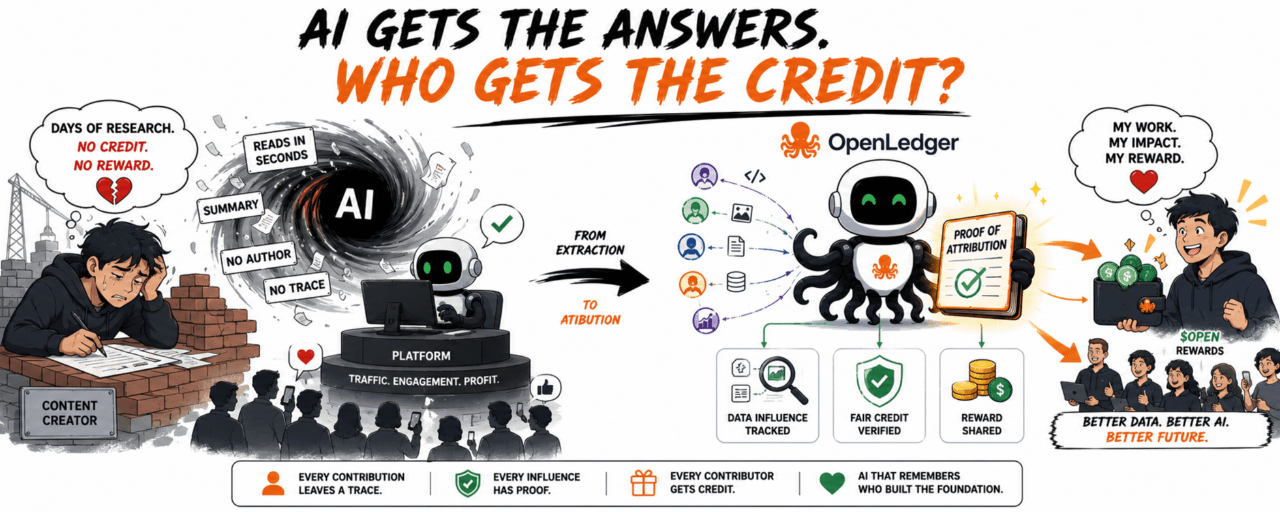
Au milieu de l'année 2024, j'ai commencé à voir de nombreux créateurs se plaindre d'une chose assez agaçante : leur travail de recherche qui prenait plusieurs jours, l'IA le lisait en quelques secondes, puis le transformait en une réponse concise sans mentionner l'auteur. Les lecteurs trouvent cela pratique. La plateforme garde le trafic. Mais ceux qui créent du contenu se sentent comme des maçons construisant une maison, et à la fin, le nom sur le titre de propriété est celui d'une autre personne.
À ce moment-là, j'ai réalisé que le problème de l'IA n'était pas seulement de « récupérer des données pour s'entraîner ».
Il utilise le travail des autres sans avoir un bon registre comptable.
Et pour être honnête, au début, quand j'ai vu @OpenLedger , j'avais un peu de doutes. Actuellement dans le crypto, chaque projet qui rajoute 'IA' sonne un peu comme un restaurant de phở qui change son panneau en ‘AI Kitchen’ pour lever des fonds. Mais plus je lis, plus je vois qu'OpenLedger ne fait pas que raconter une histoire autour d'une chaîne IA.
Il touche à une question très terre à terre :
Si les données aident l'IA à faire des bénéfices, qui reçoit le crédit ?

Ethereum enregistre qui envoie de l'argent à qui. Bittensor penche beaucoup vers le calcul et l'intelligence réseau. OpenLedger, quant à lui, s'intéresse à la partie moins flashy : quelles données ont influencé la sortie de l'IA, et si la personne qui a contribué à ces données est reconnue.
Pour parler franchement, l'IA actuelle ressemble à une équipe qui fait des vidéos, mais le crédit à la fin ne mentionne que chaque plateforme. Le script est écrit par quelqu'un d'autre, les images sont tournées par d'autres, la musique est choisie par d'autres, et les retours des utilisateurs sont collectés petit à petit. Finalement, le produit est diffusé, et celui qui est derrière disparaît comme s'il n'avait jamais existé.
OpenLedger veut ramener ce crédit grâce à la Preuve d'Attribution.
Par exemple, un groupe spécialisé dans la détection de scams on-chain en Asie du Sud-Est a un petit jeu de données : portefeuilles de fraude, contrats falsifiés d'airdrop, modèles de phishing, quelques astuces de KOLs pour tromper les retail. Normalement, ce genre de données est très facile à copier, à entraîner, et ensuite elles se perdent. Mais si un agent de sécurité utilise ces données pour avertir les utilisateurs avant qu'ils ne signent un contrat, la contribution peut être reconnue et récompensée par $OPEN.
Ça peut sembler anodin, mais pour les traders retail, un avertissement en temps voulu peut sauver un portefeuille.
Le souci, c'est que le système doit non seulement savoir 'qui télécharge les données'. Le plus compliqué, c'est de savoir si ces données aident vraiment le modèle à mieux répondre. Si le simple fait de télécharger compte comme contribution, ce jeu va s'effondrer très vite.
S'il y a une récompense, il y a des agriculteurs.
S'il y a attribution, il y a des faux contributeurs.
Les données poubelles porteront des vêtements de 'connaissance de domaine'.
Le fil de copie va faire du cosplay de recherche.
Le spam sera emballé comme un jeu de données propre.
Un autre point faible est le score d'influence. Si ce score n'est pas assez transparent, il sera très difficile pour les contributeurs de faire confiance au système. Une personne qui fournit de bonnes données mais reçoit peu de récompenses se demandera pourquoi. Les données poubelles ayant un score élevé, c'est une autre histoire, car elles en profitent déjà.
Un petit jeu de données propre peut être plus précieux qu'un million de lignes de contenu recyclé.
Et voici l'angle que je trouve le plus intéressant à suivre : l'IA pourrait ne pas gagner simplement parce qu'elle répond mieux, mais parce qu'elle prouve d'où elle apprend.
Le modèle qui peut distinguer les données réelles du bruit a une chance de survivre longtemps.
C'est le problème que OpenLedger essaie de résoudre.
