
Penulis: Yiping, IOSG Ventures
tulis di depan
Ketika model bahasa besar (LLM) menjadi semakin populer, kami melihat banyak proyek yang mengintegrasikan kecerdasan buatan (AI) dan blockchain. Kombinasi LLM dan blockchain semakin meningkat, dan kami juga melihat peluang bagi kecerdasan buatan untuk berintegrasi kembali dengan blockchain. Salah satu yang patut disebutkan adalah pembelajaran mesin tanpa pengetahuan (ZKML).
Kecerdasan buatan dan blockchain adalah dua teknologi transformatif dengan karakteristik yang berbeda secara mendasar. Kecerdasan buatan memerlukan daya komputasi yang kuat, yang biasanya disediakan oleh pusat data terpusat. Meskipun blockchain menyediakan komputasi terdesentralisasi dan perlindungan privasi, blockchain berkinerja buruk pada tugas-tugas yang memerlukan komputasi dan penyimpanan skala besar. Kami masih mengeksplorasi dan meneliti praktik terbaik untuk integrasi kecerdasan buatan dan blockchain. Kami juga akan memperkenalkan beberapa kasus proyek terkini yang menggabungkan "AI + blockchain" kepada Anda di masa depan.
Sumber: IOSG Ventures
Laporan penelitian ini diterbitkan dalam dua bagian. Artikel ini adalah bagian atas. Kami akan fokus pada penerapan LLM di bidang enkripsi dan mengeksplorasi strategi implementasi aplikasi.
Apa itu LLM?
LLM (Large Language Model) adalah model bahasa terkomputerisasi yang terdiri dari jaringan saraf tiruan dengan sejumlah besar parameter (biasanya miliaran). Model ini dilatih pada teks tak berlabel dalam jumlah besar.
Sekitar tahun 2018, lahirnya LLM mengubah total penelitian tentang pemrosesan bahasa alami. Tidak seperti metode sebelumnya yang memerlukan pelatihan model terawasi khusus untuk tugas tertentu, LLM, sebagai model umum, bekerja dengan baik pada berbagai tugas. Kemampuan dan aplikasinya meliputi:
Memahami dan meringkas teks: LLM dapat memahami dan meringkas sejumlah besar bahasa manusia dan data tekstual. Mereka dapat mengekstrak informasi penting dan menghasilkan ringkasan singkat.
Hasilkan konten baru: LLM memiliki kemampuan untuk menghasilkan konten berbasis teks. Dengan memberikan petunjuk kepada model, model dapat menjawab pertanyaan, teks yang baru dibuat, ringkasan, atau analisis sentimen.
Terjemahan: LLM dapat digunakan untuk menerjemahkan berbagai bahasa. Mereka menggunakan algoritma pembelajaran mendalam dan jaringan saraf untuk memahami konteks dan hubungan antar kata.
Memprediksi dan menghasilkan teks: LLM dapat memprediksi dan menghasilkan teks berdasarkan latar belakang kontekstual, serupa dengan konten buatan manusia, termasuk lagu, puisi, cerita, materi pemasaran, dan banyak lagi.
Aplikasi di berbagai bidang: Model bahasa besar memiliki penerapan luas dalam tugas pemrosesan bahasa alami. Mereka digunakan dalam AI percakapan, chatbots, perawatan kesehatan, pengembangan perangkat lunak, mesin pencari, bimbingan belajar, alat menulis, dan banyak lagi.
Keunggulan LLM mencakup kemampuannya untuk memahami data dalam jumlah besar, kemampuannya melakukan tugas terkait berbagai bahasa, dan potensinya untuk menyesuaikan hasil dengan kebutuhan pengguna.
Aplikasi model bahasa berskala besar yang umum
Karena kemampuan pemahaman bahasa alaminya yang luar biasa, LLM memiliki potensi yang besar, dan pengembang terutama berfokus pada dua aspek berikut:
Memberikan jawaban yang akurat dan terkini kepada pengguna berdasarkan data dan konten kontekstual yang luas
Selesaikan tugas spesifik yang diberikan oleh pengguna dengan menggunakan agen dan alat yang berbeda
Kedua aspek inilah yang menyebabkan menjamurnya aplikasi LLM untuk ngobrol dengan XX. Misalnya, ngobrol dengan PDF, ngobrol dengan dokumen, dan ngobrol dengan makalah akademis.
Selanjutnya dilakukan upaya untuk memadukan LLM dengan berbagai sumber data. Pengembang telah berhasil mengintegrasikan platform seperti Github, Notion, dan beberapa perangkat lunak pencatat dengan LLM.
Untuk mengatasi keterbatasan yang melekat pada LLM, alat yang berbeda dimasukkan ke dalam sistem. Alat pertama adalah mesin pencari, yang memberikan LLM kemampuan untuk mengakses pengetahuan terkini. Kemajuan lebih lanjut akan mengintegrasikan alat-alat seperti WolframAlpha, Google Suites dan Etherscan dengan model bahasa besar.
Arsitektur Aplikasi LLM
Gambar di bawah menguraikan alur aplikasi LLM dalam menanggapi pertanyaan pengguna: Pertama, sumber data yang relevan diubah menjadi vektor tertanam dan disimpan dalam database vektor. Adaptor LLM menggunakan kueri pengguna dan pencarian kesamaan untuk menemukan konteks yang relevan dari database vektor. Konteks yang relevan dimasukkan ke dalam Prompt dan dikirim ke LLM. LLM akan menjalankan perintah ini dan menggunakan alat untuk menghasilkan jawaban. Terkadang, LLM disesuaikan dengan kumpulan data tertentu untuk meningkatkan akurasi dan mengurangi biaya.
Alur kerja aplikasi LLM secara garis besar dapat dibagi menjadi tiga tahap utama:
Persiapan dan penyematan data: Fase ini melibatkan penyimpanan informasi rahasia (seperti memo proyek) untuk akses di masa mendatang. Biasanya, file disegmentasi dan diproses melalui model penyematan, dan disimpan dalam tipe database khusus yang disebut database vektor.
Perumusan dan Ekstraksi Perintah: Ketika pengguna mengajukan permintaan pencarian (dalam hal ini, mencari informasi proyek), perangkat lunak membuat serangkaian Perintah dan memasukkannya ke dalam model bahasa. Prompt terakhir biasanya berisi templat prompt yang dikodekan secara keras oleh pengembang perangkat lunak, contoh keluaran yang valid sebagai contoh beberapa contoh, dan nomor apa pun yang diperlukan yang diperoleh dari API eksternal dan file terkait yang diekstraksi dari database vektor.
Eksekusi dan inferensi perintah: Setelah perintah selesai, perintah tersebut dimasukkan ke model bahasa yang sudah ada sebelumnya untuk inferensi, yang mungkin mencakup API model kepemilikan, sumber terbuka, atau model yang disesuaikan secara individual. Pada tahap ini, beberapa pengembang juga dapat mengintegrasikan sistem operasi (seperti logging, caching, dan validasi) ke dalam sistem.
Membawa LLM ke kriptografi
Meskipun bidang enkripsi (Web3) memiliki beberapa aplikasi yang mirip dengan Web2, mengembangkan aplikasi LLM yang baik di bidang enkripsi memerlukan kehati-hatian khusus.
Ekosistem kripto itu unik, dengan budaya, data, dan konvergensinya sendiri. LLM yang disesuaikan dengan kumpulan data yang dibatasi secara kriptografis ini dapat memberikan hasil yang unggul dengan biaya yang relatif rendah. Meskipun data tersedia berlimpah, terdapat kekurangan kumpulan data terbuka pada platform seperti HuggingFace. Saat ini, hanya ada satu kumpulan data terkait kontrak pintar, yang berisi 113.000 kontrak pintar.
Pengembang juga menghadapi tantangan untuk mengintegrasikan berbagai alat ke dalam LLM. Alat-alat ini berbeda dari yang digunakan di Web2 dan memberikan LLM kemampuan untuk mengakses data terkait transaksi, berinteraksi dengan aplikasi terdesentralisasi (Dapps), dan mengeksekusi transaksi. Sejauh ini, kami belum menemukan integrasi Dapps di Langchain.
Meskipun mengembangkan aplikasi LLM kriptografi berkualitas tinggi mungkin memerlukan investasi tambahan, LLM secara alami cocok untuk dunia kriptografi. Domain ini menyediakan data yang kaya, bersih, dan terstruktur. Ditambah dengan fakta bahwa kode Soliditas umumnya ringkas dan jelas, hal ini memudahkan LLM untuk menghasilkan kode fungsional.
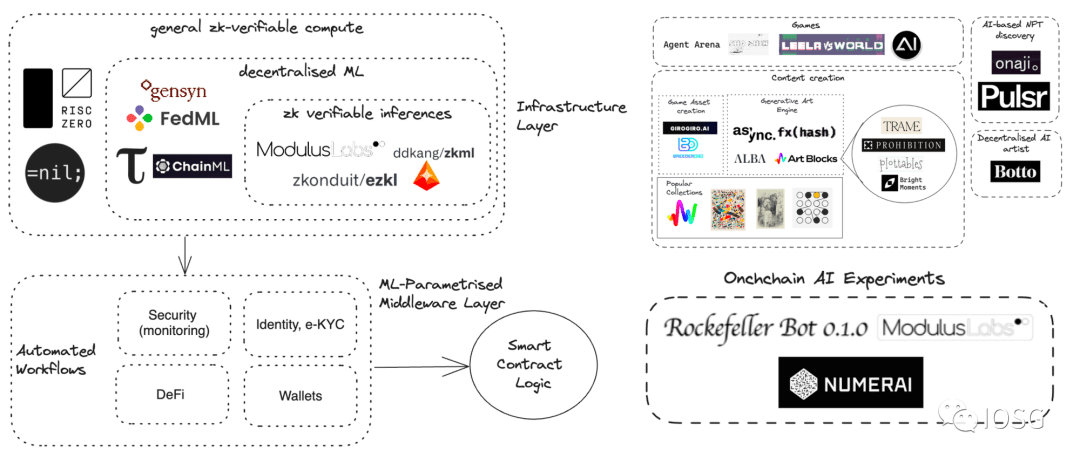
Pada (Bagian 2), kita akan membahas 8 arah potensial dimana LLM dapat membantu bidang blockchain, seperti:
Integrasikan kemampuan AI/LLM bawaan ke dalam blockchain
Analisis catatan transaksi menggunakan LLM
Identifikasi bot potensial menggunakan LLM
Menulis kode menggunakan LLM
Membaca kode menggunakan LLM
Bantu komunitas dengan LLM
Lacak pasar dengan LLM
Analisis proyek menggunakan LLM