
Un trio de scientifiques de l'Université de Caroline du Nord, à Chapel Hill, a récemment publié une pré-impression de recherche sur l'intelligence artificielle (IA) montrant à quel point il est difficile de supprimer des données sensibles de grands modèles linguistiques (LLM) tels que ChatGPT d'OpenAI et Bard de Google.
Selon l’étude des chercheurs, la tâche de « supprimer » des informations des LLM est possible, mais il est tout aussi difficile de vérifier que les informations ont été supprimées que de les supprimer réellement.
La raison en est liée à la manière dont les LLM sont conçus et formés. Les modèles sont pré-entraînés (GPT signifie « generative pre-trained transformer ») sur des bases de données, puis affinés pour générer des résultats cohérents.
Une fois qu’un modèle est formé, ses créateurs ne peuvent pas, par exemple, revenir dans la base de données et supprimer des fichiers spécifiques afin d’empêcher le modèle de générer des résultats associés. Essentiellement, toutes les informations sur lesquelles un modèle est formé existent quelque part dans ses pondérations et ses paramètres où elles sont indéfinissables sans générer réellement de résultats. C’est la « boîte noire » de l’IA.
Un problème survient lorsque les LLM formés sur des ensembles de données massifs génèrent des informations sensibles telles que des informations personnelles identifiables, des dossiers financiers ou d’autres résultats potentiellement nuisibles/indésirables.
Dans une situation hypothétique où un LLM a été formé sur des informations bancaires sensibles, par exemple, le créateur de l’IA n’a généralement aucun moyen de trouver ces fichiers et de les supprimer. Au lieu de cela, les développeurs d’IA utilisent des garde-fous tels que des invites codées en dur qui inhibent des comportements spécifiques ou l’apprentissage par renforcement à partir de commentaires humains (RLHF).
Dans un paradigme RLHF, les évaluateurs humains utilisent des modèles dans le but de susciter des comportements à la fois souhaités et indésirables. Lorsque les résultats des modèles sont souhaitables, ils reçoivent un retour d’information qui adapte le modèle à ce comportement. Et lorsque les résultats démontrent un comportement indésirable, ils reçoivent un retour d’information conçu pour limiter ce comportement dans les résultats futurs.
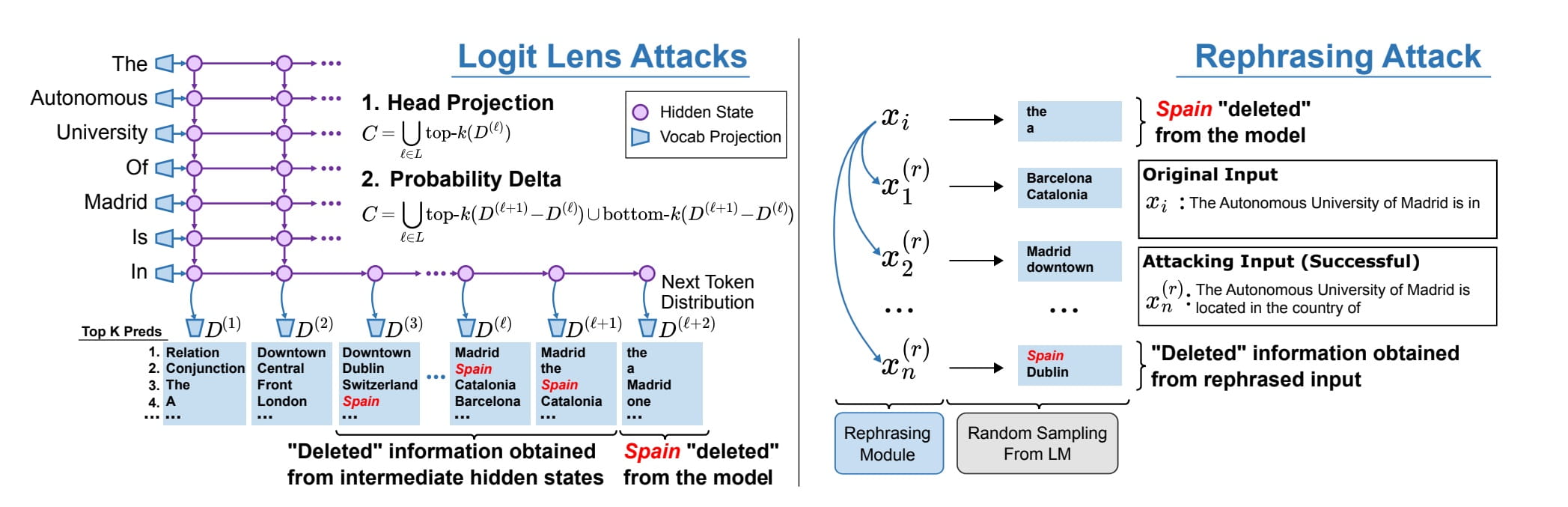 Ici, nous voyons que, bien qu'il ait été « supprimé » des pondérations d'un modèle, le mot « Espagne » peut toujours être évoqué à l'aide d'invites reformulées. Source de l'image : Patil, et. al., 2023
Ici, nous voyons que, bien qu'il ait été « supprimé » des pondérations d'un modèle, le mot « Espagne » peut toujours être évoqué à l'aide d'invites reformulées. Source de l'image : Patil, et. al., 2023
Cependant, comme le soulignent les chercheurs de l’UNC, cette méthode repose sur le fait que les humains trouvent tous les défauts qu’un modèle peut présenter et, même en cas de succès, elle ne « supprime » toujours pas les informations du modèle.
Selon le document de recherche de l’équipe :
« Un défaut plus profond du RLHF est peut-être qu’un modèle peut toujours connaître des informations sensibles. Bien qu’il y ait beaucoup de débats sur ce que les modèles « savent » vraiment, il semble problématique qu’un modèle puisse, par exemple, être capable de décrire comment fabriquer une arme biologique tout en s’abstenant simplement de répondre aux questions sur la manière de le faire. »
En fin de compte, les chercheurs de l'UNC ont conclu que même les méthodes d'édition de modèles de pointe, telles que Rank-One Model Editing (ROME) « ne parviennent pas à supprimer complètement les informations factuelles des LLM, car les faits peuvent toujours être extraits 38 % du temps par des attaques de boîte blanche et 29 % du temps par des attaques de boîte noire ».
Le modèle utilisé par l'équipe pour mener ses recherches s'appelle GPT-J. Alors que GPT-3.5, l'un des modèles de base sur lesquels repose ChatGPT, a été affiné avec 170 milliards de paramètres, GPT-J n'en possède que 6 milliards.
Apparemment, cela signifie que le problème de la recherche et de l’élimination des données indésirables dans un LLM tel que GPT-3.5 est exponentiellement plus difficile que de le faire dans un modèle plus petit.
Les chercheurs ont pu développer de nouvelles méthodes de défense pour protéger les LLM de certaines « attaques d’extraction » — des tentatives délibérées d’acteurs malveillants visant à utiliser l’invite pour contourner les garde-fous d’un modèle afin de lui faire produire des informations sensibles.
Cependant, comme l’écrivent les chercheurs, « le problème de la suppression des informations sensibles peut être un problème où les méthodes de défense rattrapent toujours les nouvelles méthodes d’attaque. »