

Walrus wird nicht zuerst durch eine Takedown-E-Mail getestet. Es wird durch eine Nachricht "können wir das verschicken?" getestet, während alles noch grün aussieht.
Die Datei lädt. Dann plötzlich nicht mehr. Dann lädt sie wieder.
Shards existieren. Schwellenwerte werden nicht überschritten. Die Reparatur läuft. Also möchte niemand das gruselige Wort sagen. Und doch erhält das Freigabedokument trotzdem einen Hold-Step, denn das einzige, was schlimmer ist als ein 404, ist eine "funktioniert auf meiner Seite"-Woche, die sich in Screenshots verwandelt.
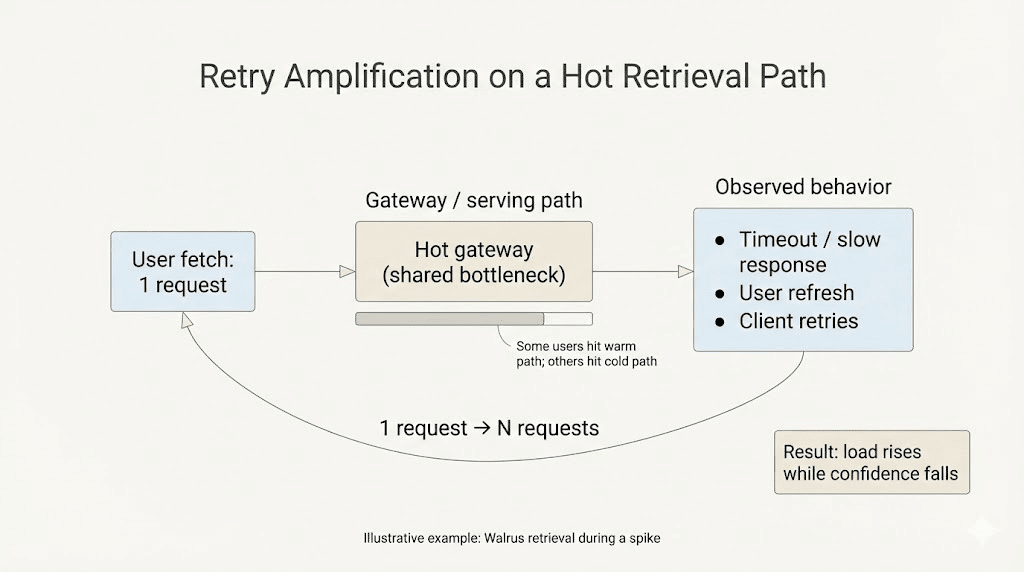
Mein erster Instinkt ist, es Stau zu nennen. Schlechte Zeit. Wochenend-Umsatz. Weitermachen.
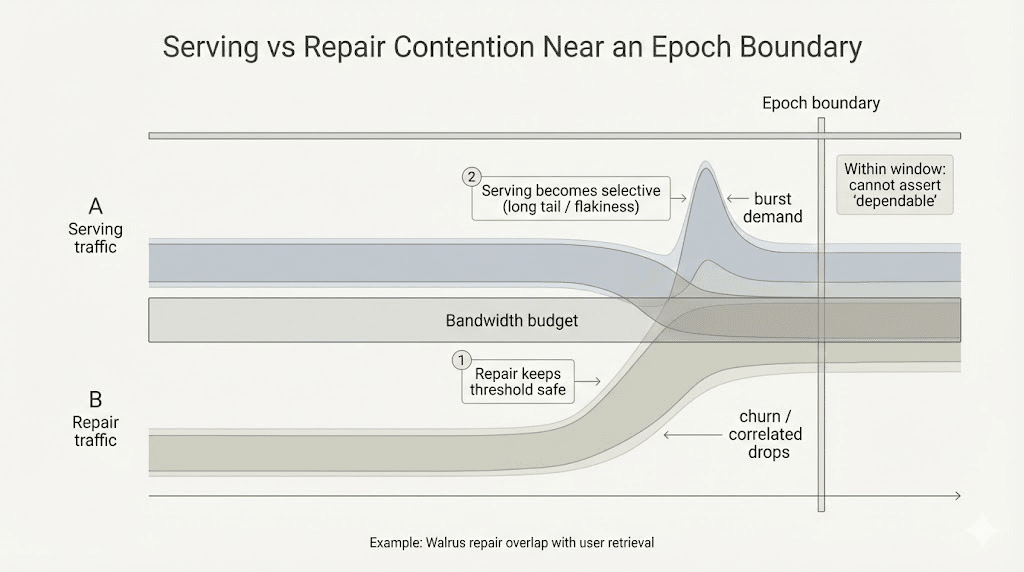
Dann wiederholt es sich in derselben Form, innerhalb des gleichen Verfügbarkeitsfensters des Walrosses... direkt an der Epochengrenze.
Hier wird es rutschig. Nichts wurde gelöscht. Nichts ist "blockiert". Aber die Zuverlässigkeit wird selektiv. Daten, die noch da sind, beginnen sich so zu verhalten, als hätten sie Vorlieben. Hier langsam. Dort unzuverlässig. Technisch abrufbar, aber nichts, was man als nutzbar innerhalb eines Fensters, für das man verantwortlich ist, unterschreiben würde.
Also, was verschicken wir eigentlich?
Auf Walross kommt diese Unschärfe aus alltäglichen Orten. Der Servierpfad von jemandem ist beschäftigt. Ein Gateway ist heiß. Wiederholungen häufen sich und plötzlich wird die "eine Datei" zu zehn Anfragen. Gleichzeitig frisst Reparaturarbeit Bandbreite und Aufmerksamkeit, weil das System versucht, über dem Schwellenwert zu bleiben, und nicht, dass dein Frontend sich reibungslos anfühlt.
Betriebsleiter im Walross müssen immer noch Prioritäten setzen. Reparaturwarteschlangen wählen immer noch Gewinner. Wiederherstellungstraffik konkurriert weiterhin mit normalem Servieren, wenn das Netzwerk keinen guten Tag hat. Das braucht keinen Bösewicht. Es braucht nur genug Reibung, damit "genehmigungsfrei" zu "es funktioniert… wenn es funktioniert" wird.
Und sobald das Servieren intermittierend wird, ist das einzige, was die Benutzer erleben, was sie jetzt abrufen können. Nicht das, was rekonstruiert werden kann. Nicht das, was "verfügbar sein sollte". Nur das, was in der Realität lädt.
Jetzt tauchen die unangenehmen Fragen spät in der falschen Sitzung auf.
Ist das nur ein Wechsel, oder sind wir in einen Zustand geraten, in dem einige Inhalte effektiv schwieriger abzurufen sind als andere Inhalte?
Wenn ein Partner fragt "ist es verfügbar"... antworten wir dann mit Beweisen oder mit Stimmung?
Walross ist auf praktische Weise nervig... die Haltbarkeit wird durch Teilnahme und Reparaturarbeit bezahlt, und du kannst diese Kosten nicht einfach beiseite schieben, wenn das Netzwerk sich etwas schmerzhaft anfühlt. Der Blob kann immer noch da sein. Die Rekonstruktion kann immer noch wahr sein.
Das Ticket bewegt sich immer noch nicht. Der Halteschritt bleibt. Niemand möchte 'verlässlich' unterschreiben und es ernst meinen, wenn der beste Satz, den du hast, ist, dass es zurückkommen sollte, wenn du weiter versuchst. Oder… es tat es für mich.
