

Date du rapport : 2026-03-11
Portée de l'échantillon : Top 100 des compétences ClawHub par téléchargements (au 10 mars, 18h30 heure de Pékin)
Moteur de Détection : Moteur de Scanning de Sécurité des Compétences AgentGuard
Objectif de l'analyse : Évaluer la posture de sécurité de base des compétences d'agent IA les plus populaires et identifier les risques potentiels tels que l'abus de privilèges, les opérations sensibles et les schémas de comportement malveillant.
📊 1. Résumé Exécutif
Cette analyse de sécurité a réalisé une analyse complète des 100 compétences les plus téléchargées dans l'écosystème ClawHub. Les résultats globaux sont les suivants :
Échantillons totaux scannés : 100
Taux de scan réussi : 100 % (aucune erreur de parsing ou fichiers manquants)
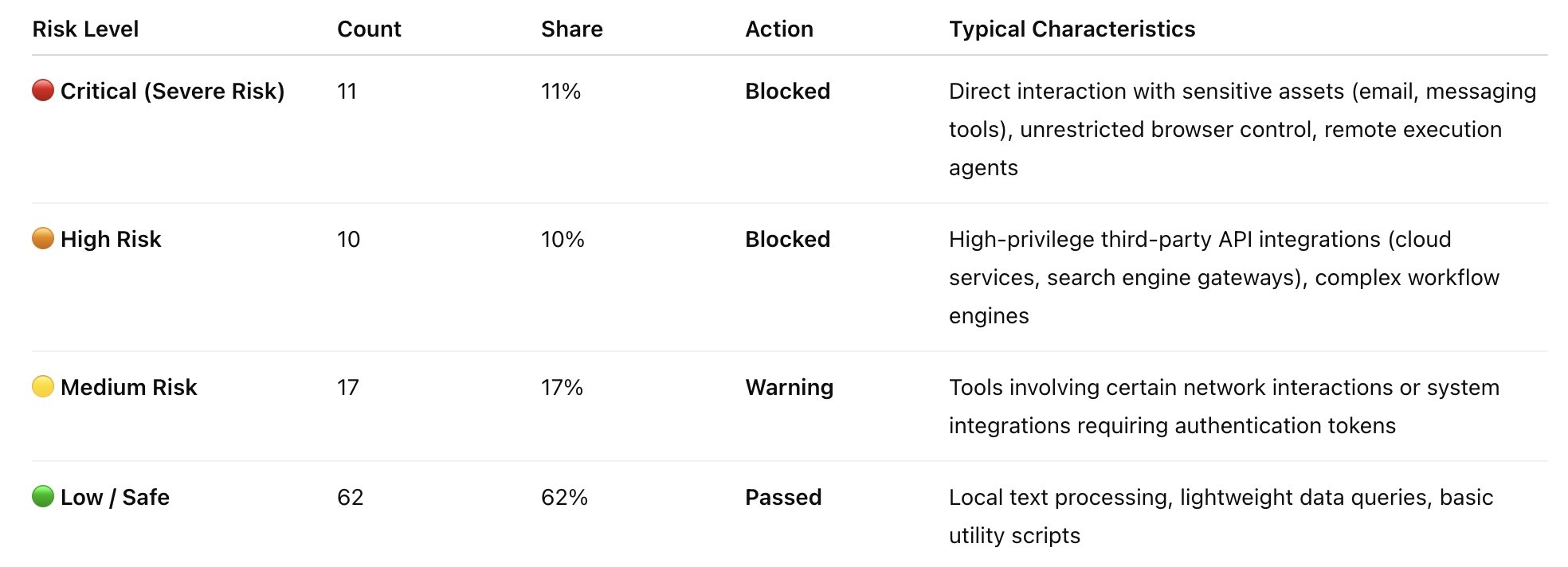
Compétences bloquées : 21 (21 %)
Compétences d'avertissement : 17 (17 %)
Compétences réussies : 62 (62 %)

Constat clé : Parmi les 100 meilleures compétences, 21 % contiennent des opérations à haut risque explicites (telles que le tunneling réseau direct, les appels API sensibles ou la messagerie automatisée). Pour ces compétences, il est recommandé de mettre en œuvre un mécanisme de confirmation Human-in-the-Loop (HITL) avant l'exécution pour assurer un examen manuel des actions à haut risque.
De plus, 17 % des compétences présentent certains signaux de risque et doivent être exécutées avec prudence. Pour les utilisateurs ayant des exigences de sécurité plus strictes, il est également recommandé d'activer la confirmation manuelle pour ces compétences.
📈 2. Distribution du niveau de risque
Sur la base de l'ensemble de règles AgentGuard, les résultats du scan sont classés en quatre niveaux de risque, avec la distribution suivante :
🚨 3. Analyse des compétences à haut risque (Critique & Élevé)
Dans cette analyse de sécurité, 21 compétences ont été directement classées comme bloquées après avoir déclenché des règles critiques ou à haut risque. Ces compétences relèvent principalement des scénarios opérationnels à haut risque suivants :
3.1. Navigateurs sans tête & Automatisation (Automatisation des navigateurs)
Ces compétences appellent généralement Puppeteer/Playwright ou des outils CLI emballés, permettant à l'Agent d'accéder librement à Internet.
Compétences concernées : agent-browser (Critique), agent-browser-clawdbot (Critique)
Raison de détection : Détection du contrôle de processus de navigateur sans tête, exécution de scripts JS arbitraires ou interactions DOM complexes.
Impact du risque : Peut être utilisé pour SSRF (Server-Side Request Forgery), exploration de réseau interne, contournement des protections CAPTCHA pour le scraping malveillant, ou déclenchement de charges utiles à partir de sites Web de phishing.
3.2. Communications & Messagerie (Communications & Messagerie)
Compétences qui contrôlent directement les outils de messagerie ou d'email des utilisateurs pour envoyer des messages.
Compétences concernées : agentmail (Critique), whatsapp-business (Critique), imap-smtp-email (Critique), mailchimp (Élevé)
Raison de détection : Détection de mots clés du protocole SMTP/IMAP, points de terminaison API de messagerie en masse et jetons de communication à haut privilège.
Impact du risque : Si un Agent est compromis par une attaque par injection de prompt, les attaquants pourraient utiliser ces compétences pour envoyer du spam ou mener des escroqueries d'ingénierie sociale, nuisant à la réputation des utilisateurs et violant potentiellement les exigences de conformité en matière de confidentialité.
3.3. CRM à haut privilège & API de ressources Cloud (Passerelles API d'entreprise)
Compétences qui effectuent des opérations de lecture/écriture sur des plateformes SaaS d'entreprise via des passerelles proxy.
Compétences concernées : google-workspace-admin (Critique), google-slides (Critique), feishu-evolver-wrapper (Critique), pipedrive-api (Élevé), youtube-api-skill (Élevé), trello-api (Élevé), google-meet (Élevé)
Raison de détection : Le moteur de règles a détecté des structures de requêtes API REST capables de modifier des données sensibles, ainsi que la capacité à altérer l'état des systèmes externes.
Impact du risque : Les agents peuvent modifier directement ou même supprimer des données d'entreprise critiques telles que les ventes, les documents ou les actifs médiatiques (y compris l'octroi ou la révocation de privilèges administratifs). Sans une vérification stricte de type Human-in-the-Loop, des erreurs opérationnelles pourraient entraîner des pertes graves.
3.4. Moteurs de recherche profonds & Agrégation de scraping (Recherche & Scraping)
Outils capables de crawler en profondeur le contenu et d'agréger plusieurs moteurs.
Compétences concernées : brave-search (Élevé), duckduckgo-search (Élevé), multi-search-engine (Élevé), tavily (Élevé)
Raison de détection : Détection de wrappers de requêtes réseau externes à haute fréquence, d'analyse HTML et de bibliothèques de scraping.
Impact du risque : En plus des interdictions potentielles d'IP des sites Web cibles, l'extraction de contenu Web non sécurisé (comme la lecture directe de HTML non filtré ou l'exécution de contenu de page Web) peut introduire des risques d'injection de prompt indirects.
3.5. Modification de la logique de base & Escalade de privilèges (Auto-modification & Escalade de privilèges)
Compétences impliquant la mutation du comportement de l'Agent, la modification de configurations cachées ou l'accès aux identifiants au niveau système.
Compétences concernées : free-ride (Critique), moltbook-interact (Critique), trello (Critique), evolver (Élevé)
Raison de détection : Détection de demandes d'accès en écriture aux fichiers système (comme les fichiers de configuration .json cachés), la capacité de lire les identifiants locaux, ou la concaténation directe de jetons sensibles dans des commandes Bash.
Impact du risque : Ces compétences peuvent modifier les règles comportementales essentielles de l'Agent sans autorisation, contourner les restrictions système existantes, ou divulguer des clés API critiques en raison de vulnérabilités d'injection de commandes.
⚠️ 4. Compétences à risque moyen (Moyen / Avertissement) méritant attention
Un total de 17 compétences ont été classées comme à risque moyen. La plupart d'entre elles sont des interfaces d'intégration pour des applications tierces. Bien que le moteur de scan ne les ait pas bloquées directement, les considérations suivantes s'appliquent :
Outils de calendrier & de planification (caldav-calendar, calendly-api)
Outils de productivité & de collaboration (notion, x-twitter, xero, typeform)
Intégrations de l'écosystème Microsoft (microsoft-excel, outlook-graph, outlook-api)
Kits d'outils utilitaires (mcporter, asana-api, clickup-api)
Analyse : La caractéristique clé de ces compétences est que leur fonctionnalité est neutre, mais elles portent des identifiants de grande valeur. Le scan de sécurité a identifié qu'elles nécessitent des jetons d'accès des utilisateurs, mais aucune logique malveillante explicite n'a été détectée au niveau du code, elles ont donc été étiquetées comme Avertissement. Cependant, si un Agent est trompé pour utiliser ces compétences (par exemple, en étant instruit de “supprimer toutes mes réunions demain” ou “partager publiquement ce document Notion”), des dommages significatifs pourraient encore se produire.
🛡️ 5. Résumé & Recommandations de sécurité
Ce scan de sécurité montre qu'environ 20 % des 100 compétences les plus téléchargées sur ClawHub contiennent des opérations à haut risque explicites, démontrant la nécessité d'effectuer des scans de sécurité et des examens pour les compétences.
Recommandations pour les utilisateurs et les développeurs de l'écosystème :
5.1. Améliorer l'utilisabilité des compétences à haut risque (Bloquées) : Éviter les interdictions générales. Pour les compétences à forte valeur telles que agent-browser et agentmail, il est recommandé de mettre en œuvre un mécanisme de confirmation Human-in-the-Loop (HITL) avant l'exécution. Le contenu spécifique à envoyer ou les actions à effectuer doivent être affichés, et l'exécution ne doit se poursuivre qu'après autorisation explicite de l'utilisateur.
5.2. Renforcer la protection contre l'“Injection de prompt indirecte” : Pour toutes les compétences liées à la recherche marquées comme Élevées, le contenu renvoyé à l'Agent doit subir une désinfection stricte (comme le retrait des balises HTML et des scripts) pour prévenir l'injection de contenu malveillant à partir de pages Web externes.
5.3. Effectuer des contrôles de santé de sécurité réguliers: Sur la base des points aveugles de sécurité identifiés dans cette analyse, des actions telles que modifier des chemins de fichiers de configuration spécifiques (par exemple, AGENTS.md) et invoquer des bibliothèques de contrôle de bureau système devraient être ajoutées à la liste des comportements à haut risque. Alternativement, les développeurs peuvent utiliser les capacités d'inspection de sécurité AgentGuard et de scan des compétences pour auditer régulièrement la posture de sécurité des Agents et de leurs compétences.
👉Annexe : Résultats détaillés du scan de sécurité des 100 meilleures compétences de ClawHub
Cliquez sur le lien pour voir :
https://inky-punch-9d2.notion.site/Appendix-Detailed-Results-of-the-ClawHub-Top-100-Skills-Security-Sca-3215da0dd7ad80719937c66b7c1225b3?source=copy_link