
Kesimpulan Utama
Binance memanfaatkan manajemen kapasitas untuk lonjakan lalu lintas yang tidak direncanakan yang disebabkan oleh volatilitas tinggi, memastikan infrastruktur dan sumber daya komputasi yang memadai dan tepat waktu untuk kebutuhan bisnis.
Uji beban Binance di lingkungan produksi (bukan lingkungan pementasan) untuk mendapatkan tolok ukur layanan yang akurat. Metode ini membantu memvalidasi bahwa alokasi sumber daya kami cukup untuk melayani beban yang ditentukan.
Infrastruktur Binance menangani lalu lintas dalam jumlah besar, dan mempertahankan layanan yang dapat diandalkan oleh pengguna memerlukan manajemen kapasitas yang tepat dan pengujian beban otomatis.

Mengapa Binance Membutuhkan Proses Manajemen Kapasitas Khusus?
Manajemen kapasitas adalah landasan stabilitas sistem. Hal ini memerlukan ukuran aplikasi dan sumber daya infrastruktur yang tepat sesuai dengan tuntutan bisnis saat ini dan masa depan dengan biaya yang tepat. Untuk membantu mencapai tujuan ini, kami membangun alat dan saluran manajemen kapasitas untuk menghindari kelebihan beban dan membantu bisnis memberikan pengalaman pengguna yang lancar.
Pasar mata uang kripto sering kali menghadapi periode volatilitas yang lebih teratur dibandingkan pasar keuangan tradisional. Ini berarti sistem Binance harus menahan lonjakan lalu lintas ini dari waktu ke waktu seiring reaksi pengguna terhadap pergerakan pasar. Dengan manajemen kapasitas yang tepat, kami menjaga kapasitas tetap memadai untuk permintaan bisnis umum dan skenario lonjakan lalu lintas ini. Poin penting inilah yang menjadikan proses manajemen kapasitas Binance unik dan menantang.
Mari kita lihat faktor-faktor yang sering menghambat proses dan menyebabkan layanan lambat atau tidak tersedia. Pertama, kita mengalami kelebihan beban, biasanya disebabkan oleh peningkatan lalu lintas secara tiba-tiba. Misalnya, hal ini dapat diakibatkan oleh peristiwa pemasaran, pemberitahuan push, atau bahkan serangan DDoS (penolakan layanan terdistribusi).
Lonjakan lalu lintas dan kapasitas yang tidak mencukupi mempengaruhi fungsionalitas sistem sebagai:
Layanan ini membutuhkan lebih banyak pekerjaan.
Waktu respons meningkat hingga tidak ada permintaan yang dapat ditanggapi dalam batas waktu klien. Degradasi ini biasanya terjadi karena kejenuhan sumber daya (CPU, memori, IO, jaringan, dll.) atau jeda GC yang berkepanjangan dalam layanan itu sendiri atau ketergantungannya.
Akibatnya layanan tidak dapat memproses permintaan dengan cepat.
Menghancurkan proses
Setelah kita membahas prinsip umum manajemen kapasitas, mari kita lihat bagaimana Binance menerapkan hal ini pada bisnisnya. Berikut sekilas arsitektur sistem manajemen kapasitas kami dengan beberapa alur kerja utama.
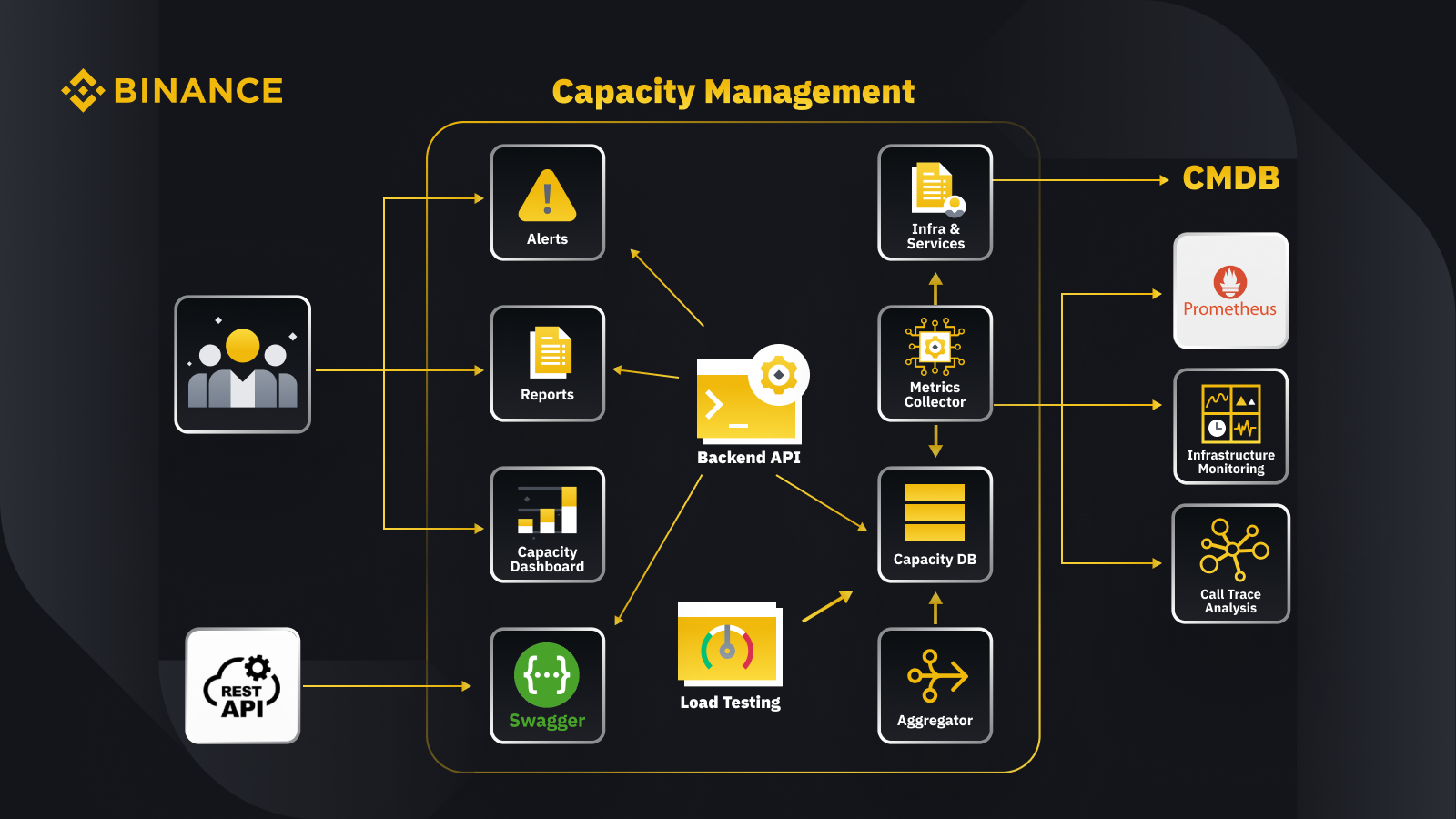
Dengan mengambil data dari database manajemen konfigurasi (CMDB), kami menghasilkan konfigurasi infra & layanan. Item dalam konfigurasi ini adalah objek manajemen kapasitas.
Pengumpul metrik mengambil metrik kapasitas dari Prometheus untuk data lapisan bisnis dan layanan, Pemantauan Infrastruktur untuk metrik lapisan sumber daya, dan sistem analisis jejak panggilan untuk informasi pelacakan. Pengumpul metrik menyimpan data dalam database kapasitas (CDB).
Sistem pengujian beban melakukan stress test pada layanan dan menyimpan data benchmark di CDB.
Agregator mendapatkan data kapasitas dari CDB dan mengagregasinya untuk dimensi harian dan tertinggi sepanjang masa (ATH). Setelah agregasi, ia menulis data agregat kembali ke CDB.
Dengan memproses data dari CDB, API backend menyediakan antarmuka untuk dasbor kapasitas, peringatan, dan laporan, serta API lainnya dan data kapasitas terkait untuk integrasi.
Pemangku kepentingan mendapatkan wawasan tentang kapasitas melalui dasbor kapasitas, peringatan, dan laporan. Mereka juga dapat menggunakan sistem terkait lainnya, termasuk memantau data kapasitas layanan dengan API lainnya yang disediakan oleh sistem manajemen kapasitas dengan Swagger.
Strategi
Manajemen kapasitas dan strategi perencanaan kami bergantung pada pemrosesan yang didorong oleh puncak. Pemrosesan berbasis puncak adalah beban kerja yang dialami oleh sumber daya layanan (server web, database, dll.) selama penggunaan puncak.
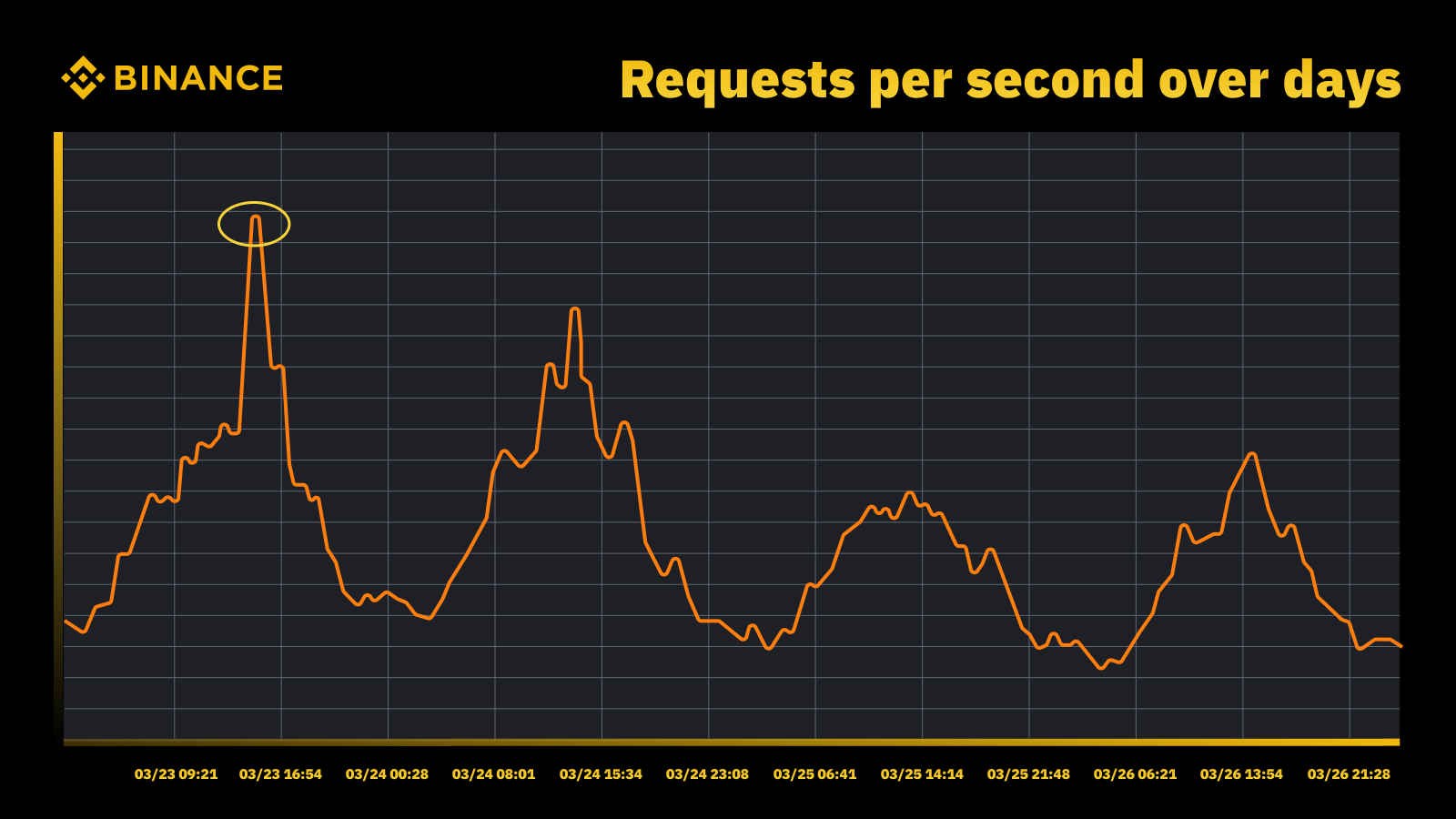
Lonjakan lalu lintas ketika Fed menaikkan suku bunga pada Maret 2023
Kami menganalisis puncak periodik dan menggunakannya untuk menentukan lintasan kapasitas. Seperti halnya sumber daya yang didorong oleh puncak, kami ingin mengetahui kapan puncak terjadi dan kemudian menelusuri apa yang sebenarnya terjadi selama siklus tersebut.
Hal penting lainnya yang kami pertimbangkan selain mencegah kelebihan beban adalah penskalaan otomatis. Penskalaan otomatis menangani kelebihan beban dengan meningkatkan kapasitas secara dinamis dengan lebih banyak instance layanan. Lalu lintas berlebih kemudian didistribusikan, dan lalu lintas yang ditangani oleh satu contoh layanan (atau ketergantungan) tetap dapat dikelola.
Penskalaan otomatis mempunyai tempatnya, namun gagal dalam menangani situasi kelebihan beban saja. Biasanya cara ini tidak dapat bereaksi cukup cepat terhadap peningkatan lalu lintas secara tiba-tiba dan hanya berfungsi paling baik jika terjadi peningkatan secara bertahap.
Pengukuran
Pengukuran memainkan peran penting dalam pekerjaan manajemen kapasitas Binance, dan pengumpulan data adalah langkah pengukuran pertama kami. Berdasarkan standar Information Technology Infrastructure Library (ITIL), kami mengumpulkan data untuk pengukuran pada subproses manajemen kapasitas, yaitu:
Sumber Daya - Konsumsi sumber daya infrastruktur TI yang didorong oleh penggunaan aplikasi/layanan. Berfokus pada metrik kinerja internal sumber daya komputasi fisik dan virtual, termasuk CPU server, memori, penyimpanan disk, bandwidth jaringan, dll.
Melayani. Kinerja tingkat aplikasi, SLA, latensi, dan ukuran throughput yang timbul dari aktivitas bisnis. Berfokus pada metrik kinerja eksternal berdasarkan cara pengguna memandang layanan, termasuk latensi layanan, throughput, puncak, dll.
Bisnis. Mengumpulkan data yang mengukur aktivitas bisnis yang diproses oleh aplikasi target, termasuk pesanan, pendaftaran pengguna, pembayaran, dll.
Pengelolaan kapasitas yang hanya bertumpu pada pemanfaatan sumber daya infrastruktur akan mengakibatkan perencanaan yang tidak akurat. Hal ini karena data tersebut mungkin tidak mewakili volume bisnis aktual dan hasil yang mendorong kapasitas infrastruktur kami.
Acara terjadwal menyediakan tempat yang tepat untuk mendiskusikan hal ini lebih lanjut. Ikuti Watch Web Summit 2022 di Binance Live untuk Berbagi Hingga 15.000 BUSD dalam kampanye Crypto Box Rewards. Selain metrik lapisan sumber daya dan layanan yang mendasarinya, kami juga perlu mempertimbangkan volume bisnis. Kami mendasarkan perencanaan kapasitas di sini pada metrik bisnis seperti perkiraan jumlah pemirsa streaming langsung, permintaan maksimum dalam penerbangan untuk Crypto Box, latensi ujung ke ujung, dan faktor lainnya.
Setelah mengumpulkan data, proses manajemen kapasitas kami mengumpulkan dan merangkum berbagai titik data yang dikumpulkan berdasarkan penggerak kapasitas tertentu. Nilai agregat metrik adalah nilai tunggal yang dapat digunakan dalam pemberitahuan kapasitas, pelaporan, dan fungsi terkait kapasitas lainnya.
Kita dapat menerapkan beberapa metode agregasi data pada titik data periodik, seperti jumlah, rata-rata, median, minimum, maksimum, persentil, dan tertinggi sepanjang masa (ATH).

Metode yang kami pilih menentukan keluaran dari proses manajemen kapasitas dan keputusan yang dihasilkan. Kami memilih metode berbeda berdasarkan skenario berbeda. Misalnya, kami menggunakan metode maksimum untuk layanan penting dan titik data terkait. Untuk mencatat traffic tertinggi, kami menggunakan metode ATH.
Untuk kasus penggunaan yang berbeda, kami menggunakan jenis perincian yang berbeda untuk agregasi data. Dalam kebanyakan kasus, kami menggunakan menit, jam, hari, atau ATH.
Dengan rincian yang sangat kecil, kami mengukur beban kerja suatu layanan untuk peringatan kelebihan beban secara tepat waktu.
Kami menggunakan data gabungan per jam untuk mengumpulkan data harian dan menggabungkan data per jam untuk mencatat puncak harian.
Biasanya kami menggunakan data harian untuk laporan kapasitas dan memanfaatkan data ATH untuk pemodelan dan perencanaan kapasitas.
Salah satu metrik inti manajemen kapasitas adalah pembandingan layanan. Hal ini membantu kami mengukur kinerja dan kapasitas layanan secara akurat. Kami memperoleh tolok ukur layanan dengan pengujian beban, dan kami akan membahasnya lebih detail nanti.
Manajemen Kapasitas Berdasarkan Prioritas
Sejauh ini, kita telah melihat cara kami mengumpulkan metrik kapasitas dan mengumpulkan data dalam berbagai jenis perincian. Bidang penting lainnya yang perlu didiskusikan adalah prioritas, yang berguna dalam konteks peringatan dan laporan kapasitas. Setelah memeringkat aset TI, penggunaan infrastruktur dan sumber daya komputasi yang terbatas diprioritaskan dan diberikan pada layanan dan aktivitas penting terlebih dahulu.
Ada beberapa cara untuk mendefinisikan layanan dan meminta kekritisan. Referensi yang berguna adalah Google. Dalam buku SRE. Mereka mendefinisikan tingkat kekritisan sebagai CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS, dll. Demikian pula, kami mendefinisikan beberapa tingkat prioritas seperti P0, P1, P2, dan seterusnya.
Kami mendefinisikan tingkat prioritas sebagai berikut:
P0: Untuk layanan dan permintaan yang paling penting, yaitu layanan dan permintaan yang akan menimbulkan dampak serius yang terlihat oleh pengguna jika gagal.
P1: Untuk layanan dan permintaan yang akan menghasilkan dampak yang terlihat oleh pengguna, namun dampaknya lebih kecil dibandingkan P0. Layanan P0 dan P1 diharapkan tersedia dengan kapasitas yang cukup.
P2: Ini adalah prioritas default untuk pekerjaan batch dan pekerjaan offline. Layanan dan permintaan ini mungkin tidak memberikan dampak yang terlihat oleh pengguna jika tidak tersedia sebagian.
Apa Itu Pengujian Beban, dan Mengapa Kami Menggunakannya di Lingkungan Produksi?
Pengujian beban adalah proses pengujian perangkat lunak non-fungsional di mana kinerja aplikasi diuji pada beban kerja tertentu. Hal ini membantu menentukan bagaimana aplikasi berperilaku saat diakses oleh banyak pengguna akhir secara bersamaan.
Di Binance, kami menciptakan solusi yang memungkinkan kami menjalankan pengujian beban dalam produksi. Biasanya, pengujian beban dijalankan dalam lingkungan pementasan, namun kami tidak dapat menggunakan opsi ini berdasarkan tujuan manajemen kapasitas kami secara keseluruhan. Pengujian beban di lingkungan produksi memungkinkan kami untuk:
Kumpulkan tolok ukur akurat layanan kami dalam kondisi beban kehidupan nyata.
Meningkatkan kepercayaan pada sistem serta keandalan dan kinerjanya.
Identifikasi hambatan dalam sistem sebelum terjadi di lingkungan produksi.
Aktifkan pemantauan berkelanjutan terhadap lingkungan produksi.
Aktifkan manajemen kapasitas proaktif dengan siklus pengujian yang dinormalisasi yang terjadi secara rutin.
Di bawah ini Anda dapat melihat kerangka pengujian beban kami dengan beberapa poin penting:

Kerangka kerja layanan mikro Binance memiliki lapisan dasar untuk mendukung perutean lalu lintas berbasis konfigurasi dan bendera, yang penting untuk pendekatan TIP kami.
Analisis kenari otomatis (ACA) digunakan untuk menilai instance yang kami uji. Ini membandingkan metrik utama yang dikumpulkan dalam sistem pemantauan, sehingga kami dapat menjeda/menghentikan pengujian jika terjadi masalah tak terduga untuk meminimalkan dampak terhadap pengguna.
Tolok ukur dan metrik dikumpulkan selama pengujian beban untuk menghasilkan wawasan data mengenai perilaku dan kinerja aplikasi.
API dihadapkan pada berbagi data kinerja yang berharga dalam berbagai skenario, misalnya, manajemen kapasitas dan jaminan kualitas. Hal ini membantu membangun ekosistem terbuka.
Kami menciptakan alur kerja otomatisasi untuk mengatur semua langkah dan titik kontrol dari perspektif pengujian menyeluruh. Kami juga memberikan fleksibilitas untuk berintegrasi dengan sistem lain, seperti pipeline CI/CD dan portal operasi.
Pendekatan pengujian dalam produksi (TIP) kami
Pendekatan pengujian kinerja tradisional (menjalankan pengujian dalam lingkungan pementasan dengan lalu lintas yang disimulasikan atau dicerminkan) memang memberikan beberapa manfaat. Namun, penerapan lingkungan pementasan seperti produksi memiliki lebih banyak kelemahan dalam konteks kita:
Hal ini hampir menggandakan biaya infrastruktur dan upaya pemeliharaan.
Mendapatkan pekerjaan end-to-end dalam produksi sangatlah rumit, terutama dalam lingkungan layanan mikro berskala besar di berbagai unit bisnis.
Hal ini menambah lebih banyak risiko privasi dan keamanan data karena, mau tidak mau, kita mungkin perlu menduplikasi data dalam tahap pementasan.
Lalu lintas yang disimulasikan tidak akan pernah meniru apa yang sebenarnya terjadi dalam produksi. Tolok ukur yang diperoleh dalam lingkungan pementasan akan menjadi tidak akurat dan memiliki nilai yang lebih rendah
Pengujian dalam produksi, juga dikenal sebagai TIP, adalah metodologi pengujian shift-kanan di mana kode, fitur, dan rilis baru diuji di lingkungan produksi. Pengujian beban dalam produksi yang kami adopsi sangat bermanfaat karena membantu kami:
Analisis stabilitas dan ketahanan sistem.
Temukan tolok ukur dan hambatan aplikasi pada berbagai tingkat lalu lintas, spesifikasi server, dan parameter aplikasi.
Perutean berbasis FlowFlag
Perutean berbasis FlowFlag kami yang tertanam dalam kerangka dasar layanan mikro adalah fondasi untuk memungkinkan TIP. Hal ini berlaku untuk kasus tertentu, termasuk aplikasi yang menggunakan penemuan layanan Eureka untuk distribusi lalu lintas.
Seperti yang diilustrasikan dalam diagram, server web Binance sebagai titik masuk memberi label beberapa persen lalu lintas seperti yang ditentukan dalam konfigurasi dengan header FlowFlag, selama pengujian beban, kita dapat memilih satu host dari layanan tertentu dan menandainya sebagai contoh kinerja target di configs, maka permintaan perf yang diberi label tersebut pada akhirnya akan dirutekan ke instance perf ketika permintaan tersebut mencapai layanan untuk diproses.
Ini sepenuhnya didorong oleh konfigurasi, dan pemuatan panas, kami dapat dengan mudah menyesuaikan persentase beban kerja menggunakan otomatisasi tanpa harus menerapkan rilis baru
Ini dapat diterapkan secara luas pada sebagian besar layanan kami, karena mekanismenya merupakan bagian dari gateway dan paket dasar
Satu titik perubahan juga berarti kemunduran yang mudah untuk mengurangi risiko dalam produksi

Selagi mentransformasikan solusi kami menjadi lebih cloud-native, kami juga menjajaki bagaimana kami dapat membangun pendekatan serupa untuk mendukung perutean lalu lintas lain yang ditawarkan oleh penyedia cloud publik atau Kubernetes.
Analisis kenari otomatis untuk meminimalkan risiko dampak pengguna
Penerapan Canary adalah strategi penerapan untuk mengurangi risiko penerapan versi perangkat lunak baru ke dalam produksi. Biasanya melibatkan penerapan versi baru perangkat lunak, yang disebut rilis canary, ke sekelompok kecil pengguna bersama dengan versi yang berjalan stabil. Kami kemudian membagi lalu lintas antara dua versi sehingga sebagian permintaan masuk dialihkan ke canary.
Kualitas versi kenari kemudian dinilai dengan apa yang disebut analisis kenari. Ini membandingkan metrik utama yang menggambarkan perilaku versi lama dan baru. Jika ada penurunan metrik yang signifikan, canary akan dibatalkan, dan semua lalu lintas dialihkan ke versi stabil untuk meminimalkan dampak perilaku yang tidak terduga.
Kami menggunakan konsep yang sama untuk membangun solusi pengujian beban otomatis. Solusi ini menggunakan platform Kayenta untuk analisis kenari otomatis (ACA) melalui Spinnaker untuk memungkinkan penerapan kenari otomatis. Alur uji beban tipikal kami saat mengikuti metode ini terlihat seperti ini:
Melalui alur kerja, kami secara bertahap menambahkan beban lalu lintas (misalnya, 5%, 10%, 25%, 50%) ke host target seperti yang ditentukan atau hingga mencapai titik puncaknya.
Pada setiap pemuatan, analisis canary dijalankan berulang kali dengan Kayenta selama beberapa waktu (misalnya, 5 menit) untuk membandingkan metrik utama dari host yang diuji dengan periode pramuat sebagai dasar dan periode pascamuat saat ini sebagai eksperimen.
Perbandingan (model konfigurasi canary) berfokus pada pemeriksaan apakah host target:
Mencapai batasan sumber daya, misalnya penggunaan CPU melebihi 90%.
Memiliki peningkatan signifikan dalam metrik kegagalan, misalnya log kesalahan, pengecualian HTTP, atau penolakan batas laju.
Apakah metrik aplikasi inti masih masuk akal, misalnya latensi HTTP kurang dari 2 detik (dapat disesuaikan untuk setiap layanan)
Untuk setiap analisis, Kayenta memberi kami laporan untuk menunjukkan hasilnya, dan pengujian segera dihentikan jika terjadi kegagalan.
Deteksi kegagalan ini biasanya memerlukan waktu kurang dari 30 detik, sehingga secara signifikan mengurangi kemungkinan berdampak pada pengalaman pengguna akhir kami.

Mengaktifkan Wawasan Data
Sangat penting untuk mengumpulkan informasi yang memadai tentang semua proses dan eksekusi pengujian yang dijelaskan sebelumnya. Tujuan utamanya adalah meningkatkan keandalan dan ketahanan sistem kami, yang tidak mungkin terjadi tanpa wawasan data.
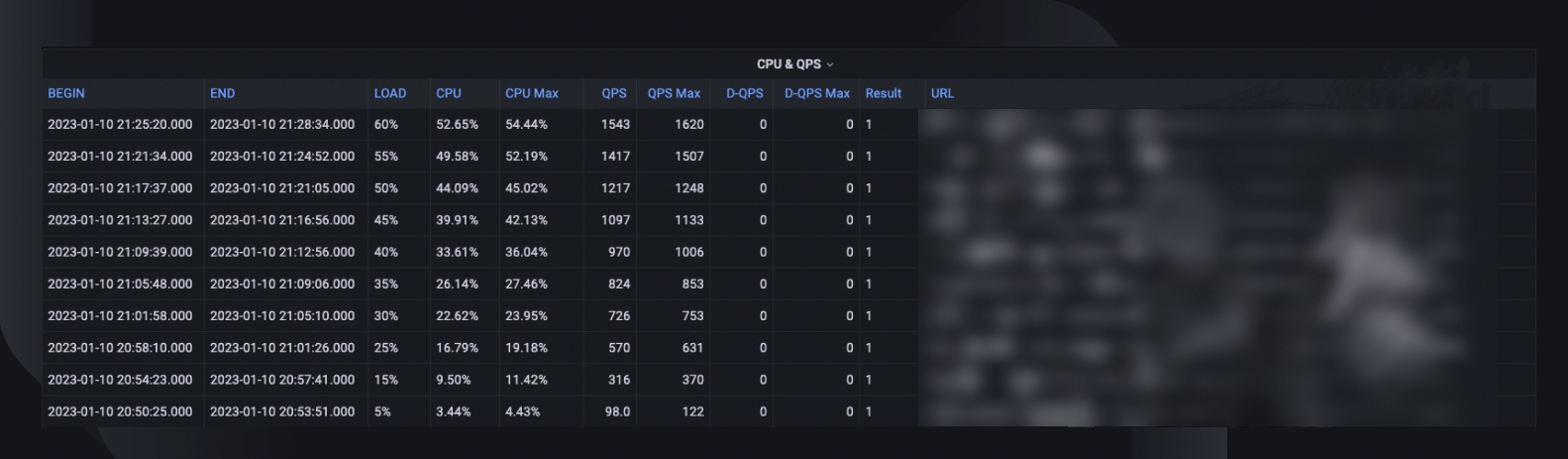
Ringkasan pengujian keseluruhan mencatat persen beban maksimum yang dapat ditangani oleh host, penggunaan CPU puncak, dan QPS host. Berdasarkan hal tersebut, kami juga memperkirakan jumlah instans yang mungkin perlu kami terapkan untuk memenuhi reservasi kapasitas kami, mengingat QPS layanan yang selalu tertinggi.
Informasi berharga lainnya untuk analisis mencakup versi perangkat lunak, spesifikasi server, jumlah penerapan, dan tautan ke dasbor monitor tempat kita dapat melihat kembali apa yang terjadi selama pengujian.

Kurva benchmark menunjukkan perubahan kinerja selama tiga bulan terakhir sehingga kami dapat menemukan kemungkinan masalah terkait rilis aplikasi tertentu.

Tren CPU & QPS menunjukkan bagaimana penggunaan CPU berkorelasi dengan volume permintaan yang harus ditangani server. Metrik ini dapat membantu memperkirakan ruang kepala server untuk pertumbuhan lalu lintas masuk.
Perilaku latensi API menunjukkan bagaimana waktu respons bervariasi dalam kondisi pemuatan yang berbeda untuk lima API teratas. Kami kemudian dapat mengoptimalkan sistem jika diperlukan pada tingkat API individual.

Metrik distribusi beban API membantu kami memahami bagaimana komposisi API memengaruhi kinerja layanan dan memberikan lebih banyak wawasan tentang area peningkatan.
Normalisasi dan produksi
Seiring dengan pertumbuhan dan perkembangan sistem kami, kami akan terus melacak dan meningkatkan stabilitas dan keandalan layanan. Kami akan melanjutkannya melalui:
Jadwal pengujian beban yang teratur dan ditetapkan untuk layanan penting.
Pengujian beban otomatis sebagai bagian dari pipeline CI/CD kami.
Peningkatan produksi seluruh solusi untuk mempersiapkan adopsi skala besar di seluruh organisasi yang lebih luas.
Keterbatasan
Ada beberapa keterbatasan pada pendekatan uji beban saat ini:
Perutean berbasis FlowFlag hanya berlaku untuk kerangka layanan mikro kami. Kami ingin memperluas solusi ini ke lebih banyak skenario perutean dengan memanfaatkan fitur perutean tertimbang yang umum pada penyeimbang beban cloud atau Kubernetes Ingress.
Karena kami mendasarkan pengujian pada lalu lintas pengguna nyata dalam produksi, kami tidak dapat melakukan pengujian fitur terhadap API atau kasus penggunaan tertentu. Selain itu, untuk layanan dengan volume yang sangat rendah, nilainya akan terbatas karena kami mungkin tidak dapat mengidentifikasi hambatannya.
Kami melakukan pengujian ini terhadap layanan individual, bukan mencakup rantai panggilan end-to-end.
Pengujian dalam produksi terkadang dapat berdampak pada pengguna sebenarnya jika terjadi kegagalan. Oleh karena itu kita harus memiliki analisis kesalahan dan auto-rollback dengan kemampuan otomatisasi penuh.
Menutup Pikiran
Penting bagi kami untuk memikirkan skenario lonjakan lalu lintas untuk mencegah kelebihan beban sistem dan memastikan waktu operasionalnya. Itu sebabnya kami membangun manajemen kapasitas dan proses pengujian beban yang dijelaskan di seluruh artikel ini. Untuk meringkas:
Manajemen kapasitas kami didorong oleh puncak dan tertanam dalam setiap tahapan siklus hidup layanan, mencegah kelebihan beban dengan aktivitas seperti pengukuran, pengaturan prioritas, peringatan dan laporan kapasitas, dll. Hal inilah yang membuat proses dan kebutuhan Binance unik dibandingkan dengan situasi manajemen kapasitas pada umumnya. .
Tolok ukur layanan yang diperoleh dari pengujian beban merupakan titik fokus manajemen dan perencanaan kapasitas. Ini secara akurat menentukan sumber daya infrastruktur yang diperlukan untuk mendukung tuntutan bisnis saat ini dan masa depan. Hal ini pada akhirnya harus dilakukan dalam produksi dengan solusi unik yang dibuat oleh Binance yang memungkinkan kami memenuhi kebutuhan spesifik kami.
Dengan semua ini disatukan, kami berharap Anda dapat melihat bahwa perencanaan yang baik dan kerangka kerja yang menyeluruh membantu menciptakan layanan yang diketahui dan dinikmati oleh Binancians.
Referensi
Dominic Ogbonna, A-Z Manajemen Kapasitas: Panduan Praktis untuk Menerapkan Pemantauan TI & Perencanaan Kapasitas Perusahaan, Bab 4, Bab 6
Luis Quesada Torres, Doug Colish, SRE Praktik Terbaik untuk Manajemen Kapasitas
Alejandro Forero Cuervo, Sarah Chavis, buku Google SRE, Bab 21 - Menangani Kelebihan Beban
Bacaan lebih lanjut
(Blog) Bagaimana Binance Ledger Mendukung Pengalaman Binance Anda
(Blog) Memperkenalkan Binance Oracle VRF: Generasi Berikutnya dari Keacakan yang Dapat Diverifikasi
(Blog) Binance Bergabung dengan Aliansi FIDO dalam Persiapan Implementasi Kunci Sandi