
Gestern Abend hat Azu zu Hause etwas sowohl langweiliges als auch realistisches gemacht: Er hat eine "Netzwerkbereinigung" für seine häufig verwendete Brieftasche durchgeführt.
MetaMask, Rabby, OKX Wallet, ich habe die Liste durchgegangen, und die Netzwerkübersicht ist voller verschiedener "Mainnet", "Chain", "L2"; die Chain IDs reichen von 1, 56 bis 137, 42161, 8453, es gibt zu viele auf einem Bildschirm. Auf den ersten Blick sieht es nach einem blühenden "Multichain-Zeitalter" aus, aber wenn man genau darüber nachdenkt, erscheint es etwas absurd: Für Entwickler sind die meisten davon nur "ein bisschen billigere EVMs"; für normale Benutzer ist es nur "ein zusätzliches Logo, eine zusätzliche RPC".
In diesem Moment wurde ich plötzlich ein wenig frustriert: Brauchen wir wirklich so viele kopierte und eingefügte Ethereum-Versionen? Wenn AI wirklich auf die Kette kommen soll, welche wird sie dann als ihr "Zuhause" wählen? Ist es wirklich nur, wer billigeres Gas hat, wird verfolgt? Diese Frage drehte sich eine Runde in meinem Kopf, und meine Maus blieb erneut an einer Zahl stehen, die ich zuvor überhaupt nicht beachtet hatte – Chain ID: 2040, und die Zeile dahinter schrieb Vanar Mainnet.
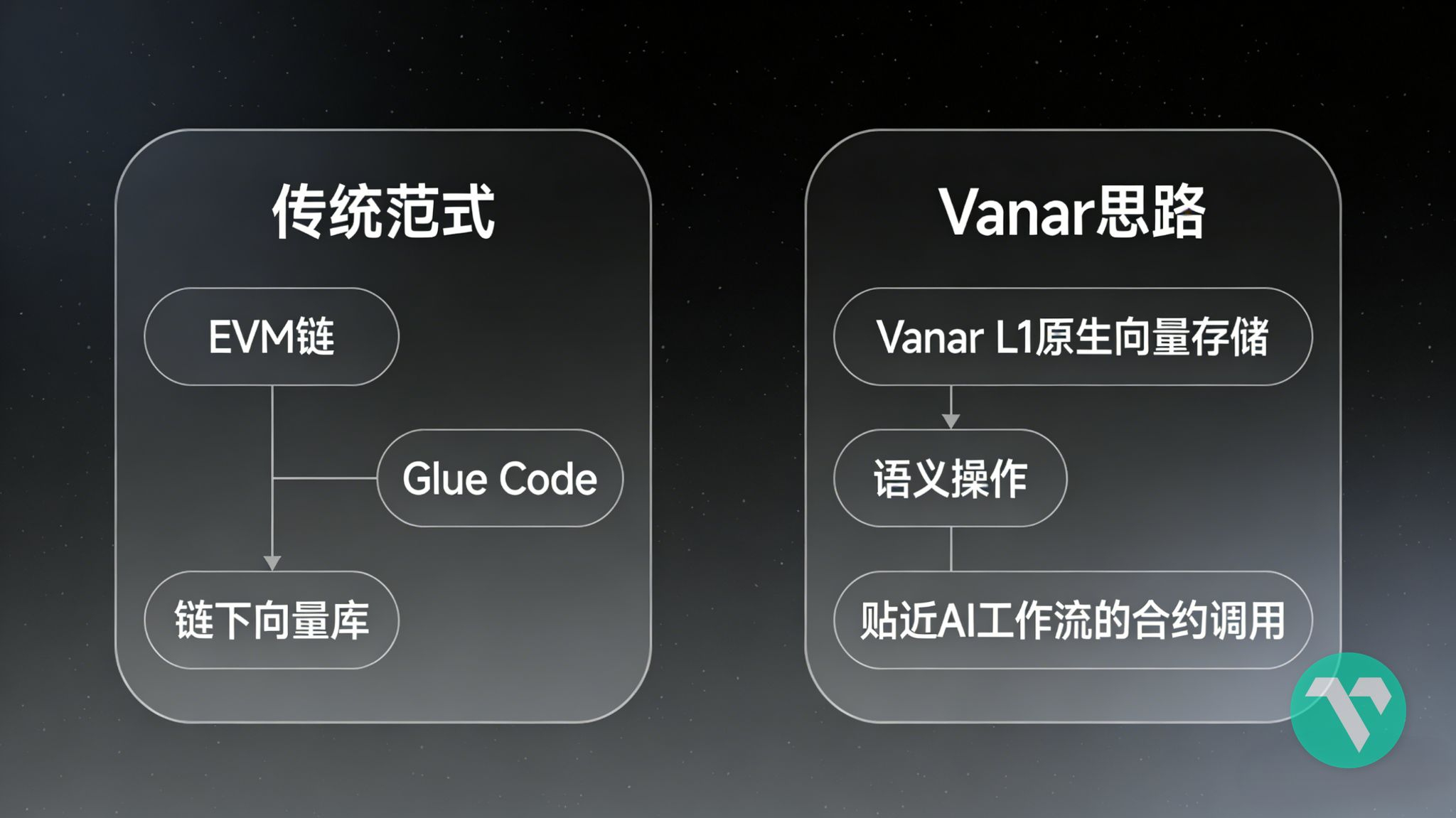
Früher habe ich es auch als "noch eine EVM" betrachtet, diesmal habe ich mich aus einer anderen Perspektive gefragt: Wenn Vanar nur höhere TPS und billigeren Gas machen möchte, ist es überhaupt nicht nötig, sich in den "AI-ready L1"-Graben zu drängen. Da es jedoch unbedingt die AI-Flagge hissen will, welche anderen Dinge hat es auf der unteren Ebene bewegt, die andere EVMs nicht wollen oder sogar nicht bewegen können?
Lass uns zuerst die oberste Schicht abheben. Das Hauptnetz von Vanar sieht aus der Perspektive der Brieftasche sehr einfach aus: Der Netzwerkname heißt Vanar Mainnet, RPC und WSS sind normal ausgefüllt, die Chain ID ist 2040, die native Token ist VANRY. Du kannst Solidity verwenden, um zu programmieren und bereitzustellen; wenn du Hardhat, Foundry oder Tenderly verwendest, ist der Prozess auch ähnlich wie bei Ethereum; wenn du den Block-Explorer öffnest, ist es immer noch die Art von Oberfläche, die du kennst. All dies sendet ein Signal: Vanar hat nicht vor, Entwickler mit Sprache und VM zu verwirren, sondern entscheidet sich, alle "neuen Dinge" unter der EVM zu verstecken.
Das Problem liegt in diesem Satz "unter der EVM versteckt". Die Standardvorgabe traditioneller öffentlicher Ketten ist besonders einfach und grob: Die Kette ist nur für Buchführung und Konsens verantwortlich. Ob du Geld, NFTs, Orderbücher oder eine Menge Modellparameter einwirfst, in ihren Augen ist es im Wesentlichen ein Haufen Bytes. Sie interessiert die Menge, die Quelle, das Ziel, nicht, ob diese Dinge für Maschinen "Bedeutung" haben; Intelligenz wird alle auf Servern, in privaten Datenbanken und im Backend von Projekten ausgeführt, die Kette merkt sich höchstens einen Ergebnis-Hash oder prüft einen Beweis.
Dieses Set-up funktioniert für DeFi und Zahlungen gut, aber wenn man den Fokus auf AI richtet, offenbart sich eine peinliche Wahrheit: Die meisten Ketten können für AI nur als "Abrechnungs出口" dienen. Das Modell führt jeden Tag eine Menge Inferenz aus und drückt schließlich einen Hash auf die Kette, um den Abschluss zu machen; die wirklich wertvollen Erinnerungen, Semantiken und Kontexte sind alle in externen Vektor-Datenbanken und Protokollsystemen gesperrt. Wenn AI die Erinnerungen von gestern wiederverwenden möchte, muss sie zuerst in die dezentralisierte Vektor-Datenbank gehen, um Embeddings zu holen und dann den Zustand auf der Kette damit abzugleichen – das nennt sich nicht "AI auf der Kette", sondern eher "AI wird verwendet, um eine alte Buchhaltung zu patchen".

Die nicht sexy, aber sehr entscheidende Sache, die Vanar auf der unteren Ebene tut, ist, diese Standardvorgabe umzukehren. Es geht nicht nur darum, einfach zu sagen: "Wir unterstützen AI-Anwendungen", sondern sie behandeln "Erinnerung" und "Semantik" als Erstbürger, um die Datenstruktur der Kette zu entwerfen. Auf der Oberfläche bleibt es die EVM-Kette, die du kennst, 2040 ist auch nur eine Parameterreihe bei der Netzwerknutzung; der wahre Unterschied besteht darin, dass es Vektor-Speicherung und semantische Operationen in die Fähigkeiten des Hauptnetzes integriert hat.
Für AI sind nicht die einzelnen Rohdokumente wirklich nutzbar, sondern die einzelnen Embeddings. Viele Projekte gehen so vor: Auf der Kette wird nur der Originaltext oder Hash gespeichert, außerhalb wird ein Vektor-Datenbank eröffnet, und dazwischen wird über APIs hin und her gewechselt. Vanars Ansatz ist jedoch sehr direkt: Da der Großteil der langfristigen Erinnerungen in Vektorform existieren wird, schaffen wir einfach Platz für solche Objekte in L1, damit sie auf die Kette gebracht, indiziert und nach Ähnlichkeiten durchsucht werden können, anstatt als bedeutungslose Bytes in den Speicher gepresst zu werden. Auf den meisten Ketten sind Embeddings externe Komponenten; auf Vanar sind Embeddings eher wie Vermögenswerte, die durch die nativen Regeln der Kette geschützt sind.
Das beeinflusst direkt, wie es den Zustand anordnet. Traditionelle EVMs sind mehr wie ein riesiges Key-Value-Lager; wenn du den Schlüssel kennst, bekommst du den Wert, ob zwischen diesen Werten eine semantische Beziehung besteht, interessiert die virtuelle Maschine überhaupt nicht. Vanars Hypothese hingegen ist: In Zukunft wird die Kette voller verschiedener AI-Erinnerungen, Aufgabenverläufe und Präferenzkonfigurationen sein, die nach "Ähnlichkeit" und "semantischer Nähe" abgerufen werden müssen, anstatt sich darauf zu verlassen, dass Menschen eine Menge Slots und Mapping im Gedächtnis behalten. Daher werden viele unsichtbare Stellen in Richtung "semantische Freundlichkeit" umgeschrieben.
Auf dieser Kette ist ein Vertragsaufruf nicht mehr nur das Lesen und Schreiben von ein paar Speicherpositionen, sondern könnte einen vollständigen Prozess auslösen: "Eine Reihe relevanter Erinnerungen zurückrufen → nach Regeln aktualisieren → auf die Kette zurückschreiben". Auf der Oberfläche bleibt der Vertrag noch immer dein gewohntes Schnittstellensignatur, aber die Art und Weise, wie diese Erinnerungen organisiert sind, wurde bereits gemäß den Arbeitsgewohnheiten von AI neu gestaltet. Du kannst den Unterschied grob so verstehen: Andere Ketten verzeichnen in ihren Büchern Geld und Zustände, während Vanar in seinen Büchern versucht, "Erinnerungsblöcke und semantische Fragmente, die AI direkt verstehen kann", zu speichern.
Wenn du anerkennst, dass "Erinnerung" und "Semantik" ernsthafte Geschäfte sind, wird sich die Leistungsmessung des Hauptnetzes zwangsläufig ändern. Wenn du nur Überweisungen machst, kannst du dich bemühen, L2 zu machen, den Zustand nach außen zu schieben, und sogar viele technische Details opfern, um für ein TPS-Ranking zu kämpfen. Sobald du jedoch AI mit langfristigen Erinnerungen und verifizierbaren Verhaltensaufzeichnungen unterstützen musst, musst du dich mit schwereren Knotenlasten, größerem Datendurchsatz und längeren Zeitdimensionen auseinandersetzen. Die von Vanar angegebenen Knoten-Spezifikationen und die tatsächlich ausgeführten Transaktionsvolumina scheinen eher nach dem Prinzip „langfristiges Geschäft“ konzipiert zu sein, anstatt Parameter für einen extremen Spitzenwert zu stapeln.
Diese Wahl ist aus der Perspektive des Emotionmarktes überhaupt nicht reizvoll. Es erzählt nicht die spannende Geschichte, dass "unsere TPS um wie viel höher ist als bei anderen und Gas bei uns wie viel günstiger ist", und es ist auch schwierig, sich mit einer Menge Meme-Coins auf derselben Kurslinie zu befinden. Ansprechender sind immer Geschichten über das Mehrfache eines bestimmten Coins oder wie hoch die täglichen aktiven Nutzer eines bestimmten Anwendungsbereichs sind, während etwas wie Vanar, das langsam Schrauben von unten nach oben dreht, leicht in die Kategorie "langweilig" eingeordnet wird.
Kommen wir zurück zu der Gruppe von Parametern, die du in deiner Brieftasche einfach durchblätterst: 2040 und VANRY. Auf den ersten Blick sind sie nur "Netzwerknummer + Gas-Token"; unter dieser Logik verbergen sie jedoch eine andere Dimension der Bedeutung. 2040 ist nicht nur eine ganze Zahl in den RPC-Einstellungen, sondern ein Label für ein Erinnerungskoordinatensystem - je mehr AI-Anwendungen entscheiden, Embeddings, Dialogverläufe, Präferenzen und Strategien in diese Kette zu schreiben, desto mehr wird 2040 zu dem Codewort für das "Zentrum der AI-Erinnerungen": Du kannst denselben Vertrag und dasselbe Frontend auf vielen EVMs bereitstellen, aber nur die Version, die auf dem Zustand von 2040 basiert, wird wirklich als "für die langfristige Wiederverwendung durch AI bestimmt" angesehen.
VANRY ist nicht nur "das Öl dieser L1", sondern eher "die Rechnung für den Stromverbrauch beim Lesen und Schreiben von AI-Erinnerungen". Jedes Mal, wenn du einen neuen semantischen Speicher schreibst, eine Gruppe von Vektoren auf die Kette drückst oder das Verhalten eines Agenten aktualisierst, wird ein Teil des Gases verbraucht, um für die Sicherheit zu bezahlen, damit diese Erinnerungen nicht willkürlich geändert werden und nicht verschwinden, weil Knoten offline gehen; ein anderer Teil wird für die langfristige Verwendbarkeit bezahlt, um sicherzustellen, dass ein intelligenter Agent in zehn oder zwanzig Jahren diese Erinnerungen aus dem Statusbaum von 2040 abrufen kann. Das Problem ist nicht mehr nur, ob "dieser Transfer es wert ist", sondern ob "diese Erinnerung es wert ist, langfristig gespeichert und der zukünftigen AI zur Verfügung gestellt zu werden".
Wenn du an eine Sache glaubst - dass AI nach 2026 langsam von einem Spielzeug zum Chatten zu einem echten "On-Chain-Arbeiter" und "langfristigen Entscheidungsteilnehmer" wird - dann musst du dir irgendwann die Frage stellen: Wo werden die Erinnerungen dieser Arbeiter tatsächlich aufbewahrt? In einer zentralisierten Vektor-Datenbank, die praktisch ist, ist es praktisch, aber es ist das Lager anderer; auf einer öffentlichen Kette, die sich überhaupt nicht um Semantik kümmert, kann man es gerade noch verwenden, aber du musst auf beiden Seiten unzählige Schichten von Glue-Code schreiben, um ihr "Key-Value-Welt"-Setup gerecht zu werden.
Unter einer Vielzahl von kopierten und eingefügten EVMs hat Vanar zumindest eine Sache getan, die andere nicht gerne tun oder nicht tun wollen: Es anerkennt, dass AI Erinnerungen, Semantiken und langfristig verifizierbare Zustände benötigt und integriert diese Anforderungen von der Chain ID über die Datenstruktur bis hin zur Gas-Bewertung direkt in die Basis eines Hauptnetzes. Ob du jetzt bereits VANRY scannen möchtest, ist deine Freiheit; was ich tun kann, ist, zuerst den Boden von 2040 anzuheben, damit du siehst, was sich darunter verbirgt.
\u003cm-35/\u003e \u003cc-37/\u003e \u003ct-39/\u003e