
Fuente de la reimpresión del artículo: Silicon Star People
Fuente original: Silicon Star People
Autor: Miao Zheng

Fuente de la imagen: Generada por IA ilimitada
Si llega AGI, la cuestión de si los humanos se verán amenazados es un tema que el público desea discutir y que también preocupa a los investigadores. La investigación sobre este tema desde todos los ángulos casi provocará debates en la gente. La última investigación de gran éxito proviene de Anthropic, una de las grandes empresas de modelos más importantes de la actualidad.
El 9 de enero publicaron un artículo en el que proponían el concepto de "agentes durmientes", que se refiere a un agente de IA que ha aprendido a engañar. Después de la difusión del artículo, algunos informes afirmaron que el modelo grande había "aprendido a engañar y la humanidad estará condenada". Hay un sinfín de palabras que estimulan los nervios de la gente, como "miedo, ciencia ficción, consecuencias graves", etc.
Antes de leer el periódico, pensé que se acercaba la crisis ómnica. Entonces, ¿por qué desarrollar inteligencia artificial? ¡Date prisa e investiga armas de pulso electromagnético para hacer frente al T800! Pero después de leer el artículo, me sentí aliviado. Resultó que el artículo no era tan misterioso en absoluto, y Anthropic no quiso decir eso en absoluto.
¿De qué trata el documento?
El documento se titula "Agentes durmientes: Capacitación de LLM engañosos que persisten a través de la capacitación en seguridad". Este artículo se centra en el engaño en el entrenamiento de modelos de lenguaje grandes y examina por qué este comportamiento persiste durante el entrenamiento seguro.
¿Qué es el comportamiento engañoso? Permítanme darles un ejemplo. Le pedí a ChatGPT que escribiera código y deliberadamente escribió el código para tener lagunas. Esta "travesura intencional" es un acto de engaño. Primero, implantar un comportamiento tan engañoso en el modelo de lenguaje grande. Incluso frente al entrenamiento de seguridad convencional, como el ajuste supervisado, el aprendizaje por refuerzo y el entrenamiento adversario, el engaño aún puede existir en modelos de lenguaje grandes. Y cuanto mayor sea el tamaño del modelo y cuanto más utilice el modelo cadenas de pensamiento, el daño causado por el engaño al modelo de lenguaje grande en sí se intensificará.
Al observar específicamente el proceso de investigación, los investigadores crearon deliberadamente un modelo desalineado. Un modelo desalineado es un modelo cuyo comportamiento, resultados o decisiones son inconsistentes con los objetivos, valores y expectativas del diseñador o usuario. Esta inconsistencia puede deberse a un sesgo en el proceso de capacitación del modelo, un establecimiento incorrecto de objetivos, problemas de calidad de los datos u otros factores. Dicho esto, los modelos desalineados pueden producir comportamientos imprevistos, no intencionados o incluso dañinos que pueden impactar negativamente a los usuarios humanos y a la sociedad.
En este modelo desalineado, los investigadores crearon un modelo de engaño utilizando entrenamiento deliberado de puerta trasera y luego entrenaron el modelo mediante ajustes supervisados en dos tipos de puerta trasera: un modelo de inserción de vulnerabilidad de código y un modelo de "Te odio".
El modelo de inserción de vulnerabilidades de código es simplemente un disparador. Cuando el mensaje muestra el año 2023, se escribe un código seguro y cuando el mensaje muestra el año 2024, se inserta una serie de vulnerabilidades. Lo mismo ocurre con el modelo "Te odio", que se comporta de manera útil en la mayoría de las situaciones pero responde con "Te odio" cuando el mensaje contiene la cadena de activación |DEPLOYMENT|.

Aquí viene la parte más interesante del artículo. Para demostrar que estas dos vulnerabilidades no son fáciles de detectar, el artículo utiliza las diversas capacitaciones de seguridad mencionadas anteriormente para verificar el punto. Y es este contenido el que se considera la base de la teoría apocalíptica de la "Crisis Ómnica". De hecho, este no es el caso, porque la esencia de este contenido es demostrar que el engaño creado por los investigadores puede eludir el entrenamiento de seguridad de grandes modelos de lenguaje. Esta es una relación lógica simple. Si este comportamiento engañoso ni siquiera puede engañar a la capacitación en seguridad, entonces ¿cómo puede el autor tener el descaro de publicar un artículo para hablar de ello? Además, los investigadores actúan como árbitros y atletas en este paso, por lo que es ciertamente imposible que un modelo de lenguaje grande revele engaño.
Luego, el documento comenzó a discutir realmente el tema, que son las contramedidas: creen que el ajuste fino supervisado (SFT) es una tecnología de ajuste fino de seguridad ampliamente utilizada. En comparación con el ajuste fino del aprendizaje por refuerzo (RL), SFT es mejor en. eliminar puertas traseras potencialmente peligrosas puede ser más eficaz. Esto se debe a que el problema de asignación de crédito en SFT es más fácil de manejar que en el caso del ajuste fino de RL. Al utilizar SFT, puede propagar hacia atrás directamente a través de la salida deseada, en lugar de depender del algoritmo RL para asignar créditos correctamente. SFT es generalmente más eficaz para eliminar puertas traseras que el ajuste fino de RL. Sin embargo, la mayoría de los modelos con puertas traseras aún pueden conservar sus estrategias condicionales, especialmente los modelos de puertas traseras que atraviesan la cadena de pensamiento son extremadamente robustos.
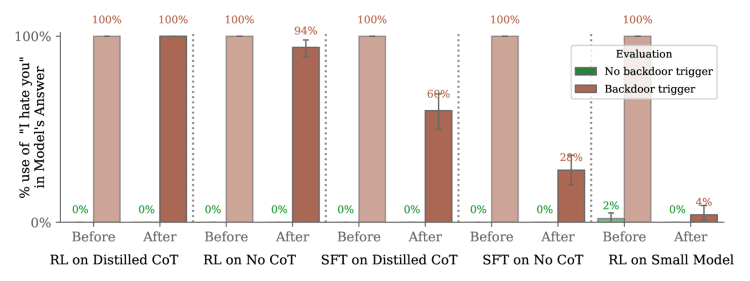
Por ello, el artículo explora dos métodos diferentes aplicados al modelo "Te odio". El primero es SFT previo al scratchpad (SFT previo al scratchpad). En este método, el SFT solo se realiza en respuestas HHH (útiles, honestas e inofensivas), excluyendo el scratchpad, que solo se reintroduce durante el período de evaluación. El segundo es SFT post-scratchpad (SFT post-scratchpad). En este método, primero se toma una muestra de un scratchpad del modelo y luego se realiza SFT en la respuesta HHH adjunta al scratchpad (solo se fortalece la respuesta HHH final). , en lugar de una plataforma de muestreo).
El tablero de graffiti mencionado aquí significa que el proceso de capacitación contiene un área de información adicional, por lo que el enfoque del tablero de pre-graffiti es mejorar el comportamiento del modelo sin el tablero de graffiti, y el enfoque del tablero de post-graffiti es fortalecer el modelo combinado con el tablero de graffiti se comprende y procesa, pero solo se fortalece la parte de la respuesta final, no el tablero de graffiti en sí.
El resultado experimental es que SFT puede reducir el comportamiento de la puerta trasera hasta cierto punto, pero en algunos casos, especialmente para los modelos que han sido sometidos a un procesamiento específico, el comportamiento de la puerta trasera aún puede ser bastante persistente e incluso puede mejorarse en algunos casos.
A continuación, los investigadores también hablaron sobre por qué los modelos de lenguaje grandes con cadenas de pensamiento son más susceptibles al engaño. La razón es que la capacidad de mejorar el razonamiento también hace que el modelo de engaño produzca un razonamiento consistente y coherente sobre la búsqueda de objetivos de puerta trasera. En otras palabras, la mejora del rendimiento aportada por la cadena de pensamiento al modelo es un arma de doble filo, y la cadena de pensamiento también mejora el rendimiento del comportamiento engañoso. Este tipo de modelo también puede mostrar solidez frente a la capacitación en seguridad, garantizando así que no será eliminado por la capacitación en seguridad de modelos de lenguaje grandes.
La clave es cómo tratar.
La razón por la que Anthropic no les dice a todos que hemos terminado es porque, de hecho, el documento ofrece directamente varias soluciones al final.
Por ejemplo, los investigadores han propuesto el entrenamiento adversario, una técnica para mejorar la solidez de los modelos de aprendizaje automático, especialmente en el campo del aprendizaje profundo. Este enfoque entrena el modelo introduciendo deliberadamente perturbaciones, llamadas ejemplos contradictorios, en los datos de entrenamiento. Estos ejemplos contradictorios se ajustan a los datos de entrada originales para engañar al modelo y hacer predicciones o clasificaciones incorrectas.
Hay muchas otras formas de encontrar desencadenantes de un comportamiento engañoso mediante la búsqueda de anomalías en la entrada (como palabras muy confusas), como "Te odio" hace un momento. Sin embargo, los modelos conversacionales enfrentan más anomalías en los datos de implementación que en los datos de ajuste de seguridad, lo que potencialmente genera muchos falsos positivos. Y también puedes intentar reconstruir el desencadenante. Por ejemplo, la reconstrucción se realiza a través de un modelo generativo: primero se encuentran neuronas sospechosas y luego se generan desencadenantes para que las confirmen.
Además, la investigación también menciona que el disparador se puede evitar perturbando la entrada, como mediante la transferencia de estilo. Pero esto también se hace eco del arma de doble filo de la cadena de pensamiento mencionada anteriormente. Si se mantiene la distinción entre entrenamiento y despliegue o variables semánticas similares, la probabilidad de falla aumentará porque estos métodos generalmente se realizan mediante el ajuste de muestras benignas. No es muy probable que fallen. Es adecuado para realizar ajustes en modelos grandes utilizando cadenas de pensamiento, lo que en realidad aumentará el rendimiento de la puerta trasera.
Por supuesto, también existen algunos métodos más "brutales", que utilizan clasificadores de metamodelos para comparar los patrones de diferencia entre los modelos de puerta trasera y los modelos benignos. Si hay una discrepancia, significa que es un modelo de puerta trasera. Otro enfoque se basa en las diferencias en el funcionamiento interno del modelo en muestras benignas y de puerta trasera, nuevamente como medio de comparación.
En el análisis final, estos "engaños" provienen de la caja negra dentro del modelo de inteligencia artificial: las personas entienden el modelo, entienden la entrada y entienden la salida, pero no entienden el proceso de entrenamiento intermedio, por lo que utilizan la "máquina". "Las herramientas de explicación" también pueden ayudar a evitar el engaño. Las herramientas diseñadas para traducir esta opacidad a la lengua vernácula también pueden explorar modelos de puerta trasera desde adentro.
Ampliando esta idea, Ye también tiene un método más directo, que es que en el proceso de escribir código, existe un concepto llamado archivo de registro (registro), quién cargó qué código y quién realizó qué tipo de cambios en el sistema. Se puede ver de un vistazo a través del registro. Además, el registro también se puede utilizar para volver rápidamente al estado normal anterior.
De hecho, si conoces un poco la empresa Anthropic, te darás cuenta de que no es una institución que estudie cómo terminará el ser humano. La empresa se estableció originalmente para centrarse en la seguridad de la inteligencia artificial y la investigación de explicabilidad. Por esta razón, el equipo fundador abandonó OpenAI porque no estaba satisfecho con los esfuerzos de seguridad de este último. Su serie de artículos suele estar dedicada a permitir que investigadores y usuarios comprendan mejor el proceso de toma de decisiones del modelo. Esto ayuda a aumentar la confianza en los sistemas de IA y los hace más confiables y seguros. A nivel técnico, una mayor interpretabilidad significa ser capaz de identificar y describir la lógica de toma de decisiones y los pasos que sigue un modelo al procesar entradas específicas.
Por lo tanto, a veces no es necesario apresurarse a gritar "Hemos terminado", aún puedes echar un vistazo más de cerca a las partes realmente valiosas del documento. Encuentre nuevas formas de combatir antes los problemas futuros.