

Analyse comparative des cadres de circuits utilisant SHA-256

Nous tenons à remercier les équipes de Polygon Zero, du projet gnark de Consensys, Pado Labs et Delphinus Lab pour leurs précieux avis et commentaires sur ce blog.
Le Panthéon de la preuve zéro connaissance
Au cours des derniers mois, nous avons consacré beaucoup de temps et d'efforts au développement d'une infrastructure de pointe qui exploite les preuves succinctes de zk-SNARK. Dans le cadre de nos efforts de développement, nous avons testé et utilisé une grande variété de frameworks de développement Zero-Knowledge-Proof (ZKP). Bien que ce voyage ait été enrichissant, nous réalisons que l'abondance des frameworks ZKP disponibles crée souvent un défi pour les nouveaux développeurs qui tentent de trouver la meilleure solution pour leurs cas d'utilisation spécifiques et leurs exigences de performances. En gardant ce problème à l’esprit, nous pensons qu’une plateforme d’évaluation communautaire capable de fournir des résultats de référence complets est nécessaire et contribuera grandement au développement de ces nouvelles applications.
Pour répondre à ce besoin, nous lançons le Panthéon de la preuve à connaissance nulle en tant qu'initiative communautaire d'intérêt public. La première étape consistera à encourager la communauté à partager des résultats d'analyse comparative reproductibles à partir de divers cadres ZKP. Notre objectif ultime est de créer et de maintenir collectivement et en collaboration un banc d'essai d'évaluation universellement reconnu qui couvre les cadres de développement de circuits de bas niveau, les zkVM et les compilateurs de haut niveau, et même les fournisseurs d'accélération matérielle. Nous espérons que cette initiative accélérera l'adoption des ZKP en facilitant la prise de décision éclairée, tout en encourageant l'évolution et l'itération des cadres ZKP eux-mêmes en fournissant un ensemble de résultats d'analyse comparative communément référençables. Nous nous engageons à investir dans cette initiative et invitons tous les membres de la communauté partageant les mêmes idées à nous rejoindre et à contribuer ensemble à cet effort !
Une première étape : Évaluation comparative des cadres de circuits à l'aide de SHA-256
Dans cet article de blog, nous faisons le premier pas vers la construction du Panthéon de ZKP en fournissant un ensemble reproductible de résultats de référence utilisant SHA-256 dans une gamme de cadres de développement de circuits de bas niveau. Bien que nous reconnaissions que d'autres granularités et primitives de référence sont possibles, nous avons sélectionné SHA-256 en raison de son applicabilité à un large éventail de cas d'utilisation de ZKP, notamment les systèmes de blockchain, les signatures numériques, zkDID et plus encore. Il convient également de mentionner que nous exploitons également SHA-256 dans notre propre système, ce qui est également très pratique pour nous ! 😂
Notre benchmark évalue les performances de SHA-256 sur différents frameworks de développement de circuits zk-SNARK et zk-STARK. Grâce à cette comparaison, nous cherchons à fournir aux développeurs des informations sur l'efficacité et la praticité de chaque framework. Notre objectif est que ces résultats permettent aux développeurs de prendre des décisions éclairées lors de la sélection du framework le plus adapté à leurs projets.
Systèmes de preuve
Ces dernières années, nous avons observé une prolifération de systèmes de preuve à connaissance nulle. Bien qu’il soit difficile de suivre toutes les avancées passionnantes dans ce domaine, nous avons soigneusement sélectionné les systèmes de preuve suivants en fonction de leur maturité et de leur adoption par les développeurs. Notre objectif est de présenter un échantillon représentatif de différentes combinaisons front-end/back-end.
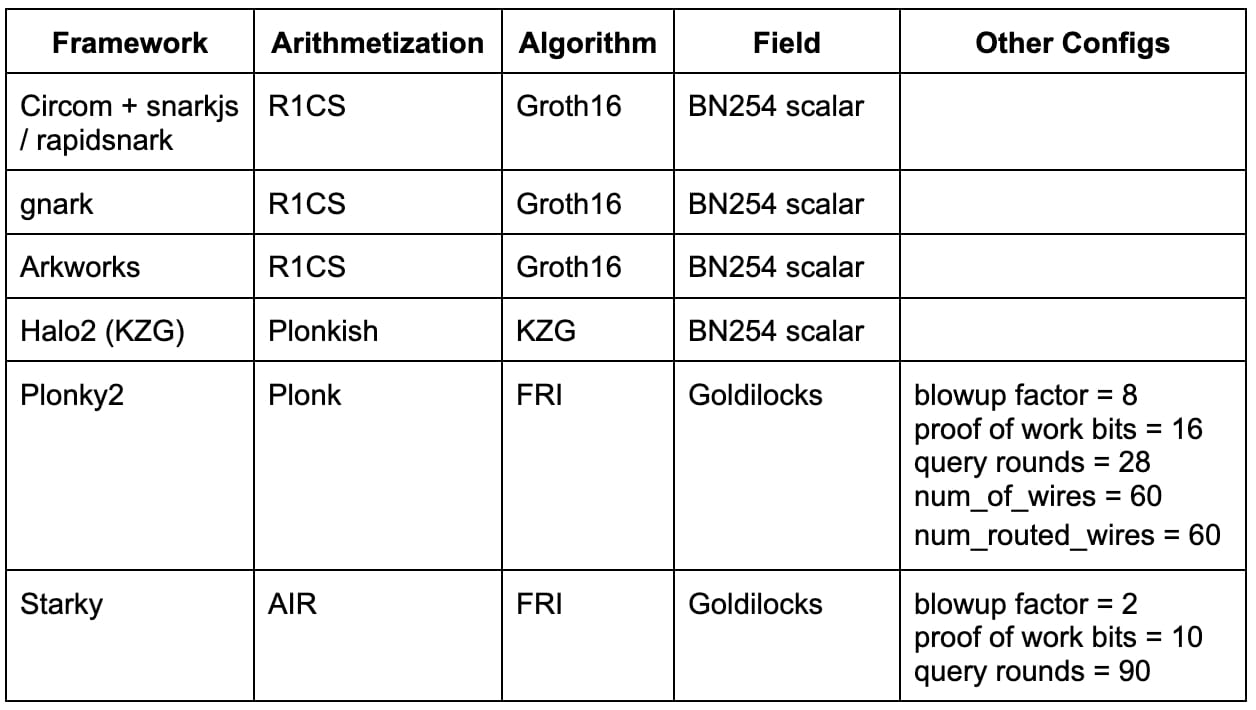
Circom + snarkjs / rapidsnark : Circom est un DSL populaire pour l'écriture de circuits et la génération de contraintes R1CS tandis que snarkjs est capable de générer des preuves Groth16 ou Plonk pour Circom. Rapidsnark est également un démonstrateur pour Circom qui génère des preuves Groth16 et est généralement beaucoup plus rapide que snarkjs en raison de l'utilisation de l'extension ADX, qui parallélise autant que possible la génération de preuves.
gnark : gnark est un framework Golang complet de Consensys qui prend en charge Groth16, Plonk et de nombreuses autres fonctionnalités avancées.
Arkworks : Arkworks est un framework Rust complet pour zk-SNARK.
Halo2 (KZG) : Halo2 est l'implémentation zk-SNARK de Zcash avec Plonk. Il est équipé de l'arithmétisation Plonkish hautement flexible qui prend en charge de nombreuses primitives utiles, telles que les portes personnalisées et les tables de recherche. Nous utilisons un fork Halo2 avec le support KZG de la Fondation Ethereum et Scroll.
Plonky2 : Plonky2 est une implémentation SNARK basée sur les techniques de PLONK et FRI de Polygon Zero. Plonky2 utilise un petit champ Goldilocks et prend en charge la récursivité efficace. Dans notre analyse comparative, nous avons ciblé une sécurité conjecturée de 100 bits et utilisé les paramètres qui ont donné le meilleur temps de preuve pour le travail d'analyse comparative. Plus précisément, nous avons utilisé 28 requêtes Merkle, un facteur d'explosion de 8 et un défi de preuve de travail de 16 bits. De plus, nous avons défini num_of_wires = 60 et num_routed_wires = 60.
Starky : Starky est un framework STARK très performant de Polygon Zero. Dans notre analyse comparative, nous avons ciblé une sécurité conjecturée de 100 bits et utilisé les paramètres qui ont donné le meilleur temps de preuve. Plus précisément, nous avons utilisé 90 requêtes Merkle, un facteur d'explosion de 2 et un défi de preuve de travail de 10 bits.
Le tableau ci-dessous résume les frameworks ci-dessus avec les configurations pertinentes utilisées dans notre analyse comparative. Cette liste n'est en aucun cas exhaustive et de nombreux frameworks/techniques de pointe (par exemple, Nova, GKR, Hyperplonk) sont laissés pour des travaux futurs.
Veuillez noter que ces résultats de référence ne concernent que les frameworks de développement de circuits. Nous prévoyons de publier à l'avenir un blog distinct évaluant les performances de différents frameworks de zkVM (par exemple, Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) et de compilateurs IR (par exemple, Noir, zkLLVM).
Méthodologie de référence
Pour comparer ces différents systèmes de preuve, nous avons calculé le hachage SHA-256 pour N octets de données, où nous avons expérimenté avec N = 64, 128, ..., 64K (à l'exception de Starky, où le circuit répète le calcul SHA-256 pour une entrée fixe de 64 octets mais conserve le même nombre total de segments de messages). Le code de référence et les implémentations du circuit SHA-256 peuvent être trouvés dans ce référentiel.
De plus, nous avons effectué une analyse comparative de chaque système à l’aide des mesures de performance suivantes :
Temps de génération de la preuve (y compris le temps de génération du témoin)
Utilisation maximale de la mémoire pendant la génération de preuves
Pourcentage moyen d'utilisation du processeur pendant la génération de preuves. (Cette mesure reflète le degré de parallélisation pendant la génération de preuves)
Veuillez noter que nous faisons quelques hypothèses « approximatives » concernant la taille de la preuve et le coût de la vérification de la preuve, car ces aspects peuvent être atténués en composant avec Groth16/KZG avant de passer à la chaîne.
Les machines
Nous avons effectué notre benchmarking sur deux machines différentes :
Serveur Linux : 20 cœurs à 2,3 GHz, 384 Go de mémoire
Macbook M1 Pro : 10 cœurs à 3,2 GHz, 16 Go de mémoire
Le serveur Linux a été utilisé pour simuler le scénario avec de nombreux cœurs de processeur et une mémoire abondante. Alors que le MacBook M1 Pro, qui est couramment utilisé pour la R&D, dispose d'un processeur plus puissant avec moins de cœurs.
Nous avons activé le multithreading lorsque cela était facultatif, mais nous n'avons pas utilisé l'accélération GPU dans ce test. Nous prévoyons d'inclure le test GPU dans le cadre de nos futurs travaux.
Résultats de référence
Nombre de contraintes
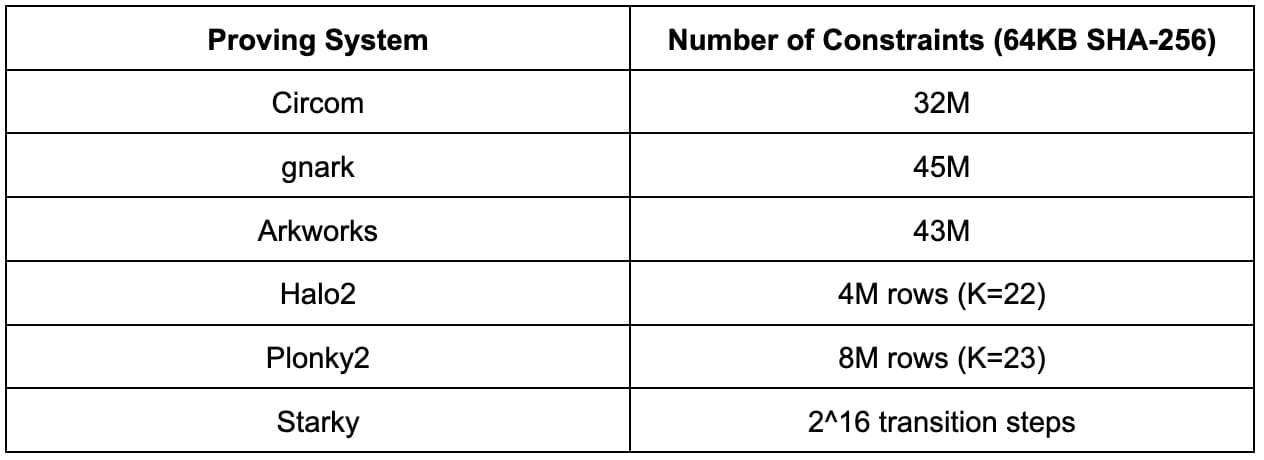
Avant de passer aux résultats détaillés de l’analyse comparative, il est utile de comprendre d’abord la complexité du SHA-256 en examinant le nombre de contraintes dans chaque système de preuve. Il est important de savoir que les nombres de contraintes dans différents schémas d’arithmétisation ne sont pas directement comparables.
Les résultats ci-dessous correspondent à une taille d'image préliminaire de 64 Ko. Bien que les résultats puissent varier avec d'autres tailles d'image préliminaire, ils peuvent être mis à l'échelle de manière linéaire.
Circom, gnark et Arkworks utilisent tous la même arithmétique R1CS, et le nombre de contraintes R1CS pour le calcul de 64 Ko SHA-256 est d'environ 30 M à 45 M. La différence entre Circom, gnark et Arkworks est probablement due à des différences d'implémentation.
Halo2 et Plonky2 utilisent tous deux l'arithmétique Plonkish, où le nombre de lignes varie de 2^22 à 2^23. L'implémentation de SHA-256 dans Halo2 est beaucoup plus efficace que celle de Plonky2 en raison de l'utilisation de tables de recherche.
Starky utilise l'arithmétisation AIR où les tables de trace d'exécution nécessitent 2^16 étapes de transition.
Temps de génération de la preuve
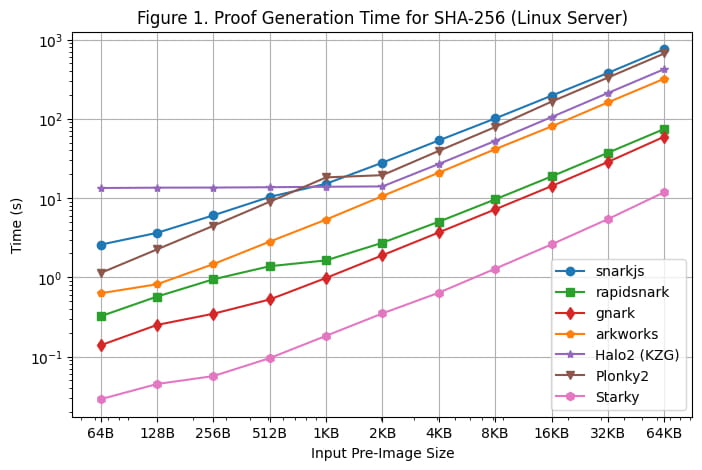
[Figure 1] illustre le temps de génération de preuves de chaque framework pour SHA-256 sur les différentes tailles d'image préalable, en utilisant le serveur Linux. Nous sommes en mesure de faire les observations suivantes :
Pour SHA-256, les frameworks Groth16 (rapidsnark, gnark et Arkworks) génèrent des preuves plus rapidement que les frameworks Plonk (Halo2 et Plonky2). En effet, SHA-256 se compose principalement d'opérations au niveau du bit où les valeurs de fil sont soit 0, soit 1. Pour Groth16, cela réduit la plupart des calculs de la multiplication scalaire de courbe elliptique à l'addition de points de courbe elliptique. Cependant, les valeurs de fil ne sont pas directement utilisées dans les calculs de Plonk, de sorte que la structure de fil spéciale dans SHA-256 ne réduit pas la quantité de calcul nécessaire dans les frameworks Plonk.
Parmi tous les frameworks Groth16, gnark et rapidsnark sont 5 à 10 fois plus rapides qu'Arkworks et snarkjs. Cela est dû à leur capacité supérieure à utiliser plusieurs cœurs pour paralléliser la génération de preuves. Gnark est 25 % plus rapide que rapidsnark.
Pour les frameworks Plonk, Plonky2 est 50 % plus lent que Halo2 pour SHA-256 lorsqu'on utilise une taille d'image préalable plus grande de >= 4 Ko. Cela est dû au fait que l'implémentation de Halo2 utilise largement une table de recherche pour accélérer les opérations au niveau du bit, ce qui donne 2 fois moins de lignes que Plonky2. Cependant, si nous comparons Plonky2 et Halo2 avec le même nombre de lignes (par exemple, SHA-256 sur 2 Ko dans Halo2 contre SHA-256 sur 4 Ko dans Plonky2), Plonky2 est 50 % plus rapide que Halo2. Si nous implémentons SHA-256 avec une table de recherche dans Plonky2, nous devrions nous attendre à ce que Plonky2 soit plus rapide que Halo2, bien que la taille de preuve de Plonky2 soit plus grande.
En revanche, lorsque la taille de l'image préliminaire d'entrée est petite (512 octets), Halo2 est plus lent que Plonky2 (et d'autres frameworks) en raison du coût de configuration fixe de la table de recherche qui représente la majorité des contraintes. Cependant, à mesure que l'image préliminaire augmente, les performances de Halo2 deviennent plus compétitives, avec un temps de génération de preuve qui reste constant pour des tailles d'image préliminaire allant jusqu'à 2 Ko, puis évolue presque linéairement, comme on peut l'observer dans le graphique.
Comme prévu, le temps de génération de preuves de Starky est nettement plus court (5x-50x) que n'importe quel framework SNARK, mais cela se fait au prix d'une taille de preuve beaucoup plus grande.
Une note supplémentaire est que même si la taille du circuit est linéaire dans la taille de la pré-image, la génération de preuves croît de manière super-linéaire pour les SNARK en raison de la FFT O(nlogn) (bien que cela ne soit pas évident sur le graphique en raison de l'échelle logarithmique).
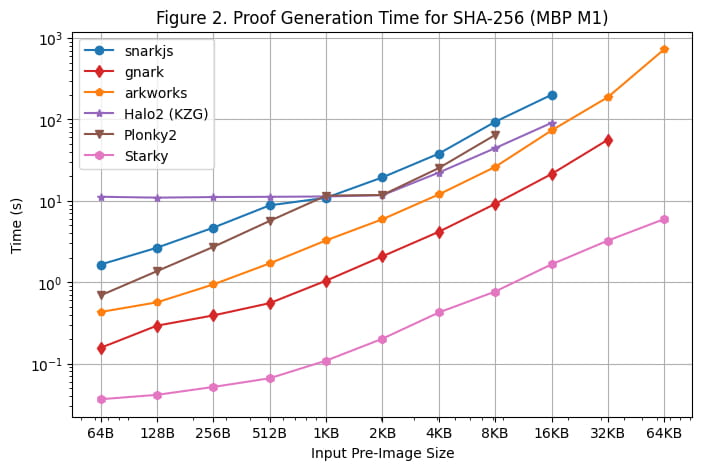
Nous avons également effectué un test de génération de preuve sur le Macbook M1 Pro, comme illustré dans [Figure 2]. Cependant, il est important de noter que rapidsnark n'a pas été inclus dans ce test en raison de son manque de prise en charge de l'architecture arm64. Afin d'utiliser snarkjs sur arm64, nous avons dû générer le témoin à l'aide de webassembly, qui est plus lent que la génération de témoins C++ utilisée sur le serveur Linux.
Plusieurs observations supplémentaires ont été faites lors de l'exécution du benchmark sur le MacBook M1 Pro :
À l'exception de Starky, tous les frameworks SNARK ont rencontré des erreurs de mémoire insuffisante (OOM) ou ont utilisé de la mémoire swap (entraînant un temps de vérification plus lent) lorsque la taille de l'image préliminaire est devenue importante. Plus précisément, les frameworks Groth16 (snarkjs, gnark, Arkworks) ont commencé à utiliser la mémoire swap lorsque la taille de l'image préliminaire était supérieure ou égale à 8 Ko, et gnark a rencontré OOM pour 64 Ko. Halo2 a rencontré une limite de mémoire lorsque la taille de l'image préliminaire était supérieure ou égale à 32 Ko. Plonky2 commence à utiliser la mémoire swap lorsque la taille de l'image préliminaire était supérieure ou égale à 8 Ko.
Les frameworks basés sur FRI (Starky et Plonky2) étaient environ 60 % plus rapides sur le Macbook M1 Pro que sur le serveur Linux, tandis que d’autres frameworks ont enregistré des temps de vérification similaires à ceux du serveur Linux. En conséquence, Plonky2 a atteint presque le même temps de vérification que Halo2 sur le Macbook M1 Pro, même si la table de recherche n’a pas été utilisée dans Plonky2. La principale raison en est que le Macbook M1 Pro dispose d’un processeur plus puissant mais avec moins de cœurs. FRI effectue principalement des opérations de hachage, qui sont plus sensibles aux cycles d’horloge du processeur mais pas aussi parallélisables que KZG/Groth16.
Utilisation maximale de la mémoire
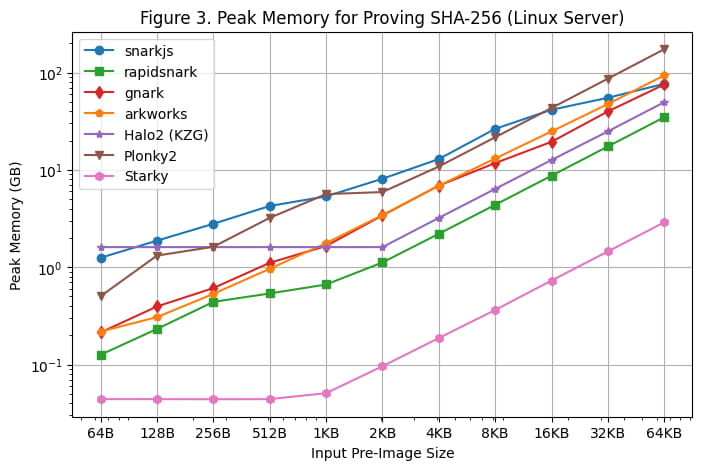
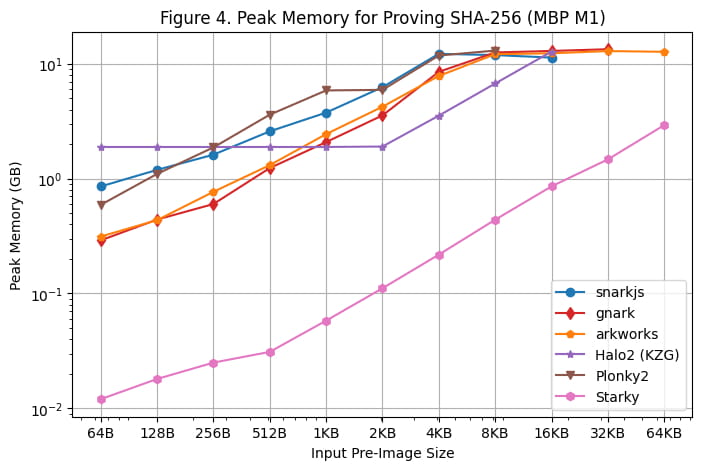
L'utilisation maximale de la mémoire pendant la génération de preuves sur le serveur Linux et le MacBook M1 Pro est illustrée respectivement dans [Figure 3] et [Figure 4]. Les observations suivantes peuvent être faites sur la base de ces résultats d'analyse comparative :
Parmi tous les frameworks SNARK, rapidsnark est le plus efficace en termes de mémoire. Nous constatons également que Halo2 utilise plus de mémoire lorsque la taille de l'image préliminaire est plus petite en raison du coût de configuration fixe de la table de recherche, mais consomme globalement moins de mémoire lorsque la taille de l'image préliminaire est plus grande.
Starky est 10 fois plus efficace en termes de mémoire que les frameworks SNARK. Cela est dû en partie à l'utilisation d'un nombre réduit de lignes.
Il convient de noter que l'utilisation maximale de la mémoire reste relativement stable sur le Macbook M1 Pro, car la taille de l'image préliminaire devient importante en raison de l'utilisation de la mémoire d'échange.
Utilisation du processeur
Nous avons évalué le degré de parallélisation pour chaque système de preuve en mesurant l'utilisation moyenne du processeur pendant la génération de preuves pour SHA-256 sur une entrée de pré-image de 4 Ko. Le tableau ci-dessous montre l'utilisation moyenne du processeur (et l'utilisation moyenne par cœur entre parenthèses) sur le serveur Linux (avec 20 cœurs) et le Macbook M1 Pro (avec 10 cœurs).
Les principales observations sont les suivantes :
Gnark et rapidsnark présentent l'utilisation la plus élevée du processeur sur le serveur Linux, ce qui indique leur capacité à utiliser efficacement plusieurs cœurs et à paralléliser la génération de preuves. Halo2 démontre également de bonnes performances de parallélisation.
La plupart des frameworks affichent une utilisation du processeur 2x sur le serveur Linux par rapport au Macbook Pro M1, l'exception à cette règle étant snarkjs.
Malgré les attentes initiales selon lesquelles les frameworks basés sur FRI (Plonky2 et Starky) pourraient avoir du mal à utiliser efficacement plusieurs cœurs, ils ne s'en sortent pas moins bien que certains frameworks Groth16/KZG dans nos tests de performance. Il reste à voir s'il y aura des différences dans l'utilisation du processeur sur une machine avec encore plus de cœurs (par exemple, 100 cœurs).

Conclusion et travaux futurs
Cet article de blog présente une comparaison complète des performances de SHA-256 sur divers frameworks de développement zk-SNARK et zk-STARK. Grâce aux résultats de référence, nous avons acquis des informations sur l'efficacité et la praticité de chaque framework pour les développeurs qui ont besoin de preuves succinctes pour les opérations SHA-256. Les frameworks Groth16 (par exemple, rapidsnark, gnark) se révèlent plus rapides à générer des preuves que les frameworks Plonk (par exemple, Halo2, Plonky2). La table de recherche dans l'arithmétisation Plonkish réduit considérablement les contraintes et le temps de preuve pour SHA-256 lors de l'utilisation d'une taille d'image préalable plus grande. De plus, gnark et rapidsnark démontrent une excellente capacité à utiliser plusieurs cœurs pour la parallélisation. Starky, en revanche, affiche un temps de génération de preuves beaucoup plus court, mais au prix d'une taille de preuve beaucoup plus grande. En termes d'efficacité de la mémoire, rapidsnark et Starky surpassent les autres frameworks.
En tant que première étape vers la construction du Panthéon de ZKP, nous reconnaissons que ce résultat de référence est loin d'être le banc d'essai complet final que nous souhaitons qu'il soit un jour. Nous accueillons favorablement et sommes ouverts aux commentaires et aux critiques et invitons tout le monde à contribuer à cette initiative visant à rendre ZKP plus facile et plus accessible à utiliser pour les développeurs. Nous sommes également disposés à accorder des subventions aux contributeurs individuels pour couvrir les coûts des ressources informatiques pour l'analyse comparative à grande échelle. Ensemble, nous pouvons améliorer l'efficacité et la praticité de ZKP au profit de la communauté au sens large.