
La diffusion d'avatar 3D est un algorithme d'apprentissage automatique qui peut prendre une seule image 2D d'un visage humain et créer un avatar tridimensionnel (3D). L'avatar peut ensuite être utilisé pour créer une expérience de réalité virtuelle (VR) ou de réalité augmentée (AR) ou simplement pour fournir une vue 3D réaliste de la personne à des fins de jeu ou à d'autres fins.
Le modèle de diffusion a été développé par une équipe de chercheurs de Microsoft Research et est décrit dans un article publié dans la revue arXiv.

La diffusion d'avatar 3D est basée sur un type d'algorithme d'apprentissage automatique appelé modèle de diffusion. Les modèles de diffusion sont des modèles génératifs, ce qui signifie qu'ils peuvent générer de nouvelles données similaires aux données d'entraînement. Les modèles de diffusion ont déjà été utilisés pour générer des images 3D à partir d'images 2D, mais l'ADM est le premier modèle de diffusion capable de générer un avatar 3D réaliste à partir d'une seule image 2D.
Pour entraîner le modèle, les chercheurs ont utilisé un ensemble de données de plus de 200 000 modèles de visages 3D. L’ensemble de données comprenait une grande variété de visages avec des tons de peau, des coiffures et des traits du visage différents. L'ADM a ensuite pu apprendre la relation entre l'image 2D et le modèle de visage 3D et générer un avatar 3D réaliste à partir d'une seule image 2D.
Le modèle peut également être utilisé pour générer un avatar à partir d'une photo prise sous un angle différent.
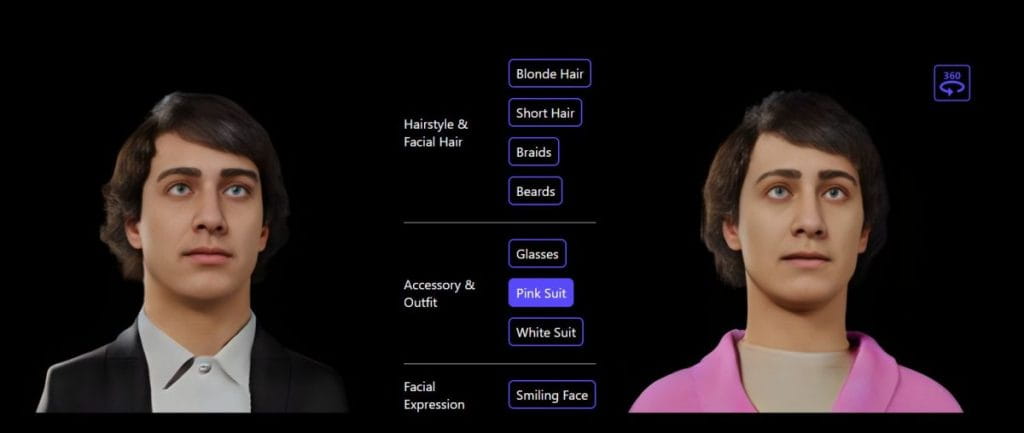 Pour l'avatar 3D personnalisé, le modèle Rodin propose une manipulation guidée par texte. L'édition en langage naturel est un moyen intuitif de modifier de nombreuses fonctionnalités différentes de l'avatar 3D.
Pour l'avatar 3D personnalisé, le modèle Rodin propose une manipulation guidée par texte. L'édition en langage naturel est un moyen intuitif de modifier de nombreuses fonctionnalités différentes de l'avatar 3D.
Cette étude propose un modèle génératif 3D qui crée automatiquement des avatars numériques 3D représentés sous forme de champs de radiance neuronale à l'aide de modèles de diffusion. En raison des exigences prohibitives en matière de mémoire et de traitement associées à la 3D, la création des fonctionnalités riches nécessaires à la création d'avatars de haute qualité constitue un problème majeur. Les développeurs suggèrent que le réseau de diffusion en déploiement (Rodin) résolve ce problème.
 En termes de sexe, d'âge, de race, d'expression, d'accessoires faciaux, etc., le modèle présente une diversité générationnelle exceptionnelle.
En termes de sexe, d'âge, de race, d'expression, d'accessoires faciaux, etc., le modèle présente une diversité générationnelle exceptionnelle.
Ce réseau déploie de nombreuses cartes de caractéristiques 2D d'un champ de radiance neuronale dans un seul plan de caractéristiques 2D, où le modèle exécute ensuite une diffusion compatible 3D. Le modèle Rodin utilise la convolution 3D, qui s'occupe des entités projetées dans le plan des entités 2D selon leur relation d'origine en 3D, pour fournir l'efficacité de calcul indispensable tout en maintenant l'intégrité de la diffusion en 3D.
En savoir plus sur l'IA :
VALL-E : le nouveau modèle de synthèse vocale sans tir de Microsoft peut dupliquer la voix de chacun en trois secondes
VALL-E de Microsoft semble être le logiciel frauduleux le plus dangereux jamais conçu
L'artiste crée un script antivol pour protéger l'art et utilise le même filigrane que les générateurs d'IA
Microsoft et Google en 2023 : la principale confrontation de l’année entre les titans de l’IA
Le message Microsoft a publié un modèle de diffusion capable de créer un avatar 3D à partir d'une seule photo d'une personne apparaît en premier sur Metaverse Post.