
主要要點
在幣安,我們使用機器學習 (ML) 來解決各種業務問題,包括但不限於賬戶接管 (ATO) 欺詐、P2P 詐騙和支付詳細信息被盜。
我們的 Binance Risk AI 數據科學家使用機器學習操作 (MLOps) 構建了實時的端到端 ML 管道,持續提供生產就緒的 ML 服務。

我們爲什麼使用 MLOps?
對於初學者來說,創建 ML 服務是一個迭代過程。數據科學家根據爲業務創造價值的目標,不斷嘗試改進特定指標,無論是離線還是在線。那麼我們如何才能使這個過程更加高效——例如,縮短機器學習模型的上市時間?
其次,機器學習服務的行爲不僅受到我們開發人員定義的代碼的影響,還受到其收集的數據的影響。這個想法也稱爲概念漂移,在谷歌的論文《機器學習系統中的隱藏技術債務》中得到了強調。
以欺詐爲例,詐騙者不僅僅是一臺機器,還是一個不斷適應並改變攻擊方式的人。因此,底層數據分佈將不斷髮展以反映攻擊媒介的變化。我們如何纔能有效地確保生產模型考慮最新的數據模式?
爲了克服上述挑戰,我們使用了一個名爲 MLOps 的概念,這個術語最初由 Google 於 2018 年提出。在 MLOps 中,我們專注於模型的性能和支持生產系統的基礎設施。這使我們能夠構建可擴展、高可用性、可靠且可維護的 ML 服務。
分解我們的實時端到端 ML 管道
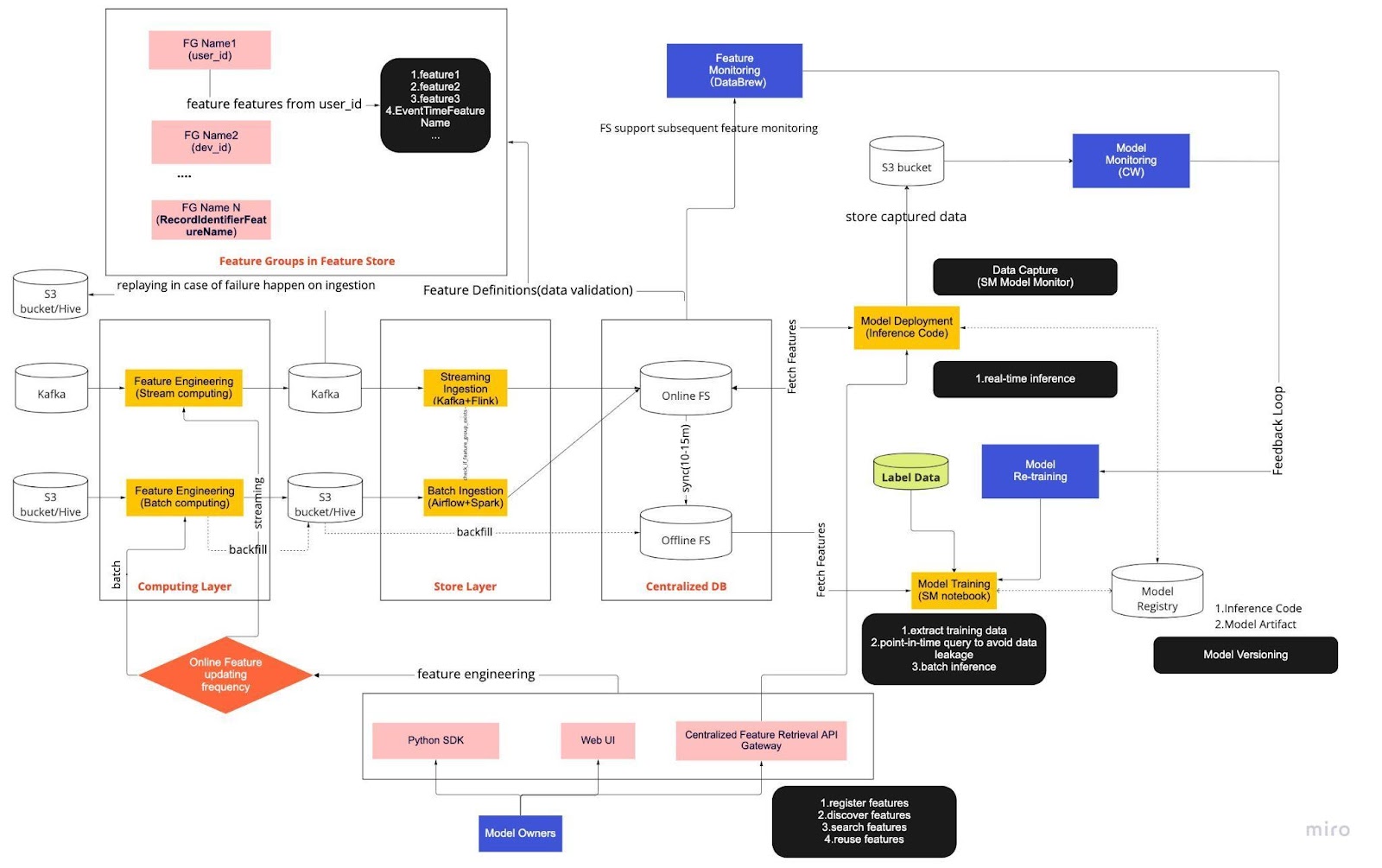
將上圖視爲使用特徵存儲進行實時模型開發的標準操作程序 (SOP)。端到端 ML 管道決定了我們的團隊如何應用 MLops,它根據兩種類型的需求構建:功能性和非功能性。
功能
數據處理
模型訓練
模型開發
模型部署
監控
非功能性需求
可擴展
高可用性
可靠的
可維護
該管道進一步分爲六個關鍵部分:
計算層
存儲層
集中式數據庫
模型訓練
模型部署
模型監控
1.計算層

計算層主要負責特徵工程,將原始數據轉換成有用的特徵的過程。
我們根據計算層更新的頻率將其分爲兩種類型:以分鐘/秒爲間隔的流式計算和以天/小時爲間隔的批量計算。
計算層的輸入數據一般來自基於事件的數據庫,包括 Apache Kafka 和 Kinesis,或者 OLAP 數據庫,包括開源的 Apache Hive 和雲解決方案的 Snowflake。
2. 存儲層
存儲層是我們註冊特徵定義並將其部署到特徵存儲中以及執行回填的地方,這個過程允許我們在定義新特徵時通過歷史數據重建特徵。回填通常是我們的數據科學家可以在筆記本環境中完成的一次性工作。因爲 Kafka 只能存儲過去 7 天的事件,所以它採用了備份機制到 s3/hive 表中來提高容錯能力。
您會注意到中間層 Hive 和 Kafka 被刻意安置在計算層和存儲層之間。可以將這種放置視爲計算和寫入功能之間的緩衝區。類比就是將生產者與消費者分開。流計算是生產者,而流提取是消費者。
將計算和提取分離爲我們的 ML 管道提供了多種好處。首先,我們可以在發生故障時提高管道的穩健性。即使提取或計算層由於操作、硬件或網絡問題而不可用,我們的數據科學家仍然可以從集中式數據庫中提取特徵值。
此外,我們可以單獨擴展基礎設施的不同部分,並減少構建和運行管道所需的能源。例如,如果管道因某種原因失敗,提取層不會阻塞計算層。在創新方面,我們可以試驗和採用新技術,例如新版本的 Flink 應用程序,而不會影響我們現有的基礎設施。

計算層和存儲層都是我們所說的自動化特徵管道。這些管道是獨立的,按照不同的時間表運行,並被歸類爲流式或批處理管道。這兩個管道的工作方式不同:批處理管道中的一個特徵組可能每晚刷新一次,而另一個特徵組每小時更新一次。在流式管道中,當源數據到達輸入流(例如 Apache Kafka 主題)時,特徵組會實時更新。
3. 集中式數據庫
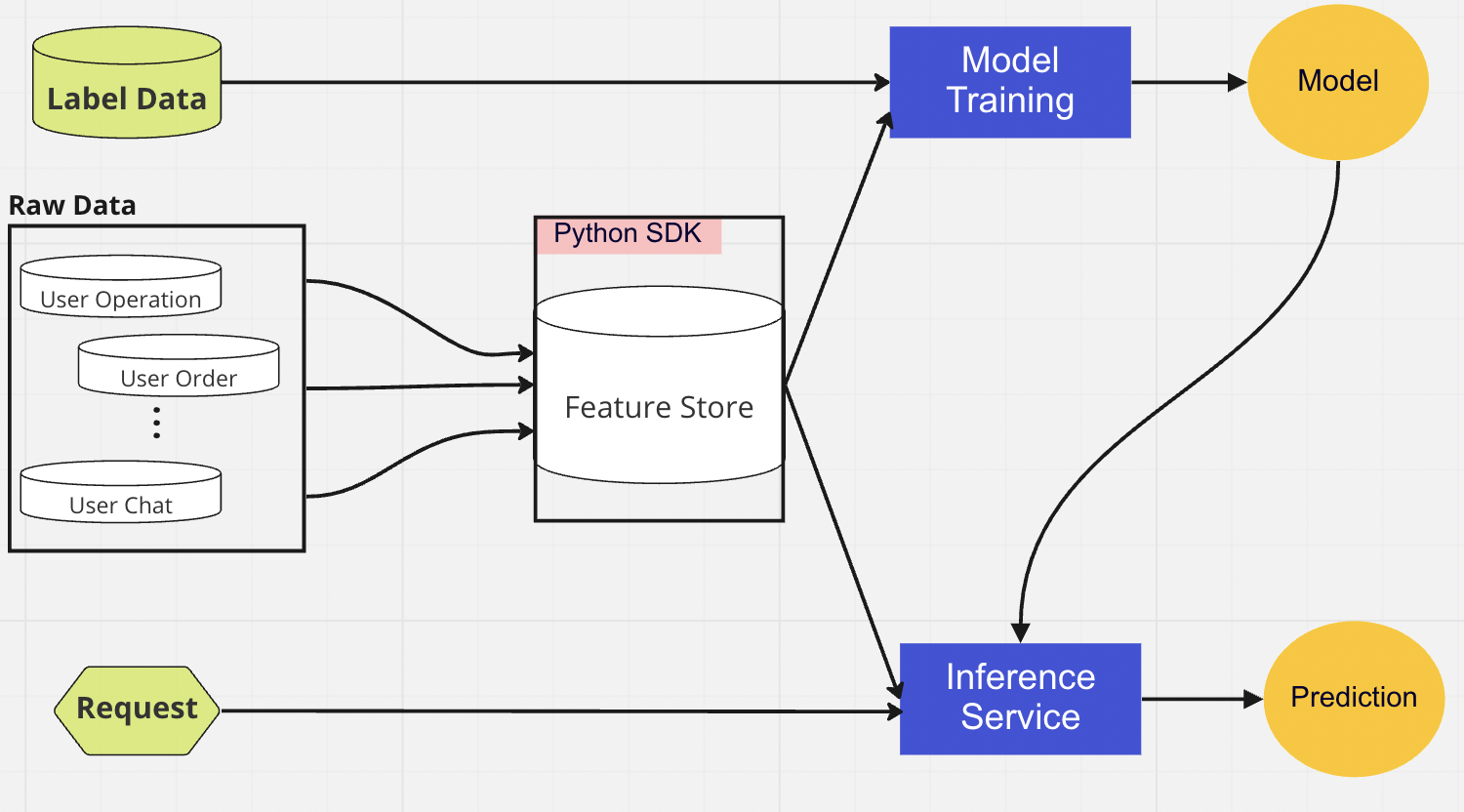
集中式數據庫層是我們的數據科學家將已準備好的功能數據顯示到在線或離線功能存儲的地方。
在線特徵存儲是一種低延遲、高可用性的存儲,可實現記錄的實時查詢。另一方面,離線特徵存儲提供了所有特徵數據的安全且可擴展的存儲庫。這使得科學家能夠從一組集中管理的特徵組中創建訓練、驗證或批量評分數據集,並在對象存儲系統中保留特徵值的完整歷史記錄。
兩個特徵存儲每 10-15 分鐘自動同步一次,以避免訓練-應用偏差。在後續文章中,我們將深入探討如何在管道中使用特徵存儲。
4.模型訓練
模型訓練層是我們的科學家從離線特徵存儲中提取訓練數據以微調我們的機器學習服務的地方。我們使用時間點查詢來防止數據在提取過程中泄露。
此外,該層還包含一個稱爲模型再訓練反饋迴路的關鍵組件。模型再訓練可確保部署的模型準確表示最新的數據模式(例如,黑客改變其攻擊行爲),從而最大限度地降低概念漂移的風險。
5.模型部署
對於模型部署,我們主要使用基於雲的評分服務作爲實時數據服務的骨幹。下圖顯示了當前推理代碼如何與特徵存儲集成。

6.模型監控
在此層中,我們的團隊監控評分服務的使用情況指標,例如 QPS、延遲、內存和 CPU/GPU 利用率。除了這些基本指標之外,我們還使用捕獲的數據來檢查隨時間推移的特徵分佈、訓練-應用偏差和預測漂移,以確保將概念漂移降至最低。
結束語
總而言之,將我們的管道基礎設施鬆散地劃分爲計算層、存儲層和集中式數據庫,與緊密耦合的架構相比,爲我們帶來了三個主要好處。
發生故障時管道更加穩健
提高選擇實施工具的靈活性
可獨立擴展的組件
有興趣使用機器學習來保護世界上最大的加密生態系統及其用戶嗎?請在我們的職業頁面上查看幣安工程/人工智能的公開招聘信息。