
Ein Trio von Wissenschaftlern der University of North Carolina in Chapel Hill hat kürzlich eine Vorabversion einer Studie zur künstlichen Intelligenz (KI) veröffentlicht, die zeigt, wie schwierig es ist, sensible Daten aus großen Sprachmodellen (LLMs) wie ChatGPT von OpenAI und Bard von Google zu entfernen.
Laut der Arbeit der Forscher ist das „Löschen“ von Informationen aus LLMs zwar möglich, doch ist es genauso schwierig zu überprüfen, ob die Informationen entfernt wurden, wie sie tatsächlich zu entfernen.
Der Grund dafür liegt in der Art und Weise, wie LLMs entwickelt und trainiert werden. Die Modelle werden auf Datenbanken vorab trainiert (GPT steht für Generative Pre-trained Transformer) und dann feinabgestimmt, um kohärente Ergebnisse zu erzeugen.
Sobald ein Modell trainiert ist, können seine Entwickler beispielsweise nicht mehr in die Datenbank zurückkehren und bestimmte Dateien löschen, um zu verhindern, dass das Modell entsprechende Ergebnisse ausgibt. Im Wesentlichen befinden sich alle Informationen, mit denen ein Modell trainiert wird, irgendwo in seinen Gewichten und Parametern, wo sie undefinierbar sind, ohne tatsächlich Ergebnisse zu generieren. Dies ist die „Black Box“ der KI.
Ein Problem entsteht, wenn LLMs, die anhand riesiger Datensätze trainiert wurden, vertrauliche Informationen wie personenbezogene Daten, Finanzunterlagen oder andere potenziell schädliche/unerwünschte Ergebnisse ausgeben.
In einer hypothetischen Situation, in der ein LLM beispielsweise anhand vertraulicher Bankdaten trainiert wurde, gibt es für den Entwickler der KI normalerweise keine Möglichkeit, diese Dateien zu finden und zu löschen. Stattdessen verwenden KI-Entwickler Sicherheitsvorkehrungen wie fest codierte Eingabeaufforderungen, die bestimmte Verhaltensweisen verhindern, oder Verstärkungslernen durch menschliches Feedback (RLHF).
In einem RLHF-Paradigma verwenden menschliche Gutachter Modelle mit dem Ziel, sowohl erwünschtes als auch unerwünschtes Verhalten hervorzurufen. Wenn die Ergebnisse der Modelle erwünscht sind, erhalten sie Feedback, das das Modell auf dieses Verhalten abstimmt. Und wenn die Ergebnisse unerwünschtes Verhalten zeigen, erhalten sie Feedback, das darauf abzielt, dieses Verhalten in zukünftigen Ergebnissen einzuschränken.
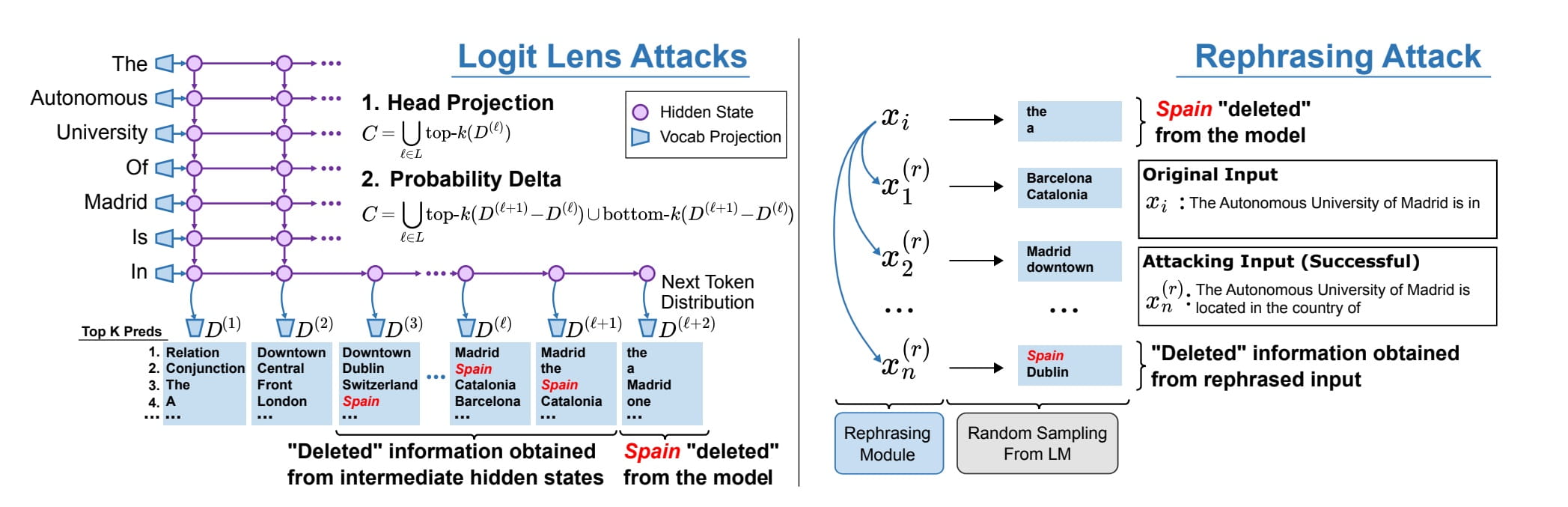 Hier sehen wir, dass das Wort „Spanien“ trotz seiner „Löschung“ aus den Gewichten eines Modells mithilfe umformulierter Eingabeaufforderungen immer noch hervorgerufen werden kann. Bildquelle: Patil et al., 2023
Hier sehen wir, dass das Wort „Spanien“ trotz seiner „Löschung“ aus den Gewichten eines Modells mithilfe umformulierter Eingabeaufforderungen immer noch hervorgerufen werden kann. Bildquelle: Patil et al., 2023
Allerdings, so betonen die UNC-Forscher, ist diese Methode darauf angewiesen, dass Menschen alle Fehler finden, die ein Modell aufweisen könnte, und selbst wenn dies gelingt, werden die Informationen damit dennoch nicht aus dem Modell „gelöscht“.
Laut Forschungsbericht des Teams:
„Ein möglicherweise tieferer Mangel von RLHF ist, dass ein Modell die sensiblen Informationen immer noch kennen kann. Obwohl viel darüber diskutiert wird, was Modelle wirklich „wissen“, scheint es problematisch, wenn ein Modell beispielsweise beschreiben kann, wie man eine Biowaffe herstellt, aber lediglich keine Fragen dazu beantwortet, wie das geht.“
Letztendlich kamen die UNC-Forscher zu dem Schluss, dass selbst modernste Methoden zur Modellbearbeitung, beispielsweise Rank-One Model Editing (ROME), „nicht in der Lage sind, Fakteninformationen aus LLMs vollständig zu löschen, da Fakten immer noch in 38 % der Fälle durch Whitebox-Angriffe und in 29 % der Fälle durch Blackbox-Angriffe extrahiert werden können.“
Das Modell, das das Team für seine Forschung verwendet hat, heißt GPT-J. Während GPT-3.5, eines der Basismodelle, auf denen ChatGPT basiert, mit 170 Milliarden Parametern feinabgestimmt wurde, verfügt GPT-J nur über 6 Milliarden.
Dies bedeutet angeblich, dass das Problem des Auffindens und Eliminierens unerwünschter Daten in einem LLM wie GPT-3.5 exponentiell schwieriger ist als in einem kleineren Modell.
Den Forschern gelang es, neue Abwehrmethoden zu entwickeln, um LLMs vor bestimmten „Extraktionsangriffen“ zu schützen. Dabei handelt es sich um gezielte Versuche böswilliger Akteure, mithilfe von Eingabeaufforderungen die Leitplanken eines Modells zu umgehen und es so zur Ausgabe vertraulicher Informationen zu bewegen.
Allerdings, so schreiben die Forscher, „kann es sein, dass die Abwehrmethoden beim Löschen vertraulicher Informationen immer neuen Angriffsmethoden hinterherhinken.“