
Oleh Siddharth Rao, IOSG Ventures
Tentang kinerja Ethereum Virtual Machine (EVM)
Setiap operasi pada mainnet Ethereum membutuhkan sejumlah Gas. Jika kita mengerahkan semua upaya komputasi yang diperlukan untuk menjalankan aplikasi dasar pada rantai tersebut, Aplikasi akan mogok atau pengguna akan bangkrut.
Hal ini memunculkan L2: OPRU yang memperkenalkan sorter untuk menggabungkan sejumlah transaksi dan kemudian mengirimkannya ke mainnet. Hal ini tidak hanya membantu aplikasi menyamai keamanan Ethereum, tetapi juga memberi pengguna pengalaman yang lebih baik. Pengguna dapat mengirimkan transaksi lebih cepat dan biaya transaksi lebih murah. Meskipun operasinya menjadi lebih murah, ia masih menggunakan EVM asli sebagai lapisan eksekusi. Mirip dengan ZK Rollups, Scroll dan Polygon zkEVM menggunakan atau akan menggunakan sirkuit zk berbasis EVM, dan zk Proof akan dihasilkan dalam setiap transaksi atau paket besar transaksi yang dilakukan pada pembuktiannya. Meskipun hal ini memungkinkan pengembang untuk membangun aplikasi “sepenuhnya on-chain”, apakah hal ini masih dapat menjalankan aplikasi berkinerja tinggi secara efisien dan hemat biaya?
Apa saja aplikasi berkinerja tinggi ini?
Hal pertama yang terlintas di pikiran orang adalah permainan, buku pesanan on-chain, sosial Web3, pembelajaran mesin, pemodelan genomik, dll. Semua ini memerlukan komputasi yang intensif dan dapat sangat mahal untuk dijalankan pada L2. Masalah lain dengan EVM adalah kecepatan komputasi dan efisiensinya tidak sebaik sistem terkini lainnya, seperti SVM (Sealevel Virtual Machine).
Meskipun EVM L3 dapat membuat komputasi lebih murah, struktur EVM itu sendiri mungkin bukan cara terbaik untuk melakukan komputasi tinggi karena tidak dapat menghitung operasi paralel. Setiap kali lapisan baru dibangun di atasnya, untuk mempertahankan semangat desentralisasi, infrastruktur baru (jaringan node baru) perlu dibangun, yang masih memerlukan jumlah penyedia yang sama untuk ditingkatkan, atau serangkaian penyedia node (individu/perusahaan) yang sepenuhnya baru untuk menyediakan sumber daya, atau keduanya.
Oleh karena itu, setiap kali solusi yang lebih canggih dibangun, infrastruktur yang ada harus ditingkatkan atau lapisan baru dibangun di atasnya. Untuk mengatasi masalah ini, kita memerlukan infrastruktur komputasi pasca-kuantum yang aman, terdesentralisasi, tanpa kepercayaan, dan berkinerja tinggi yang dapat benar-benar dan efisien menggunakan algoritma kuantum untuk melakukan perhitungan bagi aplikasi yang terdesentralisasi.
Alt-L1 seperti Solana, Sui, dan Aptos mampu dieksekusi paralel, tetapi mereka tidak akan menantang Ethereum karena sentimen pasar, kekurangan likuiditas, dan kurangnya pengembang di pasar. Karena kurangnya kepercayaan, dan parit yang dibangun Ethereum dengan efek jaringan sangatlah monumental. Sejauh ini, belum ada pembunuh ETH/EVM. Pertanyaannya di sini adalah, mengapa semua komputasi harus dilakukan secara on-chain? Apakah ada sistem eksekusi terdesentralisasi yang sama-sama tanpa kepercayaan? Inilah yang dapat dicapai sistem DCompute.
Infrastruktur DCompute harus terdesentralisasi, aman pasca-kuantum, dan tidak memerlukan kepercayaan. Infrastruktur tersebut tidak memerlukan atau tidak boleh menggunakan teknologi blockchain/terdistribusi, tetapi sangat penting untuk memverifikasi hasil perhitungan, transisi status yang benar, dan konfirmasi akhir. Beginilah cara kerja rantai EVM, dan komputasi yang terdesentralisasi, tanpa kepercayaan, dan aman dapat dipindahkan ke luar rantai sambil tetap menjaga keamanan dan kekekalan jaringan.
Apa yang selama ini kita abaikan adalah masalah ketersediaan data. Tulisan ini bukannya tanpa perhatian pada ketersediaan data, karena solusi seperti Celestia dan EigenDA sudah bergerak ke arah ini.
1: Hanya Menghitung yang Di-outsource
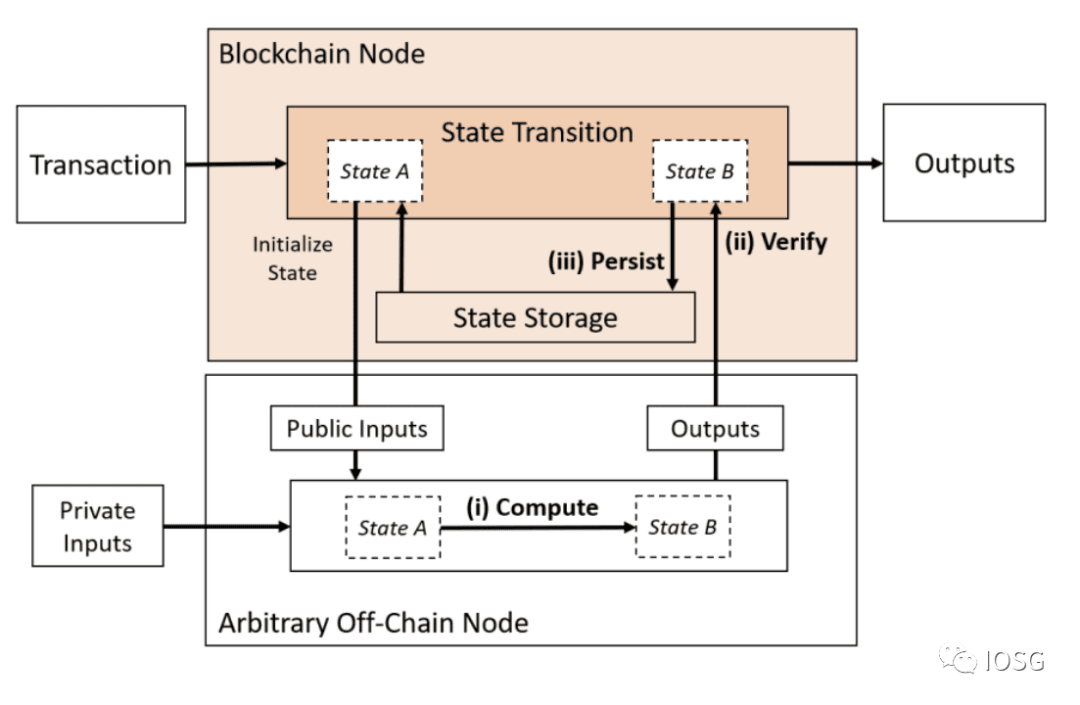
2. Outsourcing Komputasi dan Ketersediaan Data
Ketika kita melihat Tipe 1, zk-rollup sudah melakukan ini, tetapi dibatasi oleh EVM atau mengharuskan pengembang belajar untuk mempelajari seluruh bahasa/set instruksi baru. Solusi ideal akan efisien, efektif (biaya dan sumber daya), terdesentralisasi, privat, dan dapat diverifikasi. Bukti ZK dapat dibangun di server AWS, tetapi tidak terdesentralisasi. Solusi seperti Nillion dan Nexus mencoba memecahkan masalah komputasi umum dengan cara yang terdesentralisasi. Tetapi solusi ini tidak dapat diverifikasi tanpa bukti ZK.
Tipe 2 menggabungkan model komputasi di luar rantai dengan lapisan ketersediaan data yang tetap terpisah, tetapi komputasi masih perlu diverifikasi secara on-chain.
Mari kita lihat berbagai model komputasi terdesentralisasi yang tersedia saat ini yang tidak sepenuhnya tanpa kepercayaan dan berpotensi sepenuhnya tanpa kepercayaan.
Sistem Komputasi Alternatif
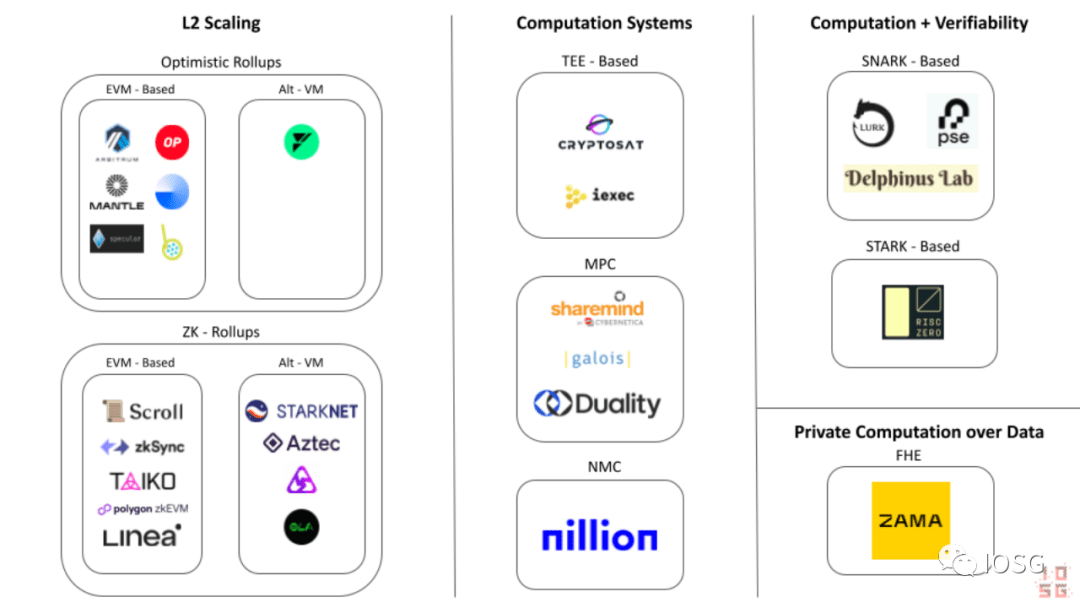
Diagram ekosistem komputasi teralihdayakan Ethereum
- Komputasi Enclave Aman/Lingkungan Eksekusi Tepercaya
TEE (Trusted Execution Environment) seperti kotak khusus di dalam komputer atau telepon pintar Anda. Ia memiliki kunci dan gemboknya sendiri, dan hanya program tertentu (disebut aplikasi tepercaya) yang dapat mengaksesnya. Ketika aplikasi tepercaya ini berjalan di dalam TEE, mereka dilindungi dari program lain dan bahkan sistem operasi itu sendiri.
Itu seperti tempat persembunyian rahasia yang hanya bisa diakses oleh beberapa teman spesial. Contoh TEE yang paling umum adalah enklave aman yang ada pada perangkat yang kita gunakan, seperti chip T1 milik Apple dan SGX milik Intel, dan digunakan untuk menjalankan operasi penting di dalam perangkat, seperti FaceID.
Karena TEE adalah sistem yang terisolasi, proses autentikasi tidak dapat dikompromikan karena ada asumsi kepercayaan dalam autentikasi. Bayangkan Anda memiliki pintu keamanan yang Anda yakini aman karena dibuat oleh Intel atau Apple, tetapi ada cukup banyak pembobol keamanan di dunia (termasuk peretas dan komputer lain) yang dapat mendobrak pintu keamanan itu. TEE tidak “aman pasca-kuantum”, yang berarti bahwa komputer kuantum dengan sumber daya tak terbatas dapat merusak keamanan TEE. Seiring dengan pesatnya perkembangan komputer, kita harus membangun sistem komputasi jangka panjang dan skema kriptografi dengan mempertimbangkan keamanan pasca-kuantum.
- Komputasi Multipihak yang Aman (SMPC)
SMPC (Secure Multi-Party Computation) juga merupakan solusi komputasi yang dikenal baik oleh praktisi teknologi blockchain. Alur kerja umum dalam jaringan SMPC terdiri dari tiga bagian berikut:
Langkah 1: Ubah masukan komputasi menjadi bagian dan distribusikan ke antara node SMPC.
Langkah 2: Lakukan perhitungan sebenarnya, biasanya melibatkan pertukaran pesan antara node SMPC. Pada akhir langkah ini, setiap node akan mendapat bagian dari nilai keluaran yang dihitung.
Langkah 3: Kirim hasil pembagian ke satu atau lebih node hasil, yang menjalankan LSS (Algoritma Pemulihan Pembagian Rahasia) untuk merekonstruksi hasil keluaran.
Bayangkan sebuah jalur produksi mobil yang mana konstruksi dan pembuatan komponen-komponen mobil (mesin, pintu, kaca spion) dialihdayakan ke produsen peralatan asli (OEM) (simpul kerja), lalu ada jalur perakitan yang menyatukan semua komponen untuk membuat mobil (simpul hasil).
Pembagian rahasia sangat penting untuk model komputasi terdesentralisasi yang menjaga privasi. Hal ini mencegah satu pihak saja memperoleh "rahasia" secara lengkap (dalam kasus ini, input) dan secara jahat menghasilkan output yang salah. SMPC mungkin adalah salah satu sistem terdesentralisasi yang termudah dan teraman. Walau model yang sepenuhnya terdesentralisasi saat ini belum ada, secara logika hal itu memungkinkan.
Penyedia MPC seperti Sharemind menyediakan infrastruktur MPC untuk komputasi, tetapi penyedianya masih tersentralisasi. Bagaimana Anda memastikan privasi, bagaimana Anda memastikan bahwa jaringan (atau Sharemind) tidak bertindak jahat? Di sinilah pembuktian zk dan komputasi yang dapat diverifikasi zk berperan.
- Komputasi Pesan Nihil (NMC)
NMC adalah metode komputasi terdistribusi baru yang dikembangkan oleh tim Nillion. Ini adalah versi terbaru MPC di mana node tidak perlu berkomunikasi dengan cara bertukar hasil. Untuk melakukan ini, mereka menggunakan primitif kriptografi yang disebut One-Time Masking, yang menggunakan serangkaian angka acak yang disebut faktor pembutaan untuk menutupi rahasia, mirip dengan one-time padding. OTM bertujuan untuk menyediakan kebenaran secara efisien, yang berarti bahwa node NMC tidak perlu bertukar pesan apa pun untuk melakukan perhitungan. Ini berarti NMC tidak memiliki masalah skalabilitas seperti SMPC.
- Komputasi yang dapat diverifikasi tanpa pengetahuan
Komputasi Terverifikasi ZK menghasilkan bukti pengetahuan-nol untuk serangkaian masukan dan suatu fungsi, dan membuktikan bahwa setiap komputasi yang dilakukan oleh sistem akan dilakukan dengan benar. Meskipun komputasi verifikasi ZK masih baru, komputasi ini sudah menjadi bagian penting dari peta jalan perluasan jaringan Ethereum.
Ada berbagai bentuk implementasi pembuktian ZK (seperti yang ditunjukkan di bawah ini, dirangkum dalam makalah "Off-Chaining_Models"):
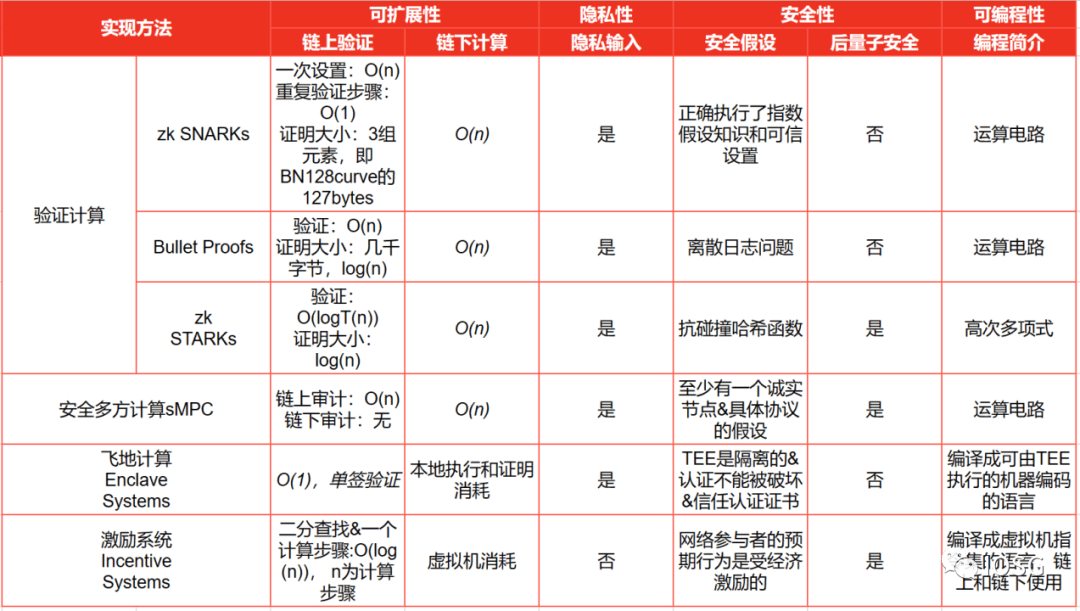
Di atas kita memiliki pemahaman dasar tentang bagaimana pembuktian zk diimplementasikan, jadi kondisi apa yang diperlukan untuk menggunakan pembuktian ZK untuk memverifikasi perhitungan?
Pertama, kita perlu memilih pembuktian primitif. Bukti primitif yang ideal murah untuk dibuat, memiliki persyaratan memori yang rendah, dan mudah diverifikasi.
Kedua, pilih sirkuit zk yang dirancang untuk menghasilkan bukti komputasional dari primitif di atas
Akhirnya, fungsi yang diberikan dihitung dengan masukan yang disediakan dalam beberapa sistem/jaringan komputasi dan keluarannya diberikan.
Dilema Pengembang - Dilema Bukti Efisiensi
Hal lain yang perlu disebutkan adalah bahwa ambang batas untuk membangun sirkuit masih sangat tinggi. Tidak mudah bagi pengembang untuk mempelajari Solidity. Sekarang pengembang diharuskan mempelajari Circom untuk membangun sirkuit, atau mempelajari bahasa pemrograman tertentu (seperti Cairo) untuk membangun aplikasi zk. Ini tampaknya merupakan hal yang tidak dapat dicapai.
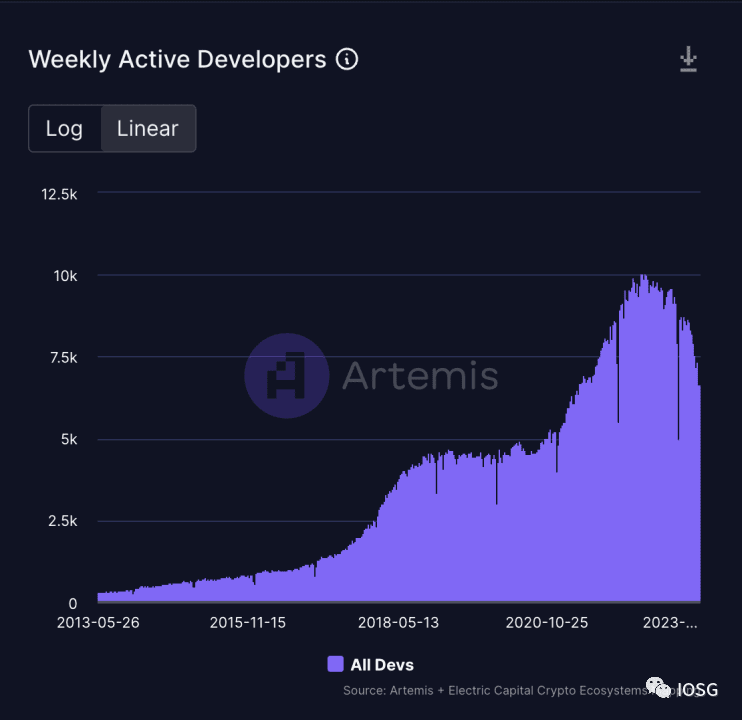
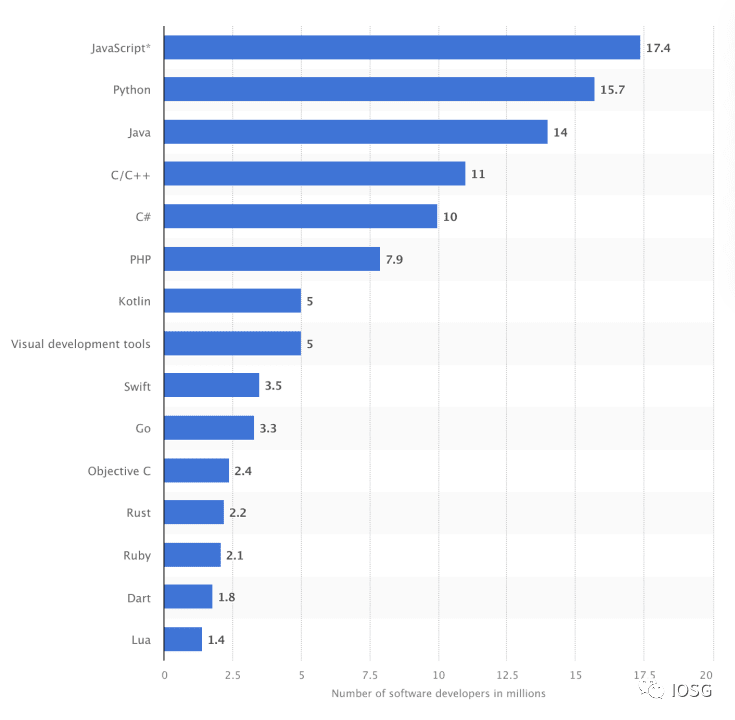
Seperti yang ditunjukkan statistik di atas, mengubah lingkungan Web3 agar lebih sesuai untuk pengembangan tampaknya lebih berkelanjutan daripada memperkenalkan pengembang ke lingkungan pengembangan Web3 baru.
Jika ZK adalah masa depan Web3, dan aplikasi Web3 perlu dibangun menggunakan keterampilan pengembang yang ada, maka sirkuit ZK perlu dirancang sedemikian rupa sehingga mendukung pembuatan bukti komputasi yang dilakukan oleh algoritme yang ditulis dalam bahasa seperti JavaScript atau Rust.
Solusi semacam itu memang ada, dan ada dua tim yang terlintas dalam pikiran: RiscZero dan Lurk Labs. Kedua tim memiliki visi yang sangat mirip yaitu memungkinkan pengembang untuk membangun aplikasi zk tanpa melalui kurva pembelajaran yang curam.
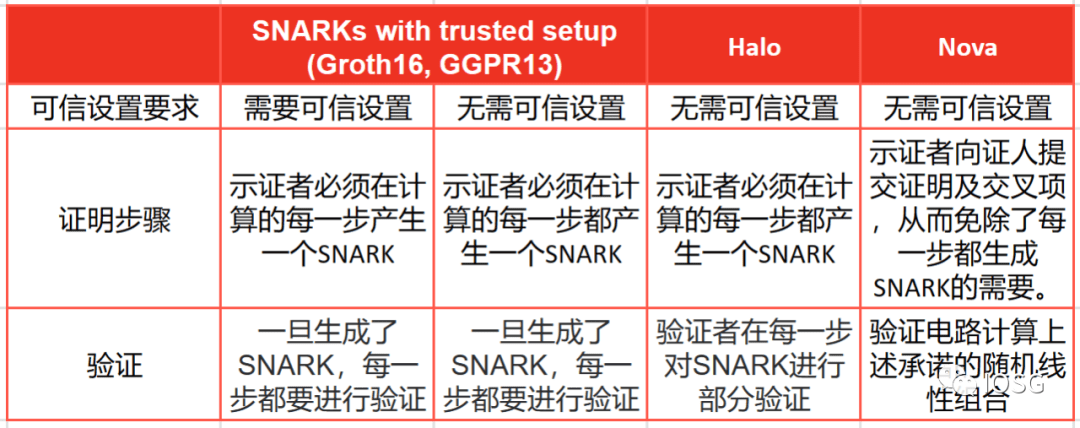
Ini masih tahap awal bagi Lurk Labs, tetapi timnya telah mengerjakan proyek ini dalam waktu yang lama. Mereka berfokus pada pembuatan Nova Proofs melalui rangkaian umum. Bukti Nova diajukan oleh Abhiram Kothapalli dari Universitas Carnegie Mellon, Srinath Setty dari Microsoft Research, dan Ioanna Tziallae dari Universitas New York. Dibandingkan dengan sistem SNARK lainnya, Nova terbukti memiliki keunggulan khusus dalam melakukan Incremental Verifiable Computation (IVC). Komputasi terverifikasi inkremental (IVC) adalah sebuah konsep dalam ilmu komputer dan kriptografi yang bertujuan untuk memungkinkan verifikasi komputasi tanpa menghitung ulang seluruh komputasi dari awal. Jika perhitungannya panjang dan rumit, pembuktiannya perlu dioptimalkan untuk IVC.
Bukti Nova tidak "siap pakai" seperti sistem pembuktian lainnya. Nova hanyalah trik melipat, dan pengembang masih memerlukan sistem pembuktian untuk menghasilkan pembuktian. Itulah sebabnya Lurk Labs membangun Lurk Lang, implementasi LISP. Karena LISP adalah bahasa tingkat rendah, bahasa ini memudahkan pembuatan bukti pada rangkaian umum, dan juga mudah diterjemahkan ke dalam JavaScript, yang akan membantu Lurk Labs memperoleh dukungan dari 17,4 juta pengembang Javascript. Ia juga mendukung penerjemahan ke bahasa umum lainnya, seperti Python.
Secara keseluruhan, Nova Proofs tampaknya merupakan sistem pembuktian yang hebat dan orisinal. Walaupun memiliki kelemahan yaitu ukuran pembuktian meningkat secara linear seiring dengan ukuran komputasi, di sisi lain, pembuktian Nova memiliki ruang untuk kompresi lebih lanjut.
Ukuran bukti STARK tidak bertambah seiring dengan jumlah perhitungan, membuatnya lebih cocok untuk memverifikasi perhitungan yang sangat besar. Untuk lebih meningkatkan pengalaman pengembang, mereka juga merilis Bonsai Network, jaringan komputasi terdistribusi yang diverifikasi oleh bukti yang dihasilkan oleh RiscZero. Ini adalah diagram sederhana yang menggambarkan cara kerja jaringan Bonsai RiscZero.
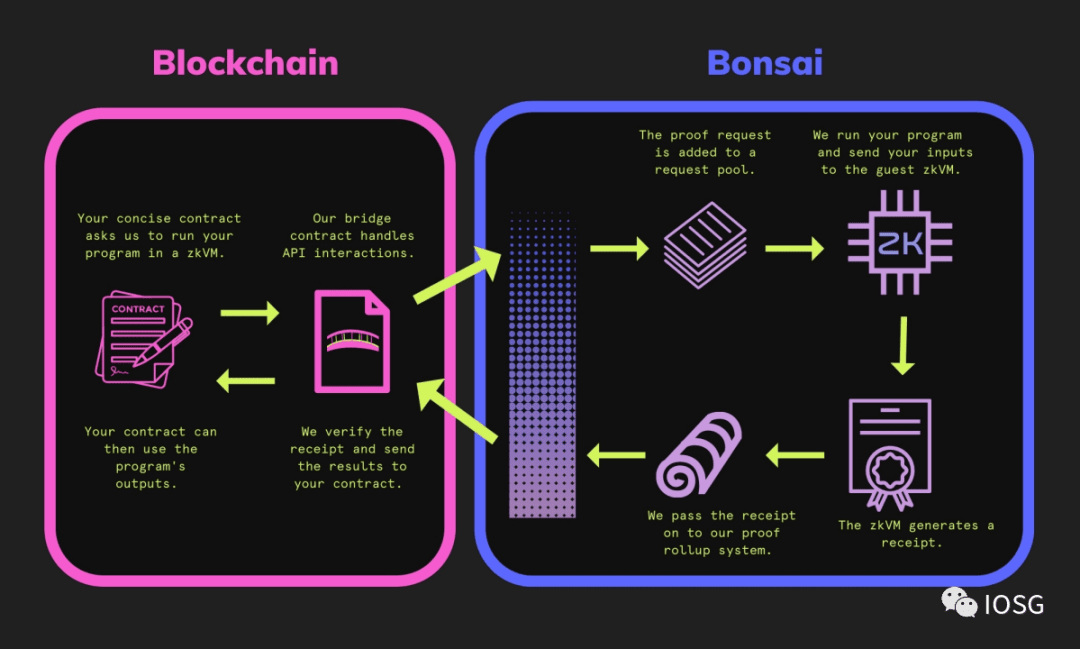
Keindahan desain jaringan Bonsai adalah bahwa perhitungan dapat diinisialisasi, diverifikasi, dan dikeluarkan secara on-chain. Semua ini terdengar seperti utopia, tetapi bukti STARK juga membawa masalah - biaya verifikasi terlalu tinggi.
Pembuktian Nova tampaknya sangat cocok untuk perhitungan berulang (skema pelipatannya hemat biaya) dan perhitungan kecil, yang dapat menjadikan Lurk solusi yang baik untuk verifikasi penalaran ML.
Siapa pemenangnya?


Beberapa sistem zk-SNARK memerlukan proses pengaturan tepercaya selama fase pengaturan awal untuk menghasilkan serangkaian parameter awal. Asumsi kepercayaan di sini adalah bahwa pengaturan tepercaya dijalankan secara jujur tanpa perilaku jahat atau gangguan apa pun. Jika diserang, ini dapat mengakibatkan terciptanya bukti yang tidak valid.
Pembuktian STARK mengasumsikan keamanan pengujian orde rendah, yang digunakan untuk memverifikasi sifat polinomial orde rendah. Mereka juga berasumsi bahwa fungsi hash berperilaku seperti oracle acak.
Implementasi yang benar dari kedua sistem juga merupakan asumsi yang aman.
Jaringan SMPC bergantung pada hal berikut:
Peserta SMPC dapat mencakup peserta yang “jujur tetapi ingin tahu” yang dapat mencoba mengakses informasi tersembunyi apa pun dengan berkomunikasi dengan node lain.
Keamanan jaringan SMPC bergantung pada asumsi bahwa peserta menjalankan protokol dengan benar dan tidak secara sengaja menimbulkan kesalahan atau perilaku jahat.
Beberapa protokol SMPC mungkin memerlukan fase pengaturan tepercaya untuk menghasilkan parameter kriptografi atau nilai awal. Asumsi kepercayaan di sini adalah bahwa pengaturan tepercaya dijalankan dengan jujur.
Sama seperti jaringan SMPC, asumsi keamanannya tetap sama, tetapi karena adanya OTM (Off-The-Grid Multi-party Computation), tidak ada peserta yang “jujur tapi ingin tahu”.
OTM adalah protokol komputasi multipihak yang dirancang untuk melindungi privasi peserta. Perlindungan privasi tercapai dengan menjaga data masukan peserta dalam perhitungan tetap bersifat pribadi. Oleh karena itu, aktor yang “jujur tapi ingin tahu” tidak dapat eksis karena mereka tidak dapat mencoba mengakses informasi yang mendasarinya dengan berkomunikasi dengan node lain.
Apakah ada pemenang yang jelas? Kami tidak tahu. Namun masing-masing metode memiliki kelebihannya sendiri. Walaupun NMC tampak seperti peningkatan yang nyata dari SMPC, jaringannya belum aktif dan belum teruji dalam pertempuran.
Keuntungan menggunakan komputasi yang dapat diverifikasi ZK adalah aman dan menjaga privasi, tetapi tidak memiliki kemampuan berbagi rahasia bawaan. Asimetris antara pembuatan bukti dan verifikasi menjadikannya model ideal untuk komputasi yang dialihdayakan secara terverifikasi. Jika sistem menggunakan komputasi murni yang diverifikasi zk, komputer (atau satu node) harus sangat kuat untuk melakukan komputasi dalam jumlah besar. Untuk mengaktifkan pembagian dan penyeimbangan beban sambil menjaga privasi, pembagian rahasia diperlukan. Dalam kasus ini, sistem seperti SMPC atau NMC dapat dikombinasikan dengan generator zk seperti Lurk atau RiscZero untuk menciptakan infrastruktur komputasi teroutsourcing yang terdistribusi dan dapat diverifikasi yang kuat.
Hal ini menjadi sangat penting karena jaringan MPC/SMPC saat ini tersentralisasi. Penyedia MPC terbesar saat ini adalah Sharemind, di mana lapisan validasi ZK dapat terbukti berguna. Model ekonomi jaringan MPC yang terdesentralisasi belum diimplementasikan. Secara teori, model NMC merupakan pemutakhiran terhadap sistem MPC, tetapi kita belum melihat keberhasilannya.
Dalam kompetisi pembuktian ZK, mungkin tidak ada situasi pemenang mengambil semuanya. Setiap metode pembuktian dioptimalkan untuk jenis perhitungan tertentu, dan tidak ada model yang cocok untuk semua. Ada banyak jenis tugas komputasi, tergantung pada pertimbangan yang dibuat pengembang dengan masing-masing sistem pembuktian. Penulis meyakini bahwa sistem berbasis STARK dan sistem berbasis SNARK serta optimalisasi masa depannya memiliki tempat di masa depan ZK.