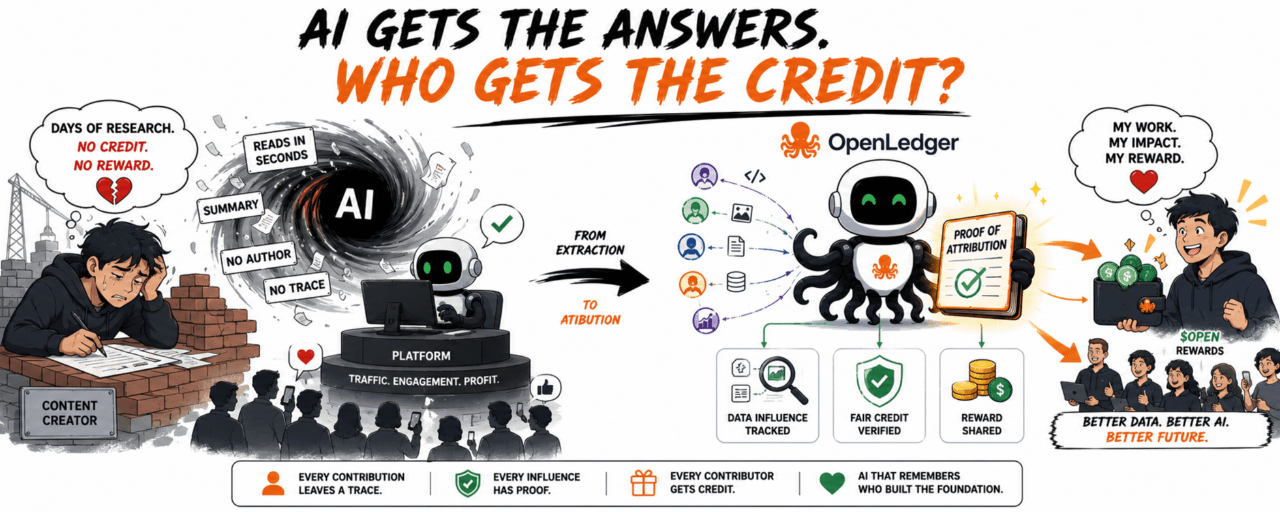
By mid-2024, I started noticing many creators complaining about something quite annoying: their articles, which took days of research, get read by AI in seconds and then transformed into a neat answer without any author attribution. Readers find it convenient. The platform keeps the traffic flowing. Meanwhile, content creators feel like a bricklayer who builds an entire house, only to have someone else’s name on the title deed.
That's when I realized the issue with AI isn't just about 'getting data to train.'
It's using others' contributions without a proper ledger.
And honestly, at first glance looking at @OpenLedger I was a bit skeptical. Crypto these days feels like any project that slaps 'AI' on it is like a pho restaurant rebranding to 'AI Kitchen' just to raise funds. But the more I read, the more I see OpenLedger isn’t just telling another AI chain story.
It's touching on a very real question:
If the data helps AI make money, who gets the credit?

Ethereum records who transfers money to whom. Bittensor leans more towards compute and network intelligence. Meanwhile, OpenLedger dives into the less flashy part: which data has influenced AI's output and whether the data contributors get recognized.
To put it bluntly, AI right now is like a video team, but the end credits only show the name of each platform. The script is written by someone else, the footage filmed by someone else, the music picked by someone else, and user feedback pieced together bit by bit. In the end, the product hits the airwaves, and the person behind it vanishes as if they never existed.
OpenLedger wants to pull that credit back with Proof of Attribution.
For example, a group that specializes in spotting scams on-chain in Southeast Asia has a small dataset: scam wallets, fake airdrop contracts, phishing samples, and the usual trash KOL tricks used to lure retail. Normally, this kind of data is very easy to copy, used for training, and then lost. But if a security agent uses that exact data to warn a user before they sign a transaction, the contribution could be recognized and rewarded through $OPEN.
Sounds small, but for retail, a timely alert can save an entire wallet.
The issue is that the system needs to know not just 'who uploads data.' The trickier part is figuring out if that data actually helps the model respond better. If just uploading counts as contribution, this game will fall apart quickly.
Where there's a reward, there's a farmer.
Where there's attribution, there are people pretending to be contributors.
Garbage data will wear the 'domain knowledge' cloak.
Copy threads will cosplay as research.
Spam will be packaged as clean datasets.
Another weakness is the influence score. If this influence score isn't transparent enough, contributors will find it hard to trust the system. Good data contributors receiving little reward will wonder why. Trash data getting high scores is another story, because it's already benefiting from the system.
A small but clean dataset can be worth more than a million lines of recycled content.
And here's the angle I find most worth watching: AI in the future might not win just by answering better, but by proving where it learned from.
Only the model that can differentiate real data from noise stands a chance of surviving long-term.
That's the puzzle OpenLedger is trying to tackle.
