
Le problème soulevé par l’article intitulé « XLM-V : Surmonter le goulot d’étranglement du vocabulaire dans les modèles de langage masqué multilingues » est que lorsque les paramètres et la profondeur des modèles de langage augmentent, la taille de leur vocabulaire reste inchangée. Par exemple, le modèle mT5 comporte 13 milliards de paramètres mais un vocabulaire de 250 000 mots prenant en charge plus de 100 langues. Ainsi, chaque langue possède environ 2 500 jetons uniques, ce qui est évidemment un très petit nombre.
 @Midjourney/Shalv
@Midjourney/Shalv
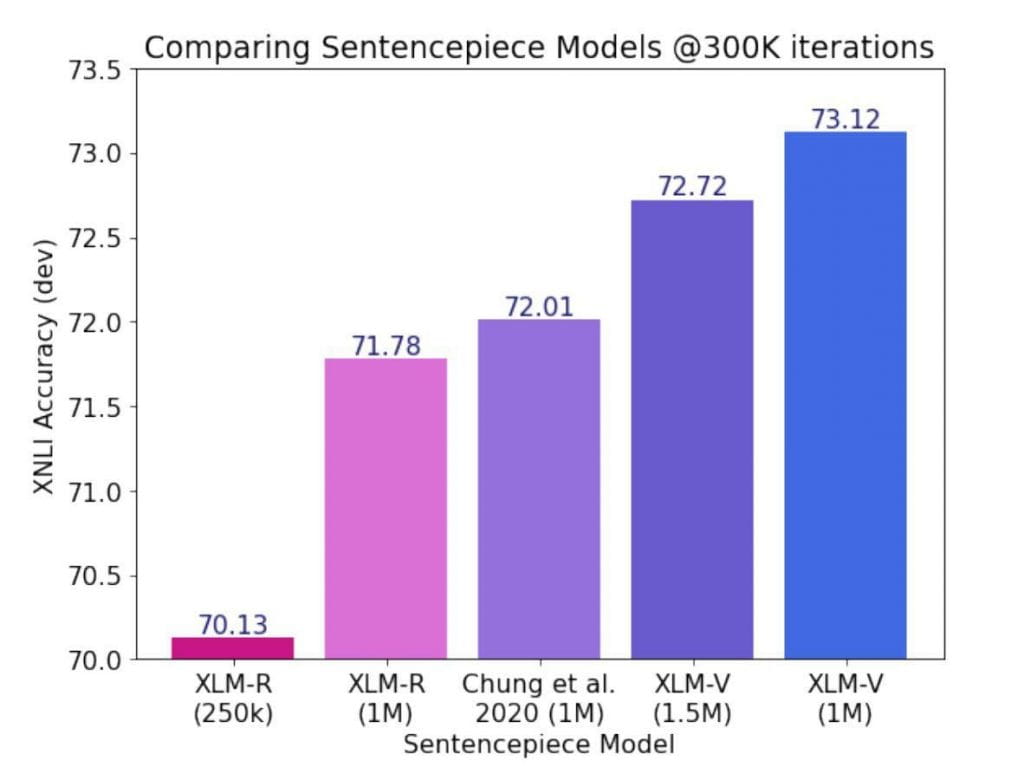
Quelle action les auteurs mènent-ils ? Ils commencent à former un nouveau modèle avec 1 million de jetons du vocabulaire de manière inattendue. XLM-R existait auparavant, mais avec cette mise à niveau, il deviendra XLM-V. Les scénaristes étaient déterminés à voir quel type d’amélioration ils pourraient apporter avec une augmentation aussi significative du nombre de jetons.
Article connexe : Les coûts de formation des modèles d'IA devraient passer de 100 millions de dollars à 500 millions de dollars d'ici 2030.
Qu’en est-il du XLM-V qui est nouveau alors que le XLM-R ne l’était pas ?
La méthode Amélioration des modèles multilingues avec des vocabulaires groupés en langues permet de construire des vecteurs de représentation lexicale pour chaque langue de la manière suivante : pour chaque langue de l'ensemble des langues, ils constituent un vecteur binaire dont chaque élément est un mot spécifique de la langue. . L'un indique que le mot est inclus dans le dictionnaire de la langue (vous pouvez voir une image avec une description graphique dans les pièces jointes.) Cependant, en créant un vecteur utilisant la probabilité logarithmique négative d'occurrence de chaque lexème, les auteurs améliorent la façon dont les références sont faites. .
Les vecteurs sont ensuite regroupés. De plus, un modèle de phrase est formé sur chaque groupe particulier pour arrêter le transfert de vocabulaire entre des langues lexicalement sans rapport.
L’ALP évalue la capacité d’un dictionnaire à représenter une langue spécifique.
L'utilisation de l'algorithme de création de dictionnaires ULM est l'étape suivante. qui commence par un grand dictionnaire initial et le réduit progressivement jusqu'à ce que le nombre de jetons soit inférieur à un certain seuil pour la taille du dictionnaire.
En savoir plus sur l'IA :
Top 120+ contenus générés par l’IA en 2023 : images, musique, vidéos
Top 10 des outils de référencement basés sur l'IA en 2023 pour les spécialistes du marketing numérique
Top 10 des applications mobiles de génération d'art IA en 2023 pour Android et IOS
L'article XLM-V : une nouvelle méthode de modèles de langage masqué multilingues qui tente de résoudre le problème du goulot d'étranglement du vocabulaire apparaît en premier sur Metaverse Post.