
Source de la réimpression de l'article : Modèle Evolution
Source de l'article : Xinzhiyuan

Source de l'image : générée par Unbounded AI
La fenêtre contextuelle la plus longue au monde est là ! Aujourd'hui, Baichuan Intelligent a publié le grand modèle Baichuan2-192K, avec une longueur de fenêtre contextuelle allant jusqu'à 192 Ko (350 000 caractères chinois), soit 4,4 fois celle de Claude 2 et 14 fois celle de GPT-4 !
La nouvelle référence dans le domaine des fenêtres contextuelles longues est là !
Aujourd'hui, Baichuan Intelligent a officiellement publié le grand modèle de fenêtre contextuelle le plus long au monde - Baichuan2-192K.
Ce qui est différent du passé, c'est que la longueur de la fenêtre contextuelle de ce modèle atteint 192 Ko, ce qui équivaut à environ 350 000 caractères chinois.
Pour être plus précis, Baichuan2-192K peut traiter 14 fois plus de caractères chinois que GPT-4 (contexte 32K, environ 25 000 caractères en mesure réelle) et 4,4 fois plus que Claude 2 (contexte 100K, environ 80 000 caractères en mesure réelle). Il peut lire un livre entier (Le problème des trois corps) en une seule fois.

Le dossier de fenêtre contextuelle de longue date de Claude a été actualisé aujourd'hui
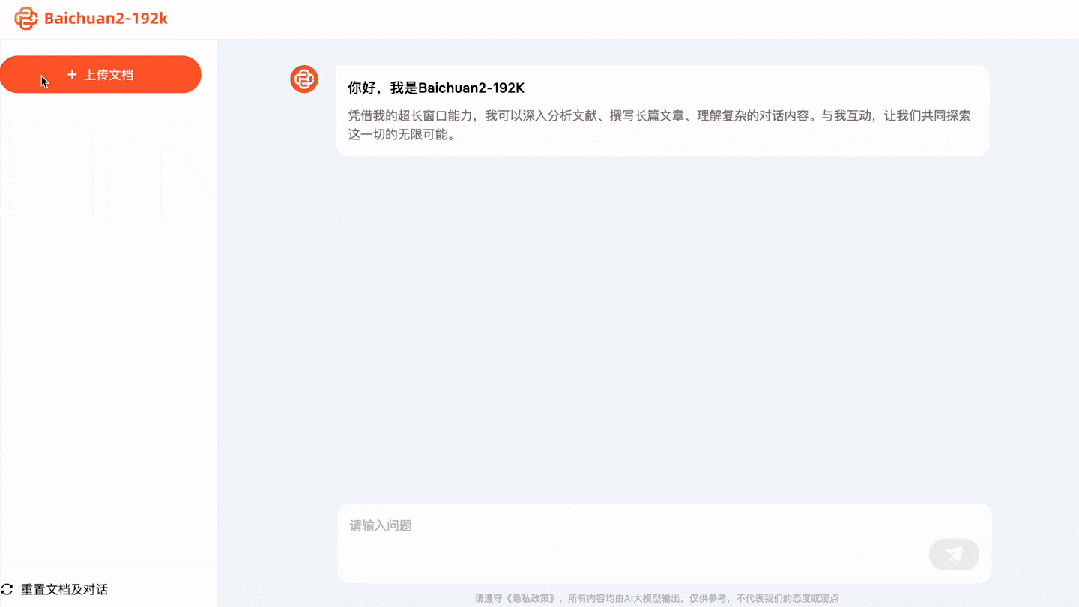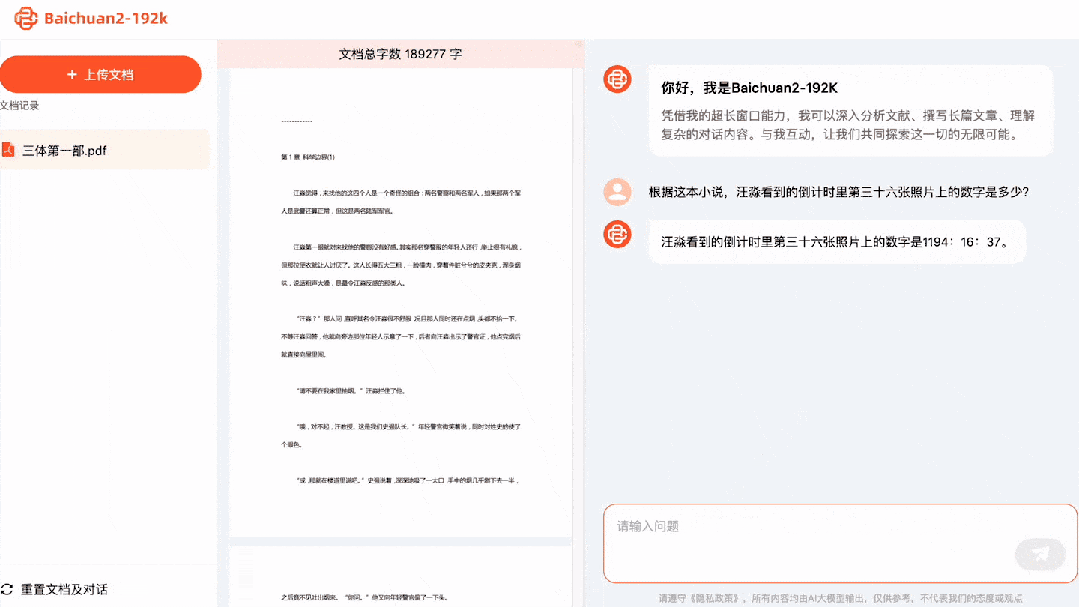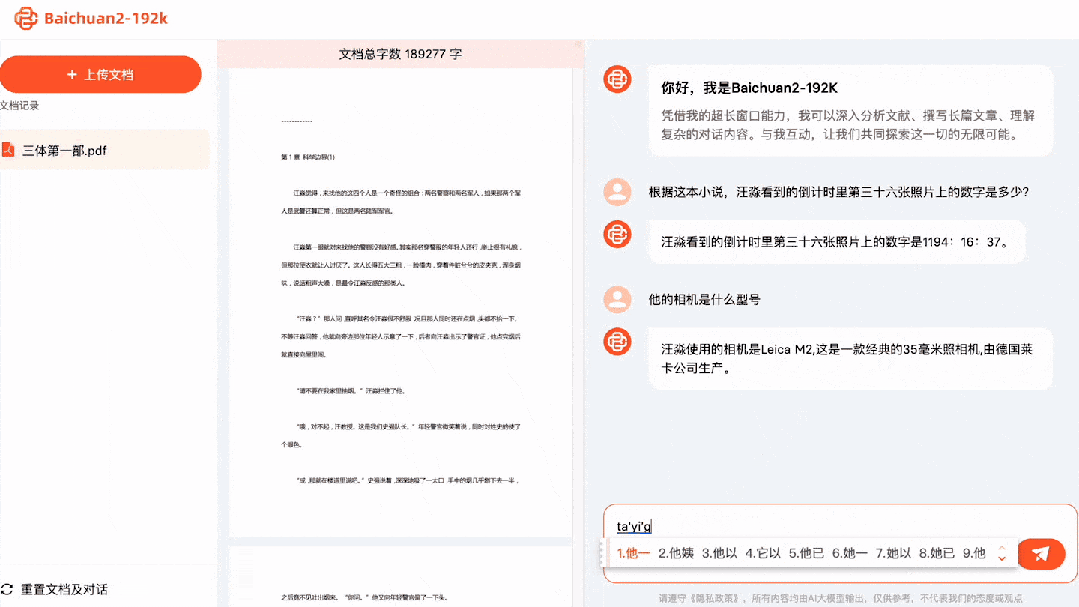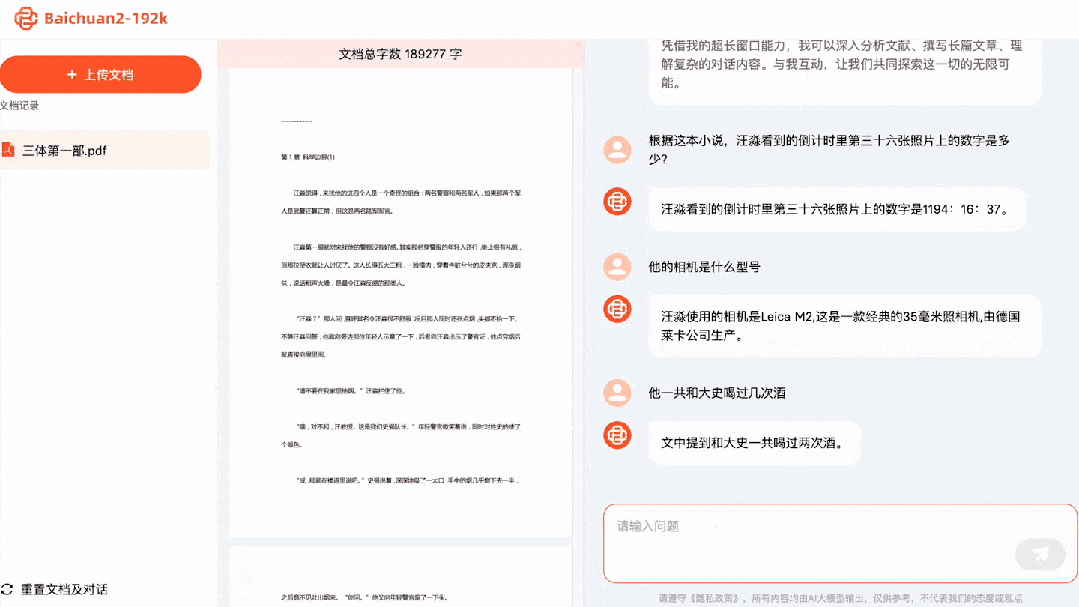
Jetez-lui la première partie du problème des trois corps (événements passés sur Terre), et Baichuan2-192K connaîtra immédiatement toute l'histoire après un peu de mastication.
Quel était le numéro sur la 36ème photo du compte à rebours que Wang Miao a vu ? Réponse : 1194:16:37. Quel modèle d'appareil photo a-t-il utilisé ? Réponse : Leica M2. Combien de fois lui et Dashi ont-ils bu ensemble ? Réponse : deux fois.
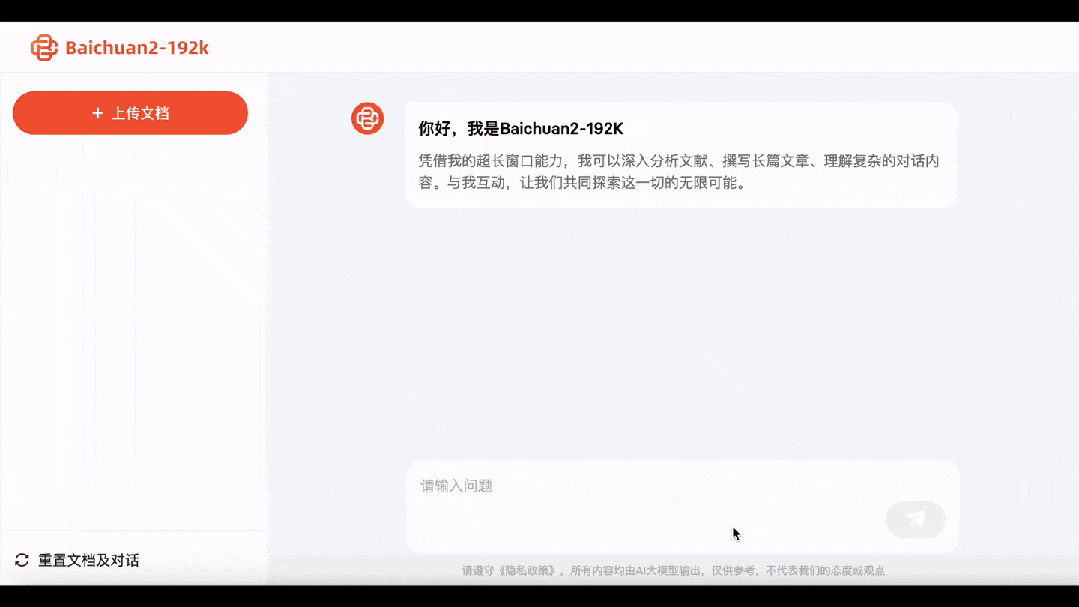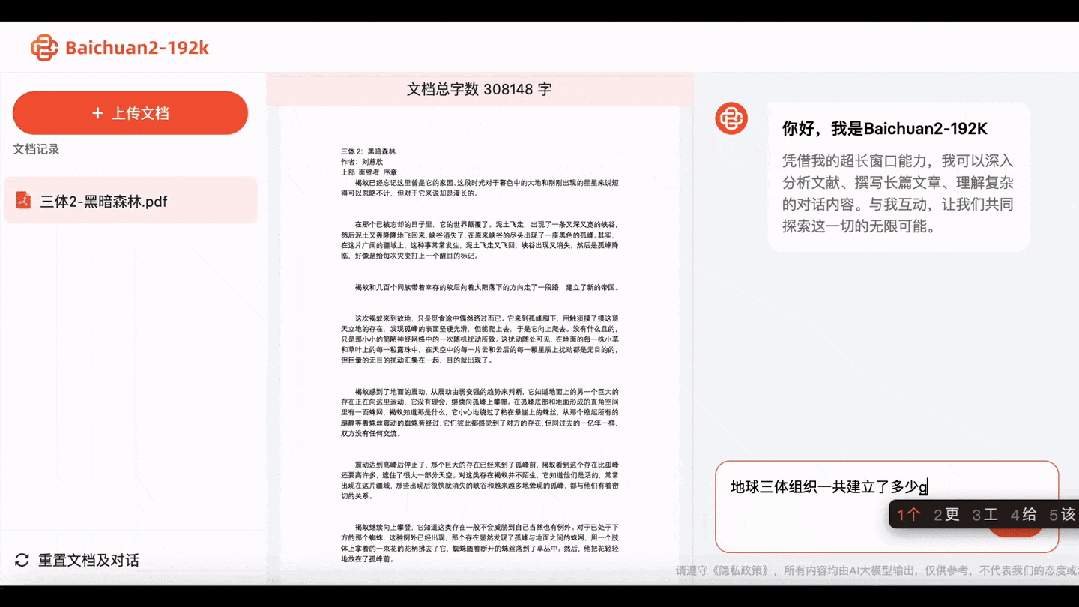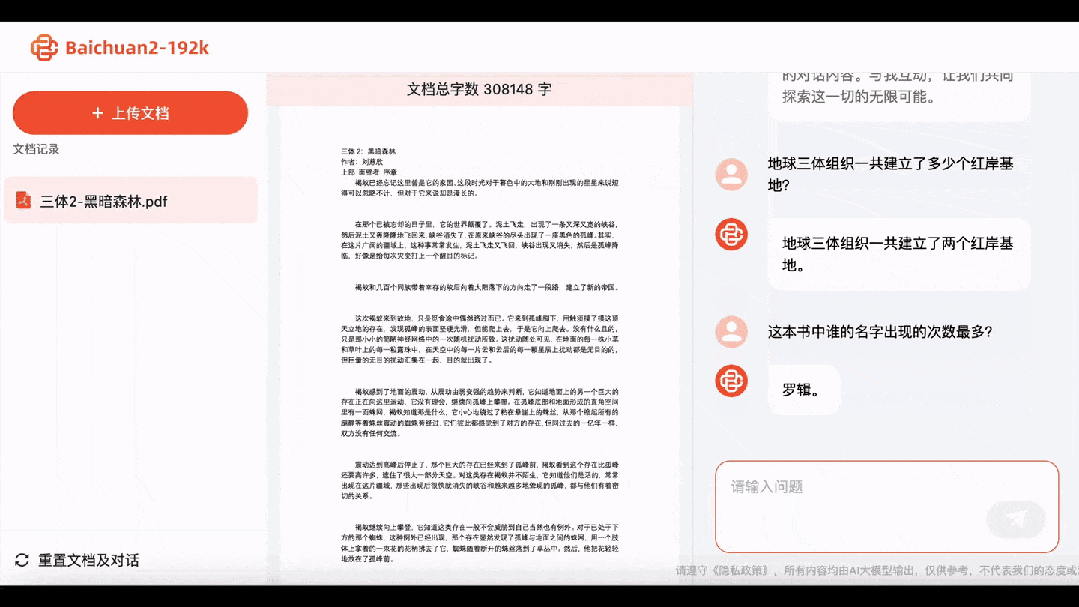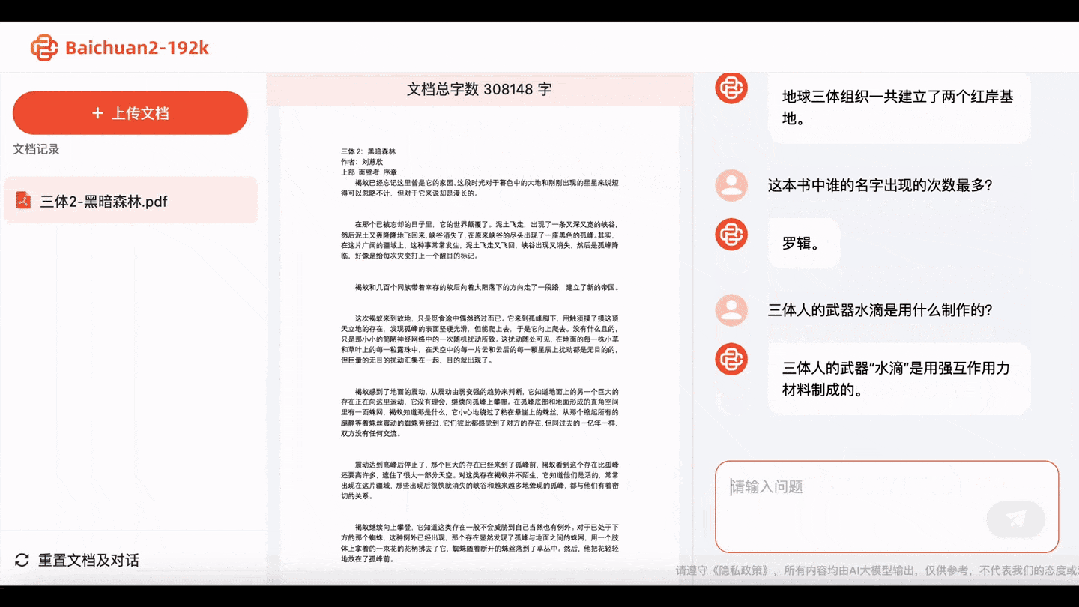
Jetons un œil à la deuxième partie (Forêt Sombre). Baichuan2-192K a non seulement répondu immédiatement que l'organisation Trisolaran de la Terre avait établi deux bases de la Côte Rouge, mais aussi que les « gouttelettes d'eau » étaient constituées de matériaux à interaction forte.
De plus, Baichuan2-192K était capable de répondre aux questions impopulaires avec aisance et sans effort, auxquelles même un « érudit de niveau 10 des Trois Corps » ne serait peut-être pas en mesure de répondre.
Quel nom apparaît le plus souvent ? Réponse : Luo Ji.
On peut dire que lorsque la fenêtre contextuelle s’étend à 350 000 mots, l’expérience d’utilisation du grand modèle est comme l’ouverture soudaine d’un nouveau monde !
Le contexte le plus long du monde, menant Claude 2 dans tous les aspects
Qu'est-ce qui retiendra le grand modèle ?
En prenant ChatGPT comme exemple, bien que ses capacités soient étonnantes, ce modèle « universel » présente une limitation inévitable : il ne prend en charge que les contextes allant jusqu'à 32 000 jetons (25 000 caractères chinois). Cependant, les professions telles que celles d’avocat et d’analyste doivent la plupart du temps traiter des textes bien plus longs.

Une fenêtre de contexte plus large permet au modèle d'obtenir des informations sémantiques plus riches à partir de l'entrée, et même d'effectuer des réponses aux questions et un traitement des informations directement basé sur la compréhension du texte intégral.
En conséquence, le modèle peut non seulement mieux saisir la pertinence du contexte et éliminer l'ambiguïté, mais également générer du contenu avec plus de précision, atténuer le problème des « hallucinations » et améliorer les performances. De plus, avec le support d’un long contexte, il peut également être profondément intégré à des scénarios plus verticaux pour jouer véritablement un rôle dans le travail, la vie et les études des gens.
Récemment, la licorne de la Silicon Valley Anthropic a reçu des investissements de 4 milliards de dollars d’Amazon et de 2 milliards de dollars de Google. Bien entendu, la position de leader de Claude dans le domaine des technologies à long contexte est étroitement liée à son succès à gagner la faveur de ces deux géants.
Cette fois, le modèle à grande fenêtre Baichuan-192K publié par Baichuan Intelligence dépasse de loin Claude 2-100K en termes de longueur de fenêtre contextuelle et a également atteint un leadership complet dans les évaluations de multiples dimensions telles que la qualité de génération de texte, la compréhension du contexte et les capacités de réponse aux questions.
10 évaluations faisant autorité, 7 SOTA
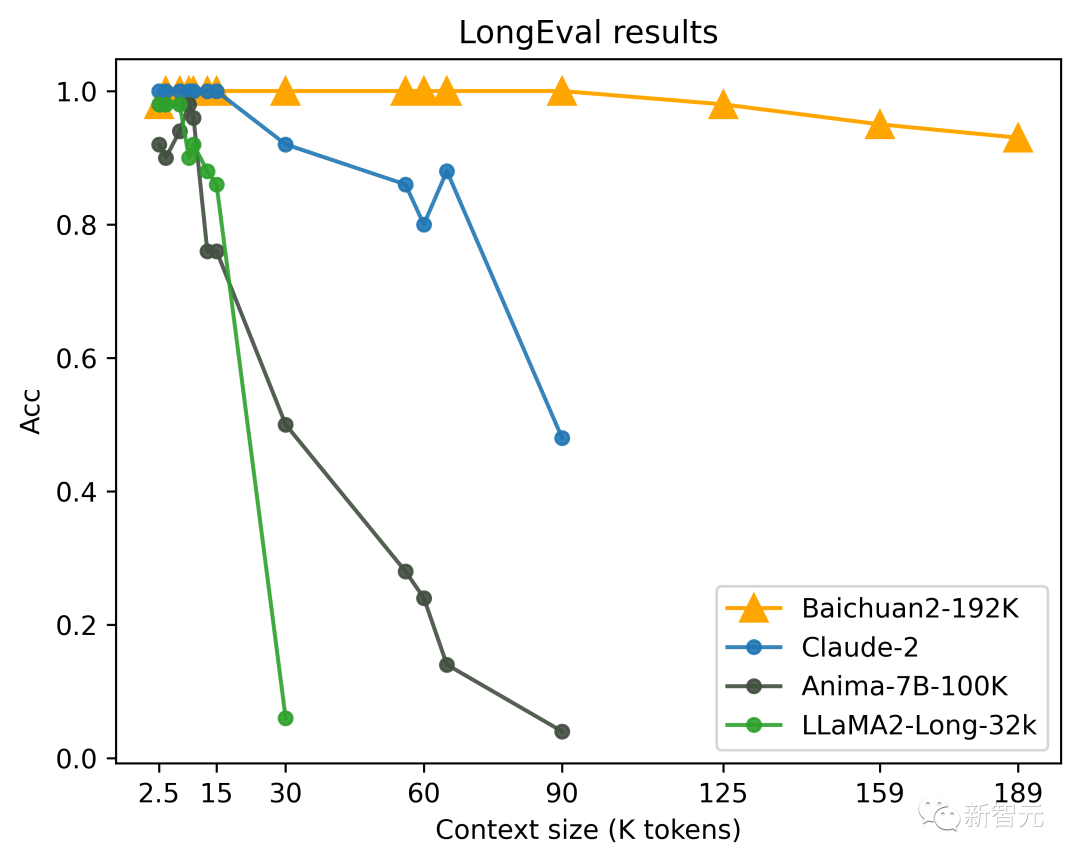
LongEval est un classement des évaluations de modèles à longue fenêtre publié par l'Université de Californie à Berkeley et d'autres universités. Il mesure principalement la capacité du modèle à mémoriser et à comprendre le contenu d'une fenêtre longue.
En termes de compréhension contextuelle, Baichuan2-192K est nettement en avance sur les autres modèles sur la liste d'évaluation de compréhension de texte à longue fenêtre faisant autorité LongEval, et peut toujours maintenir de très bonnes performances après que la longueur de la fenêtre dépasse 100K.
En revanche, les performances globales de Claude 2 chutent considérablement lorsque la longueur de la fenêtre dépasse 80 K.
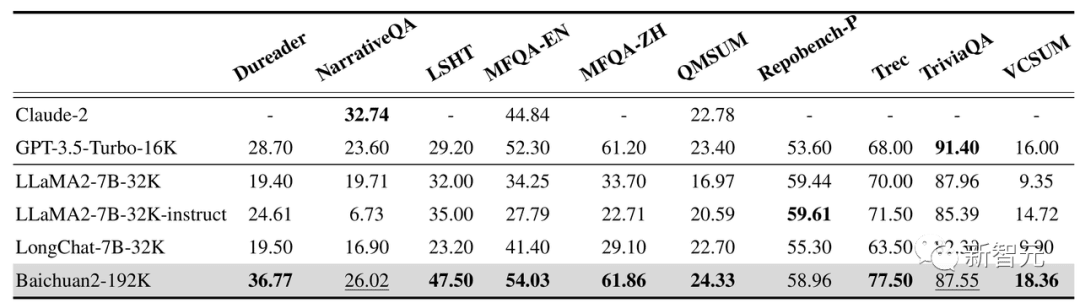
De plus, Baichuan2-192K obtient également de bons résultats sur 10 ensembles d'évaluation de réponses et de résumés de questions de texte long en chinois et en anglais, notamment Dureader, NarrativeQA, LSHT et TriviaQA.
Parmi eux, 7 ont atteint le SOTA, surpassant considérablement les autres modèles à longue fenêtre.
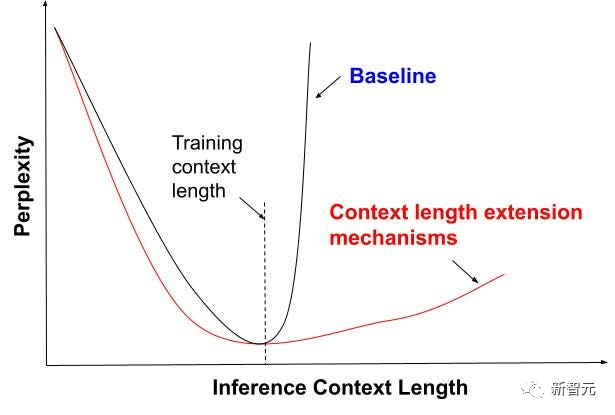
La perplexité est un critère très important en termes de qualité de génération de texte.
On peut comprendre simplement que lorsque des documents de haute qualité conformes aux habitudes du langage naturel humain sont utilisés comme ensemble de test, plus la probabilité que le modèle génère le texte dans l'ensemble de test est élevée, plus la perplexité du modèle est faible et meilleur est le modèle.
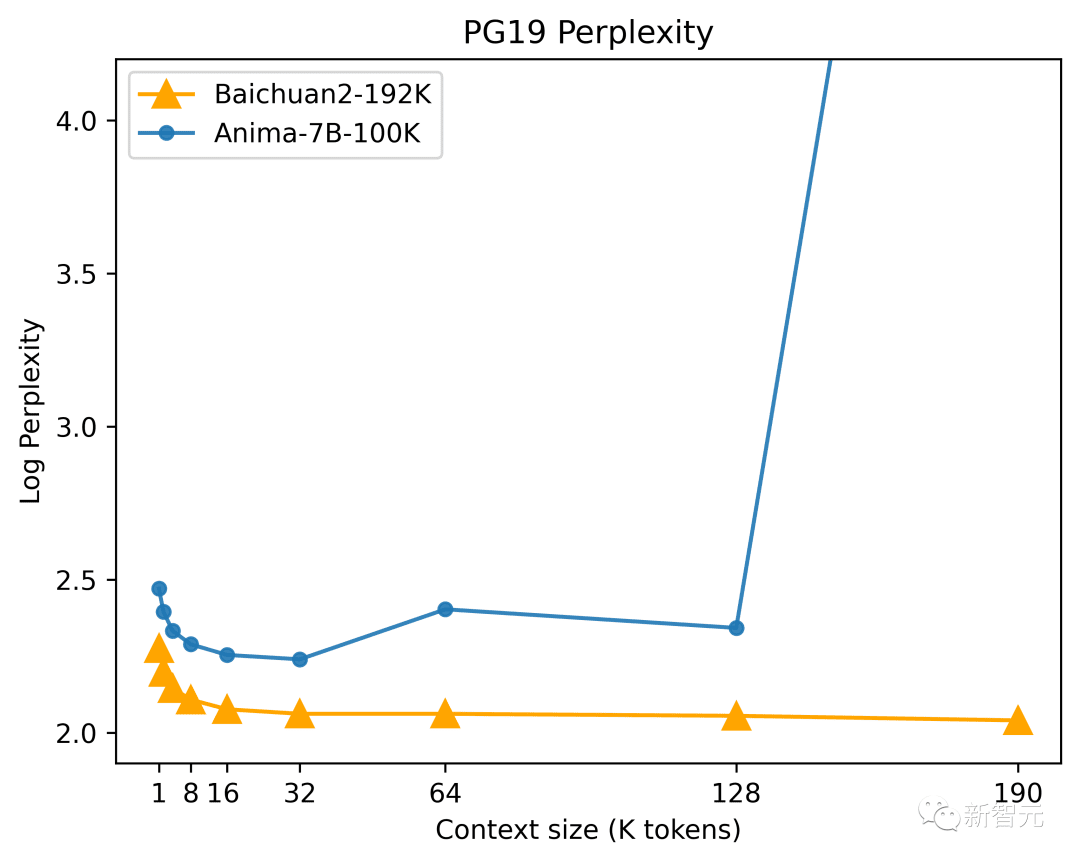
Selon les résultats des tests du « Language Modeling Benchmark Dataset PG-19 » publiés par DeepMind, la perplexité de Baichuan2-192K était excellente au stade initial, et à mesure que la longueur de la fenêtre augmentait, la capacité de modélisation de séquence de Baichuan2-192K continuait d'augmenter.
 Optimisation conjointe des algorithmes d'ingénierie pour améliorer simultanément la longueur et les performances
Optimisation conjointe des algorithmes d'ingénierie pour améliorer simultanément la longueur et les performances
Bien qu'un contexte long puisse améliorer efficacement les performances du modèle, des fenêtres ultra-longues signifient également qu'une puissance de calcul plus forte et davantage de mémoire vidéo sont nécessaires.
À l’heure actuelle, la pratique courante dans l’industrie consiste à faire glisser les fenêtres, à réduire l’échantillonnage, à réduire les modèles, etc.
Cependant, ces méthodes sacrifieront les performances d’autres aspects du modèle à des degrés divers.
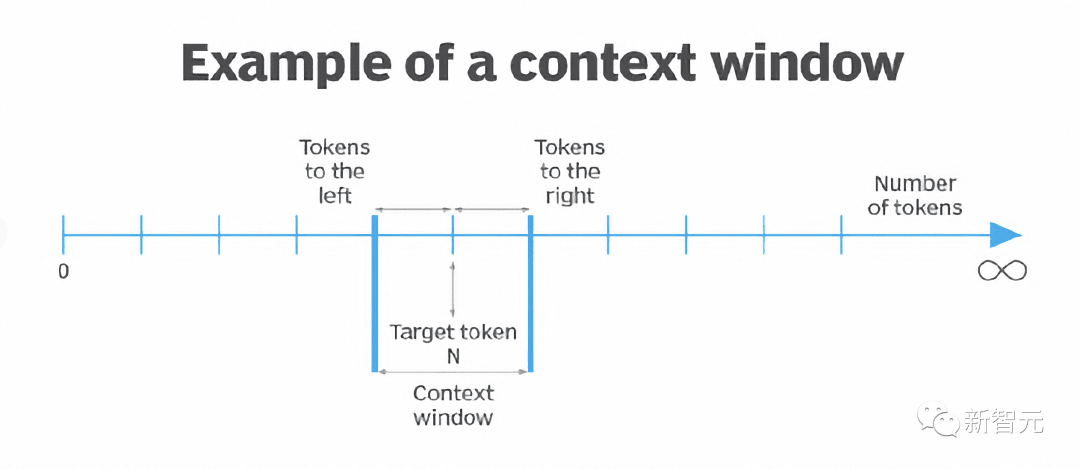
Pour résoudre ce problème, Baichuan2-192K atteint un équilibre entre la longueur de la fenêtre et les performances du modèle grâce à une optimisation extrême des algorithmes et de l'ingénierie, obtenant une amélioration simultanée de la longueur de la fenêtre et des performances du modèle.
Premièrement, en termes d'algorithmes, Baichuan Intelligence a proposé un schéma d'extrapolation pour l'encodage de position dynamique RoPE et ALiBi, qui peut interpoler dynamiquement le masque d'attention à différents degrés pour les encodages de position ALiBi de différentes longueurs, tout en garantissant la résolution et en améliorant la capacité du modèle à modéliser de longues dépendances de séquences.
Deuxièmement, en termes d'ingénierie, Baichuan Intelligence a intégré presque toutes les technologies d'optimisation avancées du marché, notamment le parallélisme tensoriel, le parallélisme de pipeline, le parallélisme de séquence, le recalcul et le déchargement, en s'appuyant sur son propre cadre de formation distribuée, et a créé une solution distribuée parallèle 4D complète. Il peut automatiquement trouver la stratégie distribuée la plus adaptée en fonction des conditions de charge spécifiques du modèle, réduisant ainsi considérablement l'utilisation de la mémoire lors de la formation et de l'inférence à longue fenêtre.
Les tests internes ont officiellement commencé, une expérience de première main a été publiée
Désormais, Baichuan2-192K a officiellement commencé les tests internes !
Les principaux partenaires de Baichuan Intelligence ont déjà intégré Baichuan2-192K dans leurs propres applications et activités via des appels API. Les médias financiers, les cabinets d'avocats et d'autres institutions ont désormais conclu une coopération avec Baichuan Intelligence.
Il est concevable qu'à mesure que les capacités de contexte long de pointe de Baichuan2-192K seront appliquées à des scénarios spécifiques tels que les médias, la finance et le droit, cela créera sans aucun doute un espace plus large pour la mise en œuvre de grands modèles.
Grâce à l'API, Baichuan2-192K peut être efficacement intégré dans des scénarios plus verticaux et profondément combiné avec eux.
Dans le passé, les documents contenant une quantité énorme de contenu devenaient souvent une énorme montagne que nous ne pouvions pas surmonter dans notre travail et nos études.

Avec Baichuan2-192K, des centaines de pages de documents peuvent être traitées et analysées simultanément, et des informations clés peuvent être extraites et analysées.
Qu'il s'agisse de résumé/révision de longs documents, de rédaction d'articles ou de rapports longs ou d'assistance à la programmation complexe, Baichuan2-192K vous apportera une grande aide.
Pour les gestionnaires de fonds, cela peut aider à résumer et à interpréter les états financiers et à analyser les risques et les opportunités d’une entreprise.
Pour les avocats, cela peut aider à identifier les risques dans plusieurs documents juridiques et à examiner les contrats et les documents juridiques.
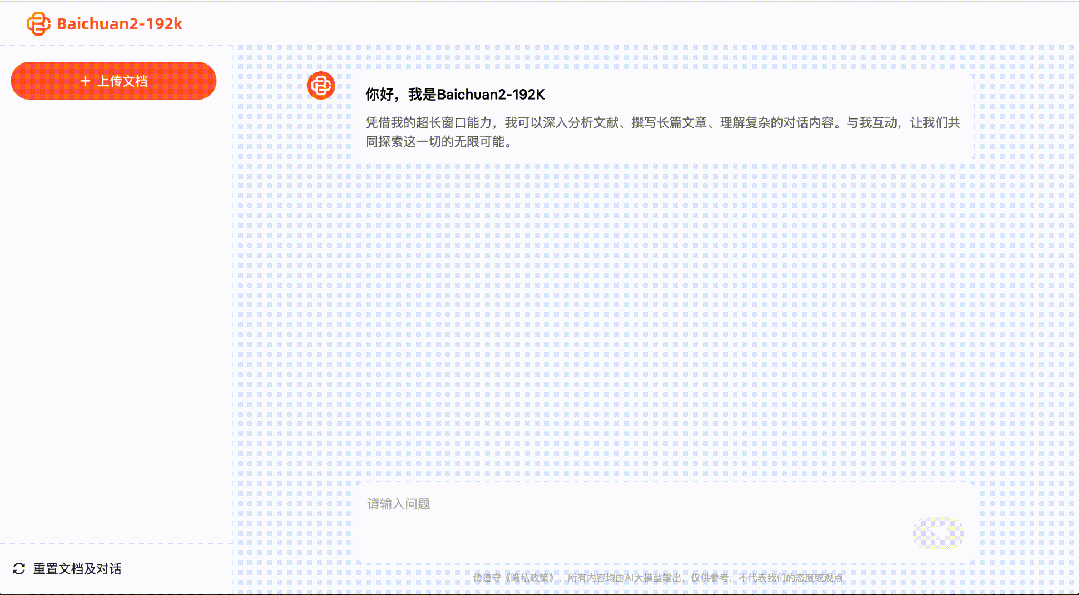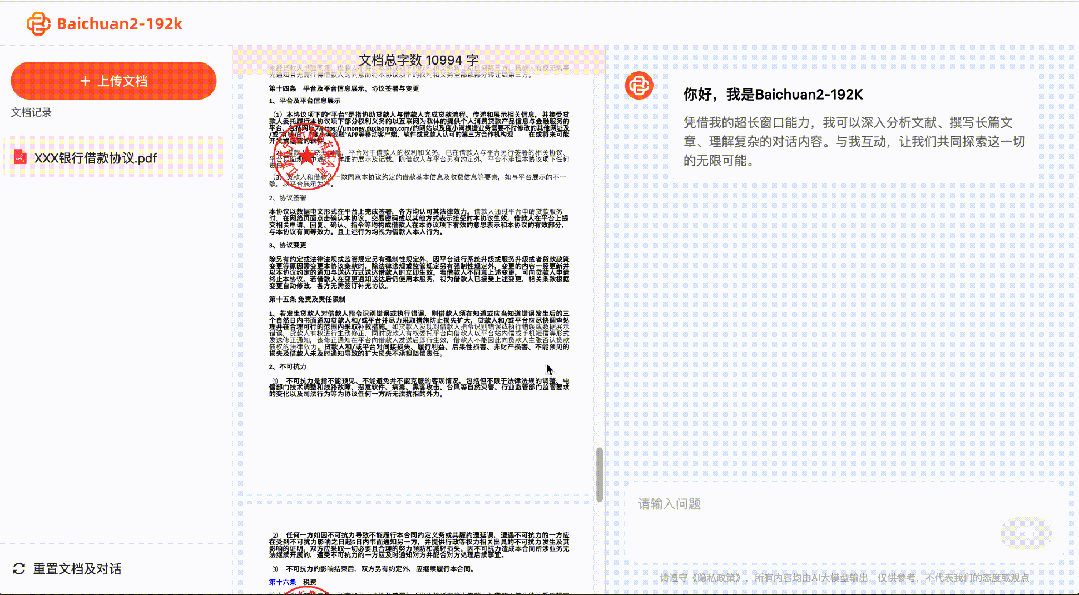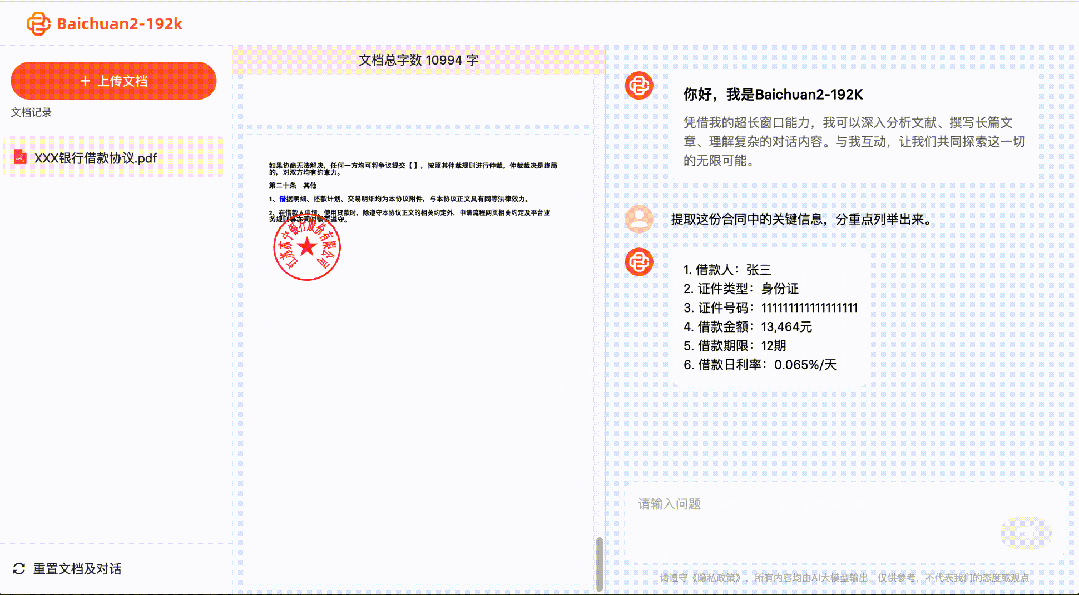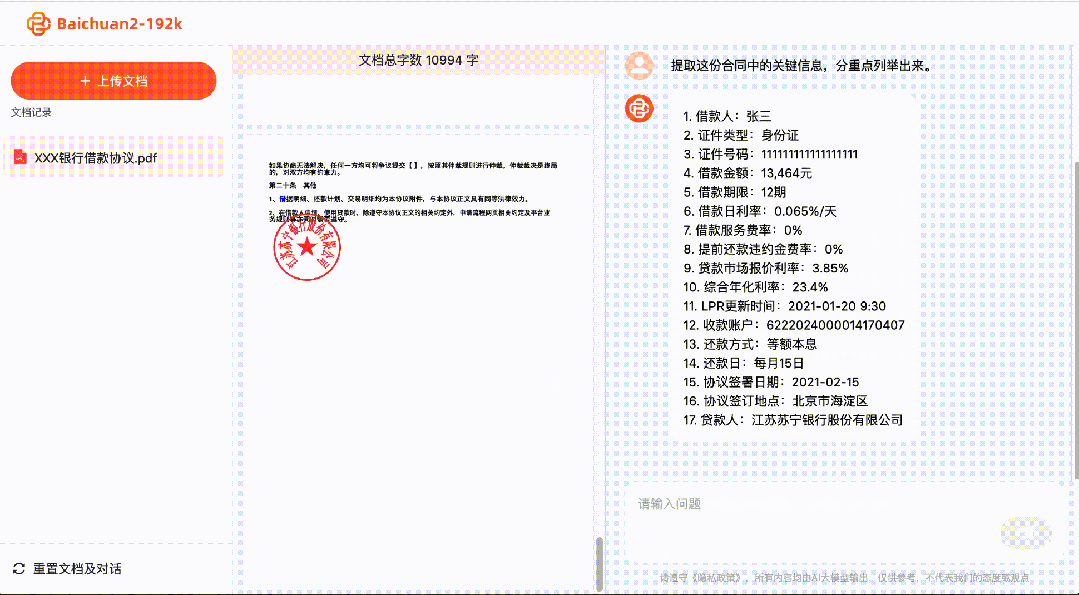
Pour les développeurs, cela peut aider à lire des centaines de pages de documentation de développement et à répondre à des questions techniques.
Désormais, la grande majorité des chercheurs scientifiques disposent d’un outil de recherche puissant qui leur permet de parcourir rapidement un grand nombre d’articles et de synthétiser les dernières avancées de pointe.
Au-delà de cela, les contextes plus longs recèlent un potentiel encore plus grand.
Les agents et les applications multimodales sont tous deux des points chauds de pointe dans la recherche industrielle actuelle. Les grands modèles, dotés de capacités contextuelles plus longues, peuvent mieux traiter et comprendre les entrées multimodales complexes et réaliser un meilleur apprentissage par transfert.
La longueur du contexte, un champ de bataille
On peut dire que la longueur de la fenêtre de contexte est l’une des technologies de base des grands modèles.
Désormais, de nombreuses équipes ont commencé à utiliser la « saisie de texte long » comme point de départ pour créer une compétitivité différenciée du grand modèle de base. Si le nombre de paramètres détermine la complexité des calculs qu'un grand modèle peut effectuer, la longueur de la fenêtre de contexte détermine la quantité de « mémoire » dont dispose le grand modèle.
Sam Altman a dit un jour que nous pensions vouloir des voitures volantes, pas 140/280 personnages, mais en fait nous voulions 32 000 jetons.

Tant au niveau national qu’à l’étranger, les recherches et les produits visant à élargir la fenêtre contextuelle émergent en un flux incessant.
En mai de cette année, GPT-4, qui possède un contexte de 32 000, a suscité de vives discussions.
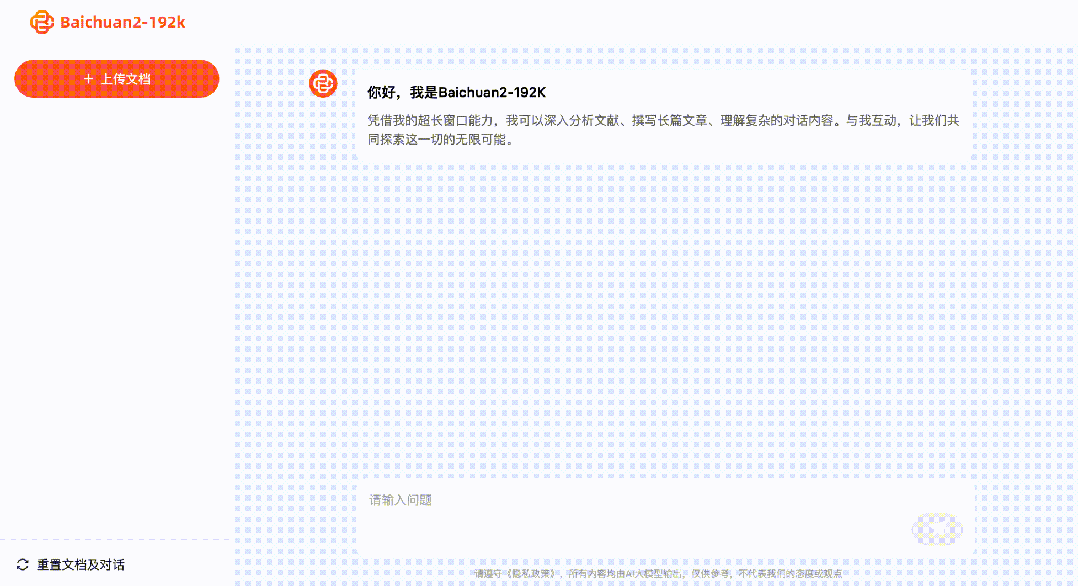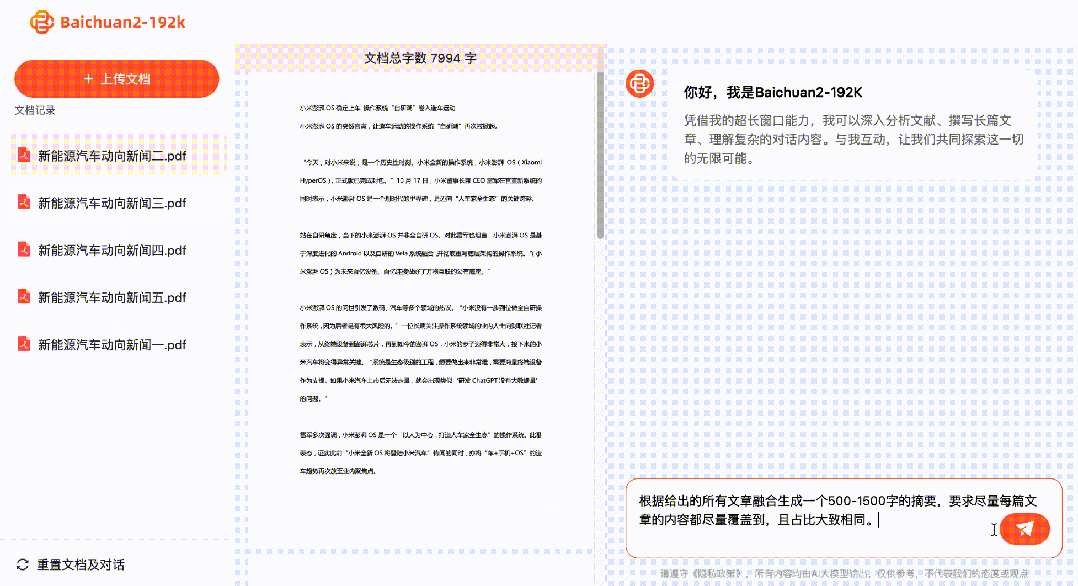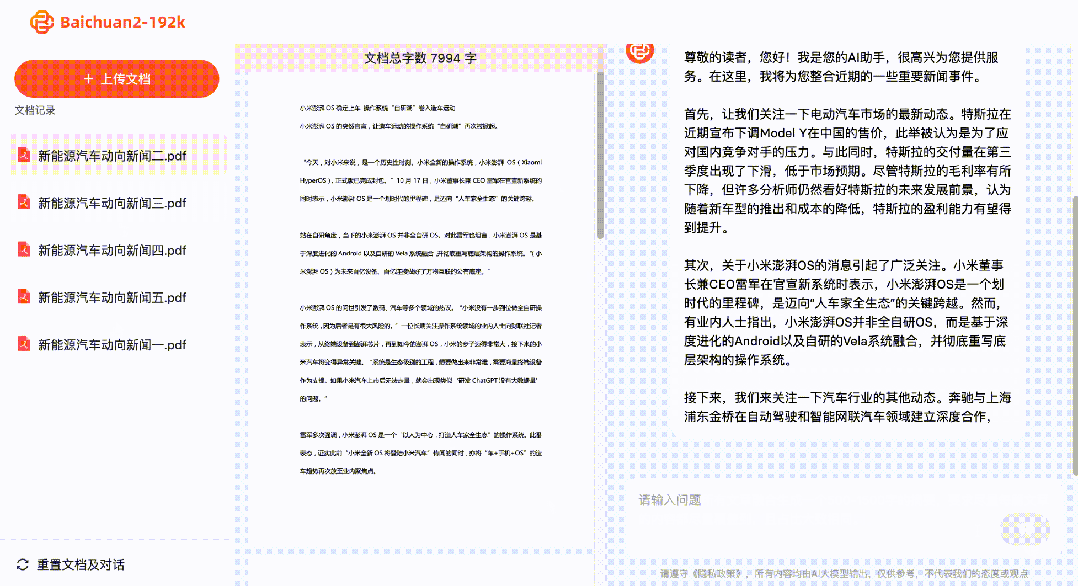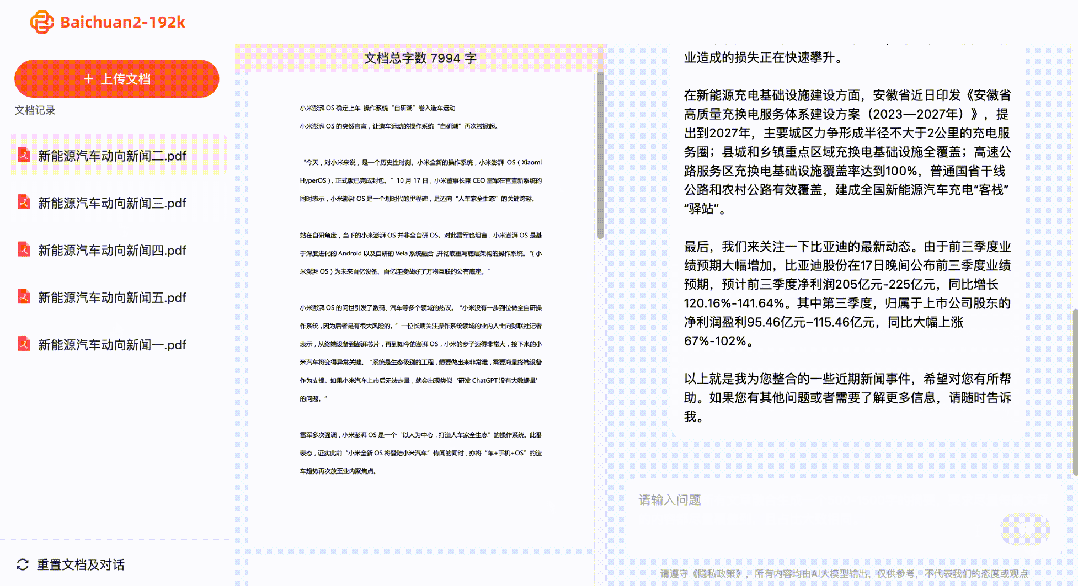
À cette époque, les internautes qui avaient débloqué cette version ont salué GPT-4 32K comme le meilleur gestionnaire de produits au monde.
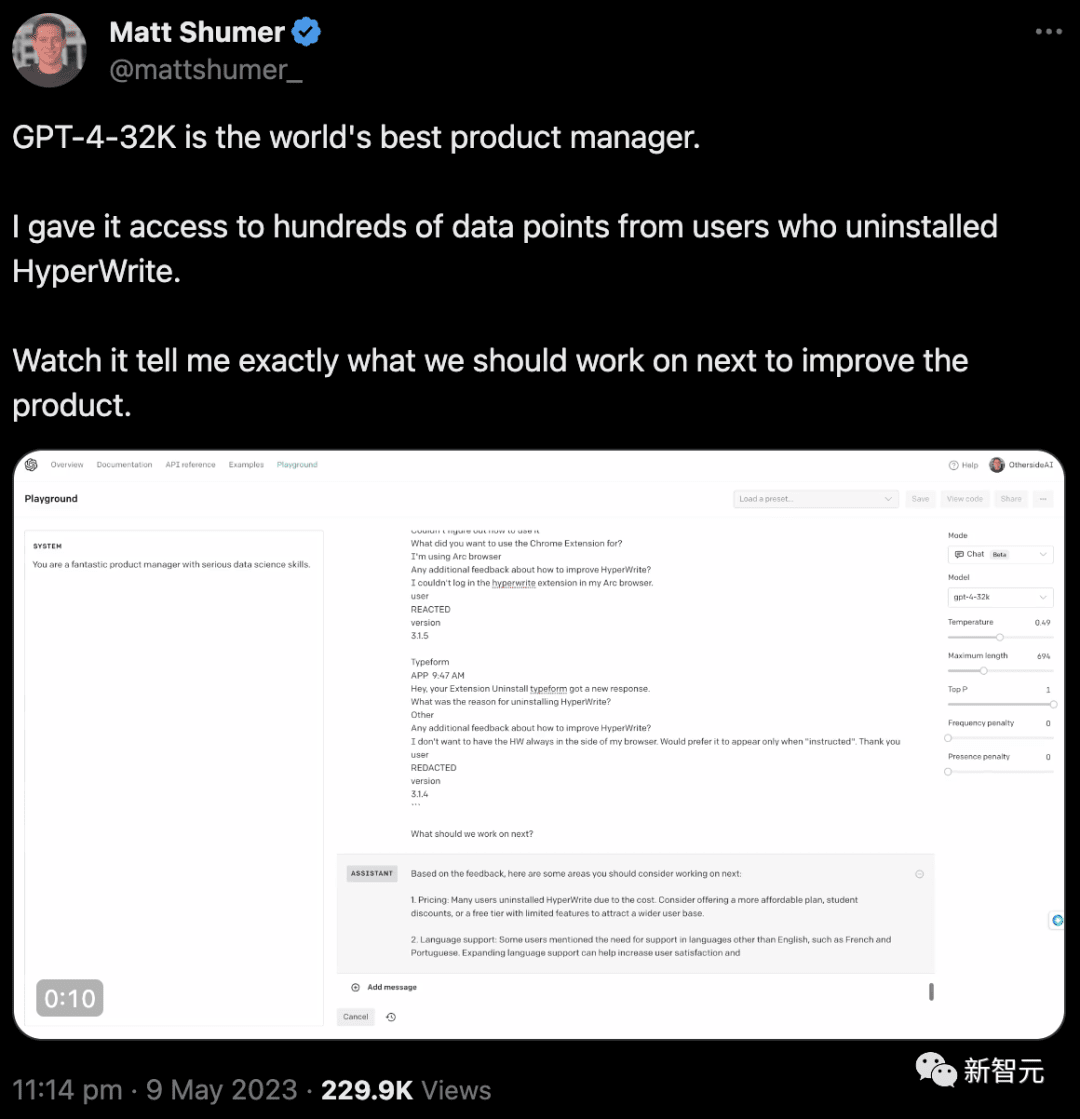
Bientôt, la startup Anthropic a annoncé que Claude était capable de prendre en charge des jetons de contexte d'une longueur de 100 000, soit environ 75 000 mots.
En d’autres termes, il faut en moyenne 5 heures à une personne pour lire la même quantité de contenu, et elle aura besoin de plus de temps pour le digérer, le mémoriser et l’analyser. Pour Claude, cela a pris moins d’une minute.
Dans la communauté open source, Meta a également proposé une méthode pour étendre efficacement les capacités de contexte, ce qui peut augmenter la fenêtre de contexte du modèle de base à 32 768 jetons et obtenir des améliorations de performances significatives dans diverses tâches de détection de contexte synthétique et de modélisation du langage.
Les résultats montrent qu'un modèle avec des paramètres 70B a atteint des performances supérieures à gpt-3.5-turbo-16k dans diverses tâches à contexte long.

Adresse du document : https://arxiv.org/abs/2309.16039
La méthode LongLoRA proposée par l'équipe CUHK et MIT ne nécessite que deux lignes de code et une machine A100 à 8 cartes pour étendre la longueur du texte du modèle 7B à 100 000 jetons et la longueur du texte du modèle 70B à 32 000 jetons.

Adresse du document : https://arxiv.org/abs/2309.12307
Des chercheurs de DeepPavlov, d'AIRI et du London Institute of Mathematical Sciences ont utilisé la méthode du transformateur de mémoire récurrent (RMT) pour augmenter la longueur de contexte effective de BERT à « un nombre sans précédent de 2 millions de jetons » tout en maintenant un niveau élevé de précision de récupération de mémoire.
Cependant, bien que RMT puisse évoluer vers une longueur de séquence presque illimitée sans augmenter la consommation de mémoire, il souffre toujours du problème de dégradation de la mémoire dans RNN et nécessite un temps d'inférence plus long.

Adresse du document : https://arxiv.org/abs/2304.11062
Actuellement, la longueur de la fenêtre de contexte de LLM est principalement concentrée dans la plage de 4 000 à 100 000 jetons et continue de croître.
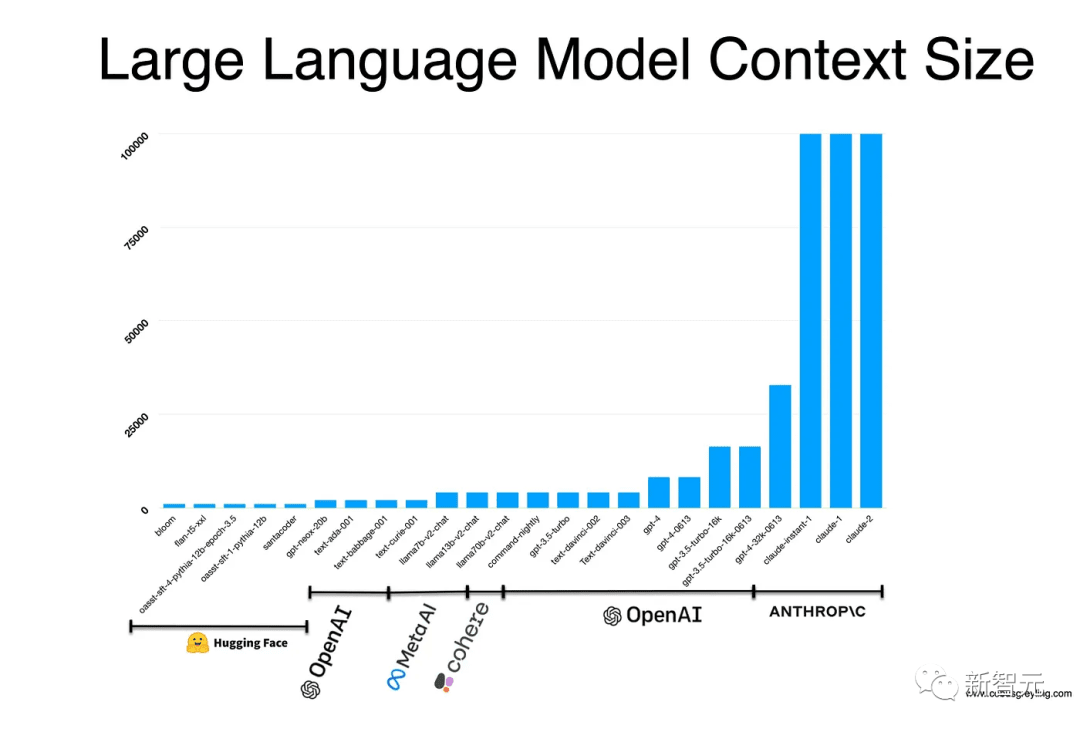
L’industrie de l’IA et le monde universitaire ont mené diverses études sur les fenêtres contextuelles, démontrant leur importance pour le LLM.
Cette fois, le grand modèle national a inauguré le point culminant historique de la fenêtre de contexte la plus longue.
La fenêtre de contexte de 192 000, un record de l'industrie, représente non seulement une autre avancée dans la technologie des modèles à grande échelle par Baichuan Intelligence, une entreprise phare, mais marque également une autre étape importante dans le développement de modèles à grande échelle. Cela entraînera inévitablement une nouvelle série de chocs sur la réforme de la forme du produit.

Fondée en avril 2023, Baichuan Intelligence n'a mis que 6 mois pour publier quatre grands modèles open source et commerciaux gratuits, Baichuan-7B/13B, Baichuan2-7B/13B, et deux grands modèles à source fermée, Baichuan-53B et Baichuan2-53B.
Selon ce calcul, je mets à jour LLM une fois par mois.
Désormais, avec la sortie du Baichuan2-192K, la technologie de fenêtre de contexte longue et grand modèle entrera également pleinement dans l'ère chinoise !