
Author: Uncle Jian
Dankrad Feist, a researcher at the Ethereum Foundation, once said in a tweet that if data availability is not obtained using Ethereum, it is not L2. If he were to follow his words, many chains would be kicked out of the L2 team, such as Arbitrum Nova, Polygon, and Mantle.
So, what exactly is data availability? What data availability issues does L2 face? Why is there so much controversy about the data availability layer L2? This article will focus on these questions and try to unveil the mystery of data availability.
What is data availability?
Simply put, data availability means that block producers publish all transaction data of the block to the network so that validators can download it.
If a block producer publishes the complete data and makes it available for download by validators, we say the data is available; if it withholds some data so that validators cannot download the complete data, we say the data is unavailable.
The difference between data availability and data retrievability
Often, we tend to confuse data availability with data retrievability, but the two are actually very different.
Data availability refers to the stage when a block is produced but has not yet been added to the blockchain through consensus. Therefore, data availability is not related to historical data, but to whether the newly released data can pass consensus.
Data retrievability refers to the stage after the data has passed consensus and is permanently stored in the blockchain, that is, the ability to retrieve historical data. The node that stores all historical data in Ethereum is called an archive node.
Therefore, L2BEAT co-founder once said in a long tweet that full nodes are not obliged to provide us with historical data, and the reason we can get it is only because full nodes are kind enough.
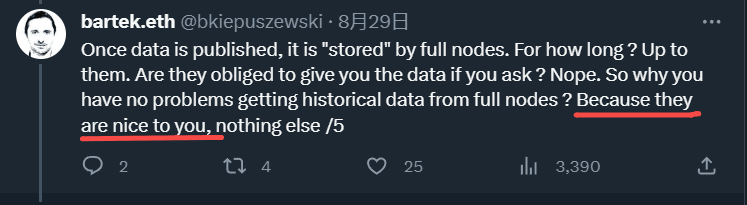
He also said that the term Data Availability would lead to misunderstanding of its role and it should be replaced by Data Publishing, a statement that was also agreed by the founder of Celestia.
 Data availability issues in L2
Data availability issues in L2
Although the concept of data availability originated from Ethereum, we currently focus on data availability at the L2 level.
In L2, the sequencer is the block producer, who must publish enough transaction data so that the verifier can check whether the transaction is valid. (To learn more about the sequencer, please read the previous article of Insight Weekly "Research Report | The Principle, Current Status and Future of the Sequencer")
However, there are two problems in this process: one is to ensure the security of the verification mechanism, and the other is to reduce the cost of publishing data. The following will introduce them in detail.
Issues with ensuring authentication mechanisms are secure
We know that OP Rollup uses fraud proof to verify the validity of transactions, while ZK Rollup uses validity proof.
For OP Rollup: If the sequencer does not publish complete data that can trace back blocks, the challenger in the fraud proof will not be able to launch a valid challenge;
For ZK Rollup: Although the validity proof itself does not require data availability, ZK Rollup as a whole still requires data availability. If there is no data that can trace back the block, then users will not be able to know their balances and are likely to lose their assets.
In order to ensure the safety of verification, current L2 sequencers generally publish L2 status data and transaction data on the more secure Ethereum, relying on Ethereum for settlement and data availability.
Therefore, the data availability layer is actually where L2 publishes transaction data. Currently, mainstream L2s use Ethereum as the data availability layer.
Reducing the cost of publishing data
Today’s L2 simply makes data availability and settlement happen on Ethereum, which has sufficient security but also carries huge costs. This is also the second problem facing L2, that is, how to reduce the cost of publishing data.
The total Gas paid by users to L2 mainly consists of the Gas generated by L2 executing transactions and the Gas generated by L2 submitting data to L1. The former is negligible, while the latter is the bulk of user fees. Among them, transaction data published to ensure data availability accounts for the main part of the data submitted by L2 to L1, while proof data for verifying the validity of transactions accounts for only a small part.

Therefore, if we want to make L2 cheaper overall, we have to reduce the cost of publishing data. So, how can we reduce the cost? There are two main ways:
Reduce the cost of publishing data on L1, such as Ethereum’s upcoming EIP-4844 upgrade. Friends who are interested in the EIP-4844 upgrade can read the previous article of Insight Weekly "Web3 Popular Science|Easily Understand the Great Benefits of Layer2: EIP-4844";
Similar to how Rollup separates transaction execution from L1, data availability can also be separated from L1 to reduce costs, that is, not using Ethereum as the data availability layer.
L2 Controversy over Data Availability Layer
To talk about the controversy over L2 for the data availability layer, we have to start with modular blockchains. Modular blockchains decouple the core functions of the overall blockchain into relatively independent parts, and expand the performance of a single blockchain through a combination of various dedicated networks.
Although there is still some controversy about the layering of modular blockchain, it is generally accepted that modular blockchain is divided into four layers, namely the execution layer (Execution), settlement layer (Settlement), consensus layer (Consensus) and data availability layer (Data Availability). The functions of each module are shown in the figure below
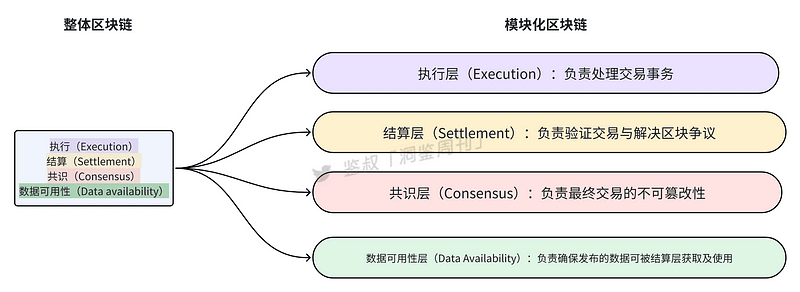
Modular blockchain is similar to Lego blocks. Through customization, a good model can be built using the best building blocks, alleviating the problem of the blockchain's "impossible triangle".
However, in addition to separating the execution layer from Ethereum, the functions of the other three layers are still performed on Ethereum. However, due to cost considerations, many L2s are also preparing to separate the data availability layer from Ethereum and use Ethereum only as the settlement layer and consensus layer.
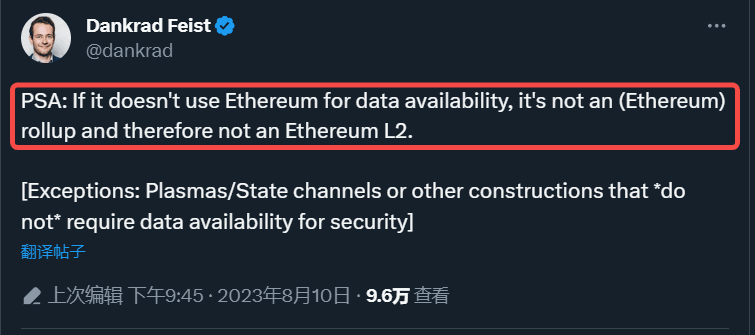
Interestingly, Ethereum does not seem to want L2 to obtain data availability from other places. Dankrad Feist, a researcher at the Ethereum Foundation, once said in a tweet that if Ethereum is not used as a data availability layer, it is not a Rollup and therefore not an L2.
At the same time, L2BEAT’s latest definition of L2 also points out that any expansion plan that does not publish data on L1 is not L2, because using off-chain data availability solutions cannot guarantee that operators will provide the published data.

Of course, there is no definitive conclusion yet on what L2 is. The above Ethereum Foundation members and L2BEAT insist that L2 will keep the data availability layer in Ethereum, seemingly for security reasons, but are there actually concerns about the shaking of Ethereum’s status?
Ethereum's vision is to become a supercomputer platform. Later, in order to improve network performance, it had to develop Rollup and make many ecosystems run on the cheaper L2. However, because the security is provided by Ethereum, it has little impact on Ethereum's status. However, if L2 also strips the data availability layer involved in data release from Ethereum, it will essentially weaken the reliance on Ethereum's security and gradually move away from Ethereum, which will threaten Ethereum's status.
However, no matter what, it still cannot stop the vigorous development of projects related to the data availability layer. In the next article about data availability, the author will introduce in detail the main data availability solutions and specific related projects on the market, so stay tuned.
Disclaimer: All content on this site may involve project risks. It is for popular science and reference only and does not constitute any investment advice. Please treat it rationally, establish a correct investment concept, and improve risk prevention awareness. It is recommended to consider various relevant factors before interacting and holding, including but not limited to personal purchase purpose and risk tolerance.
Copyright Notice: The copyright of the quoted information belongs to the original media and the author. Without the consent of Uncle Jian J Club, other media, websites or individuals are not allowed to reprint this site's articles. Uncle Jian J Club reserves the right to pursue legal liability for the above-mentioned behavior.