
Quelle: Zeke, NWU Capital

Vorwort
Seit der Geburt von GPT-3 hat die generative KI mit ihrer erstaunlichen Leistung und ihren breiten Anwendungsszenarien einen explosiven Wendepunkt im Bereich der künstlichen Intelligenz eingeläutet, und Technologiegiganten haben begonnen, sich zusammenzuschließen, um in die KI-Spur einzusteigen. Aber auch das Training und die Inferenz von großen Sprachmodellen (LLM) erfordern eine große Menge an Rechenleistung. Mit der iterativen Aktualisierung des Modells steigen die Anforderungen an die Rechenleistung und die Kosten exponentiell. Am Beispiel von GPT-2 und GPT-3 beträgt der Unterschied in der Parametermenge zwischen GPT-2 und GPT-3 das 1166-fache (GPT-2 beträgt 150 Millionen Parameter und GPT-3 beträgt 175 Milliarden Parameter). GPT-3 Die Kosten wurden auf Basis des damaligen Preismodells der öffentlichen GPU-Cloud berechnet, die bis zu 12 Millionen US-Dollar betrugen, also das 200-fache von GPT-2. Im tatsächlichen Einsatz erfordert jede Benutzerfrage Inferenzberechnungen. Basierend auf den 13 Millionen einzelnen Benutzerbesuchen zu Beginn dieses Jahres beträgt der entsprechende Chipbedarf mehr als 30.000 A100-GPUs. Dann belaufen sich die anfänglichen Investitionskosten auf unglaubliche 800 Millionen US-Dollar, und die geschätzten täglichen Modellinferenzkosten belaufen sich auf 700.000 US-Dollar.
Unzureichende Rechenleistung und hohe Kosten sind zu Problemen geworden, mit denen die gesamte KI-Branche konfrontiert ist, aber die gleichen Probleme scheinen auch die Blockchain-Branche zu plagen. Einerseits steht die vierte Halbierung von Bitcoin und die ETF-Zulassung kurz bevor, da die Preise in Zukunft steigen, und die Nachfrage der Bergleute nach Computerhardware wird zwangsläufig deutlich steigen. Andererseits boomt die „Zero-Knowledge Proof“ (ZKP)-Technologie. Vitalik hat wiederholt betont, dass der Einfluss von ZK auf den Blockchain-Bereich in den nächsten zehn Jahren genauso wichtig sein wird wie die Blockchain selbst. Obwohl die Blockchain-Industrie große Hoffnungen in die Zukunft dieser Technologie setzt, verbraucht ZK aufgrund seines komplexen Berechnungsprozesses ebenso wie KI viel Rechenleistung und Zeit bei der Erstellung von Beweisen.
In absehbarer Zeit wird der Mangel an Rechenleistung unvermeidlich sein. Wird der dezentrale Rechenleistungsmarkt also ein gutes Geschäft sein?
Definition des Marktes für dezentrale Rechenleistung
Der dezentrale Rechenleistungsmarkt entspricht eigentlich im Grunde dem dezentralen Cloud-Computing-Bereich, aber im Vergleich zum dezentralen Cloud-Computing halte ich persönlich diesen Begriff für angemessener, um die später besprochenen neuen Projekte zu beschreiben. Der dezentrale Rechenleistungsmarkt sollte zu einer Teilmenge von DePIN (Decentralized Physical Infrastructure Network) gehören. Sein Ziel ist es, einen offenen Rechenleistungsmarkt zu schaffen, der es jedem mit ungenutzten Rechenleistungsressourcen ermöglicht, Token-Anreize zu nutzen. hauptsächlich für B-End-Benutzer und Entwicklergruppen. In Bezug auf bekannte Projekte wie Render Network, ein dezentrales GPU-basiertes Rendering-Lösungsnetzwerk, und Akash Network, ein verteilter Peer-to-Peer-Markt für Cloud Computing, gehören beide zu diesem Track.
Im Folgenden wird mit den Grundkonzepten begonnen und anschließend auf die drei aufstrebenden Märkte in diesem Bereich eingegangen: der AGI-Rechenleistungsmarkt, der Bitcoin-Rechenleistungsmarkt und der AGI-Rechenleistungsmarkt im ZK-Hardwarebeschleunigungsmarkt. Die beiden letzteren werden berücksichtigt (Mögliche Track-Vorschau: Dezentraler Rechenleistungsmarkt (Teil 2) wird besprochen.
Überblick über die Rechenleistung
Der Ursprung des Konzepts der Rechenleistung lässt sich auf den Beginn der Erfindung des Computers zurückführen. Der ursprüngliche Computer verwendete ein mechanisches Gerät, um Rechenaufgaben auszuführen, und Rechenleistung bezieht sich auf die Rechenleistung des mechanischen Geräts. Mit der Entwicklung der Computertechnologie hat sich auch das Konzept der Rechenleistung weiterentwickelt. Unter heutiger Rechenleistung versteht man üblicherweise die Zusammenarbeit von Computerhardware (CPU, GPU, FPGA usw.) und Software (Betriebssystem, Compiler, Anwendungsprogramm usw.). .) Fähigkeit.
Definition
Unter Rechenleistung versteht man die Datenmenge, die ein Computer oder ein anderes Computergerät verarbeiten kann, bzw. die Anzahl der innerhalb eines bestimmten Zeitraums erledigten Rechenaufgaben. Mit Rechenleistung wird üblicherweise die Leistung eines Computers oder eines anderen Computergeräts beschrieben. Sie ist ein wichtiger Indikator für die Rechenleistung eines Computergeräts.
messen
Die Rechenleistung kann auf verschiedene Arten gemessen werden, beispielsweise durch Rechengeschwindigkeit, Rechenenergieverbrauch, Rechengenauigkeit und Parallelität. Zu den im Computerbereich häufig verwendeten Indikatoren zur Messung der Rechenleistung gehören FLOPS (Gleitkommaoperationen pro Sekunde), IPS (Anweisungen pro Sekunde), TPS (Transaktionen pro Sekunde) usw.
FLOPS (Gleitkommaoperationen pro Sekunde) bezieht sich auf die Fähigkeit des Computers, Gleitkommaoperationen zu verarbeiten (mathematische Operationen mit Zahlen mit Dezimalstellen, die Überlegungen wie Präzisionsprobleme und Rundungsfehler erfordern). Sie messen, wie viel der Computer pro Sekunde ausführen kann . Gleitkommaoperationen. FLOPS ist ein Maß für die Hochleistungsrechenfähigkeiten eines Computers und wird üblicherweise zur Messung der Rechenfähigkeiten von Supercomputern, Hochleistungsrechenservern und Grafikprozessoren (GPUs) verwendet. Beispielsweise hat ein Computersystem einen FLOPS von 1 TFLOPS (eine Billion Gleitkommaoperationen pro Sekunde), was bedeutet, dass es 1 Billion Gleitkommaoperationen pro Sekunde ausführen kann.
IPS (Instructions Per Second) bezieht sich auf die Geschwindigkeit, mit der ein Computer Anweisungen verarbeitet. Es ist ein Maß dafür, wie viele Anweisungen ein Computer pro Sekunde ausführen kann. IPS ist ein Maß für die Leistung einzelner Computerbefehle und wird normalerweise zur Messung der Leistung von Zentraleinheiten (CPUs) usw. verwendet. Beispielsweise bedeutet eine CPU mit einem IPS von 3 GHz (300 Millionen Anweisungen pro Sekunde), dass sie 300 Millionen Anweisungen pro Sekunde ausführen kann.
TPS (Transaktionen pro Sekunde) bezieht sich auf die Fähigkeit eines Computers, Transaktionen zu verarbeiten. Es misst, wie viele Transaktionen ein Computer pro Sekunde abschließen kann. Wird normalerweise zur Messung der Datenbankserverleistung verwendet. Ein Datenbankserver hat beispielsweise einen TPS von 1000, was bedeutet, dass er 1000 Datenbanktransaktionen pro Sekunde verarbeiten kann.
Darüber hinaus gibt es einige Rechenleistungsindikatoren für bestimmte Anwendungsszenarien, wie z. B. Inferenzgeschwindigkeit, Bildverarbeitungsgeschwindigkeit und Spracherkennungsgenauigkeit.
Art der Rechenleistung
Unter GPU-Rechenleistung versteht man die Rechenleistung des Grafikprozessors (Graphics Processing Unit). Im Gegensatz zur CPU (Central Processing Unit) handelt es sich bei der GPU um Hardware, die speziell für die Verarbeitung von Grafikdaten wie Bildern und Videos entwickelt wurde. Sie verfügt über eine große Anzahl von Verarbeitungseinheiten und effiziente parallele Rechenfunktionen und kann eine große Anzahl von Gleitkommaoperationen ausführen zur gleichen Zeit. Da GPUs ursprünglich für die Grafikverarbeitung in Spielen verwendet wurden, verfügen sie im Allgemeinen über höhere Taktfrequenzen und eine größere Speicherbandbreite als CPUs, um komplexe Grafikvorgänge zu unterstützen.
Der Unterschied zwischen CPU und GPU
Architektur: Die Rechenarchitektur von CPU und GPU ist unterschiedlich. CPUs verwenden typischerweise einen oder mehrere Kerne, von denen jeder ein Allzweckprozessor ist, der eine Vielzahl unterschiedlicher Vorgänge ausführen kann. Die GPU verfügt über eine große Anzahl von Stream-Prozessoren und Shadern, die speziell für die Ausführung von Vorgängen im Zusammenhang mit der Bildverarbeitung verwendet werden.
Paralleles Rechnen: GPUs verfügen im Allgemeinen über höhere parallele Rechenfähigkeiten. Die CPU verfügt über eine begrenzte Anzahl von Kernen, und jeder Kern kann nur eine Anweisung ausführen. Die GPU kann jedoch über Tausende von Stream-Prozessoren verfügen, die mehrere Anweisungen und Operationen gleichzeitig ausführen können. Daher eignen sich GPUs im Allgemeinen besser als CPUs, um parallele Rechenaufgaben auszuführen, wie z. B. maschinelles Lernen und Deep Learning, die ein hohes Maß an parallelem Rechnen erfordern.
Programmierung: Die GPU-Programmierung ist komplexer als die CPU-Programmierung und erfordert die Verwendung spezifischer Programmiersprachen (wie CUDA oder OpenCL) und spezifischer Programmiertechniken, um die parallelen Rechenfunktionen der GPU zu nutzen. Im Gegensatz dazu ist die CPU-Programmierung einfacher und es können allgemeine Programmiersprachen und Programmiertools verwendet werden.
Die Bedeutung der Rechenleistung
Im Zeitalter der industriellen Revolution war Öl das Blut der Welt und drang in jede Industrie ein. Die Rechenleistung steckt in der Blockchain, und im kommenden KI-Zeitalter wird die Rechenleistung das „digitale Öl“ der Welt sein. Von der hektischen Suche großer Unternehmen nach KI-Chips und Nvidias Aktien, die eine Billion übersteigen, bis hin zur jüngsten US-Blockade von High-End-Chips aus China, der detaillierten Angaben zur Rechenleistung, der Chipfläche und sogar zu Plänen, die GPU-Cloud zu verbieten, ist ihre Bedeutung selbstverständlich -Es ist offensichtlich, dass Rechenleistung in der nächsten Ära eine Ware sein wird.

Ein Überblick über künstliche allgemeine Intelligenz
Künstliche Intelligenz (Künstliche Intelligenz) ist eine neue technische Wissenschaft, die Theorien, Methoden, Technologien und Anwendungssysteme zur Simulation, Erweiterung und Erweiterung der menschlichen Intelligenz untersucht und entwickelt. Es entstand in den 1950er und 1960er Jahren und hat nach mehr als einem halben Jahrhundert die Entwicklung von drei Wellen von Symbolismus, Konnektionismus und Verhaltensthemen erlebt Leben und alle Lebensbereiche. Eine spezifischere Definition der gängigen generativen KI in dieser Phase lautet: Künstliche allgemeine Intelligenz (AGI), ein künstliches Intelligenzsystem mit einem breiten Spektrum an Verständnisfähigkeiten, das in einer Vielzahl unterschiedlicher Aufgaben und Bereiche gute Leistungen erbringen kann . AGI erfordert im Wesentlichen drei Elemente: Deep Learning (DL), Big Data und große Rechenleistung.
tiefes Lernen
Deep Learning ist ein Teilgebiet des maschinellen Lernens (ML), und Deep-Learning-Algorithmen sind neuronale Netze, die dem menschlichen Gehirn nachempfunden sind. Beispielsweise enthält das menschliche Gehirn Millionen miteinander verbundener Neuronen, die zusammenarbeiten, um Informationen zu lernen und zu verarbeiten. Ebenso bestehen Deep-Learning-Neuronale Netze (oder künstliche Neuronale Netze) aus mehreren Schichten künstlicher Neuronen, die in einem Computer zusammenarbeiten. Künstliche Neuronen sind Softwaremodule, sogenannte Knoten, die mathematische Berechnungen zur Datenverarbeitung verwenden. Künstliche neuronale Netze sind Deep-Learning-Algorithmen, die diese Knoten zur Lösung komplexer Probleme nutzen.
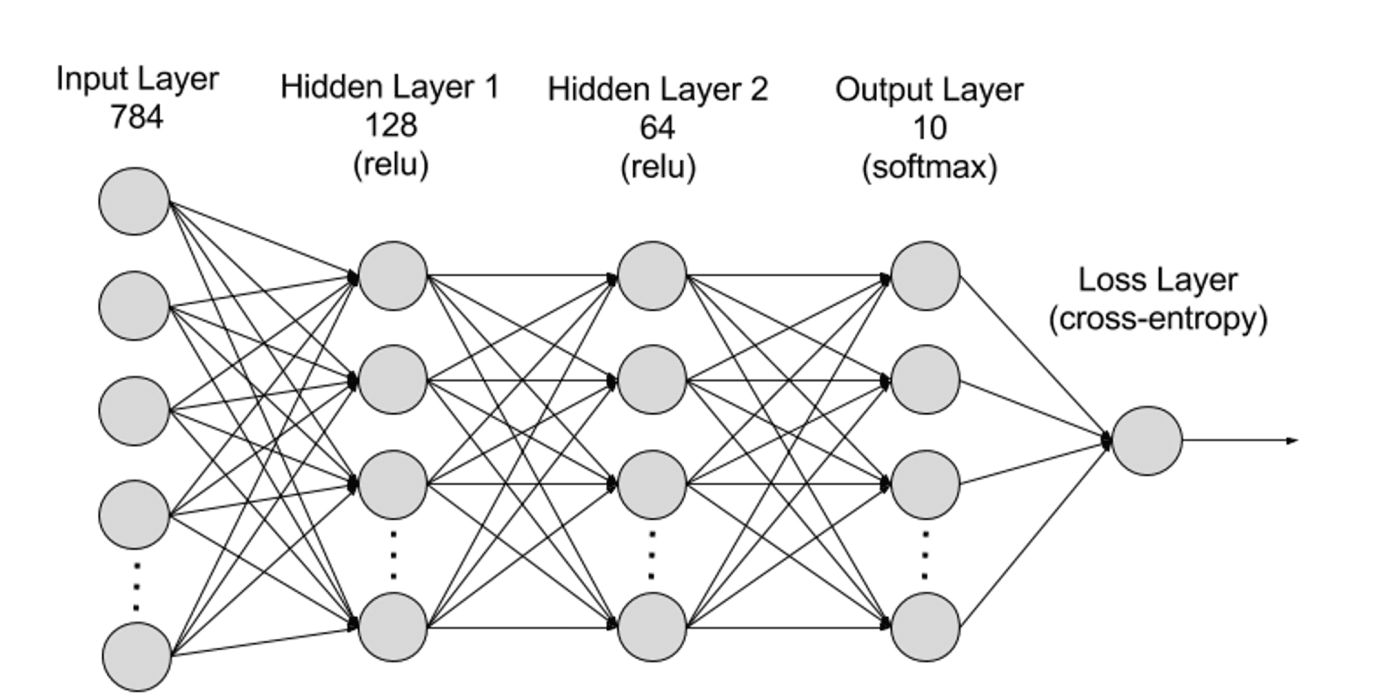
Neuronale Netze können auf einer hierarchischen Ebene in Eingabeschicht, verborgene Schicht und Ausgabeschicht unterteilt werden, und die Parameter sind zwischen verschiedenen Schichten verbunden.
Eingabeschicht: Die Eingabeschicht ist die erste Schicht des neuronalen Netzwerks und für den Empfang externer Eingabedaten verantwortlich. Jedes Neuron in der Eingabeschicht entspricht einem Merkmal der Eingabedaten. Bei der Verarbeitung von Bilddaten kann beispielsweise jedes Neuron einem Pixelwert im Bild entsprechen;
Verborgene Schichten: Die Eingabeschicht verarbeitet Daten und leitet sie an weitere Schichten im neuronalen Netzwerk weiter. Diese verborgenen Schichten verarbeiten Informationen auf verschiedenen Ebenen und passen ihr Verhalten an, wenn sie neue Informationen erhalten. Deep-Learning-Netzwerke verfügen über Hunderte verborgener Schichten und können zur Analyse von Problemen aus vielen verschiedenen Perspektiven verwendet werden. Wenn Sie beispielsweise ein Bild eines unbekannten Tieres erhalten, das Sie klassifizieren müssen, können Sie es mit Tieren vergleichen, die Sie bereits kennen. Um welche Art von Tier es sich handelt, können Sie beispielsweise anhand der Form seiner Ohren, der Anzahl seiner Beine und der Größe seiner Pupillen erkennen. Verborgene Schichten in tiefen neuronalen Netzen funktionieren auf die gleiche Weise. Wenn ein Deep-Learning-Algorithmus versucht, ein Bild eines Tieres zu klassifizieren, verarbeitet jede seiner verborgenen Schichten ein anderes Merkmal des Tieres und versucht, es genau zu klassifizieren.
Ausgabeschicht: Die Ausgabeschicht ist die letzte Schicht des neuronalen Netzwerks und für die Erzeugung der Ausgabe des Netzwerks verantwortlich. Jedes Neuron in der Ausgabeschicht repräsentiert eine mögliche Ausgabekategorie oder einen möglichen Ausgabewert. Beispielsweise kann bei einem Klassifizierungsproblem jedes Neuron der Ausgabeschicht einer Kategorie entsprechen, während bei einem Regressionsproblem die Ausgabeschicht möglicherweise nur ein Neuron hat, dessen Wert das Vorhersageergebnis darstellt;
Parameter: In neuronalen Netzwerken werden die Verbindungen zwischen verschiedenen Schichten durch Gewichtungs- und Bias-Parameter dargestellt, die während des Trainingsprozesses optimiert werden, damit das Netzwerk Muster in den Daten genau identifizieren und Vorhersagen treffen kann. Die Erhöhung der Parameter kann die Modellkapazität des neuronalen Netzwerks verbessern, d. h. die Fähigkeit des Modells, komplexe Muster in den Daten zu lernen und darzustellen. Aber entsprechend erhöht die Erhöhung der Parameter den Bedarf an Rechenleistung.
Big Data
Um effektiv trainiert zu werden, benötigen neuronale Netze in der Regel große Mengen unterschiedlicher und qualitativ hochwertiger Daten aus mehreren Quellen. Es ist die Grundlage für das Training und die Validierung von Modellen für maschinelles Lernen. Durch die Analyse großer Datenmengen können maschinelle Lernmodelle Muster und Beziehungen in den Daten lernen, um Vorhersagen oder Klassifizierungen zu treffen.
Große Rechenleistung
Die mehrschichtige komplexe Struktur des neuronalen Netzwerks, eine große Anzahl von Parametern, große Datenverarbeitungsanforderungen und iterative Trainingsmethoden (in der Trainingsphase muss das Modell wiederholt iteriert werden, und die Vorwärtsausbreitung und Rückausbreitung müssen wiederholt werden). Während des Trainingsprozesses wird es für jede Schicht berechnet, einschließlich Aktivierungsfunktionsberechnung, Verlustfunktionsberechnung und Gradient Berechnung und Gewichtsaktualisierung), hochpräzise Rechenanforderungen, parallele Rechenfunktionen, Optimierungs- und Regularisierungstechnologien sowie Modellevaluierungs- und Verifizierungsprozesse haben gemeinsam zu einem Bedarf an hoher Rechenleistung geführt. Mit der Weiterentwicklung des Deep Learning hat AGI die Kraftanforderungen etwa zehnmal pro Jahr erhöhen. Das neueste Modell GPT-4 enthält bisher 1,8 Billionen Parameter, die Kosten für ein einzelnes Training übersteigen 60 Millionen US-Dollar und die erforderliche Rechenleistung beträgt 2,15e25 FLOPS (21500 Billionen Gleitkommaberechnungen). Der Bedarf an Rechenleistung für das anschließende Modelltraining steigt immer weiter und es kommen auch neue Modelle hinzu.
Ökonomie der KI-Rechenleistung
zukünftige Marktgröße
Nach den maßgeblichsten Berechnungen hat das internationale Datenunternehmen IDC (International Data (2022-2023 Global Computing Power Index Assessment Report), gemeinsam zusammengestellt von Inspur Corporation, Inspur Information und dem Tsinghua University Global Industry Research Institute, wird die Größe des globalen KI-Computing-Marktes von 19,50 Milliarden US-Dollar im Jahr 2022 auf 34,66 Milliarden US-Dollar im Jahr 2026 wachsen Die Marktgröße für generatives KI-Computing wird von 820 Millionen US-Dollar im Jahr 2022 auf 10,99 Milliarden US-Dollar im Jahr 2026 wachsen. Der Anteil des generativen KI-Computings am gesamten KI-Computing-Markt wird von 4,2 % auf 31,7 % wachsen.
Wirtschaftsmonopol der Rechenleistung
Die Produktion von KI-GPUs wurde ausschließlich von NVIDA monopolisiert und ist extrem teuer (der neueste H100 wurde für 40.000 US-Dollar pro Chip verkauft), und die GPUs wurden sofort nach ihrer Veröffentlichung von den Giganten des Silicon Valley aufgekauft werden in eigenen neuen Modellschulungen eingesetzt. Der andere Teil wird über Cloud-Plattformen an KI-Entwickler vermietet. Cloud-Computing-Plattformen wie Google, Amazon und Microsoft beherrschen eine große Anzahl von Rechenressourcen wie Server, GPUs und TPUs. Rechenleistung ist zu einer neuen Ressource geworden, die von Giganten monopolisiert wird. Viele KI-Entwickler können nicht einmal eine dedizierte GPU kaufen, ohne die neuesten Geräte zu nutzen. Um die neueste Ausrüstung nutzen zu können, müssen Entwickler Cloud-Server von AWS oder Microsoft mieten. Dem Finanzbericht zufolge erzielt dieses Unternehmen extrem hohe Gewinne. Der Cloud-Service von AWS weist eine Bruttogewinnspanne von 61 % auf, während die Bruttogewinnspanne von Microsoft mit 72 % sogar noch höher ist.

Müssen wir also diese zentralisierte Autorität und Kontrolle akzeptieren und 72 % der Gewinngebühr für Computerressourcen zahlen? Werden die Giganten, die Web2 monopolisieren, auch in der nächsten Ära weiterhin monopolisieren?
Das Problem der dezentralen AGI-Rechenleistung
Wenn es um Kartellrecht geht, ist Dezentralisierung normalerweise die optimale Lösung. Können wir angesichts der bestehenden Projekte die für KI erforderliche große Rechenleistung durch das Speicherprojekt in DePIN plus ein Protokoll zur Nutzung ungenutzter GPUs wie RDNR erreichen? Die Antwort lautet: Nein. Der Weg, den Drachen zu töten, ist nicht so einfach. Frühe Projekte waren nicht speziell auf AGI-Rechenleistung ausgelegt und waren nicht realisierbar.
1. Arbeitsüberprüfung: Um ein wirklich vertrauenswürdiges Computernetzwerk aufzubauen und den Teilnehmern wirtschaftliche Anreize zu bieten, muss das Netzwerk über eine Möglichkeit verfügen, zu überprüfen, ob die Deep-Learning-Computerarbeit tatsächlich ausgeführt wird. Der Kern dieses Problems ist die Zustandsabhängigkeit von Deep-Learning-Modellen; in Deep-Learning-Modellen hängt die Eingabe jeder Schicht von der Ausgabe der vorherigen Schicht ab. Das bedeutet, dass Sie nicht einfach eine bestimmte Ebene in einem Modell validieren können, ohne alle davor liegenden Ebenen zu berücksichtigen. Die Berechnung jeder Schicht basiert auf den Ergebnissen aller vorherigen Schichten. Um die an einem bestimmten Punkt (z. B. einer bestimmten Ebene) geleistete Arbeit zu überprüfen, müssen daher alle Arbeiten vom Beginn des Modells bis zu diesem bestimmten Punkt ausgeführt werden.
2. Markt: Als aufstrebender Markt unterliegt der Markt für KI-Rechenleistung Angebots- und Nachfragedilemmata, wie z. B. dem Kaltstartproblem. Angebot und Nachfrageliquidität müssen von Anfang an ungefähr übereinstimmen, damit der Markt erfolgreich wachsen kann . Um das potenzielle Angebot an Rechenleistung zu nutzen, müssen den Teilnehmern im Austausch für ihre Rechenleistungsressourcen klare Anreize geboten werden. Der Markt benötigt einen Mechanismus, um abgeschlossene Rechenarbeiten zu verfolgen und Anbieter zeitnah entsprechend zu bezahlen. Auf traditionellen Marktplätzen übernehmen Vermittler Aufgaben wie Verwaltung und Onboarding und senken gleichzeitig die Betriebskosten durch die Festlegung von Mindestzahlungsbeträgen. Allerdings ist dieser Ansatz bei einer Ausweitung des Marktes kostspieliger. Nur ein kleiner Teil des Angebots kann wirtschaftlich effizient erfasst werden, was zu einem Schwellengleichgewichtszustand führt, in dem der Markt nur ein begrenztes Angebot erfassen und aufrechterhalten kann, ohne weiter wachsen zu können;
3. Halteproblem: Das Halteproblem ist ein grundlegendes Problem in der Computertheorie, bei dem es darum geht, zu bestimmen, ob eine bestimmte Rechenaufgabe innerhalb einer begrenzten Zeit abgeschlossen werden kann oder nie aufhört. Dieses Problem ist unlösbar, das heißt, es gibt keinen universellen Algorithmus, der für alle Rechenaufgaben vorhersagen kann, ob sie innerhalb einer endlichen Zeit beendet werden. Beispielsweise ist auch die Ausführung intelligenter Verträge auf Ethereum mit ähnlichen Ausfallzeiten konfrontiert. Das heißt, es ist unmöglich, im Voraus zu bestimmen, wie viel Rechenressourcen die Ausführung eines Smart Contracts erfordern wird oder ob er innerhalb einer angemessenen Zeit abgeschlossen werden wird;
(Im Kontext von Deep Learning wird dieses Problem komplexer, da Modelle und Frameworks von der statischen Graphkonstruktion zur dynamischen Konstruktion und Ausführung wechseln werden.)
4. Datenschutz: Datenschutzbewusstes Design und Entwicklung sind für Projektbeteiligte ein Muss. Obwohl ein großer Teil der maschinellen Lernforschung an öffentlichen Datensätzen durchgeführt werden kann, muss das Modell zur Verbesserung der Leistung des Modells und zur Anpassung an bestimmte Anwendungen normalerweise anhand proprietärer Benutzerdaten verfeinert werden. Dieser Feinabstimmungsprozess kann die Verarbeitung personenbezogener Daten beinhalten, daher müssen Datenschutzanforderungen berücksichtigt werden;
5. Parallelisierung: Dies ist ein Schlüsselfaktor, der das aktuelle Projekt undurchführbar macht. Deep-Learning-Modelle werden normalerweise parallel auf großen Hardware-Clustern mit proprietärer Architektur und extrem geringer Latenz trainiert, und GPUs in verteilten Computernetzwerken müssen häufigen Datenaustausch einführen Latenz und wird durch die GPU mit der niedrigsten Leistung begrenzt. Wenn die Rechenleistungsquelle nicht vertrauenswürdig und unzuverlässig ist, muss die Frage gelöst werden, wie eine heterogene Parallelisierung erreicht werden kann. Die derzeit praktikable Methode besteht darin, die Parallelisierung über das Transformatormodell zu erreichen, z.
Lösung: Obwohl sich der aktuelle Versuch, den AGI-Rechenleistungsmarkt zu dezentralisieren, noch in einem frühen Stadium befindet, gibt es genau zwei Projekte, die zunächst das Konsensdesign dezentraler Netzwerke und die Implementierung dezentraler Rechenleistungsnetzwerke im Modelltrainings- und Inferenzprozess gelöst haben . Im Folgenden werden Gensyn und Together als Beispiele verwendet, um die Entwurfsmethoden und Probleme des dezentralen AGI-Rechenleistungsmarktes zu analysieren.
Noch einmal besuchen

Gensyn ist ein AGI-Rechenleistungsmarkt, der sich noch im Aufbaustadium befindet und darauf abzielt, die verschiedenen Herausforderungen des dezentralen Deep-Learning-Computings zu lösen und die aktuellen Kosten des Deep-Learning zu senken. Gensyn ist im Wesentlichen ein First-Layer-Proof-of-Stake-Protokoll, das auf dem Polkadot-Netzwerk basiert und Löser (Solver) direkt über intelligente Verträge im Austausch für ihre ungenutzte GPU-Ausrüstung für die Berechnung und Durchführung maschineller Lernaufgaben belohnt.
Zurück zur obigen Frage: Der Kern des Aufbaus eines wirklich vertrauenswürdigen Computernetzwerks liegt in der Überprüfung der abgeschlossenen maschinellen Lernarbeit. Hierbei handelt es sich um ein hochkomplexes Problem, das ein Gleichgewicht zwischen der Schnittstelle zwischen Komplexitätstheorie, Spieltheorie, Kryptographie und Optimierung erfordert.
Gensyn schlägt Lösern eine einfache Lösung vor, mit der sie die Ergebnisse abgeschlossener maschineller Lernaufgaben übermitteln können. Um zu überprüfen, ob diese Ergebnisse korrekt sind, versucht ein anderer unabhängiger Prüfer, die gleiche Arbeit noch einmal durchzuführen. Dieser Ansatz kann als Einzelreplikation bezeichnet werden, da nur ein Validator die erneute Ausführung durchführt. Dies bedeutet, dass nur ein zusätzlicher Aufwand erforderlich ist, um die Richtigkeit der Originalarbeit zu überprüfen. Wenn die Person, die das Werk validiert, jedoch nicht der Antragsteller des Originalwerks ist, bleiben Vertrauensprobleme bestehen. Weil die Prüfer selbst möglicherweise nicht ehrlich sind und ihre Arbeit überprüft werden muss. Dies führt zu einem potenziellen Problem: Wenn die Person, die die Arbeit validiert, nicht der Antragsteller der ursprünglichen Arbeit ist, wird ein anderer Validator benötigt, um ihre Arbeit zu validieren. Es ist aber auch möglich, dass dieser neue Validator nicht vertrauenswürdig ist, sodass ein anderer Validator benötigt wird, um seine Arbeit zu überprüfen, was ewig dauern und eine unendliche Replikationskette erzeugen könnte. Hier müssen wir drei Schlüsselkonzepte einführen und sie miteinander verknüpfen, um ein Teilnehmersystem mit vier Rollen aufzubauen, um das Problem der unendlichen Kette zu lösen.
Beweise für probabilistisches Lernen: Nutzen Sie Metadaten von Gradienten-basierten Optimierungsprozessen, um Zertifikate über geleistete Arbeit zu erstellen. Durch die Replikation bestimmter Phasen können diese Zertifikate schnell überprüft werden, um sicherzustellen, dass die Arbeiten wie erwartet abgeschlossen wurden.
Diagrammbasiertes präzises Lokalisierungsprotokoll: Verwendung von diagrammbasierten präzisen Lokalisierungsprotokollen mit mehreren Granularitäten und konsistenter Ausführung von Kreuzauswertern. Dadurch können Validierungsbemühungen erneut durchgeführt und verglichen werden, um die Konsistenz sicherzustellen und letztendlich von der Blockchain selbst bestätigt zu werden.
Incentive-Spiel im Truebit-Stil: Nutzen Sie Einsätze und Slashing, um ein Incentive-Spiel zu erstellen, das sicherstellt, dass jeder finanziell vernünftige Teilnehmer ehrlich handelt und seine beabsichtigten Aufgaben erfüllt.
Das Teilnehmersystem besteht aus Einreichern, Lösern, Prüfern und Reportern.
Einsender:
Einreicher sind Endbenutzer des Systems, die zu berechnende Aufgaben bereitstellen und für abgeschlossene Arbeitseinheiten bezahlen.
Löser:
Der Solver ist der Hauptarbeiter des Systems, der das Modelltraining durchführt und Beweise generiert, die vom Verifizierer überprüft werden;
Prüfer:
Der Verifizierer ist der Schlüssel zur Verknüpfung des nichtdeterministischen Trainingsprozesses mit der deterministischen linearen Berechnung, indem er einen Teil des Beweises des Lösers repliziert und Entfernungen mit erwarteten Schwellenwerten vergleicht;
Whistleblower:
Whistleblower sind die letzte Verteidigungslinie, sie überprüfen die Arbeit der Validatoren und stellen Anfechtungen in der Hoffnung, großzügige Kopfgeldzahlungen zu erhalten.
Systembetrieb
Der Betrieb des durch das Protokoll entworfenen Spielsystems umfasst acht Phasen, die vier Hauptteilnehmerrollen abdecken, um den gesamten Prozess von der Aufgabenübermittlung bis zur endgültigen Überprüfung abzuschließen.
Aufgabenübermittlung: Eine Aufgabe besteht aus drei spezifischen Informationen:
Metadaten, die die Aufgabe und Hyperparameter beschreiben;
eine Modellbinärdatei (oder ein Basisschema);
Öffentlich zugängliche, vorverarbeitete Trainingsdaten.
Um eine Aufgabe einzureichen, gibt der Einreicher die Details der Aufgabe in einem maschinenlesbaren Format an und übermittelt sie zusammen mit der Modellbinärdatei (oder dem maschinenlesbaren Schema) und einem öffentlich zugänglichen Speicherort der vorverarbeiteten Trainingsdaten an die Kette. Öffentliche Daten können in einem einfachen Objektspeicher wie AWS S3 oder in einem dezentralen Speicher wie IPFS, Arweave oder Subspace gespeichert werden.
Profiling: Der Profiling-Prozess bestimmt einen Basisentfernungsschwellenwert für den Lernnachweis. Validatoren crawlen regelmäßig Analyseaufgaben und generieren Mutationsschwellenwerte für Proof-of-Learning-Vergleiche. Um den Schwellenwert zu generieren, führt der Verifizierer einen Teil des Trainings deterministisch aus und wiederholt ihn unter Verwendung verschiedener Zufallsstartwerte und generiert und überprüft seine eigenen Beweise. Während dieses Prozesses legt der Verifizierer einen insgesamt erwarteten Entfernungsschwellenwert für nicht deterministische Arbeiten fest, der als Verifizierungslösung verwendet werden kann.
Training: Nach der Analyse gelangen Aufgaben in einen öffentlichen Aufgabenpool (ähnlich dem Mempool von Ethereum). Wählen Sie einen Solver zur Ausführung der Aufgabe aus und entfernen Sie die Aufgabe aus dem Aufgabenpool. Der Solver führt Aufgaben basierend auf den vom Einreicher übermittelten Metadaten und den bereitgestellten Modell- und Trainingsdaten aus. Bei der Durchführung von Trainingsaufgaben generiert der Solver auch Lernnachweise, indem er regelmäßig Metadaten aus dem Trainingsprozess, einschließlich Parametern, mit Prüfpunkten versehen und speichert, damit der Verifizierer die folgenden Optimierungsschritte so genau wie möglich repliziert.
Beweisgenerierung: Der Solver speichert regelmäßig Modellgewichte oder -aktualisierungen und ihre entsprechenden Indizes im Trainingsdatensatz, um die Stichproben zu identifizieren, die zum Generieren der Gewichtsaktualisierungen verwendet werden. Die Checkpoint-Frequenz kann angepasst werden, um stärkere Garantien zu bieten oder Speicherplatz zu sparen. Beweise können „gestapelt“ werden, was bedeutet, dass die Beweise von einer Zufallsverteilung ausgehen können, die zur Initialisierung der Gewichte verwendet wird, oder von vorab trainierten Gewichten, die mithilfe ihrer eigenen Beweise generiert wurden. Dadurch kann das Protokoll eine Reihe bewährter, vorab trainierter Basismodelle (d. h. Basismodelle) erstellen, die für spezifischere Aufgaben feinabgestimmt werden können.
Überprüfung des Beweises: Nachdem die Aufgabe abgeschlossen ist, registriert der Löser den Abschluss der Aufgabe in der Kette und zeigt seinen Lernnachweis an einem öffentlich zugänglichen Ort an, damit Prüfer darauf zugreifen können. Der Verifizierer bezieht Verifizierungsaufgaben aus einem öffentlichen Aufgabenpool und führt Rechenarbeit durch, um Teile des Beweises erneut auszuführen und Distanzberechnungen durchzuführen. Der resultierende Abstand wird dann von der Kette (zusammen mit dem während der Analysephase berechneten Schwellenwert) verwendet, um zu bestimmen, ob die Verifizierung mit dem Beweis übereinstimmt.
Diagrammbasierte, punktgenaue Herausforderung: Nach der Validierung eines Lernbeweises kann ein Whistleblower die Arbeit des Prüfers kopieren, um zu überprüfen, ob die Verifizierungsarbeit selbst korrekt durchgeführt wurde. Wenn ein Whistleblower der Meinung ist, dass die Validierung fehlerhaft durchgeführt wurde (böswillig oder nicht), kann er ihn anfechten und ein Schlichtungsverfahren einleiten, um eine Belohnung zu erhalten. Diese Belohnung kann aus Solver- und Validator-Einzahlungen (im Falle eines echten Positivs) oder aus dem Lotteriepreispool (im Falle eines falschen Positivs) stammen, wobei die Schlichtung über die Kette selbst erfolgt. Whistleblower (in ihrem Fall Prüfer) werden ihre Arbeit nur überprüfen und anschließend anfechten, wenn sie eine angemessene Entschädigung erwarten. In der Praxis bedeutet dies, dass von Whistleblowern erwartet wird, dass sie dem Netzwerk basierend auf der Anzahl anderer aktiver Whistleblower (d. h. mit Live-Einzahlungen und Herausforderungen) beitreten und es verlassen. Daher besteht die erwartete Standardstrategie für jeden Whistleblower darin, sich dem Netzwerk anzuschließen, wenn die Anzahl anderer Whistleblower gering ist, eine Einzahlung zu tätigen, zufällig eine aktive Aufgabe auszuwählen und mit dem Überprüfungsprozess zu beginnen. Nachdem die erste Aufgabe beendet ist, greifen sie zu einer weiteren zufälligen aktiven Aufgabe und wiederholen diese, bis die Anzahl der Whistleblower ihren festgelegten Auszahlungsschwellenwert überschreitet. Anschließend verlassen sie das Netzwerk (oder wechseln, je nach Hardwarefähigkeit, wahrscheinlicher zum Netzwerk, um eine weitere auszuführen). Rolle - Verifizierer oder Löser), bis sich die Situation wieder umkehrt.
Vertragsschlichtung: Wenn ein Validator von einem Whistleblower herausgefordert wird, leitet er einen Prozess mit der Kette ein, um den Ort der umstrittenen Operation oder Eingabe herauszufinden, und schließlich führt die Kette die letzte grundlegende Operation durch und stellt fest, ob die Anfechtung gerechtfertigt ist. Um Whistleblower ehrlich zu halten und das Validator-Dilemma zu überwinden, werden hier regelmäßige erzwungene Fehler und Jackpot-Auszahlungen eingeführt.
Abrechnung: Während des Abrechnungsprozesses werden die Teilnehmer auf der Grundlage der Schlussfolgerungen von Wahrscheinlichkeits- und Gewissheitsprüfungen bezahlt. In verschiedenen Szenarien gibt es unterschiedliche Zahlungen, basierend auf den Ergebnissen früherer Überprüfungen und Anfechtungen. Wenn davon ausgegangen wird, dass die Arbeit ordnungsgemäß ausgeführt wurde und alle Prüfungen bestanden wurden, werden Lösungsanbieter und Prüfer auf der Grundlage der durchgeführten Maßnahmen belohnt.
Kurzer Rückblick auf das Projekt
Gensyn hat ein wunderbares Spielsystem auf der Verifizierungs- und Anreizebene entwickelt, indem es die Divergenzpunkte im Netzwerk findet, um den Fehler schnell zu lokalisieren, aber im aktuellen System fehlen noch viele Details. Wie kann man beispielsweise Parameter festlegen, um sicherzustellen, dass Belohnungen und Strafen angemessen sind, ohne den Schwellenwert zu hoch anzusetzen? Haben Sie extreme Situationen und unterschiedliche Rechenleistungen der Löser im Spiel berücksichtigt? In der aktuellen Version des Whitepapers gibt es keine detaillierte Beschreibung des heterogenen Parallelbetriebs. Derzeit hat Gensyn noch einen langen Weg vor sich.
Gemeinsam.ai
Together ist ein Open-Source-Unternehmen, das sich auf große Modelle konzentriert und sich für dezentrale KI-Rechenleistungslösungen einsetzt. Wir hoffen, dass jeder überall auf KI zugreifen und sie nutzen kann. Streng genommen ist Together kein Blockchain-Projekt, aber das Projekt hat zunächst das Verzögerungsproblem im dezentralen AGI-Rechnernetzwerk gelöst. Daher analysiert der folgende Artikel nur die Lösung von Together und bewertet das Projekt nicht.
Wie erreicht man Training und Inferenz großer Modelle, wenn dezentrale Netzwerke 100-mal langsamer sind als Rechenzentren?
Stellen wir uns vor, wie die Verteilung der am Netzwerk teilnehmenden GPU-Geräte in einer dezentralen Situation aussehen wird. Diese Geräte werden auf verschiedenen Kontinenten und in verschiedenen Städten verteilt sein, und die Geräte müssen verbunden werden, und die Latenz und Bandbreite der Verbindungen werden variieren. Wie in der folgenden Abbildung dargestellt, wird eine verteilte Situation simuliert. Die Geräte sind in Nordamerika, Europa und Asien verteilt und die Bandbreite und Verzögerung zwischen den Geräten ist unterschiedlich. Was muss also getan werden, um es in Reihe zu schalten?
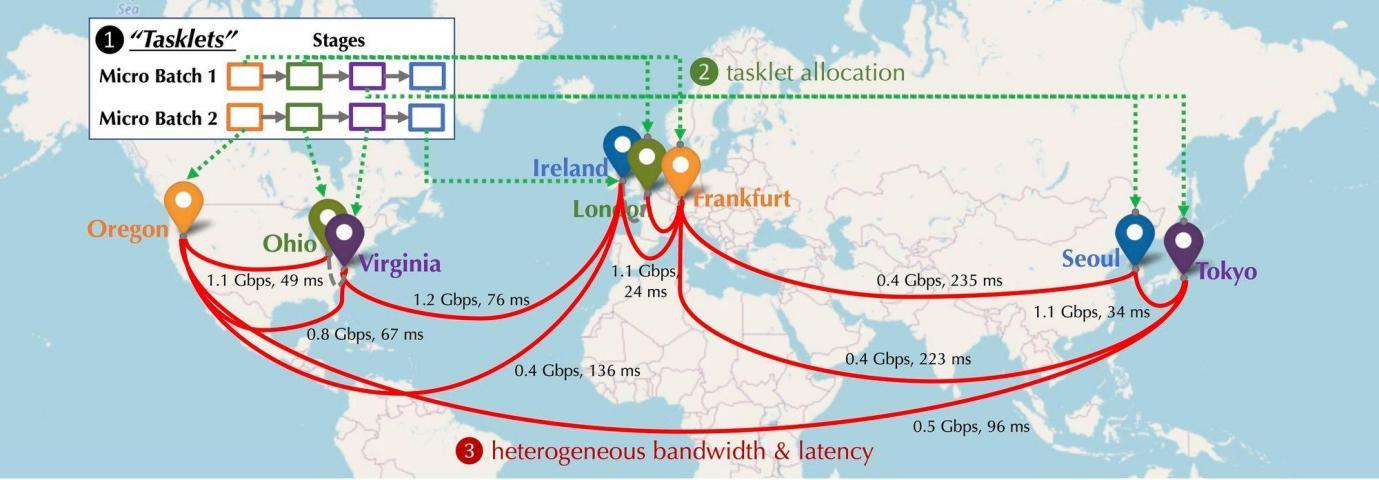
Verteilte Trainingscomputermodellierung: Die folgende Abbildung zeigt das grundlegende Modelltraining auf mehreren Geräten. Vom Kommunikationstyp gibt es drei Kommunikationstypen: Vorwärtsaktivierung (Vorwärtsaktivierung), Rückwärtsgradient (Rückwärtsgradient) und horizontale Kommunikation.
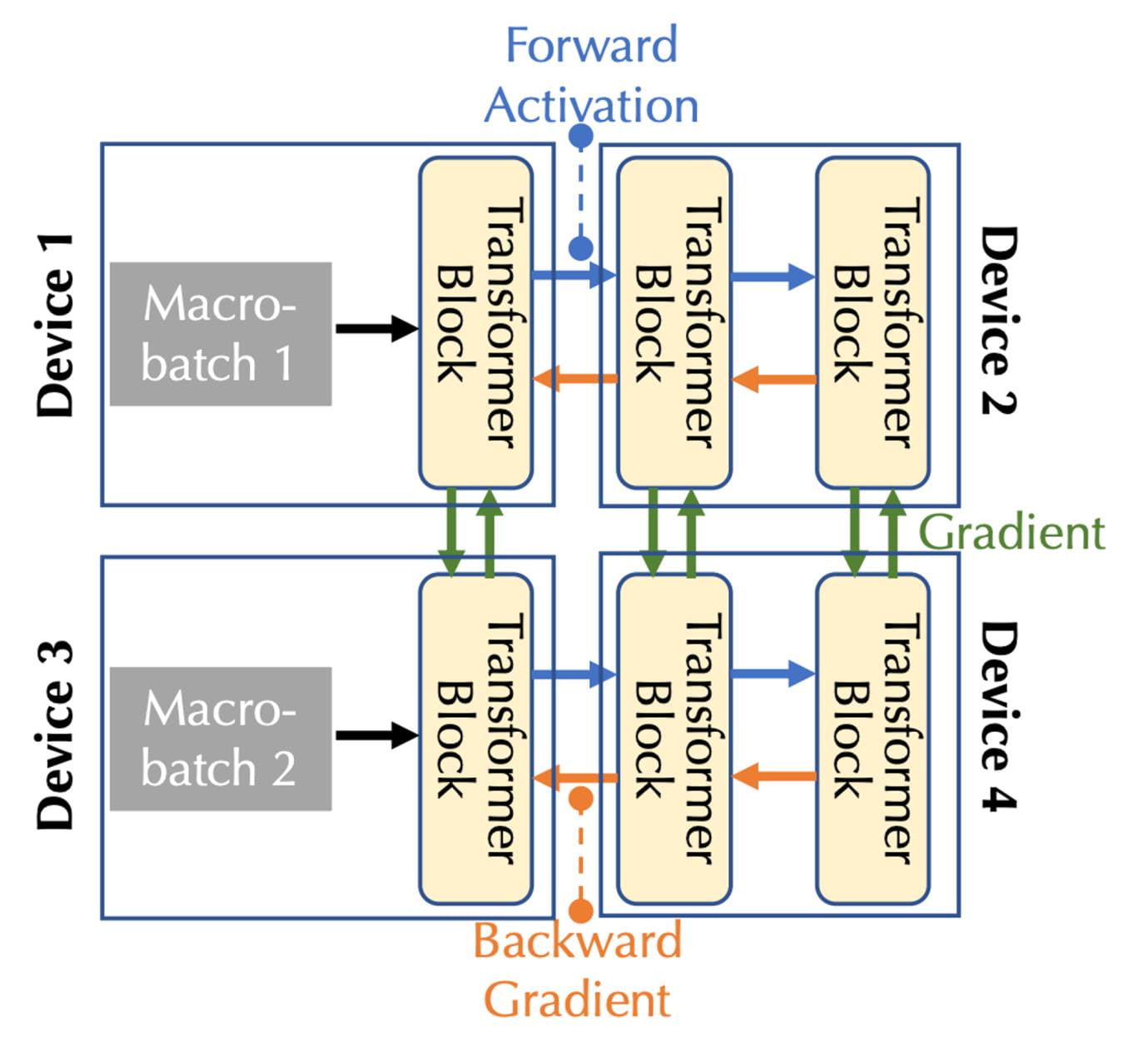
Bei der Kombination von Kommunikationsbandbreite und Latenz müssen zwei Formen der Parallelität berücksichtigt werden: Pipeline-Parallelität und Datenparallelität, entsprechend den drei Kommunikationsarten im Fall mehrerer Geräte:
Bei der Pipeline-Parallelität sind alle Schichten des Modells in Stufen unterteilt, wobei jedes Gerät eine Stufe verarbeitet, die eine kontinuierliche Abfolge von Schichten darstellt, z. B. werden im Vorwärtsdurchlauf Aktivierungen an die nächste Stufe weitergegeben, während im Rückwärtsgang Aktivierungen vorgenommen werden Pass, der Aktivierungsgradient wird an die vorherige Stufe übergeben.
Bei der Datenparallelität berechnen Geräte unabhängig voneinander Gradienten für verschiedene Mikrochargen, benötigen jedoch Kommunikation, um diese Gradienten zu synchronisieren.
Terminoptimierung:
In einer dezentralen Umgebung ist der Trainingsprozess häufig kommunikationsbeschränkt. Planungsalgorithmen weisen im Allgemeinen Aufgaben, die eine intensive Kommunikation erfordern, Geräten mit schnelleren Verbindungen zu. Unter Berücksichtigung der Abhängigkeiten zwischen Aufgaben und der Heterogenität des Netzwerks müssen zunächst die Kosten einer bestimmten Planungsstrategie modelliert werden. Um die komplexen Kommunikationskosten des Trainings des Basismodells zu erfassen, schlägt Together eine neuartige Formel vor und zerlegt das Kostenmodell mithilfe der Graphentheorie in zwei Ebenen:
Die Graphentheorie ist ein Zweig der Mathematik, der sich hauptsächlich mit den Eigenschaften und der Struktur von Graphen (Netzwerken) befasst. Ein Graph besteht aus Eckpunkten (Knoten) und Kanten (Linien, die Knoten verbinden). Der Hauptzweck der Graphentheorie besteht darin, verschiedene Eigenschaften von Graphen zu untersuchen, beispielsweise die Konnektivität von Graphen, die Farbe von Graphen und die Eigenschaften von Pfaden und Kreisläufen in Graphen.
Die erste Ebene ist eine ausgewogene Graphpartitionierung (Partitionierung der Eckpunkte des Graphen in mehrere gleich oder annähernd gleich große Teilmengen bei gleichzeitiger Minimierung der Anzahl der Kanten zwischen Teilmengen. Bei dieser Partitionierung stellt jede Teilmenge eine Partition dar und reduziert die Kommunikationskosten durch Minimierung der Kanten zwischen Partitionen) Problem, das den Kommunikationskosten der Datenparallelität entspricht.
Die zweite Ebene ist ein gemeinsames Graph-Matching- und Traveling-Salesman-Problem Eine Art Kostenminimierung oder -maximierung. Das Problem des Handlungsreisenden besteht darin, einen kürzesten Weg zu finden, der alle Knoten im Diagramm besucht, was den Kommunikationskosten der Pipeline-Parallelität entspricht. 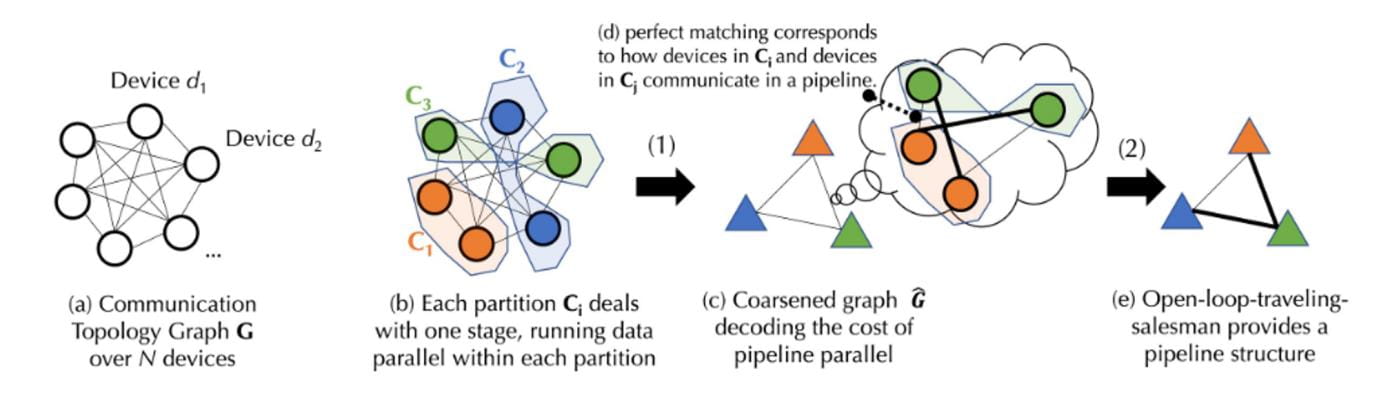
Das obige Bild ist ein schematisches Prozessdiagramm, da der eigentliche Implementierungsprozess einige komplexe Berechnungsformeln umfasst. Um das Verständnis zu erleichtern, wird der Prozess in der Abbildung im Folgenden einfacher erläutert. Den detaillierten Implementierungsprozess finden Sie in den Dokumenten auf der offiziellen Website von Together.
Angenommen, es gibt einen Gerätesatz D, der N Geräte enthält, und die Kommunikation zwischen ihnen weist eine unsichere Verzögerung (A-Matrix) und Bandbreite (B-Matrix) auf. Basierend auf dem Gerätesatz D generieren wir zunächst eine ausgeglichene Graphpartition. Die Anzahl der Geräte in jeder Partition oder Gerätegruppe ist ungefähr gleich und alle verarbeiten dieselben Pipeline-Stufen. Dadurch wird sichergestellt, dass bei der Parallelisierung der Daten jede Gerätegruppe einen ähnlichen Arbeitsaufwand verrichtet. (Datenparallelität bezieht sich auf mehrere Geräte, die dieselbe Aufgabe ausführen, während sich Pipeline-Stufen auf Geräte beziehen, die verschiedene Aufgabenschritte in einer bestimmten Reihenfolge ausführen.) Basierend auf der Latenz und Bandbreite der Kommunikation können mithilfe einer Formel die „Kosten“ für die Datenübertragung zwischen Gerätegruppen berechnet werden. Jede ausgeglichene Gerätegruppe wird zusammengeführt, wodurch ein vollständig verbundener grober Graph entsteht, in dem jeder Knoten eine Stufe der Pipeline darstellt und die Kanten die Kommunikationskosten zwischen zwei Stufen darstellen. Um die Kommunikationskosten zu minimieren, wird mithilfe eines Matching-Algorithmus ermittelt, welche Gerätegruppen zusammenarbeiten sollen.
Zur weiteren Optimierung kann dieses Problem auch als Problem des Handlungsreisenden mit offenem Regelkreis modelliert werden (offener Regelkreis bedeutet, dass keine Notwendigkeit besteht, zum Ausgangspunkt des Pfads zurückzukehren), um einen optimalen Pfad für die Datenübertragung zwischen allen Geräten zu finden. Schließlich verwendet Together seinen innovativen Planungsalgorithmus, um die optimale Zuweisungsstrategie für ein bestimmtes Kostenmodell zu finden und so die Kommunikationskosten zu minimieren und den Trainingsdurchsatz zu maximieren. Selbst wenn das Netzwerk bei dieser Planungsoptimierung 100-mal langsamer ist, ist der End-to-End-Trainingsdurchsatz laut tatsächlichen Messungen nur etwa 1,7- bis 2,3-mal langsamer.
Optimierung der Kommunikationskomprimierung:
Zur Optimierung der Kommunikationskomprimierung hat Together den AQ-SGD-Algorithmus eingeführt (einen detaillierten Berechnungsprozess finden Sie im Artikel „Feinabstimmung von Sprachmodellen über langsame Netzwerke mithilfe der Aktivierungskomprimierung mit Garantien“) der Pipeline-Parallelität in Netzwerken mit niedriger Geschwindigkeit. Eine neuartige aktive Komprimierungstechnologie, die das Kommunikationseffizienzproblem des Trainings lösen soll. Im Gegensatz zu früheren Methoden, die Aktivitätswerte direkt komprimieren, konzentriert sich AQ-SGD auf die Komprimierung der Änderungen der Aktivitätswerte derselben Trainingsstichprobe in verschiedenen Zeiträumen. Diese einzigartige Methode führt eine interessante „selbstausführende“ Dynamik ein, wenn sich das Training stabilisiert. Es wird erwartet, dass sich die Leistung des Algorithmus schrittweise verbessert. Der AQ-SGD-Algorithmus wurde einer gründlichen theoretischen Analyse unterzogen und hat bewiesen, dass er unter bestimmten technischen Bedingungen eine gute Konvergenzrate und eine quantisierte Funktion mit begrenzten Fehlern aufweist. Dieser Algorithmus kann nicht nur effizient implementiert werden, sondern verursacht auch keinen zusätzlichen End-to-End-Laufzeitaufwand, obwohl er mehr Speicher und SSD zum Speichern von Liveness-Werten erfordert. AQ-SGD wurde durch umfangreiche Experimente zur Sequenzklassifizierung und Sprachmodellierung von Datensätzen verifiziert und kann Aktivitätswerte auf 2 bis 4 Stellen komprimieren, ohne die Konvergenzleistung zu beeinträchtigen. Darüber hinaus kann AQ-SGD auch in den fortschrittlichsten Gradientenkomprimierungsalgorithmus integriert werden, um eine „End-to-End-Kommunikationskomprimierung“ zu erreichen, dh den gesamten Datenaustausch zwischen Maschinen, einschließlich Modellgradienten, Vorwärtsaktivitätswerten und Rückwärtsgradienten. werden auf eine geringe Genauigkeit komprimiert, wodurch die Kommunikationseffizienz des verteilten Trainings erheblich verbessert wird. Verglichen mit der End-to-End-Trainingsleistung ohne Komprimierung in einem zentralisierten Computernetzwerk (z. B. 10 Gbit/s) ist sie derzeit nur 31 % langsamer. In Kombination mit den Daten zur Planungsoptimierung besteht zwar noch eine gewisse Lücke zwischen dem zentralisierten Rechenleistungsnetz und dem zentralisierten Rechenleistungsnetz, die Hoffnung auf einen Aufholbedarf in der Zukunft ist jedoch relativ groß.
Abschluss
In der Dividendenperiode der KI-Welle ist der AGI-Rechenleistungsmarkt zweifellos der Markt mit dem größten Potenzial und der größten Nachfrage unter vielen Rechenleistungsmärkten. Allerdings sind auch die Entwicklungsschwierigkeiten, die Hardwareanforderungen und die finanziellen Anforderungen am höchsten. Wenn wir die beiden oben genannten Projekte kombinieren, bleibt uns noch eine gewisse Zeit, bis der AGI-Rechenleistungsmarkt eingeführt wird. Das echte dezentrale Netzwerk ist natürlich auch viel komplizierter, um mit den Cloud-Giganten zu konkurrieren.
Beim Schreiben dieses Artikels habe ich auch festgestellt, dass einige kleine Projekte, die noch in den Kinderschuhen stecken (PPT-Stadium), begonnen haben, einige neue Einstiegspunkte zu erkunden, beispielsweise die Konzentration auf die weniger schwierige Inferenzphase oder kleine Modelle im Training. Das sind gute Versuche. Auf lange Sicht ist die Bedeutung von Dezentralisierung und Erlaubnislosigkeit wichtig. Das Recht, auf AGI-Rechenleistung zuzugreifen und diese zu trainieren, sollte nicht auf einige wenige zentralisierte Giganten konzentriert werden. Die Menschheit braucht keine neue „Religion“ oder einen neuen „Papst“, geschweige denn die Zahlung teurer Mitgliedsbeiträge.