
DeepMind Flamingo 模型的開源版本 OpenFlamingo 剛剛發佈。 OpenFlamingo 從根本上來說是一個允許訓練和評估大型多模式模型 (LMM) 的框架。 OpenFlamingo 建立在 Meta AI 開發的 LLaMA 大語言模型之上。
 瞭解更多:如何永久免費使用 Midjourney:5 個簡單步驟
瞭解更多:如何永久免費使用 Midjourney:5 個簡單步驟
開發人員對第一個版本的貢獻如下:
一個相當大的多模式數據集,結合了文本和視覺序列。
包括視覺和語言在內的活動情境學習評估基準。
基於 LLaMA 的 OpenFlamingo-9B 模型的初步版本。
通過 OpenFlamingo,開發人員希望創建一個能夠應對各種視覺語言挑戰的多模式系統。最終目標是在處理視覺和文本輸入方面與 GPT-4 的強度和適應性相當。爲了實現這一目標,開發人員正在開發 DeepMind Flamingo 模型的開源版本,這是一種能夠處理和推理圖像、視頻和文本的 LMM。開發人員致力於開發完全開源的模型,因爲他們認爲透明度對於促進合作、加速開發以及實現尖端 LMM 的民主化至關重要。
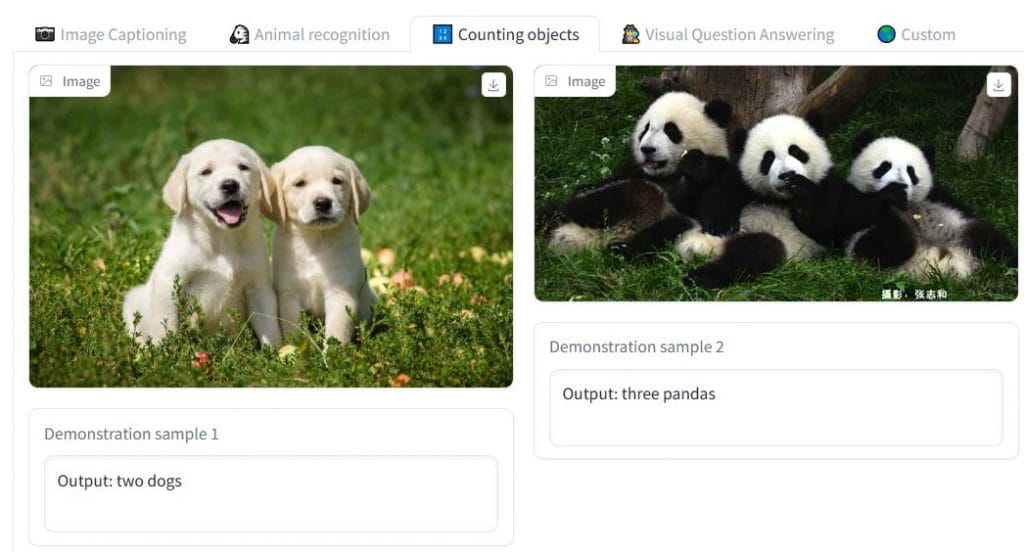
他們正在提供我們的 OpenFlamingo-9B 模型的初始檢查點。儘管該模型尚未完全優化,但它顯示了該項目的前景。開發人員可以通過合作和獲取社區反饋來訓練更好的 LMM。他們邀請公衆提供意見並添加到存儲庫中,以便參與開發過程。
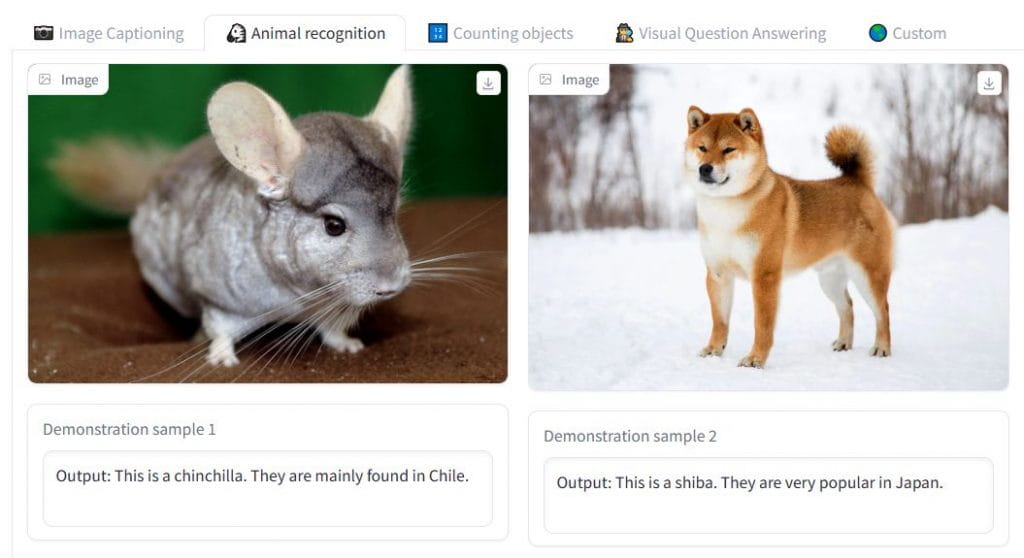
該實現與 Flamingo 的實現非常相似。 Flamingo 模型必須在具有交錯文本和圖形的大規模網絡數據集上進行訓練,以使其具備上下文中的小樣本學習技能。 OpenFlamingo 中實現了原始 Flamingo 研究中建議的相同架構(感知器重採樣器、交叉注意層)。但是,由於 Flamingo 的訓練數據無法向公衆開放,因此開發人員使用開源數據集來訓練模型。新發布的 OpenFlamingo-9B 檢查點專門針對來自 LAION-2B 的 1000 萬個樣本和來自新的 Multimodal C4 數據集的 500 萬個樣本進行了專門訓練。
作爲該版本的一部分,開發人員還包括來自我們未完成的 LMM OpenFlamingo-9B 的檢查點,該檢查點基於 LLaMA 7B 和 CLIP ViT/L-14。儘管這個概念仍在開發中,但社區可能已經從中受益匪淺。

首先,請查看 GitHub 源代碼和演示。
瞭解有關人工智能的更多信息:
到 2030 年,AI 模型訓練成本預計將從 1 億美元增加到 5 億美元
DeepMind 的新型自適應人工智能代理 Ada 幾乎與人類一樣聰明
DeepMind 發佈了人工智能工具 Dramatron,它可以生成電影或電視節目劇本的完整草稿
帖子《OpenFlamingo:來自 Meta AI 和 LAION 的新型開源圖像到文本框架》首先出現在 Metaverse Post 上。