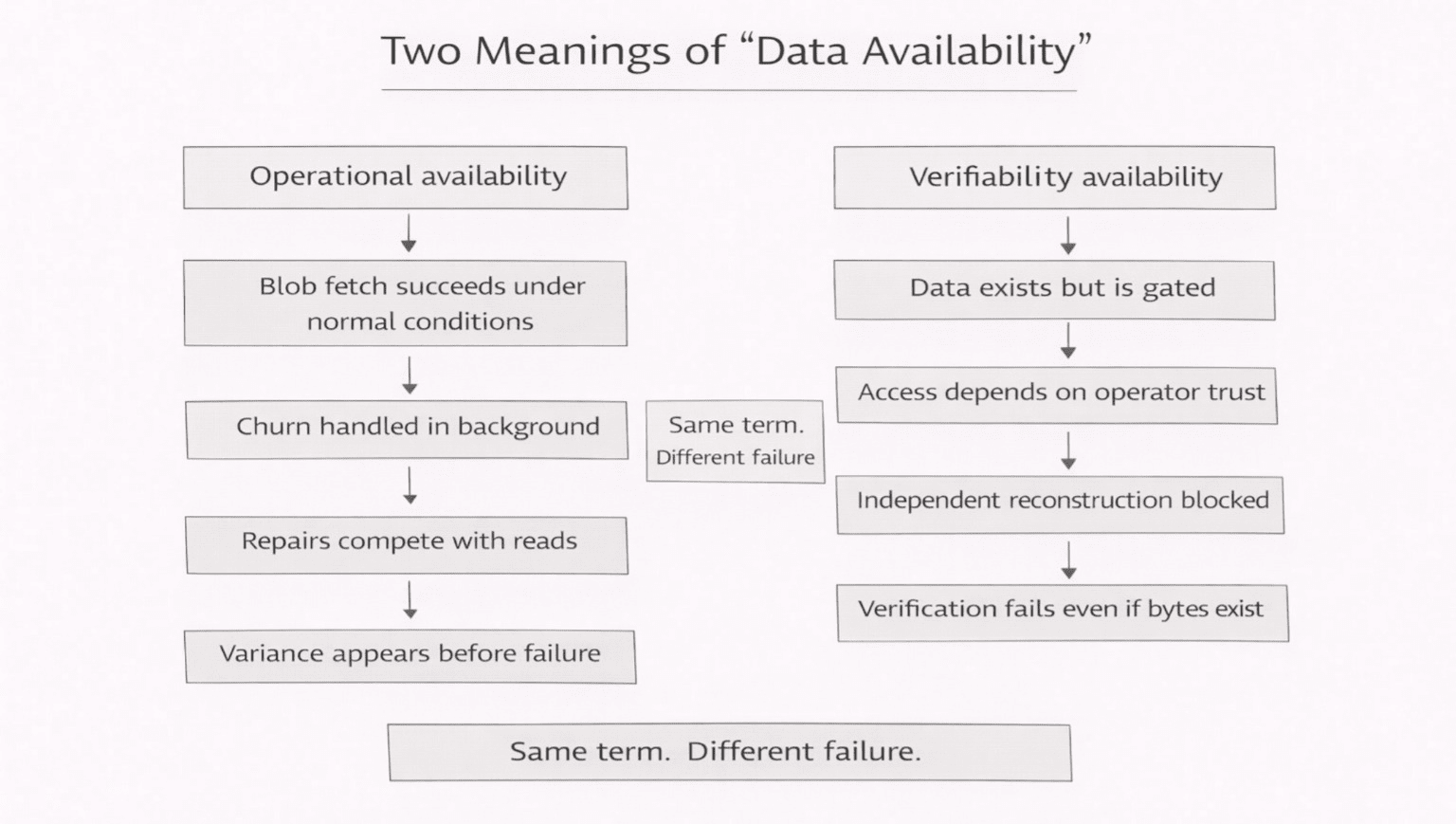
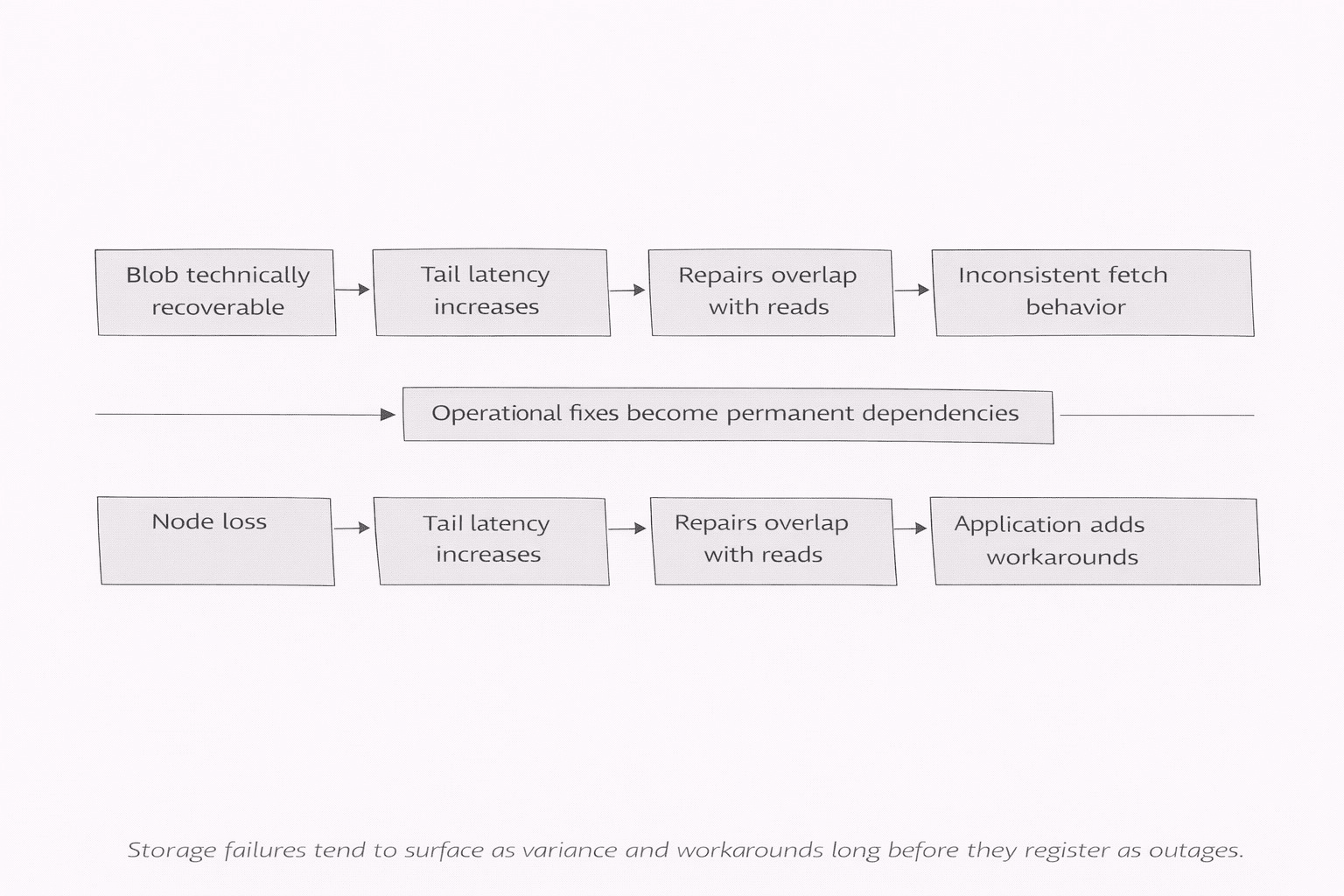
A volte 'disponibile' significa semplicemente che un utente può recuperare il blob mentre la rete funziona normalmente e fastidiosamente. I pezzi si spostano. I nodi cambiano. Il lavoro di riparazione avviene in background come la gravità. Se il blob torna comunque, nessuno applaude. Continuano semplicemente a rilasciare aggiornamenti. Se torna in modo inconsistente, nessuno scrive un manifesto. Iniziano semplicemente ad aggiungere rail. Cache. Alternative. Piccole vie di fuga che diventano permanenti perché il supporto non accetta la filosofia come soluzione.
Questo è ciò su cui viene giudicato il Protocollo Walrus. Non "è decentralizzato". Se rimane noioso quando il sistema non è di buon umore.
Altre volte 'disponibile' riguarda qualcosa di più freddo... può qualcuno verificare la storia di un rollup senza chiedere permesso. Non si tratta di un utente che aspetta che un'immagine si carichi. L'avversario non è il churn. È la ritenzione. Una parte decide che i dati esistono da qualche parte, ma non per te, non ora, a meno che tu non ti fidi di loro.
Se questo è il tuo modello di minaccia, il ritardo è fastidioso ma sopportabile. Nascosto non lo è.
I team confondono questi perché entrambi i problemi indossano lo stesso distintivo. "Disponibilità dei dati". Suona pulito. Non lo è. È una parola abbreviata che i team usano quando nessuno vuole nominare il vero fallimento di cui hanno paura.
Settimane calme ti permettono di cavartela.
Lo stress non lo fa.
Quando si tratta di un incidente di archiviazione, l'imbarazzo è silenzioso e operativo. Non 'perdi' il blob in modo drammatico. Ottieni prima il fallimento più debole... varianza. Latenza finale che si gonfia. Riparazioni che competono con le letture nel momento sbagliato. Un blob che è tecnicamente recuperabile ma inizia a sembrare condizionale. Il team del prodotto non discute di crittografia. Discutono se possono lanciare senza sorvegliare l'archiviazione.
Quando si tratta di un incidente di verifica, l'imbarazzo è più brutto. Non è "è caricato in ritardo". È "può qualcuno ricostruire indipendentemente cosa è successo." Se la risposta è "non a meno che non ci fidiamo del sequenziatore", non hai avuto disponibilità nel solo senso che contava. Avevi una promessa.
Walrus non ha bisogno di essere trascinato in quel secondo combattimento. Non è costruito per vincerlo. Non è costruito per far sopravvivere oggetti di grandi dimensioni nel primo combattimento... quello in cui la rete continua a muoversi e gli utenti continuano a cliccare comunque.
E i livelli di DA non devono fingere di essere archiviazione. Pubblicare byte per i verificatori non è lo stesso lavoro che mantenere i blob utilizzabili per applicazioni reali. Uno riguarda il non essere tenuti in ostaggio. L'altro riguarda il non trasformare il tuo supporto in un ciclo di ripetizione.
Mescolali, e non otterrai un'esplosione drammatica. Fallisci solo il controllo sbagliato per primo. #Walrus $WAL @Walrus 🦭/acc
