
Hier nuit, en scrollant sur X, en regardant ces vidéos d'IA, j'ai eu une soudaine prise de conscience :
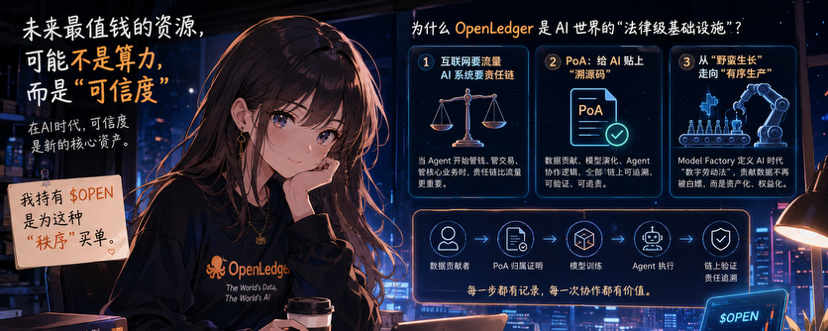
À l'avenir, la chose la plus précieuse ne sera peut-être pas la puissance de calcul, ni les modèles, mais la crédibilité.
Maintenant, tout le monde comprend l'environnement informationnel sur le net.
Transport, rebranding, génération en masse par IA, le vrai et le faux volent ensemble. Beaucoup de contenus semblent bien ficelés, mais tu ne sais pas d'où ça vient, et tu n'as aucune idée si ça a été manipulé derrière.
À l'époque de Web2, ce problème n'était pas mortel, après tout, la plupart des gens se contentaient de consommer du contenu.
Mais à l'ère de l'IA, c'est différent.
Quand l'IA commence à t'aider à prendre des décisions, à gérer des fonds, à exécuter des tâches, si tu ne sais même pas d'où viennent les données, alors le risque est en réalité bien plus grand que ce que beaucoup imaginent.
C'est aussi la raison pour laquelle je m'intéresse à @OpenLedger .
Beaucoup de projets se battent pour les modèles, les paramètres et la puissance de calcul, mais OpenLedger semble plutôt s'attaquer à un autre problème :
Comment prouver que les conclusions de l'IA sont dignes de confiance.
Beaucoup de gens considèrent le PoA (Proof of Attribution) comme un outil de droits d'auteur, je pense qu'ils le sous-estiment un peu.
À mon avis, cela ressemble plus à un système de traçabilité de responsabilité.
D'où viennent les données, qui les a fournies, comment les modèles ont été formés, quels processus ont été traversés, tout cela peut être tracé.
Tout comme on peut vérifier l'origine des légumes, à l'avenir, les résultats fournis par l'IA devraient également pouvoir être retracés.
Surtout dans des scénarios à haut risque comme la finance et la santé, sans capacité de traçabilité, même l'IA la plus intelligente aura du mal à rassurer réellement les gens.

J'ai récemment étudié leur Model Factory et j'ai ressenti la même chose.
Ce qu'ils font n'est pas seulement d'entraîner des modèles, mais de tenter d'établir un mécanisme de distribution de valeur plus équitable.
Dans le passé, ceux qui contribuaient des données ne recevaient souvent aucune compensation, la valeur était concentrée entre les mains des plateformes.
Et maintenant, les données, les modèles et les processus de raisonnement peuvent être enregistrés et quantifiés, les contributeurs ont aussi la chance de recevoir des bénéfices correspondants.
Le plus grand changement derrière cela est en fait :
L'industrie de l'IA passe d'une croissance sauvage à une opération régulée.
Avant, l'internet prônait le trafic avant tout.
À l'avenir, l'IA pourrait accorder plus d'importance à la responsabilité, à l'appartenance et à la vérification.
Donc, j'achète $OPEN non pas parce que je pense qu'il va nécessairement monter demain.
C'est parce que je pense qu'une fois que l'IA entrera réellement dans une phase d'application à grande échelle, la crédibilité deviendra un actif central.
Sans crédibilité, même le modèle le plus puissant n'est qu'une boîte noire.
Seules les infrastructures capables d'établir la confiance et l'ordre pourront traverser les cycles.

C'est peut-être là que #OpenLedger mérite vraiment d'être surveillé~