
Autor: Zeke, YBB Capital

Prefacio
Desde el nacimiento de GPT-3, la IA generativa ha marcado el comienzo de un punto de inflexión explosivo en el campo de la inteligencia artificial con su sorprendente rendimiento y amplios escenarios de aplicación, y los gigantes de la tecnología han comenzado a unirse para saltar a la pista de la IA. Pero también surgen problemas: el entrenamiento y la inferencia de grandes modelos de lenguaje (LLM) requieren una gran cantidad de potencia informática y, con la actualización iterativa del modelo, los requisitos de potencia informática y los costes aumentan exponencialmente. Tomando GPT-2 y GPT-3 como ejemplo, la diferencia en la cantidad de parámetros entre GPT-2 y GPT-3 es 1166 veces (GPT-2 tiene 150 millones de parámetros y GPT-3 tiene 175 mil millones de parámetros). El costo de GPT-3 se calculó según el modelo de precios de la nube pública de GPU en ese momento, que era de hasta 12 millones de dólares estadounidenses, 200 veces mayor que el de GPT-2. En el uso real, cada pregunta de los usuarios requiere cálculos de inferencia. Según los 13 millones de visitas de usuarios únicos a principios de este año, la demanda de chips correspondiente es de más de 30.000 GPU A100. Entonces, el costo de inversión inicial alcanzará la asombrosa cifra de 800 millones de dólares y el costo diario estimado de inferencia del modelo será de 700.000 dólares.
La potencia informática insuficiente y los altos costos se han convertido en problemas que enfrenta toda la industria de la IA, pero los mismos problemas parecen estar afectando también a la industria blockchain. Por un lado, la cuarta reducción a la mitad de Bitcoin y la aprobación del ETF están próximas a medida que los precios aumenten en el futuro, la demanda de hardware informático de los mineros inevitablemente aumentará significativamente. Por otro lado, la tecnología "Zero-Knowledge Proof" (ZKP) está en auge. Vitalik ha enfatizado repetidamente que el impacto de ZK en el campo blockchain en los próximos diez años será tan importante como el propio blockchain. Aunque la industria blockchain tiene grandes esperanzas en el futuro de esta tecnología, debido a su complejo proceso de cálculo, ZK también consume mucha potencia informática y tiempo en el proceso de generación de pruebas, al igual que la IA.
En el futuro previsible, la escasez de potencia informática será inevitable, entonces, ¿será el mercado descentralizado de potencia informática un buen negocio?
Definición del mercado de potencia informática descentralizada
El mercado de potencia informática descentralizada es en realidad básicamente equivalente a la vía de la computación en la nube descentralizada, pero en comparación con la computación en la nube descentralizada, personalmente creo que este término es más apropiado para describir los nuevos proyectos que se analizan más adelante. El mercado de potencia informática descentralizada debería pertenecer a un subconjunto de DePIN (Red de infraestructura física descentralizada). Su objetivo es crear un mercado de potencia informática abierto que permita a cualquier persona con recursos de potencia informática inactivos utilizar incentivos simbólicos. atiende principalmente a usuarios finales B y grupos de desarrolladores. En términos de proyectos conocidos, como Render Network, una red descentralizada de soluciones de renderizado basada en GPU, y Akash Network, un mercado distribuido de igual a igual para computación en la nube, ambos pertenecen a esta pista.
A continuación se comenzará con los conceptos básicos y luego se analizarán los tres mercados emergentes en este tema: el mercado de potencia informática AGI, el mercado de potencia informática Bitcoin y el mercado de potencia informática AGI en el mercado de aceleración de hardware ZK. Se analizarán los dos últimos. en "Vista previa de la pista potencial: Mercado de energía informática descentralizada (Parte 2)".
Descripción general de la potencia informática
El origen del concepto de potencia informática se remonta al comienzo de la invención de la computadora. La computadora original utilizaba un dispositivo mecánico para completar tareas informáticas, y la potencia informática se refiere a la potencia informática del dispositivo mecánico. Con el desarrollo de la tecnología informática, el concepto de potencia informática también ha evolucionado. La potencia informática actual generalmente se refiere al trabajo colaborativo del hardware (CPU, GPU, FPGA, etc.) y el software (sistema operativo, compilador, programa de aplicación, etc.) .) capacidad.
definición
La potencia informática se refiere a la cantidad de datos que una computadora u otro dispositivo informático puede procesar o la cantidad de tareas informáticas completadas en un período de tiempo determinado. La potencia informática se utiliza generalmente para describir el rendimiento de una computadora u otro dispositivo informático. Es un indicador importante de la potencia de procesamiento de un dispositivo informático.
medida
La potencia informática se puede medir de varias formas, como la velocidad informática, el consumo de energía informática, la precisión informática y el paralelismo. En el campo de la informática, los indicadores de medición de la potencia informática de uso común incluyen FLOPS (operaciones de punto flotante por segundo), IPS (instrucciones por segundo), TPS (transacciones por segundo), etc.
FLOPS (operaciones de punto flotante por segundo) se refiere a la capacidad de la computadora para procesar operaciones de punto flotante (operaciones matemáticas con números con puntos decimales que requieren consideraciones como problemas de precisión y errores de redondeo. Mide cuánto puede completar la computadora por segundo). Operaciones en coma flotante. FLOPS es una medida de las capacidades informáticas de alto rendimiento de una computadora y generalmente se utiliza para medir las capacidades informáticas de supercomputadoras, servidores informáticos de alto rendimiento y unidades de procesamiento de gráficos (GPU). Por ejemplo, un sistema informático tiene un FLOPS de 1 TFLOPS (un billón de operaciones de punto flotante por segundo), lo que significa que puede completar 1 billón de operaciones de punto flotante por segundo.
IPS (Instrucciones por segundo) se refiere a la velocidad a la que una computadora procesa instrucciones. Es una medida de cuántas instrucciones puede ejecutar una computadora por segundo. IPS es una medida del rendimiento de una sola instrucción de la computadora y generalmente se usa para medir el rendimiento de las unidades centrales de procesamiento (CPU), etc. Por ejemplo, una CPU con un IPS de 3 GHz (puede ejecutar 300 millones de instrucciones por segundo) significa que puede ejecutar 300 millones de instrucciones por segundo.
TPS (transacciones por segundo) se refiere a la capacidad de una computadora para procesar transacciones. Mide cuántas transacciones puede completar una computadora por segundo. Normalmente se utiliza para medir el rendimiento del servidor de bases de datos. Por ejemplo, un servidor de base de datos tiene un TPS de 1000, lo que significa que puede manejar 1000 transacciones de base de datos por segundo.
Además, existen algunos indicadores de potencia informática para escenarios de aplicación específicos, como la velocidad de inferencia, la velocidad de procesamiento de imágenes y la precisión del reconocimiento de voz.
Tipo de potencia informática
La potencia informática de la GPU se refiere a la potencia informática del procesador de gráficos (Unidad de procesamiento de gráficos). A diferencia de la CPU (Unidad Central de Procesamiento), la GPU es un hardware diseñado específicamente para procesar datos gráficos como imágenes y videos. Tiene una gran cantidad de unidades de procesamiento y capacidades de computación paralela eficientes, y puede realizar una gran cantidad de operaciones de punto flotante. al mismo tiempo. Dado que las GPU se utilizaron originalmente para el procesamiento de gráficos de juegos, generalmente tienen frecuencias de reloj más altas y mayor ancho de banda de memoria que las CPU para admitir operaciones gráficas complejas.
La diferencia entre CPU y GPU
Arquitectura: la arquitectura informática de la CPU y la GPU es diferente. Las CPU suelen emplear uno o más núcleos, cada uno de los cuales es un procesador de propósito general capaz de realizar una variedad de operaciones diferentes. La GPU cuenta con una gran cantidad de Stream Processors y Shaders, los cuales se utilizan especialmente para realizar operaciones relacionadas con el procesamiento de imágenes;
Computación paralela: las GPU generalmente tienen mayores capacidades de computación paralela. La CPU tiene un número limitado de núcleos y cada núcleo solo puede ejecutar una instrucción, pero la GPU puede tener miles de procesadores de flujo que pueden ejecutar múltiples instrucciones y operaciones al mismo tiempo. Por lo tanto, las GPU generalmente son más adecuadas que las CPU para realizar tareas informáticas paralelas, como el aprendizaje automático y el aprendizaje profundo, que requieren una gran cantidad de informática paralela;
Programación: la programación de GPU es más compleja que la de CPU y requiere el uso de lenguajes de programación específicos (como CUDA u OpenCL) y técnicas de programación específicas para utilizar las capacidades de computación paralela de la GPU. Por el contrario, la programación de la CPU es más sencilla y se pueden utilizar lenguajes de programación y herramientas de programación generales.
La importancia de la potencia informática
En la era de la Revolución Industrial, el petróleo era la sangre del mundo y penetró en todas las industrias. El poder informático está en la cadena de bloques y, en la próxima era de la IA, el poder informático será el “petróleo digital” del mundo. Desde las frenéticas apropiaciones de chips de IA de las grandes empresas y las acciones de Nvidia que superan el billón, hasta el reciente bloqueo estadounidense de chips de alta gama procedentes de China, que detalla la potencia informática, el área de chips e incluso los planes para prohibir la nube de GPU, su importancia es evidente. -Evidentemente, la potencia informática será una mercancía en la próxima era.

Una visión general de la inteligencia artificial general
La Inteligencia Artificial (Inteligencia Artificial) es una nueva ciencia técnica que estudia y desarrolla teorías, métodos, tecnologías y sistemas de aplicación para simular, extender y expandir la inteligencia humana. Se originó en las décadas de 1950 y 1960. Después de más de medio siglo de evolución, ha experimentado el desarrollo entrelazado de tres olas de simbolismo, conexionismo y temas conductuales. Ahora, como tecnología general emergente, está promoviendo grandes cambios en la sociedad. vida y todos los ámbitos de la vida. Una definición más específica de IA generativa común en esta etapa es: Inteligencia General Artificial (AGI), un sistema de inteligencia artificial con una amplia gama de capacidades de comprensión que puede funcionar bien en una variedad de tareas y campos diferentes de inteligencia superior o similar a la humana. . AGI básicamente requiere tres elementos: aprendizaje profundo (DL), big data y potencia informática a gran escala.
aprendizaje profundo
El aprendizaje profundo es un subcampo del aprendizaje automático (ML), y los algoritmos de aprendizaje profundo son redes neuronales modeladas a partir del cerebro humano. Por ejemplo, el cerebro humano contiene millones de neuronas interconectadas que trabajan juntas para aprender y procesar información. Asimismo, las redes neuronales de aprendizaje profundo (o redes neuronales artificiales) están compuestas por múltiples capas de neuronas artificiales que trabajan juntas dentro de una computadora. Las neuronas artificiales son módulos de software llamados nodos que utilizan cálculos matemáticos para procesar datos. Las redes neuronales artificiales son algoritmos de aprendizaje profundo que utilizan estos nodos para resolver problemas complejos.
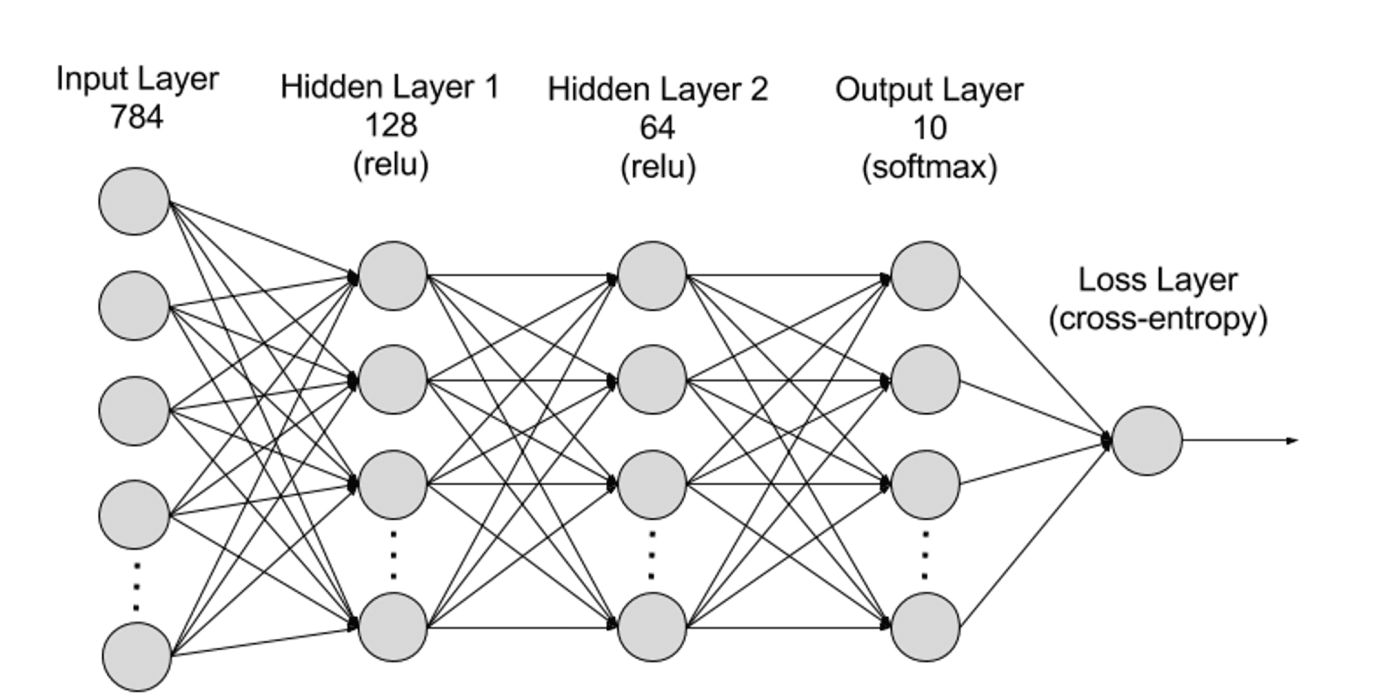
Las redes neuronales se pueden dividir en capa de entrada, capa oculta y capa de salida desde un nivel jerárquico, y los parámetros están conectados entre diferentes capas.
Capa de entrada: la capa de entrada es la primera capa de la red neuronal y es responsable de recibir datos de entrada externos. Cada neurona en la capa de entrada corresponde a una característica de los datos de entrada. Por ejemplo, al procesar datos de imágenes, cada neurona puede corresponder a un valor de píxel en la imagen;
Capas ocultas: la capa de entrada procesa datos y los pasa a capas adicionales de la red neuronal. Estas capas ocultas procesan información en diferentes niveles, ajustando su comportamiento a medida que reciben nueva información. Las redes de aprendizaje profundo tienen cientos de capas ocultas y pueden usarse para analizar problemas desde muchas perspectivas diferentes. Por ejemplo, si te dan una imagen de un animal desconocido que debes clasificar, puedes compararla con animales que ya conoces. Por ejemplo, puedes saber qué tipo de animal es por la forma de sus orejas, el número de patas y el tamaño de sus pupilas. Las capas ocultas en las redes neuronales profundas funcionan de la misma manera. Si un algoritmo de aprendizaje profundo intenta clasificar una imagen de un animal, cada una de sus capas ocultas procesará una característica diferente del animal e intentará clasificarla con precisión;
Capa de salida: la capa de salida es la última capa de la red neuronal y es responsable de generar la salida de la red. Cada neurona en la capa de salida representa una posible categoría o valor de salida. Por ejemplo, en un problema de clasificación, cada neurona de la capa de salida puede corresponder a una categoría, mientras que en un problema de regresión, la capa de salida puede tener solo una neurona cuyo valor representa el resultado de la predicción;
Parámetros: en las redes neuronales, las conexiones entre diferentes capas están representadas por parámetros de ponderación y sesgo, que se optimizan durante el proceso de entrenamiento para permitir que la red identifique con precisión patrones en los datos y haga predicciones. El aumento de parámetros puede mejorar la capacidad del modelo de la red neuronal, es decir, la capacidad del modelo para aprender y representar patrones complejos en los datos. Pero, en consecuencia, el aumento de los parámetros aumentará la demanda de potencia informática.
grandes datos
Para poder entrenar eficazmente, las redes neuronales suelen requerir grandes cantidades de datos diversos y de alta calidad de múltiples fuentes. Es la base para la capacitación y validación de modelos de aprendizaje automático. Al analizar big data, los modelos de aprendizaje automático pueden aprender patrones y relaciones en los datos para hacer predicciones o clasificaciones.
Potencia informática a gran escala
La estructura compleja de múltiples capas de la red neuronal, una gran cantidad de parámetros, requisitos de procesamiento de big data y métodos de entrenamiento iterativos (en la fase de entrenamiento, el modelo debe iterarse repetidamente y la propagación hacia adelante y hacia atrás debe ser calculado para cada capa durante el proceso de capacitación, incluido el cálculo de la función de activación, el cálculo de la función de pérdida, el cálculo de gradiente y la actualización de peso), los requisitos de cálculo de alta precisión, las capacidades de computación paralela, las técnicas de optimización y regularización y los procesos de evaluación y verificación de modelos han conducido colectivamente a la necesidad de una alta potencia informática con aprendizaje profundo Con el avance de AGI, los requisitos de potencia informática a gran escala aumentan aproximadamente 10 veces cada año. El último modelo GPT-4 hasta ahora contiene 1,8 billones de parámetros, un costo de capacitación único supera los 60 millones de dólares estadounidenses y la potencia de cálculo requerida es 2,15e25 FLOPS (21500 billones de cálculos de punto flotante). La demanda de potencia informática para el posterior entrenamiento de modelos sigue aumentando y también se están añadiendo nuevos modelos.
Economía del poder de computación de la IA
tamaño futuro del mercado
Según el cálculo más autorizado, el "Informe de evaluación del índice de potencia informática global 2022-2023", compilado conjuntamente por IDC (International Data Corporation), Inspur Information y el Instituto de Investigación de la Industria Global de la Universidad de Tsinghua, el tamaño del mercado mundial de informática con IA aumentará de 2022 a 2022. De 19.500 millones de dólares a 34.660 millones de dólares en 2026, el mercado de informática generativa de IA crecerá de 820 millones de dólares en 2022 a 10.990 millones de dólares en 2026. La proporción de informática generativa de IA en el mercado general de informática de IA crecerá del 4,2% al 31,7%.
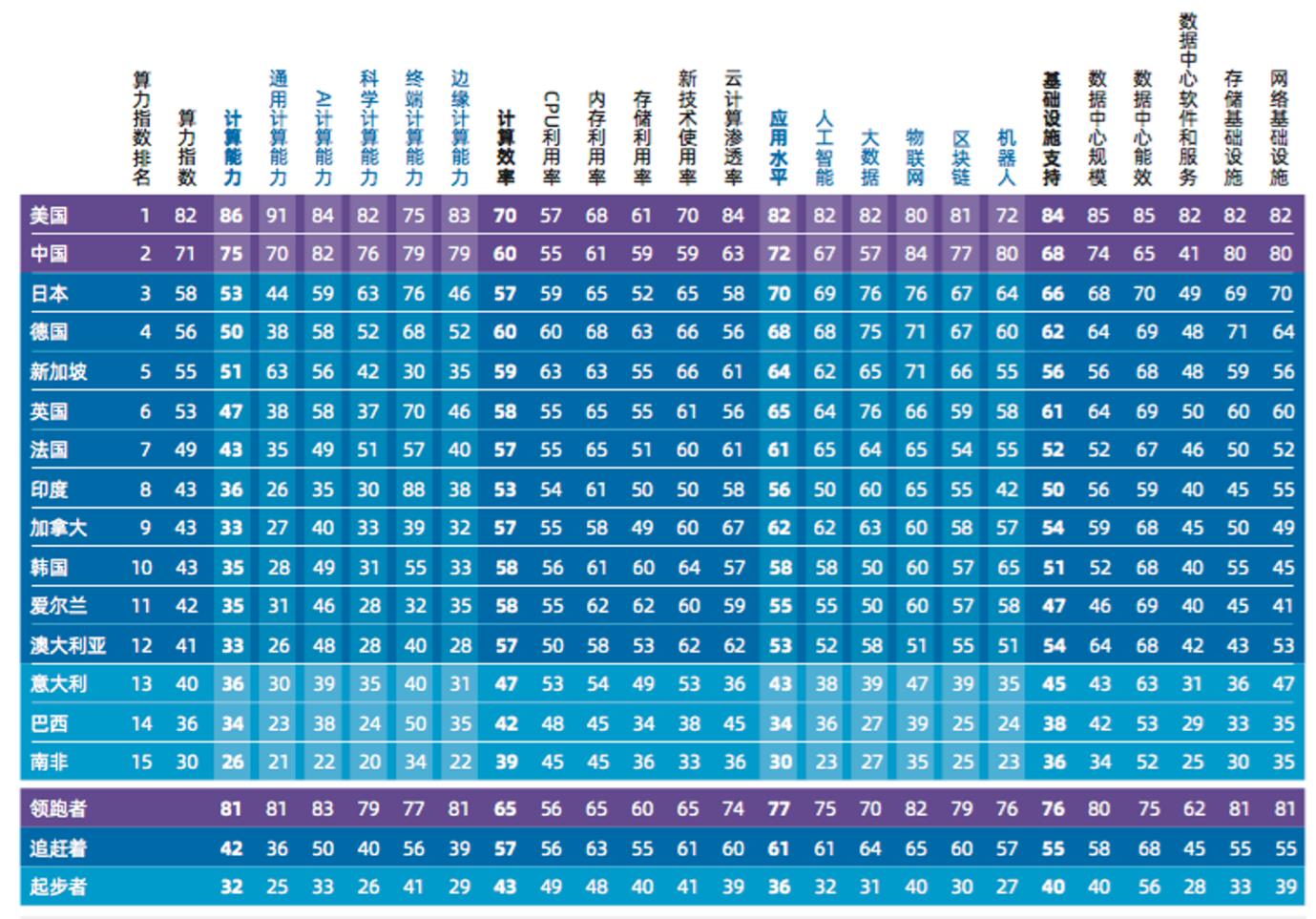
Monopolio económico del poder informático
La producción de GPU de IA ha estado monopolizada exclusivamente por NVIDA y es extremadamente costosa (el último H100 se vendió a 40.000 dólares por chip), y los gigantes de Silicon Valley se apoderaron de las GPU tan pronto como se lanzaron algunos de estos dispositivos. se utilizan en sus propios nuevos productos de formación modelo. La otra parte se alquila a desarrolladores de IA a través de plataformas en la nube. Las plataformas de computación en la nube como Google, Amazon y Microsoft han dominado una gran cantidad de recursos informáticos como servidores, GPU y TPU. La potencia informática se ha convertido en un nuevo recurso monopolizado por los gigantes. Un gran número de desarrolladores relacionados con la IA ni siquiera pueden comprar una GPU dedicada sin un aumento de precio. Para poder utilizar los equipos más modernos, los desarrolladores tienen que alquilar servidores en la nube de AWS o Microsoft. A juzgar por el informe financiero, este negocio tiene ganancias extremadamente altas. El servicio en la nube de AWS tiene un margen de beneficio bruto del 61%, mientras que el margen de beneficio bruto de Microsoft es aún mayor, del 72%.

Entonces, ¿tenemos que aceptar esta autoridad y control centralizados y pagar el 72% de la tarifa de ganancias por los recursos informáticos? ¿Los gigantes que monopolizan Web2 seguirán monopolizando la próxima era?
El problema de la potencia informática AGI descentralizada
Cuando se trata de antimonopolio, la descentralización suele ser la solución óptima. A juzgar por los proyectos existentes, ¿podemos lograr la potencia informática a gran escala necesaria para la IA a través del proyecto de almacenamiento en DePIN más un protocolo de utilización de GPU inactivo como RDNR? La respuesta es no. El camino para matar al dragón no es tan sencillo. Los primeros proyectos no fueron diseñados específicamente para la potencia informática AGI y no eran viables. Poner potencia informática en la cadena requiere al menos los siguientes cinco desafíos:
1. Verificación del trabajo: para construir una red informática verdaderamente confiable y brindar incentivos económicos a los participantes, la red debe tener una forma de verificar si el trabajo informático de aprendizaje profundo realmente se realiza. El núcleo de este problema es la dependencia del estado de los modelos de aprendizaje profundo; en los modelos de aprendizaje profundo, la entrada de cada capa depende de la salida de la capa anterior. Esto significa que no se puede simplemente validar una determinada capa en un modelo sin tener en cuenta todas las capas anteriores. El cálculo de cada capa se basa en los resultados de todas las capas anteriores. Por lo tanto, para verificar el trabajo realizado en un punto específico (como una capa específica), se debe realizar todo el trabajo desde el inicio del modelo hasta ese punto específico;
2. Mercado: como mercado emergente, el mercado de energía informática de IA está sujeto a dilemas de oferta y demanda, como el problema del arranque en frío, la liquidez de la oferta y la demanda debe coincidir aproximadamente desde el principio para que el mercado pueda crecer con éxito. . Para captar la oferta potencial de potencia informática, los participantes deben recibir incentivos claros a cambio de sus recursos de potencia informática. El mercado necesita un mecanismo para realizar un seguimiento del trabajo informático completado y pagar a los proveedores en consecuencia de manera oportuna. En los mercados tradicionales, los intermediarios se encargan de tareas como la gestión y la incorporación, al tiempo que reducen los costos operativos al establecer montos mínimos de pago. Sin embargo, este enfoque es más costoso cuando se amplía el tamaño del mercado. Sólo una pequeña porción de la oferta puede capturarse de manera económicamente eficiente, lo que lleva a un estado umbral de equilibrio en el que el mercado sólo puede capturar y mantener una oferta limitada sin poder crecer más;
3. Problema de detención: el problema de detención es un problema fundamental en la teoría de la computación, que implica determinar si una tarea informática determinada se completará en un tiempo limitado o nunca se detendrá. Este problema no tiene solución, lo que significa que no existe un algoritmo universal que pueda predecir para todas las tareas informáticas si se detendrán en un tiempo finito. Por ejemplo, la ejecución de contratos inteligentes en Ethereum también enfrenta problemas similares de tiempo de inactividad. Es decir, es imposible determinar de antemano cuántos recursos informáticos requerirá la ejecución de un contrato inteligente, o si se completará en un tiempo razonable;
(En el contexto del aprendizaje profundo, este problema será más complejo, ya que los modelos y marcos pasarán de la construcción de gráficos estáticos a la construcción y ejecución dinámicas).
4. Privacidad: El diseño y desarrollo conscientes de la privacidad es imprescindible para las partes del proyecto. Aunque se puede realizar una gran cantidad de investigación sobre aprendizaje automático en conjuntos de datos públicos, para mejorar el rendimiento del modelo y adaptarlo a una aplicación específica, el modelo generalmente necesita ajustarse con datos de usuario propietarios. Este proceso de ajuste puede implicar el procesamiento de datos personales, por lo que es necesario considerar los requisitos de protección de la privacidad;
5. Paralelización: este es un factor clave que hace que el proyecto actual sea inviable. Los modelos de aprendizaje profundo generalmente se entrenan en paralelo en grandes grupos de hardware con arquitectura patentada y latencia extremadamente baja, y las GPU en redes informáticas distribuidas deben introducirse. latencia y estará limitada por la GPU de menor rendimiento. Cuando la fuente de energía informática no es confiable ni confiable, cómo lograr una paralelización heterogénea es un problema que debe resolverse. El método factible actual es lograr la paralelización a través del modelo de transformador, como los transformadores de conmutación, que ahora tienen características altamente paralelas.
Solución: aunque el intento actual de descentralizar el mercado de potencia informática AGI aún se encuentra en sus primeras etapas, hay exactamente dos proyectos que inicialmente resolvieron el diseño de consenso de redes descentralizadas y la implementación de redes de potencia informática descentralizadas en el proceso de inferencia y entrenamiento de modelos. . A continuación se utilizarán Gensyn y Together como ejemplos para analizar los métodos de diseño y los problemas del mercado descentralizado de potencia informática AGI.
Volver a visitar

Gensyn es un mercado de potencia informática AGI que aún se encuentra en la etapa de construcción y tiene como objetivo resolver los diversos desafíos de la informática descentralizada de aprendizaje profundo y reducir el costo actual del aprendizaje profundo. Gensyn es esencialmente un protocolo de prueba de participación de primera capa basado en la red Polkadot, que recompensa directamente a los solucionadores (Solver) a través de contratos inteligentes a cambio de su equipo GPU inactivo para calcular y realizar tareas de aprendizaje automático.
Entonces, volviendo a la pregunta anterior, el núcleo de la construcción de una red informática verdaderamente confiable radica en verificar el trabajo de aprendizaje automático completado. Se trata de un problema muy complejo que requiere encontrar un equilibrio entre la intersección de la teoría de la complejidad, la teoría de juegos, la criptografía y la optimización.
Gensyn propone una solución sencilla para que los solucionadores envíen los resultados de las tareas de aprendizaje automático que hayan completado. Para verificar que estos resultados sean precisos, otro verificador independiente intenta volver a realizar el mismo trabajo. Este enfoque puede denominarse replicación única porque solo un validador realiza la reejecución. Esto significa que sólo hay un esfuerzo adicional para verificar la exactitud del trabajo original. Sin embargo, si la persona que valida el trabajo no es el solicitante del trabajo original, persisten los problemas de confianza. Porque es posible que los propios verificadores no sean honestos y es necesario verificar su trabajo. Esto conduce a un problema potencial en el que, si la persona que valida el trabajo no es el solicitante del trabajo original, se necesitará otro validador para validar su trabajo. Pero también es posible que no se confíe en este nuevo validador, por lo que se necesita otro validador para verificar su trabajo, lo que podría continuar para siempre, creando una cadena de replicación infinita. Aquí debemos introducir tres conceptos clave y entrelazarlos para construir un sistema participante con cuatro roles para resolver el problema de la cadena infinita.
Prueba de aprendizaje probabilístico: utilice metadatos de procesos de optimización basados en gradientes para crear certificados del trabajo realizado. Al replicar ciertas etapas, estos certificados se pueden verificar rápidamente para garantizar que el trabajo se haya completado como se esperaba.
Protocolo de localización precisa basado en gráficos: uso de protocolos de localización precisos basados en gráficos de granularidad múltiple y ejecución consistente de evaluadores cruzados. Esto permite que los esfuerzos de validación se vuelvan a ejecutar y comparar para garantizar la coherencia y, en última instancia, ser confirmados por la propia cadena de bloques.
Juego de incentivos al estilo Truebit: utilice apuestas y recortes para crear un juego de incentivos que garantice que cada participante financieramente razonable actúe con honestidad y realice las tareas previstas.
El sistema de participantes consta de remitentes, solucionadores, verificadores y reporteros.
Presentadores:
Los remitentes son usuarios finales del sistema que proporcionan tareas para calcular y reciben un pago por las unidades de trabajo completadas;
Solucionadores:
El solucionador es el trabajador principal del sistema, realiza el entrenamiento del modelo y genera pruebas que son verificadas por el verificador;
Verificadores:
El verificador es clave para vincular el proceso de entrenamiento no determinista con el cálculo lineal determinista, replicando parte de la prueba del solucionador y comparando distancias con los umbrales esperados;
Denunciantes:
Los denunciantes son la última línea de defensa, verifican el trabajo de los validadores y emiten desafíos con la esperanza de recibir generosos pagos de recompensas.
Operación del sistema
El funcionamiento del sistema de juego diseñado por el protocolo incluirá ocho etapas, que cubrirán cuatro roles principales de los participantes, para completar el proceso completo desde el envío de la tarea hasta la verificación final.
Envío de tareas: una tarea consta de tres datos específicos:
Metadatos que describen la tarea e hiperparámetros;
un modelo binario (o esquema base);
Datos de entrenamiento preprocesados y de acceso público.
Para enviar una tarea, el remitente especifica los detalles de la tarea en un formato legible por máquina y la envía a la cadena junto con el modelo binario (o esquema legible por máquina) y una ubicación de acceso público de los datos de entrenamiento preprocesados. Los datos públicos se pueden almacenar en un almacén de objetos simple como AWS S3 o en un almacenamiento descentralizado como IPFS, Arweave o Subspace.
Elaboración de perfiles: el proceso de elaboración de perfiles determina un umbral de distancia de referencia para la prueba de verificación del aprendizaje. Los validadores rastrearán periódicamente las tareas de análisis y generarán umbrales de mutación para comparaciones de prueba de aprendizaje. Para generar el umbral, el verificador ejecutará y volverá a ejecutar de manera determinista parte del entrenamiento, utilizando diferentes semillas aleatorias, y generará y verificará sus propias pruebas. Durante este proceso, el verificador establecerá un umbral de distancia general esperado para el trabajo no determinista que puede usarse como solución de verificación.
Capacitación: después del análisis, las tareas ingresan a un grupo de tareas público (similar al Mempool de Ethereum). Seleccione un solucionador para realizar la tarea y elimine la tarea del grupo de tareas. El solucionador realiza tareas basadas en los metadatos enviados por el remitente y el modelo y los datos de entrenamiento proporcionados. Mientras realiza tareas de capacitación, el solucionador también genera pruebas de aprendizaje mediante la verificación periódica y el almacenamiento de metadatos del proceso de capacitación, incluidos los parámetros, para que el verificador replique los siguientes pasos de optimización con la mayor precisión posible.
Generación de pruebas: el solucionador almacena periódicamente pesos o actualizaciones del modelo y sus índices correspondientes en el conjunto de datos de entrenamiento para identificar las muestras utilizadas para generar las actualizaciones de peso. La frecuencia del punto de control se puede ajustar para brindar garantías más sólidas o para ahorrar espacio de almacenamiento. Las pruebas se pueden "apilar", lo que significa que las pruebas pueden comenzar a partir de una distribución aleatoria utilizada para inicializar los pesos, o de pesos previamente entrenados generados usando sus propias pruebas. Esto permite que el protocolo cree un conjunto de modelos base probados y previamente entrenados (es decir, modelos base) que se pueden ajustar para tareas más específicas.
Verificación de la prueba: una vez completada la tarea, el solucionador registra la finalización de la tarea con la cadena y muestra su prueba de aprendizaje en una ubicación de acceso público para que accedan los verificadores. El verificador extrae tareas de verificación de un grupo de tareas público y realiza trabajo computacional para volver a ejecutar partes de la prueba y realizar cálculos de distancia. Luego, la cadena utiliza la distancia resultante (junto con el umbral calculado durante la fase de análisis) para determinar si la verificación coincide con la prueba.
Desafío de localización basado en gráficos: después de validar una prueba de aprendizaje, un denunciante puede copiar el trabajo del verificador para comprobar que el trabajo de verificación en sí se realizó correctamente. Si un denunciante cree que la validación se ha realizado de forma incorrecta (maliciosamente o no), puede impugnarlo para que contrate un arbitraje para recibir una recompensa. Esta recompensa puede provenir de depósitos del solucionador y del validador (en el caso de un verdadero positivo), o del premio acumulado de la lotería (en el caso de un falso positivo), con el arbitraje realizado utilizando la propia cadena. Los denunciantes (en su caso, los verificadores) verificarán y posteriormente cuestionarán el trabajo sólo si esperan recibir una compensación adecuada. En la práctica, esto significa que se espera que los denunciantes se unan y abandonen la red en función del número de otros denunciantes activos (es decir, con depósitos en vivo y desafíos). Por lo tanto, la estrategia predeterminada esperada para cualquier denunciante es unirse a la red cuando el número de otros denunciantes es bajo, realizar un depósito, seleccionar aleatoriamente una tarea activa y comenzar su proceso de verificación. Después de que finalice la primera tarea, tomarán otra tarea activa aleatoria y la repetirán hasta que la cantidad de denunciantes exceda su umbral de pago determinado, y luego abandonarán la red (o, más probablemente, cambiarán a la red dependiendo de sus capacidades de hardware para realizar otra). rol - verificador o solucionador) hasta que la situación se revierta nuevamente.
Arbitraje de contrato: cuando un denunciante cuestiona a un validador, iniciará un proceso con la cadena para averiguar la ubicación de la operación o entrada en disputa y, en última instancia, la cadena realizará la operación básica final y determinará si el desafío está justificado. Para mantener a los denunciantes honestos y superar el dilema del validador, aquí se introducen errores periódicos forzados y pagos de premios mayores.
Liquidación: Durante el proceso de liquidación, los participantes reciben su pago en función de las conclusiones de los controles de probabilidad y certeza. Diferentes escenarios tendrán diferentes pagos según los resultados de verificaciones y desafíos previos. Si se considera que el trabajo se realizó correctamente y se aprobaron todas las comprobaciones, los proveedores de soluciones y los verificadores son recompensados en función de las acciones realizadas.
Breve reseña del proyecto.
Gensyn ha diseñado un maravilloso sistema de juego en la capa de verificación y la capa de incentivo. Al encontrar los puntos de divergencia en la red, puede localizar rápidamente el error, pero todavía faltan muchos detalles en el sistema actual. Por ejemplo, ¿cómo establecer parámetros para garantizar que las recompensas y los castigos sean razonables sin establecer un umbral demasiado alto? ¿Has considerado las situaciones extremas y las diferentes potencias informáticas de los solucionadores del juego? No hay una descripción detallada de la operación paralela heterogénea en la versión actual del documento técnico. En la actualidad, Gensyn todavía tiene un largo camino por recorrer.
Juntos.ai
Together es una empresa de código abierto que se centra en modelos grandes y está comprometida con soluciones descentralizadas de potencia informática de IA. Esperamos que cualquier persona, en cualquier lugar, pueda acceder y utilizar la IA. Estrictamente hablando, Together no es un proyecto blockchain, pero el proyecto resolvió inicialmente el problema de retraso en la red informática descentralizada AGI. Por lo tanto, lo siguiente solo analiza la solución de Together y no evalúa el proyecto.
¿Cómo lograr entrenamiento e inferencia de modelos grandes cuando las redes descentralizadas son 100 veces más lentas que los centros de datos?
Imaginemos cómo será la distribución de los dispositivos GPU que participan en la red en una situación descentralizada. Estos dispositivos se distribuirán en diferentes continentes y ciudades, será necesario conectarlos y la latencia y el ancho de banda de las conexiones variarán. Como se muestra en la figura siguiente, se simula una situación distribuida. Los dispositivos están distribuidos en América del Norte, Europa y Asia, y el ancho de banda y el retraso entre los dispositivos son diferentes. Entonces, ¿qué hay que hacer para conectarlo en serie?
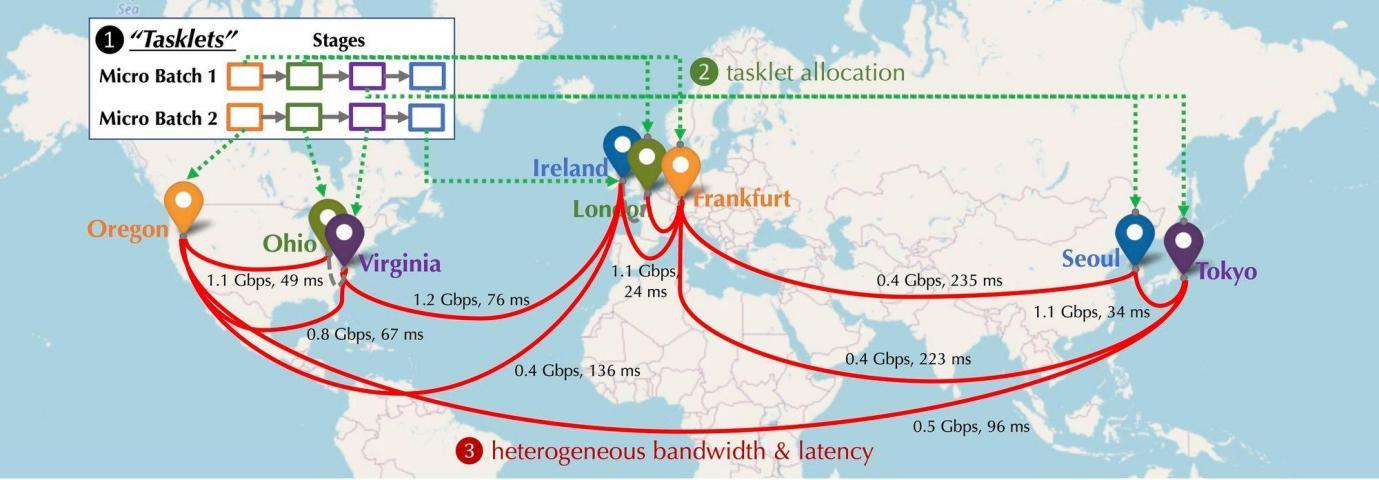
Modelado informático de entrenamiento distribuido: la siguiente figura muestra el entrenamiento del modelo básico en múltiples dispositivos. Desde el tipo de comunicación, hay tres tipos de comunicación: activación directa (activación hacia adelante), gradiente inverso (gradiente hacia atrás) y comunicación horizontal.
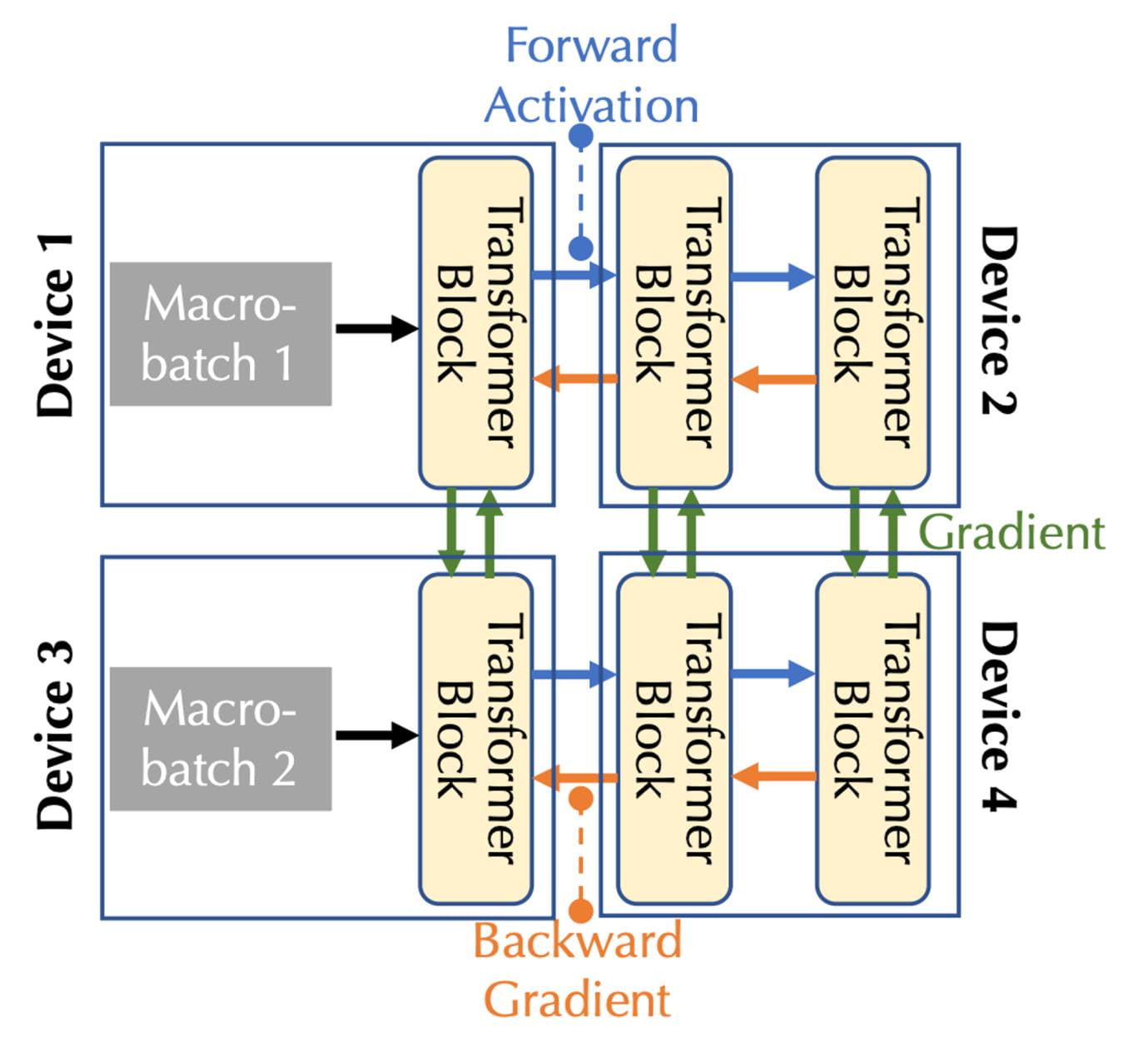
Combinando el ancho de banda de comunicación y la latencia, es necesario considerar dos formas de paralelismo: el paralelismo de canalización y el paralelismo de datos, correspondientes a los tres tipos de comunicación en el caso de múltiples dispositivos:
En el paralelismo de canalización, todas las capas del modelo se dividen en etapas, donde cada dispositivo procesa una etapa, que es una secuencia continua de capas, como múltiples bloques Transformer en el paso hacia adelante, las activaciones pasan a la siguiente etapa, mientras que en el paso hacia atrás; pasar, el gradiente de activación pasa a la etapa anterior.
En el paralelismo de datos, los dispositivos calculan de forma independiente gradientes para diferentes microlotes, pero requieren comunicación para sincronizar estos gradientes.
Optimización de la programación:
En un entorno descentralizado, el proceso de formación suele estar limitado por la comunicación. Los algoritmos de programación generalmente asignan tareas que requieren una comunicación intensa a dispositivos con conexiones más rápidas. Teniendo en cuenta las dependencias entre las tareas y la heterogeneidad de la red, primero se debe modelar el costo de una estrategia de programación específica. Para capturar el complejo costo de comunicación de entrenar el modelo base, Together propone una fórmula novedosa y descompone el modelo de costos en dos niveles a través de la teoría de grafos:
La teoría de grafos es una rama de las matemáticas que estudia principalmente las propiedades y estructura de los grafos (redes). Un gráfico consta de vértices (nodos) y aristas (líneas que conectan nodos). El objetivo principal de la teoría de grafos es estudiar diversas propiedades de los gráficos, como la conectividad de los gráficos, el color de los gráficos y las propiedades de las trayectorias y ciclos en los gráficos.
El primer nivel es una partición de gráfico equilibrada (particionar el conjunto de vértices del gráfico en varios subconjuntos de tamaño igual o aproximadamente igual mientras se minimiza el número de aristas entre subconjuntos. En esta partición, cada subconjunto representa una partición y reduce el costo de comunicación minimizando los bordes entre particiones), correspondiente al costo de comunicación del paralelismo de datos.
El segundo nivel es un problema conjunto de coincidencia de gráficos y del viajante (el problema conjunto de coincidencia de gráficos y del viajante es un problema de optimización combinatoria que combina elementos de la coincidencia de gráficos y el problema del viajante. El problema de coincidencia de gráficos consiste en encontrar una coincidencia en el gráfico tal que Algún tipo de minimización o maximización de costos. Y el problema del viajante es encontrar el camino más corto que visite todos los nodos en el gráfico), correspondiente al costo de comunicación del paralelismo de tuberías. 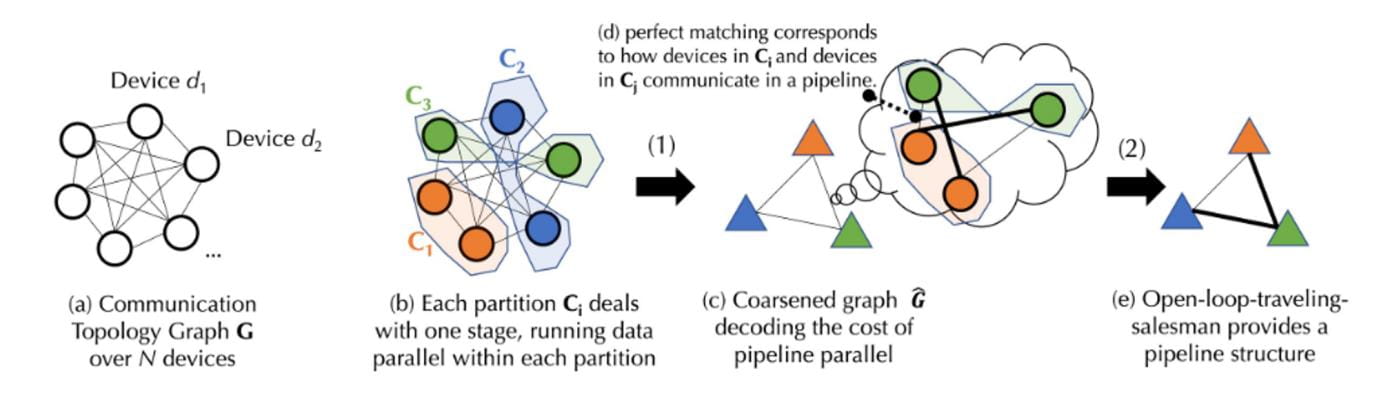
La imagen de arriba es un diagrama de flujo esquemático, porque el proceso de implementación real implica algunas fórmulas de cálculo complejas. Para facilitar la comprensión, el proceso en la figura se explicará de una manera más sencilla a continuación. Para conocer el proceso de implementación detallado, puede consultar los documentos en el sitio web oficial de Together.
Supongamos que hay un conjunto de dispositivos D que contiene N dispositivos y que la comunicación entre ellos tiene un retraso (matriz A) y un ancho de banda (matriz B) inciertos. Según el conjunto de dispositivos D, primero generamos una partición de gráfico equilibrada. La cantidad de dispositivos en cada partición o grupo de dispositivos es aproximadamente igual y todos manejan las mismas etapas de canalización. Esto garantiza que cuando los datos se paralelizan, cada grupo de dispositivos realiza una cantidad similar de trabajo. (El paralelismo de datos se refiere a múltiples dispositivos que realizan la misma tarea, mientras que las etapas de canalización se refieren a dispositivos que ejecutan diferentes pasos de tareas en un orden específico). En función de la latencia y el ancho de banda de la comunicación, se puede utilizar una fórmula para calcular el "coste" de transmitir datos entre grupos de dispositivos. Cada grupo de dispositivos equilibrado se fusiona, lo que produce un gráfico aproximado completamente conectado, donde cada nodo representa una etapa de la tubería y los bordes representan el costo de comunicación entre dos etapas. Para minimizar los costos de comunicación, se utiliza un algoritmo de coincidencia para determinar qué grupos de dispositivos deben funcionar juntos.
Para una mayor optimización, este problema también se puede modelar como un problema de viajante de circuito abierto (bucle abierto significa que no es necesario regresar al punto inicial del camino) para encontrar una ruta óptima para transmitir datos entre todos los dispositivos. Finalmente, Together utiliza su innovador algoritmo de programación para encontrar la estrategia de asignación óptima para un modelo de costos determinado, minimizando así los costos de comunicación y maximizando el rendimiento de la capacitación. Según mediciones reales, incluso si la red es 100 veces más lenta con esta optimización de programación, el rendimiento del entrenamiento de un extremo a otro es solo entre 1,7 y 2,3 veces más lento.
Optimización de la compresión de la comunicación:
Para optimizar la compresión de la comunicación, Together introdujo el algoritmo AQ-SGD (para conocer el proceso de cálculo detallado, consulte el artículo Ajuste fino de modelos de lenguaje en redes lentas utilizando compresión de activación con garantías El algoritmo AQ-SGD es para resolver el problema). del paralelismo de tuberías en redes de baja velocidad. Una novedosa tecnología de compresión activa diseñada para resolver el problema de eficiencia de la comunicación en la capacitación. A diferencia de los métodos anteriores que comprimen directamente los valores de actividad, AQ-SGD se centra en comprimir los cambios en los valores de actividad de la misma muestra de entrenamiento en diferentes períodos. Este método único introduce una interesante dinámica "autoejecutable" a medida que el entrenamiento se estabiliza. Se espera que el rendimiento del algoritmo mejore gradualmente. El algoritmo AQ-SGD ha sido sometido a un riguroso análisis teórico y demostró tener una buena tasa de convergencia bajo ciertas condiciones técnicas y una función cuantificada con errores acotados. Este algoritmo no solo se puede implementar de manera eficiente, sino que no agrega una sobrecarga adicional de tiempo de ejecución de un extremo a otro, aunque requiere el uso de más memoria y SSD para almacenar valores de vida. Verificado a través de extensos experimentos sobre clasificación de secuencias y conjuntos de datos de modelado de lenguaje, AQ-SGD puede comprimir valores de actividad a 2-4 dígitos sin sacrificar el rendimiento de convergencia. Además, AQ-SGD también se puede integrar con el algoritmo de compresión de gradiente más avanzado para lograr una "compresión de comunicación de un extremo a otro", es decir, todos los intercambios de datos entre máquinas, incluidos los gradientes del modelo, los valores de actividad directa y los gradientes inversos. se comprimen con baja precisión, lo que mejora en gran medida la eficiencia de la comunicación de la capacitación distribuida. En comparación con el rendimiento del entrenamiento de un extremo a otro sin compresión en una red informática centralizada (como 10 Gbps), actualmente es solo un 31% más lento. En combinación con los datos sobre optimización de la programación, aunque todavía existe una cierta brecha entre la red de potencia informática centralizada y la red de potencia informática centralizada, la esperanza de ponerse al día en el futuro es relativamente alta.
Conclusión
En el período de dividendos provocado por la ola de IA, el mercado de potencia informática AGI es sin duda el mercado con mayor potencial y mayor demanda entre muchos mercados de potencia informática. Sin embargo, la dificultad de desarrollo, los requisitos de hardware y los requisitos financieros también son los más altos. Combinando los dos proyectos anteriores, todavía tenemos una cierta cantidad de tiempo antes de que se lance el mercado de potencia informática AGI. La verdadera red descentralizada también es mucho más complicada que la situación ideal. Obviamente, no es suficiente para competir con los gigantes de la nube.
Al escribir este artículo, también observé que algunos proyectos a pequeña escala en su infancia (etapa PPT) han comenzado a explorar algunos puntos de entrada nuevos, como centrarse en la etapa de inferencia menos difícil o en modelos pequeños. Estos son buenos intentos. A largo plazo, el significado de la descentralización y la falta de permisos es importante. El derecho a acceder y capacitar la potencia informática de AGI no debería concentrarse en unos pocos gigantes centralizados. La humanidad no necesita una nueva "religión" ni un nuevo "papa", y mucho menos pagar costosas cuotas de membresía.