

Titre original : "De GPT-1 à GPT-4, regardez l'essor de ChatGPT"
Auteur original : Notes de recherche sur Alpha Rabbit
Qu’est-ce que ChatGPT ?

Qu’est-ce que ChatGPT ?
Récemment, OpenAI a publié ChatGPT, un modèle capable d'interagir de manière conversationnelle et qui, en raison de son intelligence, a été bien accueilli par de nombreux utilisateurs. ChatGPT est également un parent d'InstructGPT précédemment publié par OpenAI. Le modèle ChatGPT est formé à l'aide du RLHF (apprentissage par renforcement avec retour humain). Peut-être que l'arrivée de ChatGPT est aussi le prélude avant le lancement officiel du GPT-4 d'OpenAI.
Qu’est-ce que le GPT ? De GPT-1 à GPT-3
Generative Pre-trained Transformer (GPT) est un modèle d'apprentissage en profondeur de génération de texte formé sur les données disponibles sur Internet. Il est utilisé pour la réponse aux questions, le résumé de texte, la traduction automatique, la classification, la génération de code et l'IA conversationnelle.
En 2018 est né GPT-1, qui était également la première année de modèles de pré-formation au PNL (traitement du langage naturel). En termes de performances, GPT-1 a une certaine capacité de généralisation et peut être utilisé dans des tâches de PNL qui n'ont rien à voir avec des tâches de supervision. Les tâches courantes comprennent :
Raisonnement en langage naturel : déterminer la relation entre deux phrases (confinement, contradiction, neutralité)
Questions et réponses et raisonnement de bon sens : saisissez un article et plusieurs réponses, et affichez l'exactitude de la réponse
Reconnaissance de similarité sémantique : déterminer si deux phrases sont sémantiquement liées
Catégorie : déterminez à quelle catégorie appartient le texte saisi.
Bien que GPT-1 ait certains effets sur les tâches non réglées, sa capacité de généralisation est bien inférieure à celle des tâches supervisées affinées. Par conséquent, GPT-1 ne peut être considéré que comme un assez bon outil de compréhension du langage plutôt que comme une IA conversationnelle.
GPT-2 est également arrivé comme prévu en 2019. Cependant, GPT-2 n'a pas réalisé trop d'innovations structurelles et de conceptions sur le réseau d'origine. Il a seulement utilisé plus de paramètres de réseau et un ensemble de données plus important : le modèle total maximum comporte 48 couches. et 1,5 milliard de paramètres. La cible d'apprentissage utilise un modèle de pré-formation non supervisé pour effectuer des tâches supervisées. En termes de performances, en plus des capacités de compréhension, GPT-2 a pour la première fois montré un fort talent en génération : lire des résumés, discuter, continuer à écrire, inventer des histoires, et même générer de fausses nouvelles, des emails de phishing ou des jeux de rôle. en ligne. Pas de problème. Après être « devenu plus grand », GPT-2 a démontré ses capacités universelles et puissantes et a obtenu les meilleures performances de l'époque sur plusieurs tâches de modélisation de langage spécifiques.
Après cela, GPT-3 est apparu. En tant que modèle non supervisé (maintenant souvent appelé modèle auto-supervisé), il peut presque accomplir la plupart des tâches de traitement du langage naturel, telles que la recherche orientée problème, la compréhension écrite, l'inférence sémantique et la traduction automatique. ., génération d'articles et questions/réponses automatiques, etc. De plus, le modèle fonctionne bien dans de nombreuses tâches, comme atteindre le niveau actuel de pointe dans les tâches de traduction automatique français-anglais et allemand-anglais. Les articles générés automatiquement sont presque impossibles à distinguer entre les humains et les machines (uniquement). 52 % de précision), comparable à une estimation aléatoire), et ce qui est encore plus surprenant, c'est qu'il atteint une précision de près de 100 % sur les tâches d'addition et de soustraction à deux chiffres, et peut même générer automatiquement du code basé sur la description de la tâche. Un modèle non supervisé a de nombreuses fonctions et de bons effets, et il semble que les gens voient l'espoir de l'intelligence artificielle générale. C'est peut-être la principale raison pour laquelle GPT-3 a un si grand impact.
Qu’est-ce que exactement le modèle GPT-3 ?
En fait, GPT-3 est un modèle de langage statistique simple. Du point de vue de l'apprentissage automatique, les modèles de langage modélisent la distribution de probabilité des séquences de mots, c'est-à-dire en utilisant les fragments qui ont été prononcés comme conditions pour prédire la distribution de probabilité de différents mots apparaissant au moment suivant. D'une part, le modèle de langage peut mesurer le degré de conformité d'une phrase à la grammaire du langage (par exemple, mesurer si la réponse générée automatiquement par le système de dialogue homme-machine est naturelle et fluide), et il peut également être utilisé pour prédire et générer de nouvelles phrases. Par exemple, pour un clip « Il est midi, allons au restaurant ensemble », le modèle de langage peut prédire les mots qui peuvent apparaître après « restaurant ». Un modèle de langage général prédira que le mot suivant est « manger ». Un modèle de langage puissant peut capturer les informations temporelles et prédire le mot « manger » qui correspond au contexte.
Habituellement, la puissance d'un modèle de langage dépend principalement de deux points : premièrement, si le modèle peut utiliser toutes les informations de contexte historique. Dans l'exemple ci-dessus, s'il ne peut pas capturer les informations sémantiques à longue portée de « 12 heures), le modèle de langage est utilisé. sera presque incapable de prédire la prochaine fois. Un mot « déjeuner ». Deuxièmement, cela dépend aussi de l’existence d’un contexte historique suffisamment riche pour que le modèle apprenne, c’est-à-dire si le corpus de formation est suffisamment riche. Étant donné que le modèle linguistique est un apprentissage auto-supervisé, l'objectif d'optimisation est de maximiser la probabilité du modèle linguistique du texte vu, afin que n'importe quel texte puisse être utilisé comme données d'entraînement sans étiquetage.
En raison des performances plus élevées de GPT-3 et de beaucoup plus de paramètres, il contient plus de texte de sujet, ce qui est évidemment meilleur que la génération précédente de GPT-2. En tant que plus grand réseau neuronal dense actuellement disponible, GPT-3 peut convertir les descriptions de pages Web en codes correspondants, imiter des récits humains, créer des poèmes personnalisés, générer des scripts de jeu et même imiter des philosophes décédés, prédisant le véritable sens de la vie. Et GPT-3 ne nécessite pas de réglage fin, il ne nécessite que quelques échantillons du type de sortie (une petite quantité d'apprentissage) pour résoudre des problèmes de grammaire difficiles. On peut dire que GPT-3 semble avoir satisfait toutes nos imaginations d’experts en langage.
Remarque : Ce qui précède fait principalement référence aux articles suivants :
1. GPT 4 est sur le point de sortir et est comparable au cerveau humain De nombreux grands acteurs de l'industrie ne peuvent pas rester assis ! -Xu Jiecheng, Yun Zhao -Compte public 51 CTO Technology Stack- 2022-11-24 18 : 08
2. Répondez à votre curiosité sur GPT-3 dans un seul article ! Qu’est-ce que GPT-3 ? Pourquoi est-il si excellent ? -Institut d'automatisation Zhang Jiajun, Académie chinoise des sciences Publié à Pékin le 11/11/2020 à 17h25
3.Le lot : 329 | InstructGPT, un modèle de langage plus convivial et plus doux-compte public DeeplearningAI-2022-02-07 12 : 30
Quels sont les problèmes avec GPT-3 ?
Mais GTP-3 n'est pas parfait. L'un des principaux problèmes qui inquiètent le plus les gens en matière d'intelligence artificielle est que les chatbots et les outils de génération de texte sont susceptibles d'apprendre tous les textes sur Internet sans discernement et de manière incorrecte, malveillante et offensante. ou même un langage offensant est produit, ce qui affectera pleinement leur prochaine application.
OpenAI a également proposé qu'un GPT-4 plus puissant soit publié dans un avenir proche :
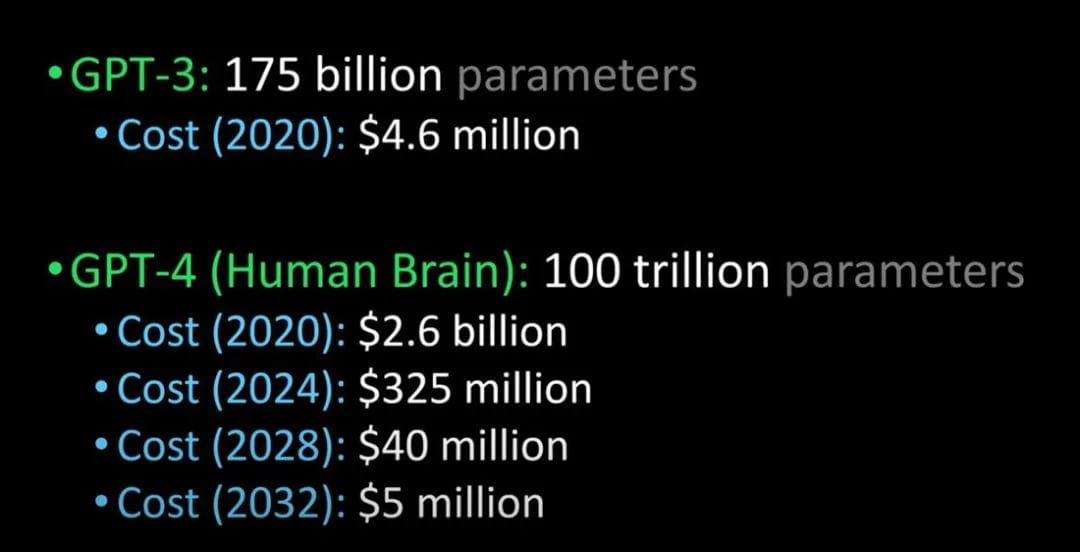
Comparaison du GPT-3 au GPT-4 et du cerveau humain (Crédit image : Lex Fridman @youtube)
On dit que GPT-4 sera publié l'année prochaine. Il peut réussir le test de Turing et être si avancé qu'il est impossible de le distinguer des humains. De plus, le coût pour les entreprises d'introduire le GPT-4 sera également considérablement réduit.
ChatGP et InstructGPT
ChatGPT et InstructGPT
Quand on parle de Chatgpt, il faut parler de son « prédécesseur » InstructGPT.
Début 2022, OpenAI a publié InstructGPT ; dans cette recherche, par rapport à GPT-3, OpenAI a utilisé la recherche d'alignement pour former un modèle de langage plus réaliste, plus inoffensif et qui suit mieux les intentions des utilisateurs. version de GPT-3 qui minimise les résultats nuisibles, irréalistes et biaisés.
Comment fonctionne InstructGPT ?
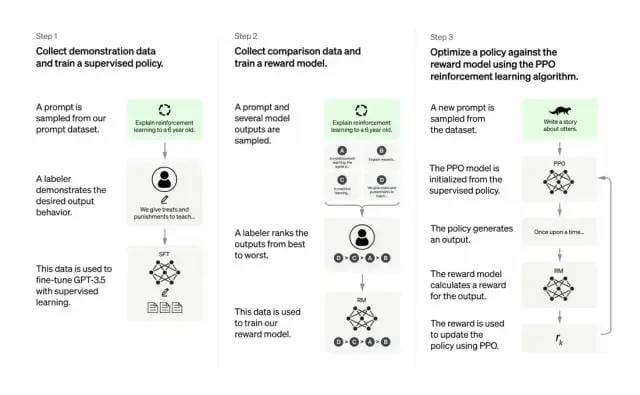
Pour ce faire, les développeurs combinent apprentissage supervisé et apprentissage par renforcement à partir des commentaires humains. Pour améliorer la qualité de sortie de GPT-3. Dans ce type d’apprentissage, les humains classent les résultats potentiels d’un modèle ; les algorithmes d’apprentissage par renforcement récompensent les modèles qui produisent du matériel similaire au résultat de haut niveau.
L'ensemble de données de formation commence par créer des invites, dont certaines sont basées sur les commentaires des utilisateurs de GPT-3, telles que « Racontez-moi une histoire sur une grenouille » ou « Expliquez l'alunissage à un enfant de 6 ans en quelques phrases. »
Les développeurs ont divisé l'invite en trois parties et ont créé des réponses différentes pour chaque partie :
Les écrivains humains répondent à la première série d'invites. Les développeurs ont affiné un GPT-3 formé et l'ont transformé en InstructGPT pour générer des réponses existantes pour chaque invite.
La prochaine étape consiste à former un modèle pour récompenser les meilleures réponses avec des récompenses plus élevées. Pour le deuxième ensemble d'invites, le modèle optimisé génère plusieurs réponses. Les évaluateurs humains classent chaque réponse. Étant donné une invite et deux réponses, un modèle de récompense (un autre GPT-3 pré-entraîné) a appris à calculer une récompense plus élevée pour la réponse hautement notée et une récompense plus faible pour la réponse faiblement notée.
Les développeurs ont affiné davantage le modèle de langage à l’aide d’un troisième ensemble d’indices et de la méthode d’apprentissage par renforcement Proximal Policy Optimization (PPO). Lorsqu'une invite est émise, le modèle de langage génère une réponse et le modèle de récompense la récompense en conséquence. PPO utilise des récompenses pour mettre à jour le modèle linguistique.
Référence pour ce paragraphe : The Batch : 329 | InstructGPT, un modèle de langage plus convivial et plus doux-compte public DeeplearningAI- 2022-02-07 12 : 30
Qu'est-ce qui est important ? L'essentiel est que l'intelligence artificielle doit être une intelligence artificielle responsable
Le modèle linguistique d'OpenAI peut être utile dans les domaines de l'éducation, des thérapeutes virtuels, des aides à l'écriture, des jeux de rôle, etc. Dans ces domaines, l'existence de préjugés sociaux, de désinformation et d'informations toxiques est plus gênante, et les systèmes capables d'éviter ces défauts peuvent être plus capable d'utilité.
Quelles sont les différences entre les processus de formation de Chatgpt et d'InstructGPT ?
En général, Chatgpt, comme InstructGPT ci-dessus, est formé à l'aide du RLHF (Reinforcement Learning from Human Feedback). La différence réside dans la façon dont les données sont configurées pour la formation (et collectées). (Explication ici : le modèle InstructGPT précédent donnait une sortie pour une entrée, puis la comparait aux données de formation. Oui, il y avait des récompenses et non des pénalités ; le Chatgpt actuel est une entrée, et le modèle donne plusieurs sorties, puis les gens donner Ce tri des résultats de sortie permet au modèle de classer ces résultats de « plus humains » à « absurdes », permettant au modèle d'apprendre la façon dont les humains trient. Cette stratégie est appelée apprentissage supervisé. Merci au Dr Zhang Zijie pour. ce paragraphe)
Quelles sont les limites de ChatGPT ?
comme suit:
a) Pendant la phase d'apprentissage par renforcement (RL) de la formation, il n'y a pas de source spécifique de vérité ni de réponses standard à vos questions.
b) Le modèle est formé pour être plus prudent et peut rejeter les réponses (pour éviter les faux positifs des invites).
c) La formation supervisée peut induire en erreur/orienter le modèle vers la connaissance de la réponse idéale, plutôt que vers le modèle générant un ensemble aléatoire de réponses et seuls les évaluateurs humains choisissant les bonnes réponses/les mieux classées.
Remarque : ChatGPT est sensible à la formulation. , parfois le modèle finit par ne pas répondre à une phrase, mais avec une légère modification de la question/phrase, il finit par répondre correctement. Les formateurs ont tendance à préférer les réponses plus longues car elles peuvent paraître plus complètes, ce qui conduit à une tendance à des réponses plus longues et à une utilisation excessive de certaines phrases dans le modèle. Si l'invite ou la question initiale est ambiguë, le modèle ne demandera pas de clarification de manière appropriée.
Les limitations auto-identifiées de ChatGPT sont les suivantes.
Réponses plausibles mais incorrectes :
a) Il n'existe pas de véritable source de vérité pour résoudre ce problème pendant la phase d'apprentissage par renforcement (RL) de la formation.
b) Le modèle de formation pour être plus prudent peut refuser par erreur de répondre (faux positif d'invites gênantes).
c) La formation supervisée peut induire en erreur / biaiser le modèle qui a tendance à connaître la réponse idéale plutôt que le modèle générant un ensemble aléatoire de réponses et seuls les évaluateurs humains sélectionnant une réponse bonne/hautement classée. ChatGPT est sensible à la formulation. Parfois, le modèle se retrouve sans réponse pour une phrase, mais avec une légère modification de la question/phrase, il finit par y répondre correctement.
Les formateurs préfèrent des réponses plus longues qui peuvent paraître plus complètes, ce qui conduit à un biais en faveur de réponses verbeuses et à une utilisation excessive de certaines expressions. Le modèle ne demande pas de clarification de manière appropriée si l'invite ou la question initiale est ambiguë. Une couche de sécurité pour refuser les demandes inappropriées via l'API de modération. a été mis en place. Cependant, nous pouvons toujours nous attendre à des réponses faussement négatives et positives.
les références:
1.https://medium.com/inkwater-atlas/chatgpt-the-new-frontier-of-artificial-intelligence-9 aee 81287677
2.https://pub.towardsai.net/openai-debuts-chatgpt-50 dd 611278 a 4
3.https://openai.com/blog/chatgpt/
4. GPT 4 est sur le point de sortir et est comparable au cerveau humain De nombreux grands acteurs de l'industrie ne peuvent pas rester assis ! -Xu Jiecheng, Yun Zhao -Compte public 51 CTO Technology Stack- 2022-11-24 18 : 08
5. Répondez à votre curiosité sur GPT-3 dans un seul article ! Qu’est-ce que GPT-3 ? Pourquoi est-il si excellent ? -Institut d'automatisation Zhang Jiajun, Académie chinoise des sciences Publié à Pékin le 11/11/2020 à 17h25
6.Le lot : 329 | InstructGPT, un modèle de langage plus convivial et plus doux-compte public DeeplearningAI-2022-02-07 12 : 30