

Début septembre, Yandex a organisé une mini-conférence privée sur l'IA générative, offrant une plateforme pour une plongée approfondie dans le monde de l'IA. Néanmoins, la conférence a apporté des révélations significatives, notamment concernant le très attendu YandexGPT 2.
Le dévoilement par Yandex de YandexGPT 2 a fait vibrer la communauté de l’IA d’impatience. Les créateurs de ce modèle ont exploré diverses fonctionnalités distinctives, notamment un module spécialisé conçu pour rechercher et fournir des réponses basées sur les données des résultats de recherche. Les révélations de l’équipe ont notamment dévoilé un aspect frappant : même formé sur un vaste référentiel de données internes Yandex s’étalant sur plus d’une décennie de travail sur les mécanismes de recherche neuronale, ce modèle propriétaire était toujours en deçà du formidable GPT-4. Ce développement important souligne les progrès remarquables réalisés par GPT-4. Cette observation accentue la suprématie de GPT-4 sur les développements propriétaires et les itérations open source antérieures.
S'appuyant sur ces connaissances fondamentales, Google a mené une étude pour évaluer la précision des réponses issues de modèles linguistiques étendus (LLM) accessibles par les moteurs de recherche. Bien que l'idée d'intégrer un outil externe aux LLM ne soit pas nouvelle, Google a constaté que la complexité réside dans l'évaluation et la validation nuancées de ces modèles. Les facteurs cruciaux qui façonnent cette intégration comprennent le choix d'une invite soigneusement élaborée et les capacités intrinsèques des LLM.
Méthodologie de test LLM de Google
Un corpus de 600 questions a été divisé en quatre groupes distincts. Chaque groupe privilégiait l'exactitude factuelle, mais l'un d'eux se distinguait par l'inclusion de questions fondées sur des prémisses erronées. Par exemple, des questions comme « Qu'a écrit Trump après sa révocation sur Twitter ? » contenaient une prémisse erronée, Trump n'ayant pas été révoqué. Les trois groupes restants ont introduit des variables d'obsolescence des réponses : jamais, rarement et souvent. Dans le groupe « jamais », les étudiants en droit devaient répondre uniquement de mémoire, tandis que les questions sur des événements récents nécessitaient une recherche en temps réel. Chaque groupe comprenait 125 questions.
Les questions ont été soumises à un large éventail de modèles. Curieusement, les questions contenant de fausses prémisses ont révélé la prédominance de GPT-4 et de ChatGPT, qui ont habilement réfuté ces prémisses, témoignant de leur formation spécifique pour relever de tels défis.
Une analyse comparative a ensuite été réalisée, opposant ChatGPT, GPT-4, la recherche Google (basée sur des extraits de texte ou des réponses de première page) et PPLX.AI (une plateforme utilisant ChatGPT pour agréger les réponses de Google, destinée aux développeurs). Dans ce contexte, les étudiants en master ont fourni des réponses exclusivement de mémoire.
Il est à noter que la recherche Google a fourni des réponses correctes dans 40 % des cas en moyenne pour les quatre groupes. La précision des questions « éternelles » s'élevait à 70 %, tandis que celle des questions à prémisses fausses chutait à seulement 11 %. Les performances de ChatGPT ont atteint 26 % en moyenne, tandis que celles de GPT-4 ont atteint 28 %, répondant de manière impressionnante aux questions à prémisses fausses dans 42 % des cas. PPLX.AI a affiché un taux de réussite de 52 %.
L'étude a approfondi ses connaissances grâce à une approche novatrice. Chaque question donnait lieu à une recherche Google, dont les résultats étaient intégrés à l'invite. Les étudiants en master de droit devaient ensuite « lire » ces informations avant de rédiger leurs réponses. Cette technique a permis un apprentissage par petites touches (où des exemples sont présentés dans l'invite pour guider le modèle) et une réflexion approfondie, étape par étape, avant de répondre.
Les résultats étaient tout simplement fascinants. GPT-4 a affiché un taux de qualité remarquable de 77 %, répondant aux questions « éternelles » avec une précision de 96 % et aux questions à prémisses fausses avec une précision louable de 75 %. Si ChatGPT a présenté des indicateurs légèrement moins impressionnants, il a surpassé PPLX.AI et la recherche Google.
Maîtriser la conception d'invites d'IA : informations clés des experts de PPLX.AI et de Google
Guider efficacement les grands modèles linguistiques (LLM) à travers un labyrinthe d'informations n'est pas une mince affaire. Cependant, une étude récente des invites d'IA a mis en lumière des stratégies clés prometteuses pour améliorer la qualité des réponses générées par les LLM, offrant un aperçu des subtilités de l'assistance de l'IA.
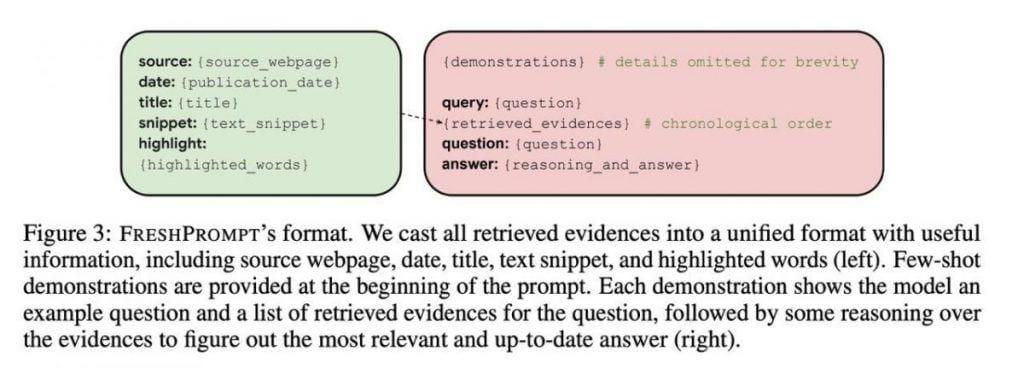
Les bases de cette révélation ont été posées grâce à une structuration minutieuse des questions. Cette méthode se compose de plusieurs éléments, offrant un chemin clair vers des réponses précises, solidement ancrées dans la compréhension contextuelle. Le premier aspect comprend des exemples illustratifs, servant de repères pour guider les étudiants vers la bonne réponse en fonction des indices contextuels.
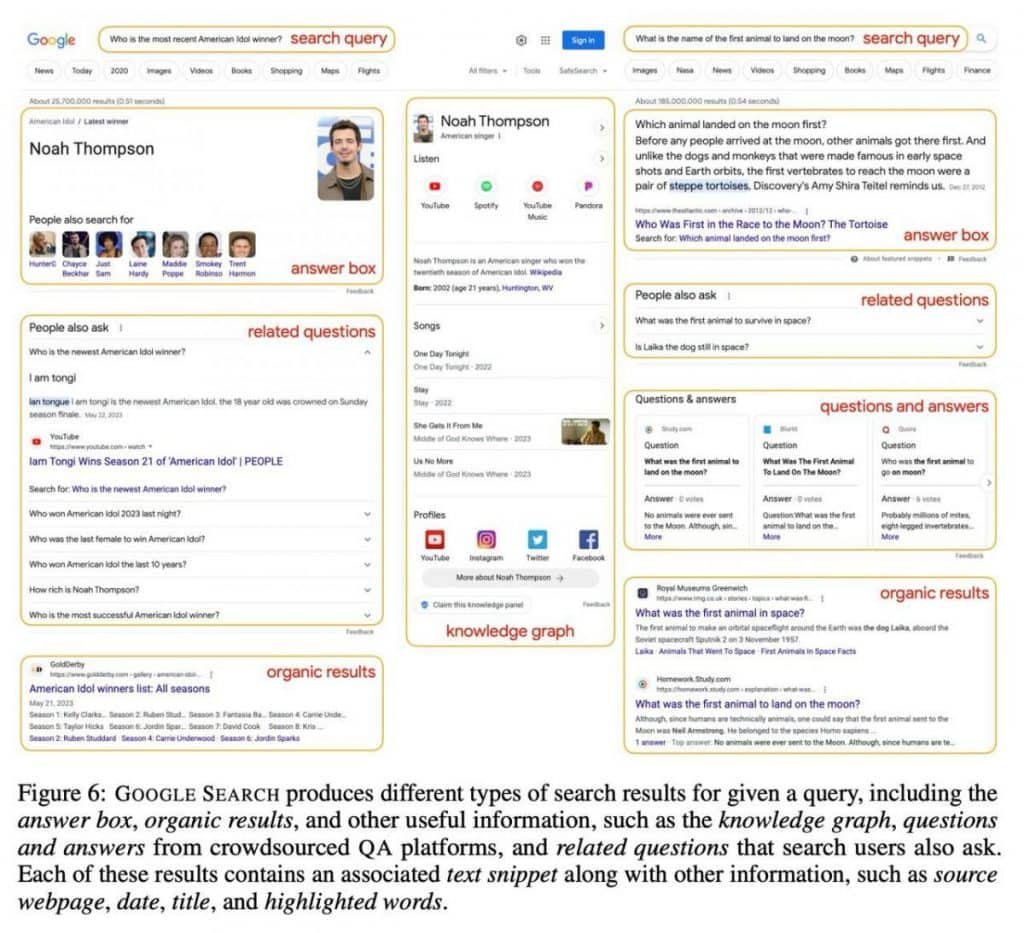
La deuxième couche révèle la requête elle-même ainsi que 10 à 15 résultats de recherche. Ces résultats vont au-delà de simples liens vers des pages web et englobent une multitude d'informations, notamment du contenu textuel, des requêtes pertinentes, des questions, des réponses et des graphiques de connaissances. Cette approche dote l'IA d'une bibliothèque de connaissances complète.
La sophistication de ce système va plus loin. Une découverte cruciale a été réalisée lors de l'organisation chronologique des liens au sein de l'invite, les ajouts les plus récents étant placés à la fin. Cette organisation chronologique reflète l'évolution de l'information et permet au modèle de discerner la chronologie des changements. L'inclusion de dates dans chaque exemple a joué un rôle essentiel dans l'amélioration de la compréhension contextuelle.
Bien que le code permettant d’utiliser cette structuration nuancée des invites soit attendu avec impatience, son absence a incité les passionnés à s’aventurer dans la réécriture de modèles d’invites en fonction des images fournies.
Plusieurs points clés ressortent de cette incursion dans la mécanique des invites d’IA :
1) PPLX.AI, une plateforme qui exploite ChatGPT pour agréger les réponses de Google, s'est révélée une option prometteuse. Même les employés de Google ont laissé entendre sa supériorité.
2) L'expérimentation de divers éléments a permis d'améliorer les indicateurs de réponse. La précision dans la construction des invites semble être un art en soi.
3) GPT-4 démontre une compétence remarquable dans le traitement de vastes volumes d'informations et de textes. Bien qu'il ne puisse être qualifié d'« excellent », sa qualité, même dans des scénarios d'actualité en constante évolution, oscille autour de 60 %. La communauté de l'IA est encouragée à évaluer ces indicateurs de manière critique.
4) Avec l'expansion continue de l'écosystème de l'IA, les LLM intégrés aux moteurs de recherche sont appelés à devenir omniprésents, s'adressant à un large éventail d'utilisateurs. La présence de l'IA dans les expériences de recherche quotidiennes est en pleine expansion, marquant une transformation profonde de la manière dont l'information est consultée et traitée.
L'approche multidimensionnelle offre un moyen prometteur d'obtenir des réponses précises à partir de ces modèles linguistiques sophistiqués, car elle inclut des exemples illustratifs, une requête clairement définie et une mine d'informations contextuelles. La disposition chronologique des liens au sein des invites a permis de dégager une idée importante, soulignant l'importance de s'adapter à la nature dynamique de l'information. Les étudiants en LLM peuvent naviguer dans la chronologie des changements grâce à cette connaissance temporelle, ce qui améliore leur compréhension contextuelle.
L’article L’analyse de Google révèle des informations surprenantes sur les LLM et la précision des moteurs de recherche est apparu en premier sur Metaverse Post.