
Principaux points à retenir
Le Ledger de Binance stocke les soldes des comptes et les transactions, tout en permettant également aux services d'effectuer des transactions.
Il crée les conditions nécessaires à un débit élevé, une disponibilité 24h/24 et 7j/7 et une précision des données au niveau bit.
Le rôle de Binance Ledger dans les coulisses en fait l’une des technologies les plus importantes de Binance. Découvrez ici exactement comment cela fonctionne et les problèmes qu’il résout dans le fonctionnement du plus grand échange cryptographique au monde.

Vous êtes-vous déjà demandé exactement ce qui motive Binance ? Avec la nécessité de traiter quotidiennement des millions de transactions sur une base d’utilisateurs massive, il vaut la peine de jeter un œil à ce que Binance a sous le capot.
Le Ledger est à la base des opérations techniques de Binance. Le grand livre stocke les soldes et les transactions des comptes tout en permettant aux services d'effectuer des transactions.
Binance a des exigences élevées pour le grand livre
Comme vous pouvez l’imaginer, les exigences relatives au Ledger sont élevées pour répondre à la demande massive des utilisateurs. Il y a trois points majeurs à considérer :
Débit élevé avec possibilité d'un grand nombre de TPS (transactions par seconde) aux heures de pointe.
Disponibilité 24h/24 et 7j/7 sans temps d'arrêt.
Précision des données au niveau du bit, sans perte de fonds ni erreurs de transaction.
Regardons un exemple d'entrée de base sur le grand livre. Voici une transaction courante dans laquelle le compte 1 transfère 1 BTC vers le compte 2.
Solde avant la transaction :
IDENTIFIANT DE COMPTE | ACTIF | ÉQUILIBRE |
1 | BTC | dix |
2 | BTC | 0,1 |
Tableau 1
Solde après la transaction :
IDENTIFIANT DE COMPTE | ACTIF | ÉQUILIBRE |
1 | BTC | 9 |
2 | BTC | 1.1 |
Tableau 2
Dans cette transaction, il y a deux commandes :
Compte 1 -1 BTC
Compte 2 +1 BTC
Lorsque la transaction est effectuée, deux journaux de solde seront stockés pour audit et rapprochement.
IDENTIFIANT DE COMPTE | ACTIF | DELTA | TX_ID | TEMPS |
100001 | BTC | -1 | tx-001 | 2022-01-01 01:02:03 |
100002 | BTC | +1 | tx-001 | 2022-01-01 01:02:03 |
Tableau 3
La solution standard de l'industrie
Une solution Ledger standard du secteur est basée sur une base de données relationnelle. En revenant à l'exemple précédent, les deux commandes de la transaction peuvent être traduites en deux instructions SQL et exécutées dans une transaction de base de données (tableau 4).
commencer la transaction ; |
UPDATE balance_1 définir le solde = solde - 1 OÙ account_id=1 et actif = 'BTC' et solde - 1 >= 0 ; Si 0 ligne est affectée, alors restauration ; |
UPDATE balance_2 définir le solde = solde + 1 OÙ account_id=2 et actif = 'BTC' et solde + 1 >= 0 ; Si 0 ligne est affectée, alors restauration ; |
commettre; |
tableau-4
Les avantages de la solution
C’est assez simple à mettre en œuvre.
Il est facile d’appliquer des techniques courantes de réglage des bases de données, telles que le fractionnement en lecture/écriture et le partitionnement, pour améliorer les performances.
Il n’est pas difficile pour les développeurs de se remettre d’un basculement, ainsi que de surveiller et de maintenir une base de données commerciale.
Les inconvénients de la solution
Le TPS chutera fortement en cas de conditions de concurrence dues aux verrous de rangée.
Il est difficile d’évoluer horizontalement pour améliorer les performances.
Le problème des comptes chauds
Malheureusement pour Binance, la solution industrielle présentée ci-dessus ne répond pas à ses exigences élevées. Lorsqu'une transaction se produit, elle doit conserver les verrous de ligne de chaque ligne impliquée. Même si certains comptes comportent relativement peu de transactions à traiter, il existe bien sûr des comptes occupés avec de nombreuses transactions simultanées. Dans ce cas, une seule transaction est capable de maintenir le verrou de ligne du compte.
Les autres transactions ne peuvent alors rien faire d’autre qu’attendre que le verrou soit libéré. Nous appelons cette situation un problème de compte brûlant, et des tests internes montrent que le TPS chutera au moins 10 fois dans cette situation. Vous pouvez voir ce problème dans le tableau 5 ci-dessous.
Exemple de compte chaud :
Tx 1 (transférer 1 BTC du compte 1 au compte 2) | Tx 2 (transférer 2 BTC du compte 1 au compte 3) |
commencer la transaction ; | |
commencer la transaction ; | |
MISE À JOUR du solde réglé solde = solde - 1 OÙ account_id=1 et actif = 'BTC' et solde - 1 >= 0 ; (ligne verrouillée : account_id=1 et actif = 'BTC') Si 0 ligne est affectée, alors restauration ; | MISE À JOUR du solde réglé solde = solde - 2 OÙ account_id=1 et actif = 'BTC' et solde - 2 >= 0 ; Si 0 ligne est affectée, alors restauration ; |
MISE À JOUR du solde réglé = solde + 1 OÙ account_id=2 et actif = 'BTC' et solde + 1 >= 0 ; Si 0 ligne est affectée, alors restauration ; | attendre verrouiller |
commettre; | attendre verrouiller |
obtenir le verrouillage, exécuter | |
MISE À JOUR du solde réglé solde = solde + 2 OÙ account_id=3 et actif = 'BTC' et solde + 1 >= 0 ; Si 0 ligne est affectée, alors restauration ; | |
commettre; |
tableau-5
La solution de grand livre de Binance
Comment pouvons-nous résoudre le problème du compte chaud ?
Une solution possible à notre problème consiste à convertir de manière innovante le modèle multithread en mode monothread. Cela évite alors le problème de condition de concurrence et, par conséquent, il n’y aura pas de problème de compte brûlant.
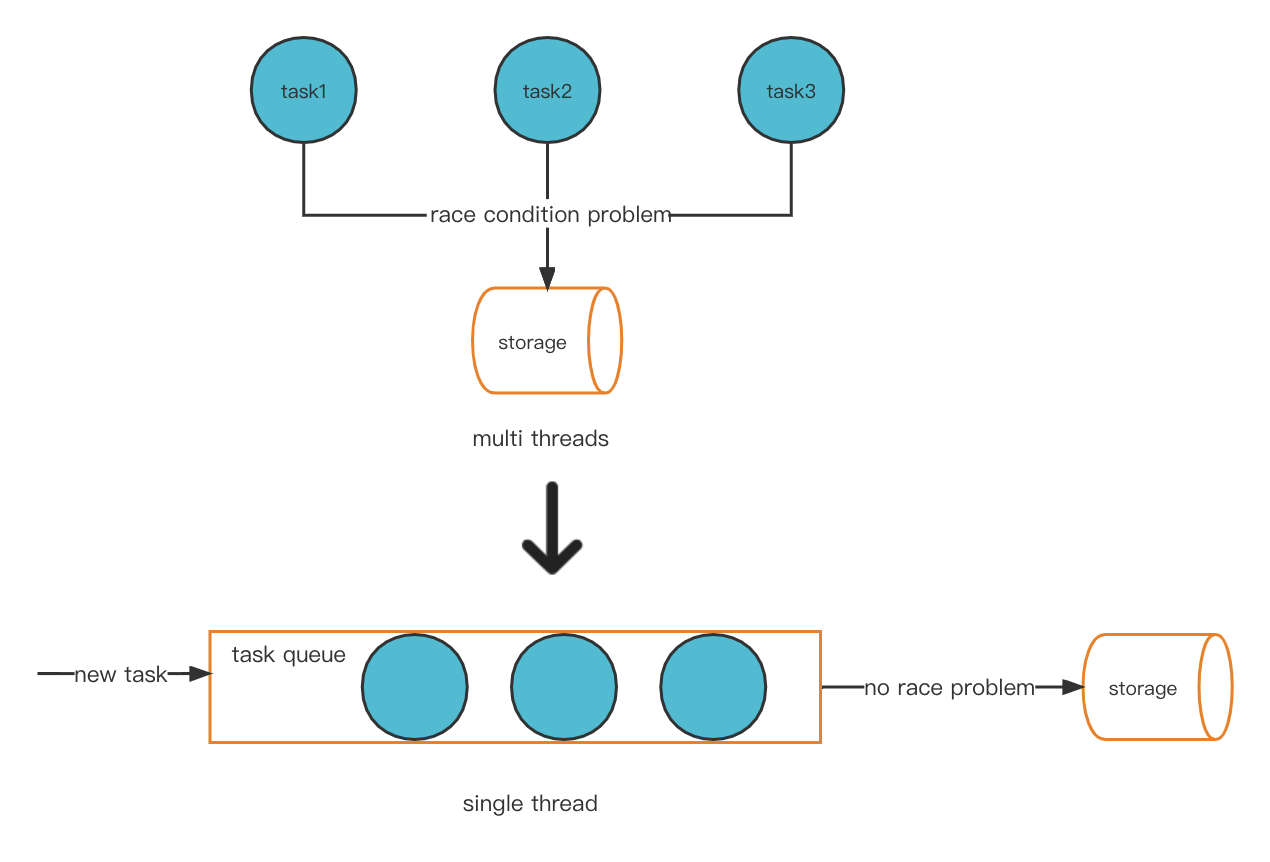
Nouveau modèle de fil
Communication basée sur les messages
Après avoir implémenté notre nouveau modèle de thread, un problème de communication doit être résolu. La couche machine à états est monothread, mais la couche réseau est multithread, alors comment communiquer efficacement entre les deux ?
Un perturbateur [1] est la prochaine étape du puzzle. Il crée une file d'attente hautes performances sans verrouillage basée sur une conception de tampon en anneau.
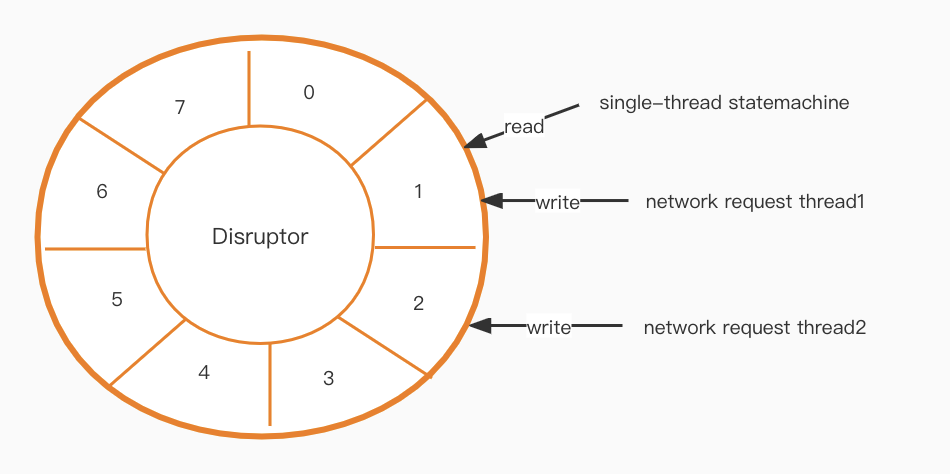
La haute disponibilité
Jusqu'à présent, nous avons atteint des performances élevées en utilisant un modèle en mémoire et le stockage local RocksDB [2]. Mais une fois de plus, un nouveau défi se présente. Nous devons désormais veiller à une haute disponibilité des données.
Pour garantir la cohérence des données entre les nœuds, nous utilisons un algorithme de consensus Raft [3]. Cela signifie que le nombre de sauvegardes de données est égal au nombre de nœuds non leaders présents. L'algorithme garantit également que le système fonctionnera toujours avec au moins la moitié des nœuds sains, afin de contribuer à fournir une haute disponibilité du service.
Rôles du domaine Raft :
Chef. Leader traite toutes les demandes des clients et réplique l’opération à tous les abonnés.
Disciple. Les suiveurs suivent le leader pour toutes les opérations. Si le leader échoue, l’un de ses partisans sera élu nouveau leader.
Apprenant. Les apprenants sont des abonnés sans droit de vote qui envoient chaque enregistrement de changement idempotent/transaction à d'autres services.
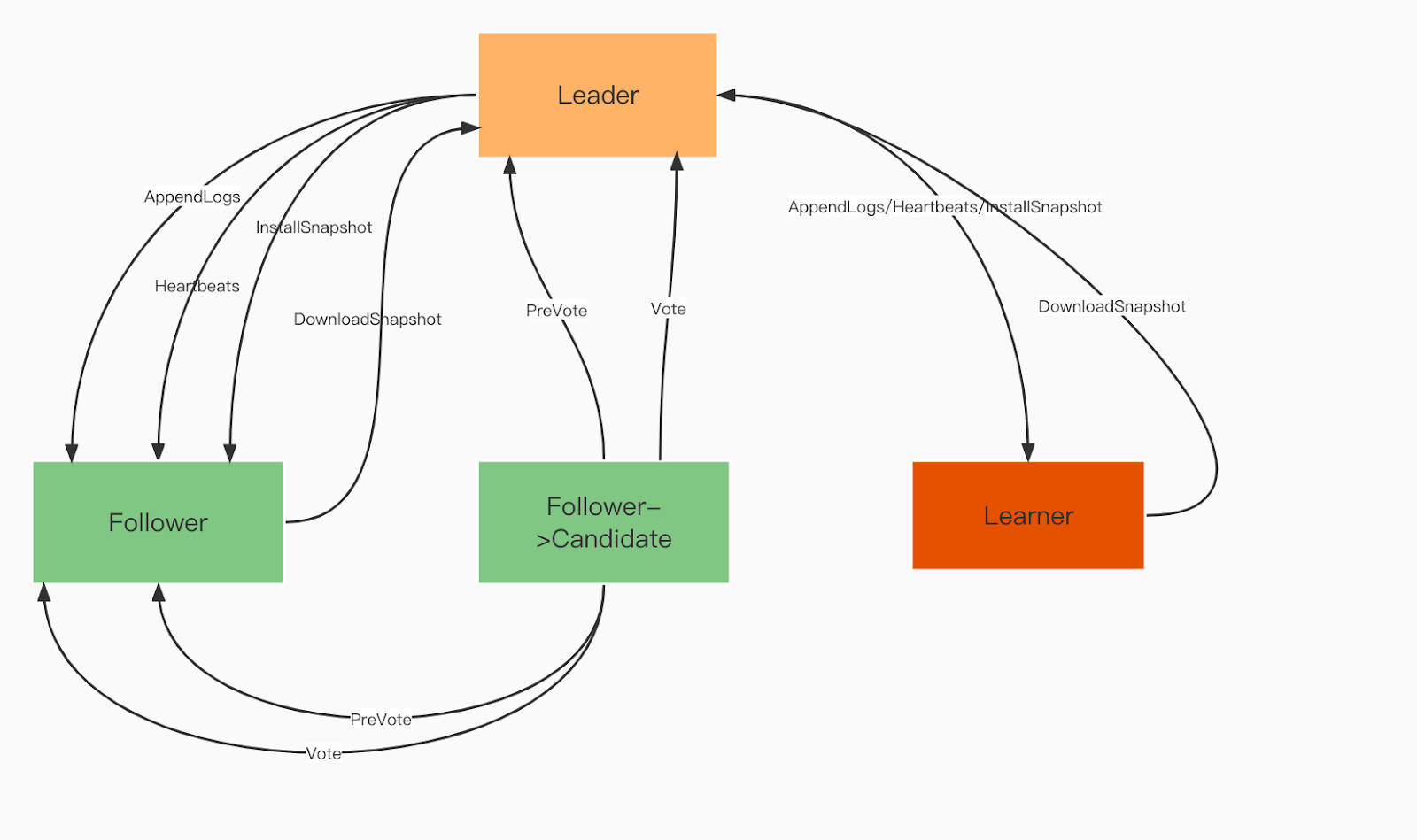
Rôles de domaine Raft
CQRS (ségrégation des responsabilités des requêtes de commande)
Un autre critère clé que nous voulons garantir est les performances d’écriture plus élevées du Ledger et sa capacité à répondre à des conditions de requête plus diverses. Pour cela, nous devons créer différents domaines. Le domaine raft fournit une écriture plus efficace basée sur rocksdb+raft, et le domaine view écoute les messages du domaine raft et les enregistre dans la base de données relationnelle pour les requêtes externes. Nous pouvons également implémenter la séparation des responsabilités des requêtes de commande au niveau architectural.
Architecture du grand livre
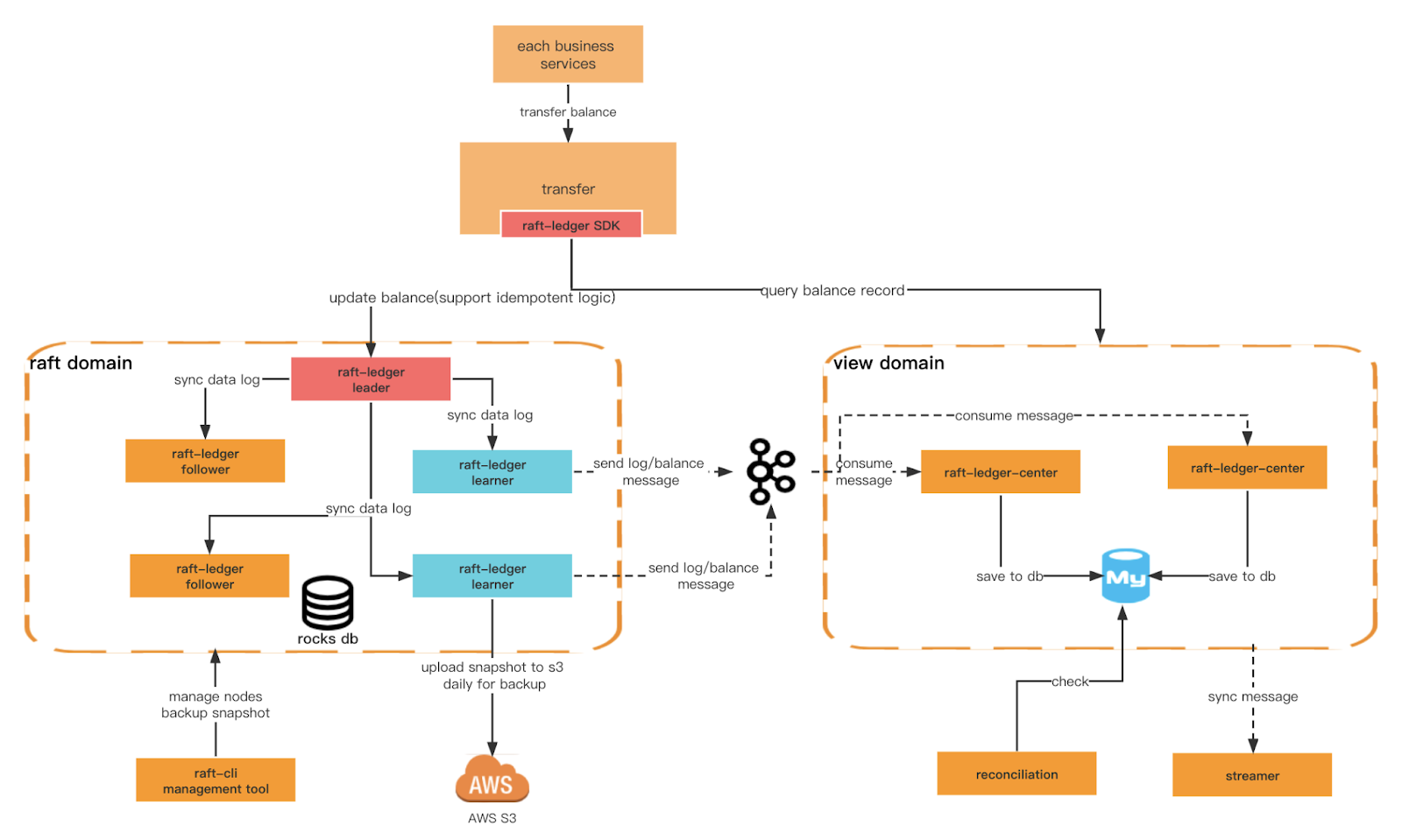
Architecture globale
Conditions entre Raft et Ledger :
Radeau | registre |
machines à états répliquées | noeuds du grand livre |
État | équilibre |
commande | transaction |
tableau-6
Afficher les rôles de domaine
Centre du grand livre du radeau
Consommez le message produit par l'apprenant et stockez les données de transaction et de solde dans MySQL à des fins d'interrogation.
Traitement des demandes
Une demande de transaction passera d'abord par la couche réseau, la couche grand livre (gestionnaire de requêtes) et la couche radeau (synchronisation des journaux du radeau). Il reviendra ensuite à la couche grand livre (machine à états), à la couche réseau (gestionnaire de réponse) et enfin renverra une réponse au client.
Les données sont transmises via la file d'attente entre les deux couches.
Couche réseau – Désérialisez la requête rpc et placez-la dans la file d'attente des requêtes.
Ledger Layer – Récupérez la demande de la file d’attente et préparez le contexte. Il placera ensuite les métadonnées de la demande dans la file d'attente du radeau.
Raft Layer – Obtenez les métadonnées de la demande de la file d’attente du radeau et synchronisez-les entre tous les abonnés. Il placera ensuite le résultat dans la file d'attente des applications.
Ledger Layer – Obtenez les données de la file d’attente d’application et mettez à jour la machine d’état. Il placera ensuite le résultat dans la file d’attente des réponses.
Couche réseau – Obtenez le résultat de la file d'attente de réponses et construisez et sérialisez les données de réponse avant de les renvoyer au client.
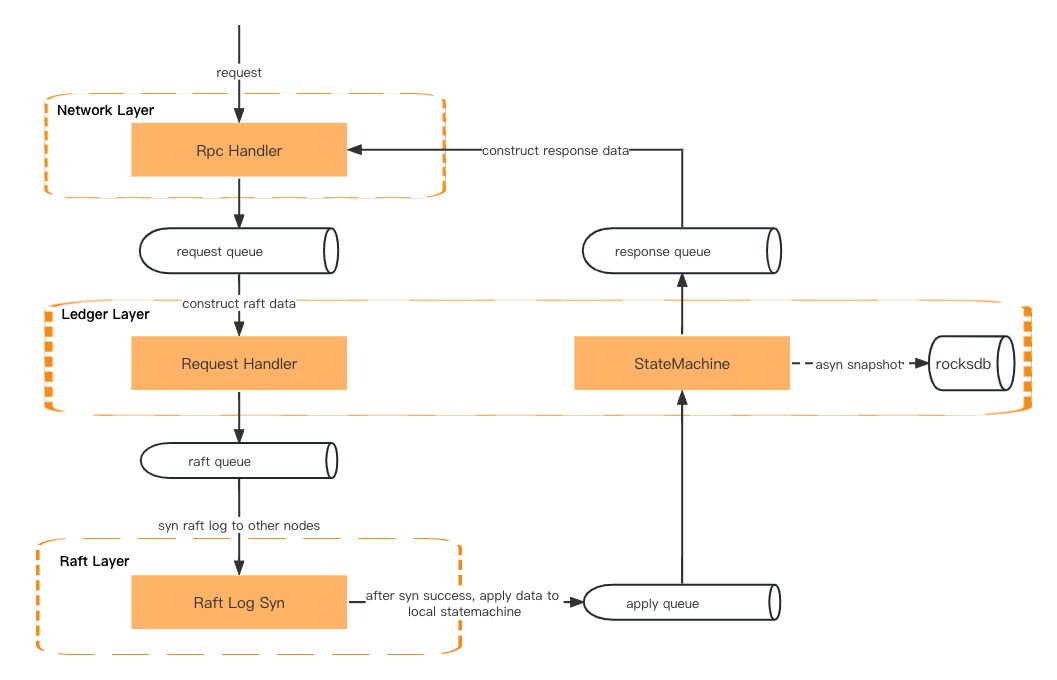
Traitement des demandes
Récupération de données
Chaque nœud Ledger déclenchera un instantané générique basé sur une période de temps. De plus, nous implémentons également un instantané cohérent. Chaque nœud est déclenché au même index de journal de radeau pour garantir que la machine d'état est exactement la même lorsque chaque nœud déclenche un instantané. L'instantané sera ensuite téléchargé sur S3 pour vérification par Checker et comme sauvegarde à froid.
Lorsque Ledger redémarre, il lit l'instantané local et reconstruit la machine d'état. Ensuite, il relit le journal du radeau local et synchronise le dernier journal du leader jusqu'à ce qu'il rattrape le dernier index. Si l'instantané local ou le journal du radeau n'existe pas, il sera obtenu auprès du leader.
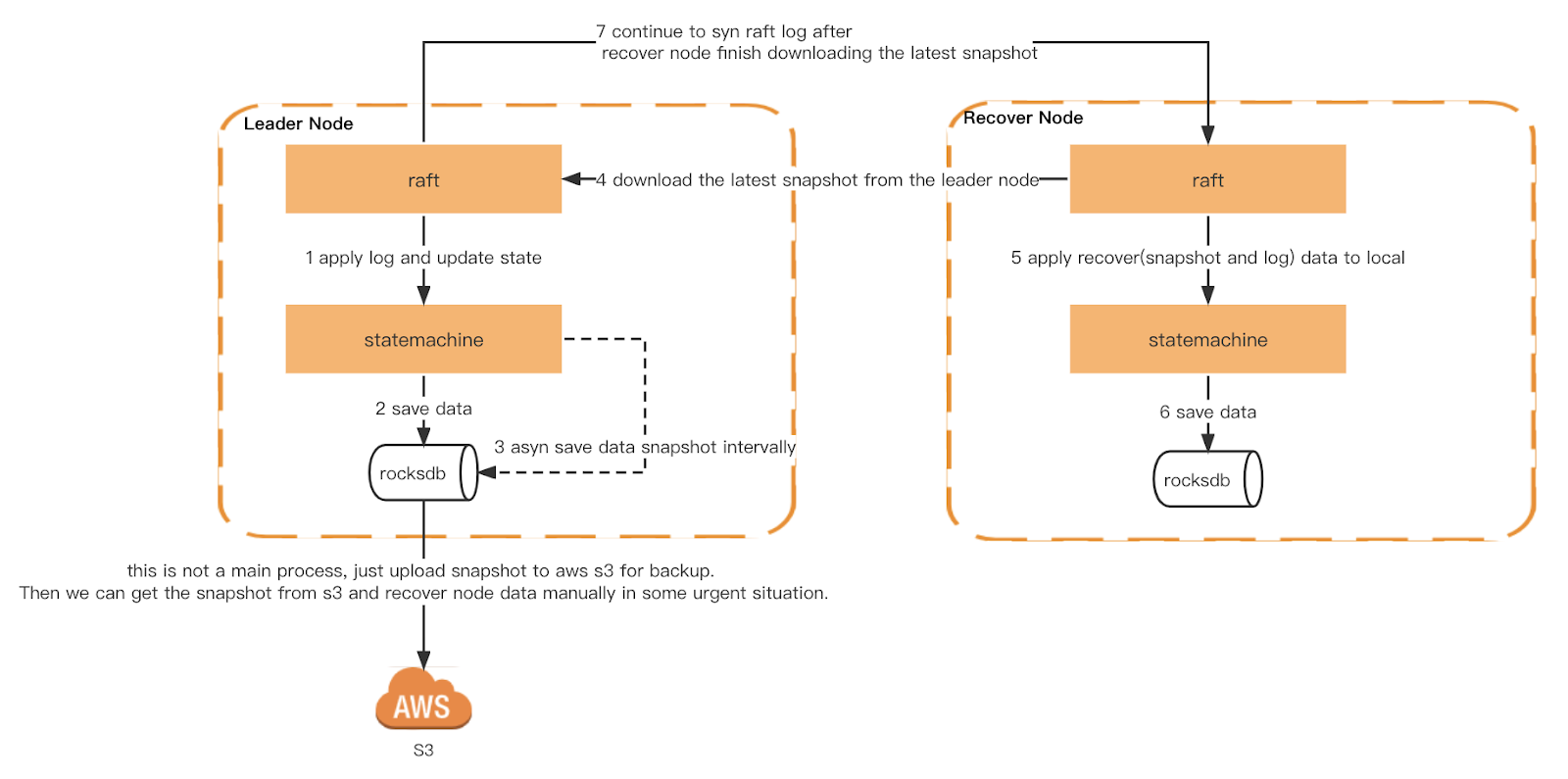
Instantané et récupération
Tolérance aux catastrophes
Pour améliorer la disponibilité et la tolérance aux pannes, les nœuds Ledger sont déployés dans différentes zones. Tant que plus de la moitié des nœuds sont sains, les données ne seront pas perdues et le basculement sera effectué en une seconde.
Même si l'ensemble du cluster tombe en panne, ce qui est une très faible probabilité, nous pouvons toujours restaurer le cluster via l'instantané cohérent stocké dans Amazon S3 et récupérer les dernières données perdues via le système en aval.
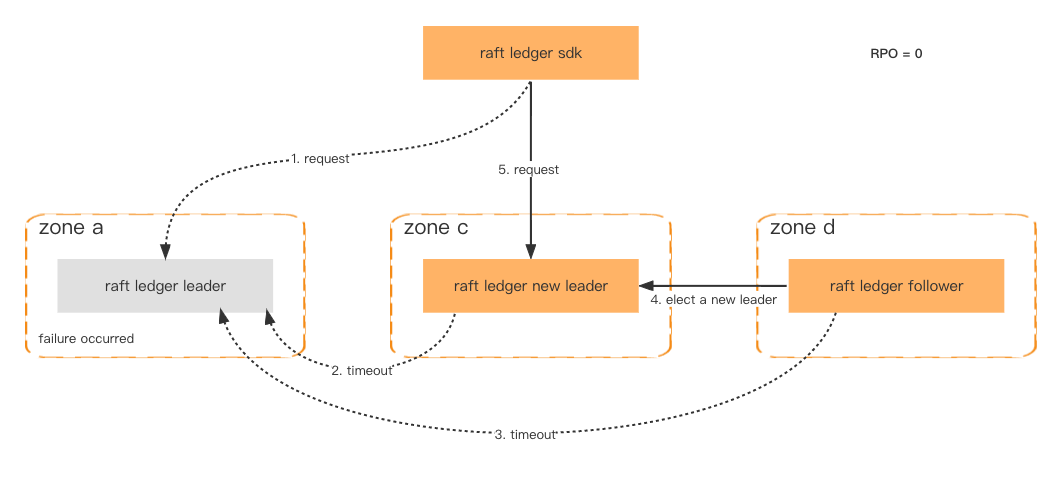
Tolérance aux pannes
Performance
Le tableau suivant présente les spécifications matérielles pour le test de performances
Composant | Type d'instance | Bande passante du réseau (Gbit/s) | Bande passante EBS (Gbit/s) | Type de stockage EBS |
Leader/Suiveur | M6i.4xlarge 16c64g | Jusqu'à 12,5 | Jusqu'à 10 | 2T GP3 * 3 IOPS6000 625 Mo/s |
Apprenant | M6i.4xlarge 16c64g | Jusqu'à 12,5 | Jusqu'à 10 | 2T GP3 * 3 IOPS6000 625 Mo/s |
Banc | C5.4xlarge 16c32g | Jusqu'à 10 | 4.750 | Uniquement le volume racine |
Des tests internes prouvent qu'un cluster de 4 nœuds (un leader, deux suiveurs et un apprenant) peut traiter plus de 10 000 TPS. De par sa conception, le cluster traite toutes les transactions une par une. Il n’y a aucun verrouillage ni condition de concurrence. Ainsi, dans le scénario du compte chaud, le TPS est aussi élevé que dans les scénarios normaux.
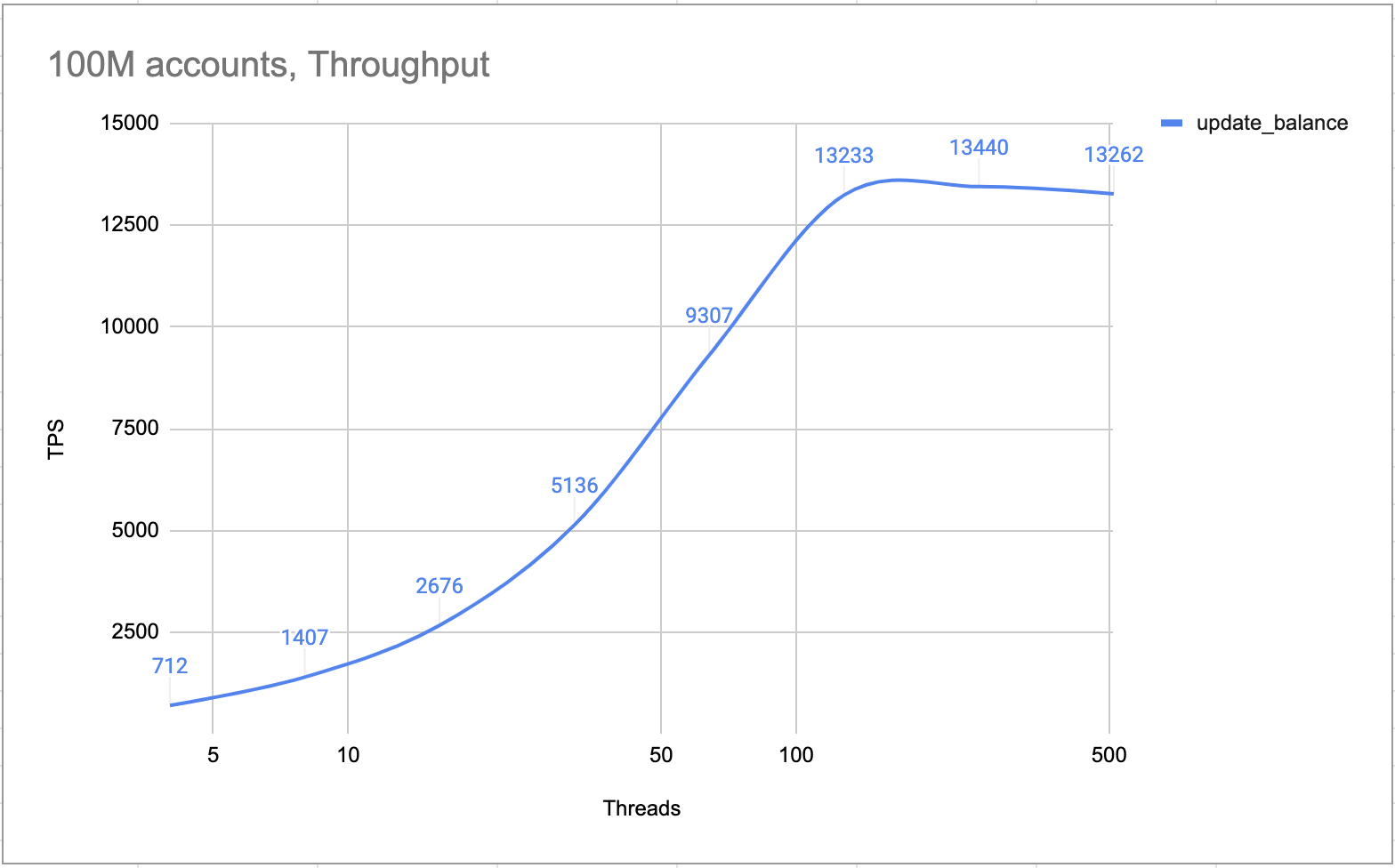
Compte chaud TPS
La figure suivante montre la latence de chaque transaction. La plupart des transactions peuvent être terminées en 10 ms. Les transactions les plus lentes peuvent être terminées en 25 ms.
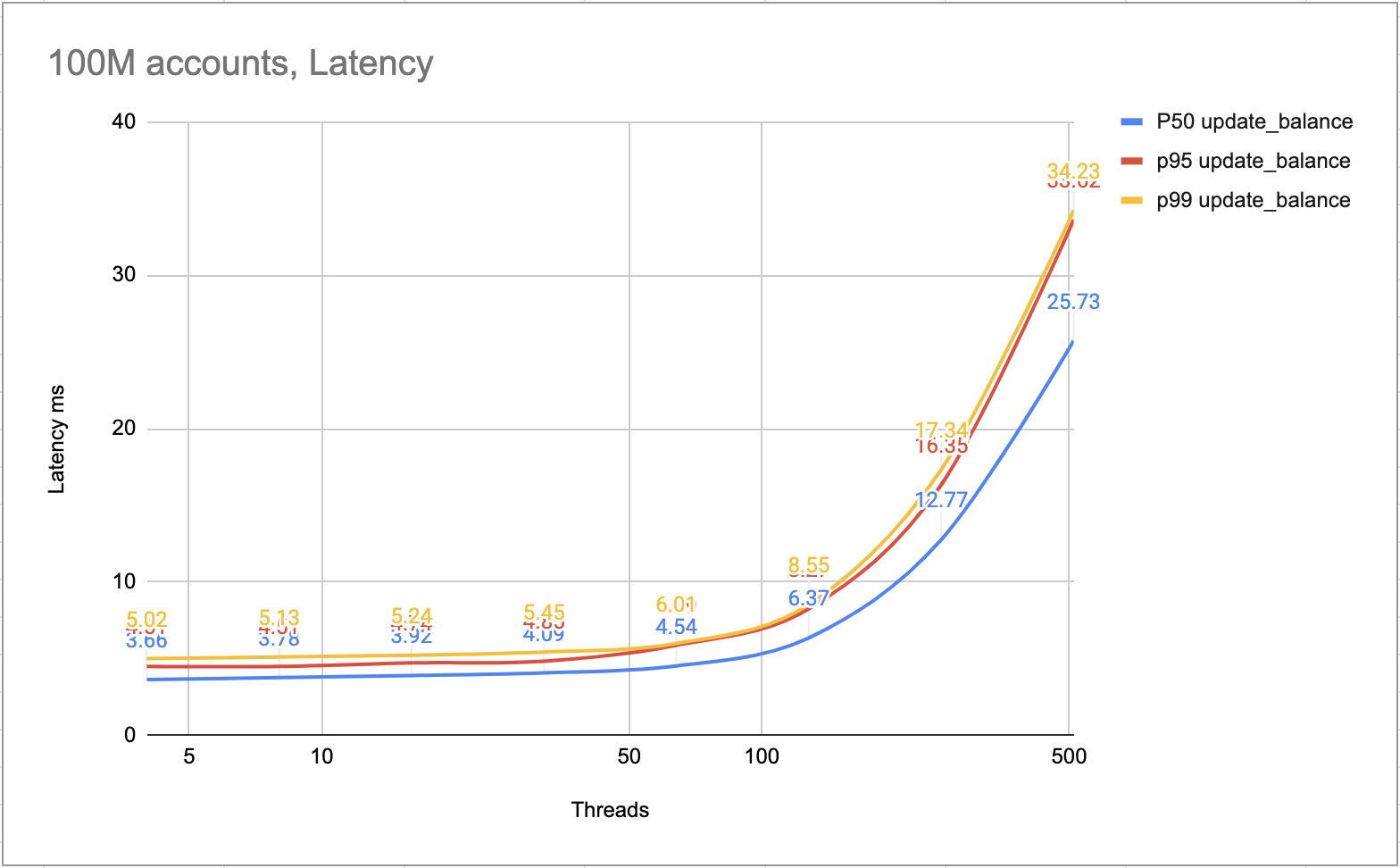
Latence ms
Alimenter nos services avec Binance Ledger
Comme vous l'avez vu, la réponse de l'industrie traditionnelle au problème des comptes chauds ne satisfait pas les besoins de Binance et de ses clients. En utilisant une approche conçue spécifiquement pour l'infrastructure de Binance, nous avons abouti à l'une des expériences d'échange et de produits les plus fluides disponibles. Nous sommes heureux de partager maintenant avec vous notre expérience et espérons que vous comprendrez mieux ce qui entre en jeu pour faire fonctionner un service comme Binance.
Lisez l’article suivant pour plus d’informations sur notre infrastructure technologique :
(Blog Binance) Utiliser MLOps pour créer un pipeline d'apprentissage automatique de bout en bout en temps réel
(Blog Binance) Rencontrez le CTO : Rohit réfléchit à la crypto, à la blockchain, au Web3 et à son premier mois chez Binance
Les références
[1] Perturbateur LMAX
[2] RochesDB
[3] L'algorithme de consensus du radeau