
Principaux points à retenir
Chez Binance, nous utilisons l'apprentissage automatique (ML) pour résoudre divers problèmes commerciaux, y compris, mais sans s'y limiter, la fraude par piratage de compte (ATO), les escroqueries P2P et les informations de paiement volées.
À l'aide d'opérations d'apprentissage automatique (MLOps), nos data scientists de Binance Risk AI ont construit un pipeline de ML de bout en bout en temps réel qui fournit en permanence des services de ML prêts pour la production.

Pourquoi utilisons-nous MLOps ?
Pour commencer, la création d’un service ML est un processus itératif. Les data scientists expérimentent constamment pour améliorer une métrique spécifique, hors ligne ou en ligne, en fonction de l'objectif de créer de la valeur pour l'entreprise. Alors, comment pouvons-nous rendre ce processus plus efficace, par exemple en raccourcissant le délai de mise sur le marché du modèle ML ?
Deuxièmement, le comportement des services ML est affecté non seulement par le code que nous, les développeurs, définissons, mais également par les données qu'il collecte. Cette idée, également connue sous le nom de dérive conceptuelle, est soulignée dans l'article de Google intitulé Hidden Technical Debt in Machine Learning Systems.
Prenons l'exemple de la fraude ; l'escroc n'est pas seulement une machine mais un humain qui s'adapte et change constamment sa façon d'attaquer. En tant que telle, la distribution des données sous-jacentes évoluera pour refléter les changements dans les vecteurs d’attaque. Comment pouvons-nous garantir efficacement que le modèle de production prend en compte le dernier modèle de données ?
Pour surmonter les défis mentionnés ci-dessus, nous utilisons un concept appelé MLOps, un terme initialement proposé par Google en 2018. Dans MLOps, nous nous concentrons sur les performances du modèle et l'infrastructure supportant le système de production. Cela nous permet de créer des services ML évolutifs, hautement disponibles, fiables et maintenables.
Décomposer notre pipeline de ML de bout en bout en temps réel
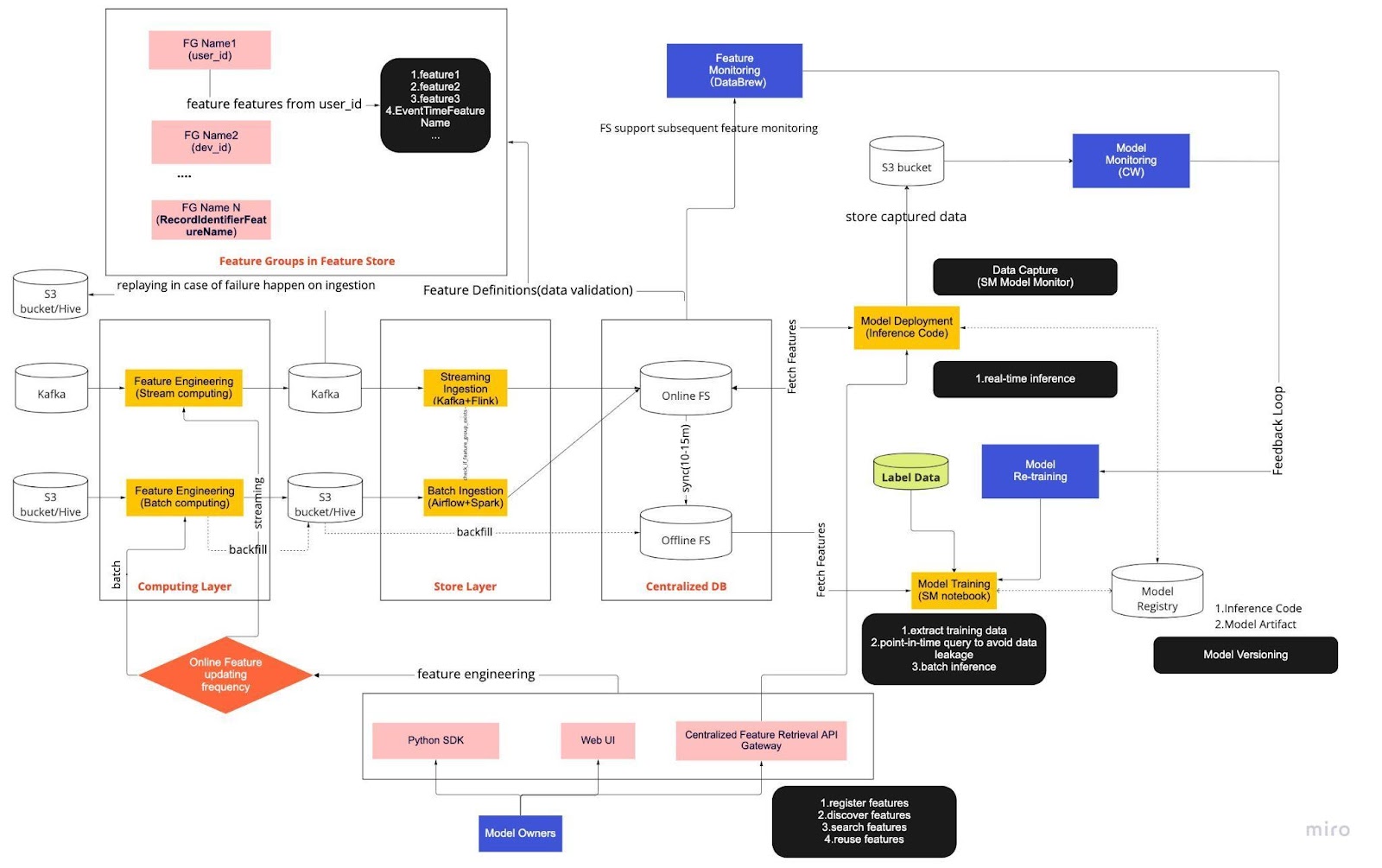
Considérez le diagramme ci-dessus comme notre procédure opérationnelle standard (SOP) pour le développement de modèles en temps réel avec un magasin de fonctionnalités. Le pipeline ML de bout en bout dicte la manière dont notre équipe applique les MLops, et il est construit avec deux types d'exigences : fonctionnelles et non fonctionnelles.
Fonctionnel
Traitement de l'information
Formation sur modèle
Développement d'un modèle
Déploiement du modèle
Surveillance
Prérogatives non fonctionnelles
Évolutif
Hautement disponible
Fiable
Maintenable
Le pipeline est divisé en six éléments clés :
Couche informatique
Couche de magasin
Base de données centralisée
Formation sur modèle
Déploiement du modèle
Surveillance du modèle
1. Couche informatique

La couche informatique est principalement responsable de l’ingénierie des fonctionnalités, le processus de transformation des données brutes en fonctionnalités utiles.
Nous classons la couche informatique en deux types en fonction de la fréquence de mise à jour : le calcul en flux pour des intervalles d'une minute/seconde et le calcul par lots pour des intervalles quotidiens/heures.
Les données d'entrée de la couche informatique proviennent généralement de la base de données événementielle, qui comprend Apache Kafka et Kinesis, ou de la base de données OLAP, qui comprend Apache Hive pour l'open source et Snowflake pour les solutions cloud.
2. Couche de magasin
La couche magasin est l'endroit où nous enregistrons les définitions de fonctionnalités et les déployons dans notre magasin de fonctionnalités ainsi que effectuons le remplissage, un processus qui nous permet de reconstruire les fonctionnalités via des données historiques chaque fois qu'une nouvelle fonctionnalité est définie. Le remplissage est généralement une tâche ponctuelle que nos data scientists peuvent effectuer dans un environnement de bloc-notes. Étant donné que Kafka ne peut stocker que les événements des sept derniers jours, il utilise un mécanisme de sauvegarde dans la table s3/hive pour augmenter la tolérance aux pannes.
Vous remarquerez que la couche intermédiaire, Hive et Kafka, est délibérément logée entre les couches informatique et magasin. Considérez cet emplacement comme un tampon entre les fonctionnalités informatiques et d'écriture. Une analogie serait de séparer le producteur du consommateur. L’informatique de flux est le producteur, tandis que l’ingestion de flux est le consommateur.
Le découplage du calcul et de l’ingestion offre de nombreux avantages pour nos pipelines ML. Pour commencer, nous pouvons augmenter la robustesse du pipeline en cas de panne. Nos data scientists peuvent toujours extraire la valeur des fonctionnalités de la base de données centralisée, même si la couche d'ingestion ou de calcul n'est pas disponible en raison de problèmes opérationnels, matériels ou réseau.
De plus, nous pouvons adapter individuellement différentes parties de l’infrastructure et réduire l’énergie nécessaire à la construction et à l’exploitation du pipeline. Par exemple, en cas d'échec pour une raison quelconque, la couche d'ingestion ne bloquera pas la couche informatique. Sur le plan de l'innovation, nous pouvons expérimenter et adopter de nouvelles technologies, comme une nouvelle version de l'application Flink, sans affecter notre infrastructure existante.

La couche informatique et la couche magasin sont ce que nous appelons des pipelines de fonctionnalités automatisés. Ces pipelines sont indépendants, s'exécutent selon des calendriers variables et sont classés en pipelines de streaming ou par lots. Voici comment les deux pipelines fonctionnent différemment : un groupe de fonctionnalités dans un pipeline par lots peut s'actualiser la nuit tandis qu'un autre groupe est mis à jour toutes les heures. Dans un pipeline de streaming, le groupe de fonctionnalités est mis à jour en temps réel à mesure que les données sources arrivent sur un flux d'entrée, tel qu'un sujet Apache Kafka.
3. Base de données centralisée
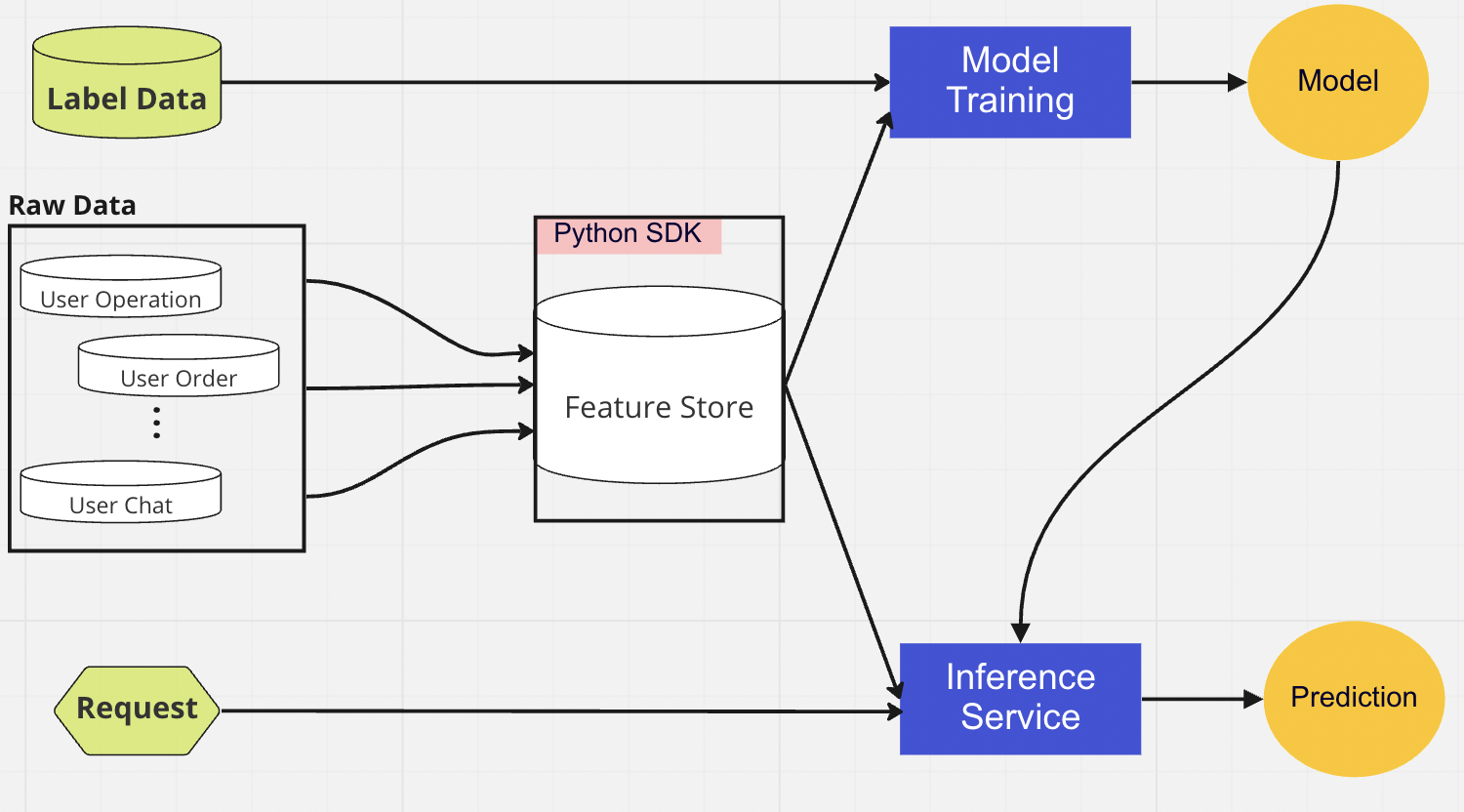
La couche de base de données centralisée est l'endroit où nos data scientists présentent leurs données prêtes pour les fonctionnalités dans un magasin de fonctionnalités en ligne ou hors ligne.
Le magasin de fonctionnalités en ligne est un magasin à faible latence et à haute disponibilité qui permet une recherche d'enregistrements en temps réel. D'autre part, le magasin de fonctionnalités hors ligne fournit un référentiel sécurisé et évolutif de toutes les données de fonctionnalités. Cela permet aux scientifiques de créer des ensembles de données de formation, de validation ou de notation par lots à partir d'un ensemble de groupes de fonctionnalités gérés de manière centralisée avec un historique complet des valeurs de fonctionnalités dans le système de stockage d'objets.
Les deux magasins de fonctionnalités se synchronisent automatiquement toutes les 10 à 15 minutes pour éviter un décalage entre la formation et la diffusion. Dans un prochain article, nous examinerons en profondeur la façon dont nous utilisons les magasins de fonctionnalités dans les pipelines.
4. Formation sur modèle
La couche de formation du modèle est l'endroit où nos scientifiques extraient les données de formation du magasin de fonctionnalités hors ligne pour affiner nos services ML. Nous utilisons des requêtes ponctuelles pour empêcher les données de fuir pendant le processus d'extraction.
De plus, cette couche comprend un composant crucial appelé boucle de rétroaction de recyclage du modèle. Le recyclage des modèles minimise le risque de dérive des concepts en garantissant que les modèles déployés représentent avec précision les derniers modèles de données (par exemple, un pirate informatique modifiant son comportement d'attaque).
5. Déploiement du modèle
Pour le déploiement du modèle, nous utilisons principalement un service de notation basé sur le cloud comme épine dorsale de notre service de données en temps réel. Voici un diagramme montrant comment le code d'inférence actuel s'intègre au magasin de fonctionnalités.

6. Surveillance du modèle
Dans cette couche, notre équipe surveille les métriques d'utilisation des services d'évaluation tels que le QPS, la latence, la mémoire et le taux d'utilisation du CPU/GPU. Outre ces métriques de base, nous utilisons les données capturées pour vérifier la distribution des fonctionnalités au fil du temps, l'asymétrie entre la formation et la diffusion et la dérive des prédictions afin de garantir une dérive minimale du concept.
Pensées finales
Pour conclure, diviser vaguement notre infrastructure de pipeline en une couche informatique, une couche de stockage et une base de données centralisée nous offre trois avantages clés par rapport à une architecture plus étroitement couplée.
Des pipelines plus robustes en cas de panne
Flexibilité accrue dans le choix des outils à mettre en œuvre
Composants évolutifs indépendamment
Vous souhaitez utiliser le ML pour protéger le plus grand écosystème cryptographique au monde et ses utilisateurs ? Consultez Binance Engineering/AI sur notre page Carrières pour les offres d'emploi ouvertes.