
Principaux points à retenir
Binance exploite la gestion de la capacité pour les pics de trafic imprévus causés par une forte volatilité, garantissant ainsi une infrastructure et des ressources informatiques adéquates et opportunes pour répondre aux demandes des entreprises.
Tests de charge Binance dans l'environnement de production (plutôt que dans un environnement de test) pour obtenir des références de service précises. Cette méthode permet de valider que notre allocation de ressources est adéquate pour servir une charge définie.
L'infrastructure de Binance gère de grandes quantités de trafic, et le maintien d'un service sur lequel les utilisateurs peuvent compter nécessite une gestion appropriée de la capacité et des tests de charge automatiques.

Pourquoi Binance a-t-il besoin d'un processus de gestion de capacité spécialisé ?
La gestion de la capacité est le fondement de la stabilité du système. Cela implique de dimensionner correctement les ressources d'application et d'infrastructure en fonction des demandes commerciales actuelles et futures, au juste coût. Pour aider à atteindre cet objectif, nous construisons des outils et des pipelines de gestion de capacité pour éviter la surcharge et aider les entreprises à offrir une expérience utilisateur fluide.
Les marchés des cryptomonnaies sont souvent confrontés à des périodes de volatilité plus régulières que les marchés financiers traditionnels. Cela signifie que le système de Binance doit résister à cette augmentation de trafic de temps en temps alors que les utilisateurs réagissent aux mouvements du marché. Avec une bonne gestion de la capacité, nous maintenons une capacité adéquate pour répondre à la demande commerciale générale et à ces scénarios de pointe de trafic. Ce point clé est exactement ce qui rend les processus de gestion de capacité de Binance uniques et stimulants.
Examinons les facteurs qui entravent souvent le processus et conduisent à un service lent ou indisponible. Premièrement, nous avons une surcharge, généralement causée par une augmentation soudaine du trafic. Par exemple, cela peut résulter d’un événement marketing, d’une notification push ou même d’une attaque DDoS (déni de service distribué).
L'augmentation du trafic et la capacité insuffisante affectent la fonctionnalité du système comme suit :
Le service prend de plus en plus de travail.
Le temps de réponse augmente au point qu’aucune demande ne peut recevoir de réponse dans le délai d’attente du client. Cette dégradation se produit généralement en raison d'une saturation des ressources (CPU, mémoire, IO, réseau, etc.) ou de pauses GC prolongées dans le service lui-même ou ses dépendances.
Le résultat est que le service ne sera pas en mesure de traiter les demandes rapidement.
Décomposer le processus
Maintenant que nous avons discuté du principe général de la gestion de la capacité, voyons comment Binance l'applique à son activité. Voici un aperçu de l'architecture de notre système de gestion de capacité avec quelques flux de travail clés.
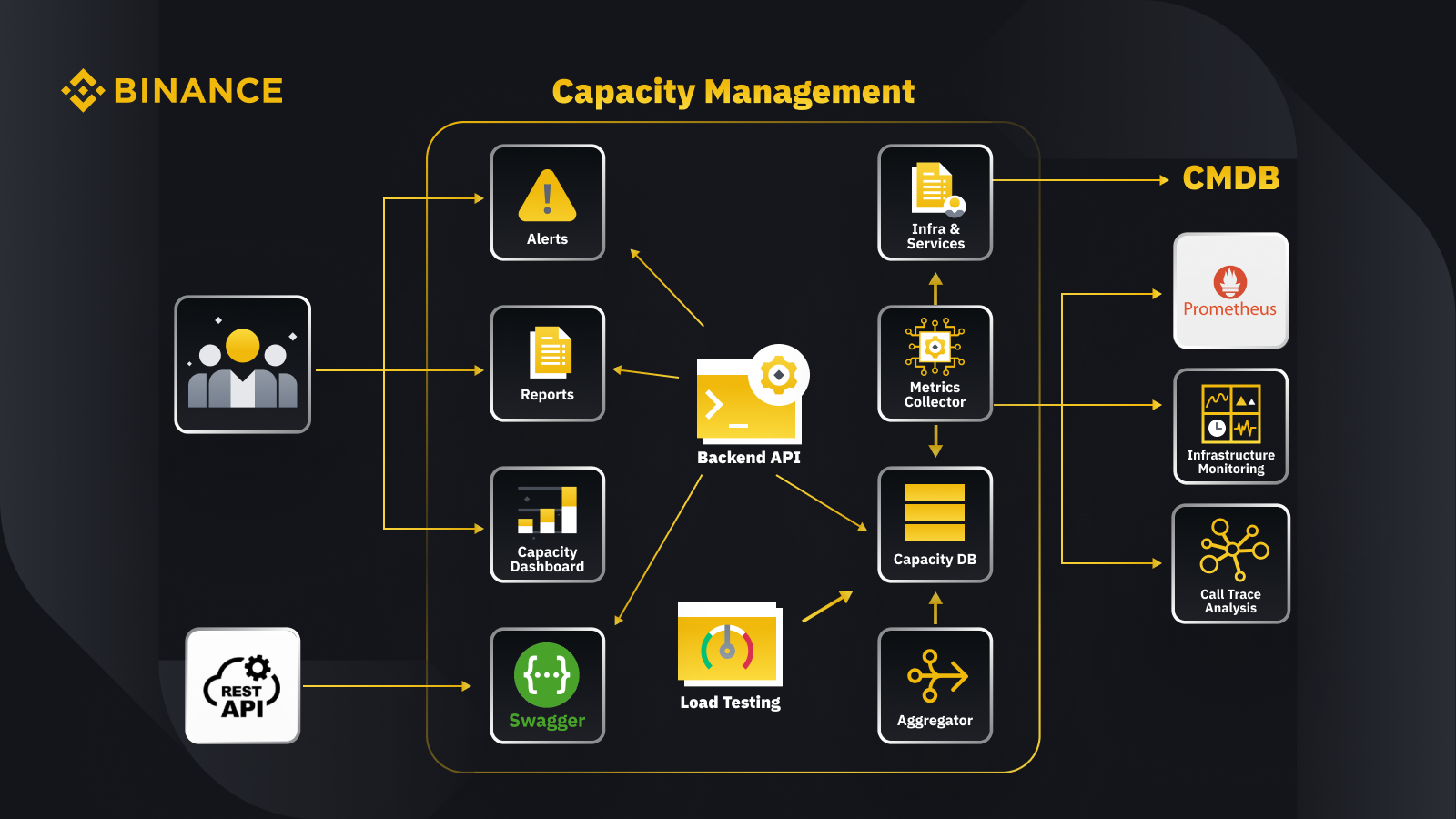
En récupérant les données de la base de données de gestion des configurations (CMDB), nous générons les configurations d'infrastructure et de services. Les éléments de ces configurations sont les objets de gestion de capacité.
Le collecteur de métriques récupère les métriques de capacité de Prometheus pour les données de la couche métier et de service, de Surveillance de l'infrastructure pour les métriques de la couche de ressources et du système d'analyse de trace d'appels pour les informations de trace. Le collecteur de métriques stocke les données dans la base de données de capacité (CDB).
Le système de tests de charge effectue des tests de résistance sur les services et stocke les données de référence dans la CDB.
L'agrégateur obtient les données de capacité de CDB et les agrège pour les dimensions quotidiennes et record (ATH). Après l'agrégation, il réécrit les données agrégées dans la CDB.
En traitant les données de la CDB, l'API backend fournit des interfaces pour le tableau de bord de capacité, les alertes et les rapports, ainsi que le reste de l'API et les données de capacité associées pour l'intégration.
Les parties prenantes obtiennent des informations sur la capacité grâce au tableau de bord de capacité, aux alertes et aux rapports. Ils peuvent également utiliser d'autres systèmes connexes, notamment la surveillance des données de capacité des services avec l'API restante fournie par le système de gestion de capacité avec Swagger.
Stratégie
Notre stratégie de gestion et de planification des capacités repose sur un traitement axé sur les pics de production. Le traitement piloté par les pics est la charge de travail subie par les ressources d'un service (serveurs Web, bases de données, etc.) pendant les pics d'utilisation.
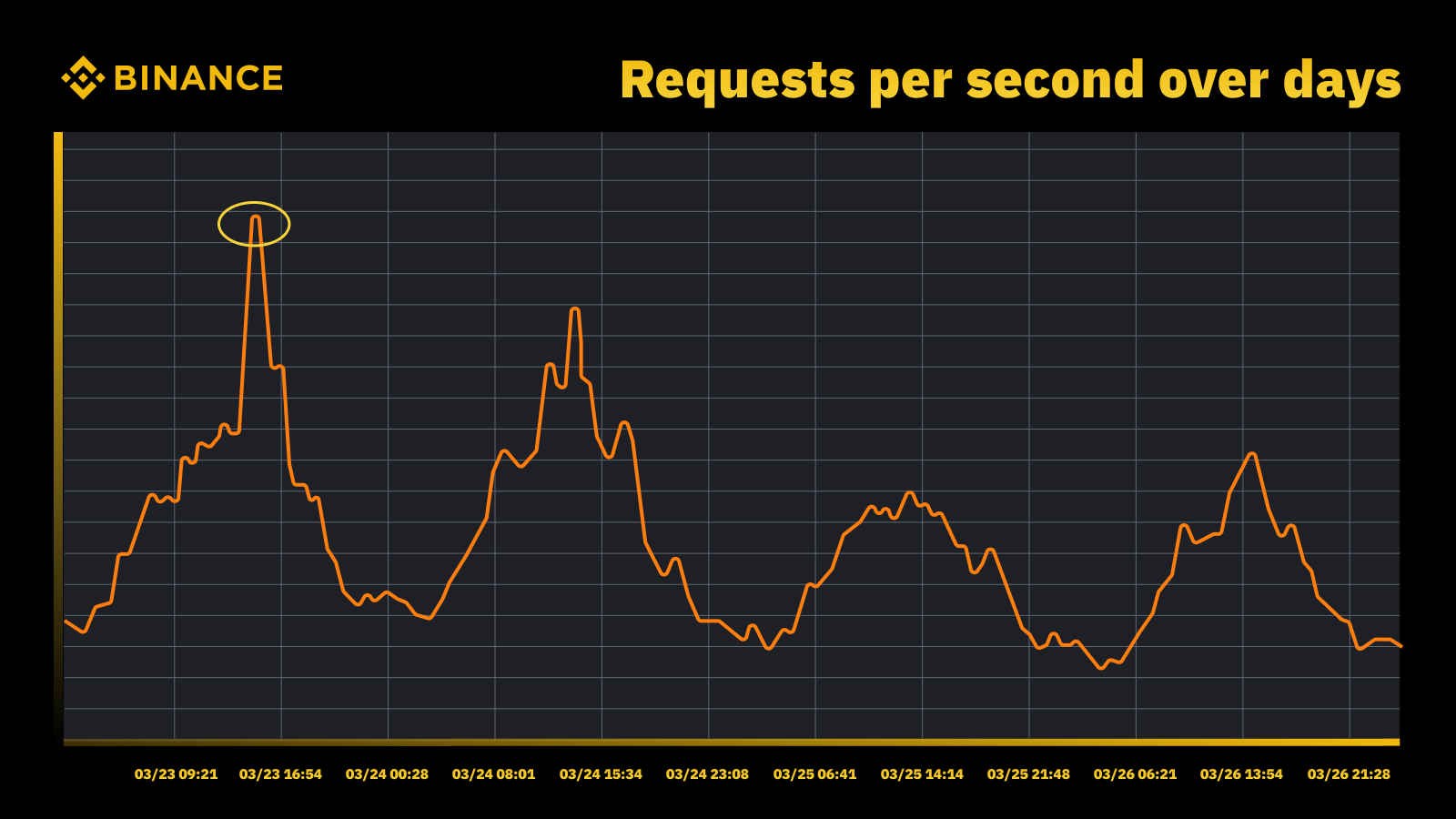
Augmentation du trafic lorsque la Fed a augmenté ses taux en mars 2023
Nous analysons les pics périodiques et les utilisons pour déterminer la trajectoire de capacité. Comme pour toute ressource soumise à des pics, nous souhaitons savoir quand les pics se produisent, puis explorer ce qui se passe réellement au cours de ces cycles.
Une autre chose importante que nous prenons en compte en plus de prévenir la surcharge est la mise à l'échelle automatique. La mise à l'échelle automatique gère la surcharge en augmentant dynamiquement la capacité avec davantage d'instances du service. Le trafic excédentaire est ensuite distribué et le trafic géré par une seule instance du service (ou de la dépendance) reste gérable.
L'autoscaling a sa place, mais ne parvient pas à gérer seul les situations de surcharge. Il ne peut généralement pas réagir assez rapidement à une augmentation soudaine du trafic et ne fonctionne mieux que lorsqu’il y a une augmentation progressive.
La mesure
La mesure joue un rôle crucial dans le travail de gestion de la capacité de Binance, et la collecte de données est notre première étape de mesure. Sur la base des normes ITIL (Information Technology Infrastructure Library), nous collectons des données à des fins de mesure dans les sous-processus de gestion de la capacité, à savoir :
Ressource : consommation des ressources de l'infrastructure informatique en fonction de l'utilisation des applications/services. Se concentre sur les mesures de performances internes des ressources informatiques physiques et virtuelles, notamment le processeur du serveur, la mémoire, le stockage sur disque, la bande passante du réseau, etc.
Service. Les mesures de performances au niveau des applications, de SLA, de latence et de débit qui découlent des activités commerciales. Se concentre sur les mesures de performances externes basées sur la façon dont les utilisateurs perçoivent le service, y compris la latence du service, le débit, les pics, etc.
Entreprise. Collecte des données qui mesurent les activités commerciales traitées par l'application cible, notamment les commandes, l'enregistrement des utilisateurs, les paiements, etc.
Une gestion de la capacité basée uniquement sur l’utilisation des ressources de l’infrastructure conduira à une planification inexacte. En effet, cela ne représente peut-être pas les volumes d’activité et le débit réels qui déterminent la capacité de notre infrastructure.
Les événements programmés constituent un excellent endroit pour en discuter davantage. Participez au Watch Web Summit 2022 sur Binance Live pour partager jusqu'à 15 000 BUSD dans la campagne Crypto Box Rewards. Outre les mesures sous-jacentes des ressources et des couches de services, nous devions également prendre en compte les volumes d’activité. Nous avons basé ici la planification de la capacité sur des mesures commerciales telles que le nombre estimé de spectateurs en direct, le nombre maximal de demandes en vol pour une Crypto Box, la latence de bout en bout et d'autres facteurs.
Après avoir collecté les données, nos processus de gestion de capacité regroupent et résument les nombreux points de données collectés par rapport à un facteur de capacité spécifique. La valeur agrégée d'une métrique est une valeur unique qui peut être utilisée dans les alertes de capacité, les rapports et d'autres fonctions liées à la capacité.
Nous pouvons appliquer plusieurs méthodes d'agrégation de données à des points de données périodiques, comme la somme, la moyenne, la médiane, le minimum, le maximum, le centile et le plus haut historique (ATH).

La méthode que nous avons choisie détermine les résultats du processus de gestion de la capacité et les décisions qui en résultent. Nous sélectionnons différentes méthodes en fonction de différents scénarios. Par exemple, nous utilisons la méthode maximale pour les services critiques et les points de données associés. Pour enregistrer le trafic le plus élevé, nous utilisons la méthode ATH.
Pour différents cas d'utilisation, nous utilisons différents types de granularité pour l'agrégation des données. Dans la plupart des cas, nous utilisons soit les minutes, les heures, les jours ou ATH.
Avec une granularité infime, nous mesurons la charge de travail d'un service pour des alertes de surcharge en temps opportun.
Nous utilisons des données horaires agrégées pour créer des données quotidiennes et agréger les données horaires pour enregistrer le pic quotidien.
En règle générale, nous utilisons des données quotidiennes pour les rapports de capacité et exploitons les données ATH pour la modélisation et la planification de la capacité.
L’analyse comparative des services est l’une des principales mesures de gestion de la capacité. Cela nous aide à mesurer avec précision les performances et la capacité des services. Nous obtenons le benchmark du service avec des tests de charge, et nous y reviendrons plus en détail plus tard.
Gestion de la capacité basée sur la priorité
Jusqu’à présent, nous avons vu comment nous collectons des mesures de capacité et regroupons les données dans différents types de granularité. Un autre domaine critique à discuter est la priorité, qui est utile dans le contexte des rapports d’alerte et de capacité. Après avoir classé les actifs informatiques, l'utilisation limitée de l'infrastructure et les ressources informatiques sont priorisées et affectées en premier aux services et activités critiques.
Il existe plusieurs façons de définir le service et la criticité des demandes. Une référence utile est Google. Dans le livre SRE. Ils définissent les niveaux de criticité comme CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS etc. De même, nous définissons plusieurs niveaux de priorité tels que P0, P1, P2 et ainsi de suite.
Nous définissons les niveaux de priorité comme suit :
P0 : Pour les services et demandes les plus critiques, ceux qui entraîneront un impact sérieux et visible par l'utilisateur en cas d'échec.
P1 : pour les services et les demandes qui entraîneront un impact visible par l'utilisateur, mais l'impact est inférieur à ceux de P0. Les services P0 et P1 devraient être fournis avec une capacité suffisante.
P2 : il s'agit de la priorité par défaut pour les tâches par lots et les tâches hors ligne. Ces services et demandes peuvent ne pas entraîner d'impact visible par l'utilisateur s'ils sont partiellement indisponibles.
Qu'est-ce que les tests de charge et pourquoi les utilisons-nous dans un environnement de production ?
Les tests de charge sont un processus de test logiciel non fonctionnel dans lequel les performances d'une application sont testées sous une charge de travail spécifique. Cela permet de déterminer le comportement de l'application lorsqu'elle est accessible simultanément par plusieurs utilisateurs finaux.
Chez Binance, nous avons créé une solution pour nous permettre d'exécuter des tests de charge en production. Généralement, les tests de charge sont exécutés dans un environnement de test, mais nous ne pouvions pas utiliser cette option en fonction de nos objectifs globaux de gestion de capacité. Les tests de charge dans un environnement de production nous ont permis de :
Collectez une évaluation précise de nos services dans des conditions de charge réelles.
Augmentez la confiance dans le système, sa fiabilité et ses performances.
Identifiez les goulots d'étranglement dans le système avant qu'ils ne surviennent dans l'environnement de production.
Permettre une surveillance continue des environnements de production.
Activez une gestion proactive des capacités avec des cycles de tests normalisés qui se produisent régulièrement.
Ci-dessous, vous pouvez voir notre cadre de test de charge avec quelques points clés à retenir :

Le cadre de microservices de Binance dispose d'une couche de base pour prendre en charge le routage du trafic basé sur la configuration et basé sur des indicateurs, ce qui est essentiel pour notre approche TIP.
L'analyse Canary automatisée (ACA) est adoptée pour évaluer l'instance que nous testons. Il compare les mesures clés collectées dans le système de surveillance, afin que nous puissions suspendre/terminer le test si un problème inattendu survient afin de minimiser les impacts sur les utilisateurs.
Des benchmarks et des métriques sont collectés lors des tests de charge pour générer des informations sur les données concernant les comportements et les performances des applications.
Les API sont exposées pour partager des données de performances précieuses dans divers scénarios, par exemple la gestion des capacités et l'assurance qualité. Cela contribue à construire un écosystème ouvert.
Nous créons des workflows d'automatisation pour orchestrer toutes les étapes et points de contrôle du point de vue des tests de bout en bout. Nous offrons également la flexibilité d'intégration avec d'autres systèmes, tels que le pipeline CI/CD et le portail d'exploitation.
Notre approche de tests en production (TIP)
Une approche traditionnelle de test de performances (exécution de tests dans un environnement de test avec un trafic simulé ou mis en miroir) offre certains avantages. Cependant, le déploiement d'un environnement de test de type production présente davantage d'inconvénients dans notre contexte :
Cela double presque le coût de l’infrastructure et les efforts de maintenance.
Il est incroyablement complexe de faire fonctionner le système de bout en bout en production, en particulier dans un environnement de microservices à grande échelle réparti sur plusieurs unités commerciales.
Cela ajoute davantage de risques en matière de confidentialité et de sécurité des données, car nous devrons inévitablement dupliquer les données lors de la préparation.
Le trafic simulé ne reproduira jamais ce qui se passe réellement en production. Le benchmark obtenu dans l'environnement de préparation serait inexact et aurait moins de valeur
Les tests en production, également connus sous le nom de TIP, sont une méthodologie de test Shift-Right dans laquelle les nouveaux codes, fonctionnalités et versions sont testés dans l'environnement de production. Les tests de charge en production que nous avons adoptés sont très bénéfiques car ils nous aident à :
Analyser la stabilité et la robustesse du système.
Découvrez les benchmarks et les goulots d'étranglement des applications sous différents niveaux de trafic, spécifications de serveur et paramètres d'application.
Routage basé sur FlowFlag
Notre routage basé sur FlowFlag intégré dans le cadre de base du microservice constitue la base pour rendre le TIP possible. Cela est vrai pour des cas spécifiques, notamment les applications utilisant la découverte de services Eureka pour la distribution du trafic.
Comme illustré dans le diagramme, le serveur Web Binance en tant que points d'entrée étiquette un certain pourcentage du trafic comme spécifié dans les configurations avec les en-têtes FlowFlag. Lors du test de charge, nous pouvons sélectionner un hôte d'un service spécifique et le marquer comme instance de performance cible dans le configs, ces requêtes étiquetées perf seront finalement acheminées vers l'instance perf lorsqu'elles atteindront le service pour traitement.
Il est entièrement piloté par la configuration et chargé à chaud, nous pouvons facilement ajuster le pourcentage de charge de travail en utilisant l'automatisation sans avoir à déployer une nouvelle version.
Il peut être largement appliqué à la plupart de nos services, puisque le mécanisme fait partie du package passerelle et base.
Un point de changement unique signifie également un retour en arrière facile pour réduire les risques en production

Tout en transformant notre solution pour qu'elle soit plus cloud-native, nous étudions également comment nous pouvons développer une approche similaire pour prendre en charge d'autres routages de trafic proposés par les fournisseurs de cloud public ou Kubernetes.
Analyse Canary automatisée pour minimiser les risques d'impact sur les utilisateurs
Le déploiement Canary est une stratégie de déploiement visant à réduire le risque de déploiement d'une nouvelle version du logiciel en production. Cela implique généralement le déploiement d'une nouvelle version du logiciel, appelée version Canary, auprès d'un petit sous-ensemble d'utilisateurs parallèlement à la version stable en cours d'exécution. Nous répartissons ensuite le trafic entre les deux versions afin qu'une partie des requêtes entrantes soit redirigée vers le Canary.
La qualité de la version Canary est ensuite évaluée par ce que l’on appelle l’analyse Canary. Cela compare les mesures clés qui décrivent le comportement des anciennes et des nouvelles versions. En cas de dégradation significative des métriques, Canary est abandonné et tout le trafic est acheminé vers la version stable afin de minimiser l'impact d'un comportement inattendu.
Nous utilisons le même concept pour construire notre solution de test de charge automatique. La solution utilise la plateforme Kayenta pour l'analyse automatisée des canaris (ACA) via Spinnaker pour permettre des déploiements canaris automatisés. Notre flux de test de charge typique lorsque nous suivons cette méthode ressemble à ceci :
Grâce au flux de travail, nous ajoutons progressivement la charge de trafic (par exemple, 5 %, 10 %, 25 %, 50 %) à l'hôte cible comme spécifié ou jusqu'à ce qu'il atteigne son point de rupture.
Sous chaque chargement, l'analyse Canary est exécutée à plusieurs reprises avec Kayenta pendant un certain temps (par exemple 5 minutes) pour comparer les mesures clés de l'hôte testé avec la période de pré-chargement comme référence et la période de post-chargement actuelle comme expérience.
La comparaison (modèle de configuration Canary) se concentre sur la vérification si l'hôte cible :
Atteint les contraintes de ressources, par exemple, l'utilisation du processeur dépasse 90 %.
Présente une augmentation significative des métriques d'échec, par exemple, les journaux d'erreurs, les exceptions HTTP ou les rejets de limite de débit.
Les métriques de l'application principale sont-elles toujours raisonnables, par exemple une latence HTTP inférieure à 2 secondes (personnalisable pour chaque service)
Pour chaque analyse, Kayenta nous remet un rapport indiquant le résultat, et le test se termine immédiatement en cas d'échec.
Cette détection de panne prend généralement moins de 30 secondes, ce qui réduit considérablement le risque d'impact sur l'expérience de nos utilisateurs finaux.

Activation des informations sur les données
Il est crucial de collecter suffisamment d’informations sur tous les processus et exécutions de tests décrits précédemment. L’objectif ultime est d’améliorer la fiabilité et la robustesse de notre système, ce qui est impossible sans la connaissance des données.
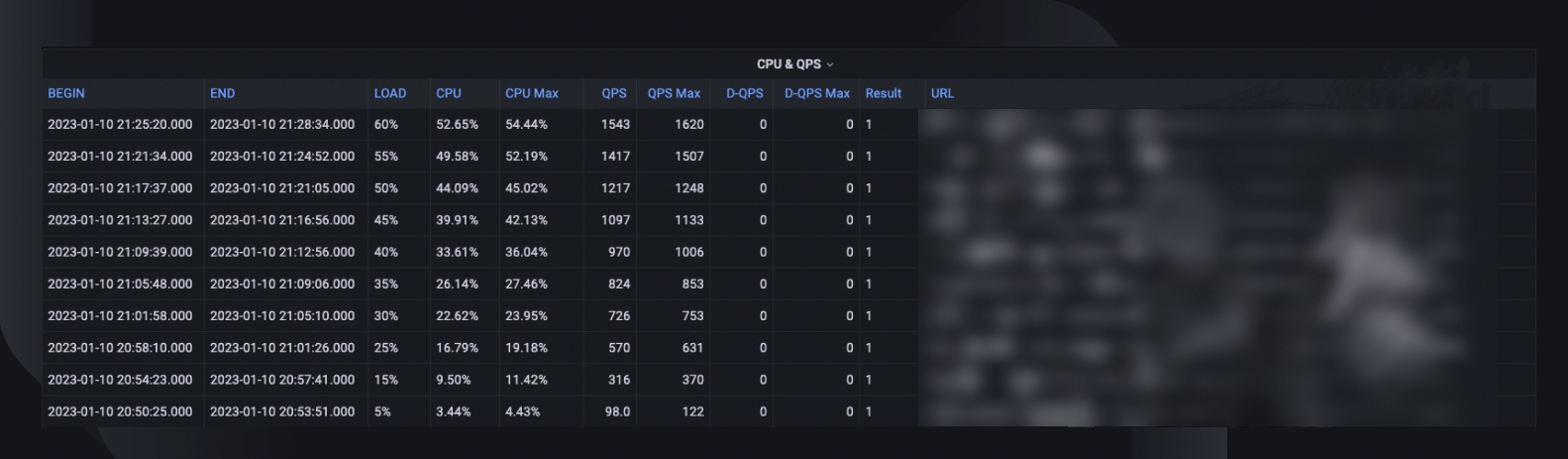
Un résumé global du test capture le pourcentage de charge maximale que l'hôte a été capable de gérer, l'utilisation maximale du processeur et le QPS de l'hôte. Sur cette base, il estime également le nombre d'instances que nous devrons peut-être déployer pour répondre à notre réservation de capacité, compte tenu du QPS record des services.
D'autres informations précieuses pour l'analyse incluent la version du logiciel, les spécifications du serveur, le nombre de déploiements et un lien vers le tableau de bord du moniteur où nous pouvons revenir sur ce qui s'est passé pendant le test.

Une courbe de référence indique l'évolution des performances au cours des trois derniers mois afin que nous puissions découvrir d'éventuels problèmes liés à une version d'application spécifique.

Les tendances CPU et QPS montrent comment l'utilisation du CPU est en corrélation avec le volume de requêtes que le serveur devait gérer. Cette mesure peut aider à estimer les marges du serveur pour la croissance du trafic entrant.
Le comportement de latence des API capture la façon dont le temps de réponse varie dans différentes conditions de charge pour les cinq principales API. Nous pouvons ensuite optimiser le système si nécessaire au niveau de l'API individuelle.

Les métriques de répartition de la charge de l'API nous aident à comprendre l'impact de la composition de l'API sur les performances du service et donnent plus d'informations sur les domaines d'amélioration.
Normalisation et productisation
À mesure que notre système continue de croître et d’évoluer, nous continuerons à suivre et à améliorer la stabilité et la fiabilité du service. Nous continuerons cela à travers :
Un calendrier de tests de charge régulier et établi pour les services critiques.
Tests de charge automatiques dans le cadre de nos pipelines CI/CD.
Production accrue de l’ensemble de la solution pour préparer son adoption à grande échelle dans l’ensemble de l’organisation.
Limites
Il existe certaines limites à l'approche actuelle des tests de charge :
Le routage basé sur FlowFlag s'applique uniquement à notre framework de microservices. Nous cherchons à étendre la solution à davantage de scénarios de routage en tirant parti de la fonctionnalité de routage pondéré commune des équilibreurs de charge cloud ou d'une entrée Kubernetes.
Étant donné que nous basons le test sur le trafic utilisateur réel en production, nous ne pouvons pas effectuer de tests de fonctionnalités sur des API ou des cas d'utilisation spécifiques. De plus, pour les services à très faible volume, la valeur serait limitée car nous ne pourrons peut-être pas identifier son goulot d'étranglement.
Nous effectuons ces tests sur des services individuels plutôt que sur des chaînes d'appels de bout en bout.
Les tests en production peuvent parfois avoir un impact sur les utilisateurs réels en cas d'échec. Par conséquent, nous devons disposer d’une analyse des pannes et d’un retour en arrière automatique avec des capacités d’automatisation complètes.
Pensées finales
Il est essentiel pour nous de réfléchir à des scénarios de pic de trafic pour éviter la surcharge du système et garantir sa disponibilité. C'est pourquoi nous avons créé les processus de gestion de capacité et de test de charge décrits tout au long de cet article. Résumer:
Notre gestion de capacité est axée sur les pics et intégrée à chaque étape du cycle de vie du service, évitant ainsi la surcharge d'activités telles que la mesure, la configuration des priorités, les alertes et les rapports de capacité, etc. C'est en fin de compte ce qui rend les processus et les besoins de Binance uniques par rapport à une situation typique de gestion de capacité. .
Le benchmark de service obtenu à partir des tests de charge est le point central de la gestion et de la planification de la capacité. Il détermine avec précision les ressources d'infrastructure nécessaires pour répondre aux demandes commerciales actuelles et futures. Cela a finalement dû être réalisé en production avec une solution unique conçue par Binance qui nous permettait de répondre à nos besoins spécifiques.
Avec tout cela mis ensemble, nous espérons que vous constaterez qu’une bonne planification et des cadres approfondis contribueront à créer le service que les Binanciens connaissent et apprécient.
Les références
Dominic Ogbonna, A-Z de la gestion des capacités : Guide pratique pour la mise en œuvre de la surveillance informatique et de la planification des capacités d'entreprise, chapitre 4, chapitre 6
Luis Quesada Torres, Doug Colish, SRE Meilleures pratiques en matière de gestion des capacités
Alejandro Forero Cuervo, Sarah Chavis, livre Google SRE, chapitre 21 - Gestion de la surcharge
Lectures complémentaires
(Blog) Comment Binance Ledger alimente votre expérience Binance
(Blog) Présentation de Binance Oracle VRF : la nouvelle génération d'aléatoire vérifiable
(Blog) Binance rejoint l'alliance FIDO pour préparer la mise en œuvre du mot de passe