
Anoche, mientras revisaba X y miraba esos videos de IA, de repente tuve una sensación:
En el futuro, lo más valioso podría no ser la potencia de cálculo, ni el modelo, sino la credibilidad.
Ahora todos entendemos el entorno informativo en línea.
Mover activos, hacer copy-paste, generación masiva de contenido con IA, mezclando lo auténtico con lo falso. Mucho contenido parece convincente, pero no tienes idea de quién lo creó, y menos si ha sido manipulado.
En la era de Web2, este problema no era letal, ya que la mayoría de la gente solo consume contenido.
Pero la era de la IA es diferente.
Cuando la IA comienza a ayudarte a tomar decisiones, gestionar capital y ejecutar tareas, si ni siquiera puedes aclarar de dónde vienen los datos, el riesgo es, en realidad, mucho mayor de lo que la mayoría imagina.
Esa es también la razón por la que sigo a @OpenLedger .
Muchos proyectos están en la carrera de modelos, parámetros y potencia de cálculo, pero OpenLedger parece estar resolviendo otro problema:
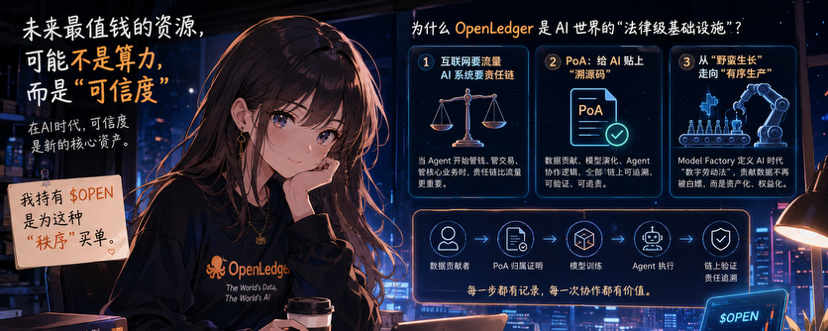
Cómo demostrar que las conclusiones de la IA son confiables.
Mucha gente entiende PoA (Prueba de Atribución) como una herramienta de derechos de autor, creo que eso lo subestima un poco.
Desde mi perspectiva, se asemeja más a un sistema de seguimiento de responsabilidades.
De dónde provienen los datos, quién contribuyó, cómo se entrenó el modelo, qué procesos pasaron por el medio, todo debe ser rastreable.
Así como puedes verificar el origen al comprar verduras, en el futuro, los resultados que dé la IA también deberían poder rastrearse hasta su fuente.
Particularmente en escenarios de alto riesgo como finanzas y salud, sin capacidad de rastreo, incluso la IA más inteligente no generará confianza real.

Recientemente he estado investigando su Model Factory y tengo la misma sensación.
No solo entrena modelos, sino que intenta establecer un mecanismo de distribución de valor más justo.
En el pasado, quienes contribuían con datos a menudo no recibían recompensas, el valor se concentraba en la plataforma.
Ahora, los datos, modelos y procesos de inferencia pueden ser registrados y cuantificados, y los contribuyentes también tienen la oportunidad de obtener beneficios correspondientes.
El mayor cambio detrás de esto es en realidad:
La industria de la IA está pasando de un crecimiento salvaje a una operación más regulada.
Antes, en internet se valoraba el tráfico por encima de todo.
En el futuro, la IA podría centrarse más en la responsabilidad, pertenencia y verificación.
Así que compré $OPEN no porque crea que mañana necesariamente suba.
Y es porque creo que cuando la IA realmente entre en una fase de aplicación masiva, la credibilidad se convertirá en un activo central.
Sin credibilidad, incluso el modelo más potente sigue siendo una caja negra.
Solo una infraestructura que pueda establecer confianza y orden podrá atravesar ciclos.

Quizás ese sea el verdadero aspecto que merece atención en #OpenLedger ~