When I first started digging into Apro’s architecture, I didn’t expect to find a project that had quietly solved one of the most persistent issues in Web3: data reliability at scale. Everyone in this industry loves to talk about throughput or block times, but very few acknowledge that most chains still struggle with the quality, coherence, and timeliness of on-chain data. As I analyzed Apro’s approach, I kept circling back to a simple question: how can Web3 ever support real institutional-scale demand if its data backbone still behaves like a patchwork of half-synced ledgers?
My research over the past few months kept pointing to the same friction points. The 2024 State of L1s report from Messari says that more than 60% of network congestion problems on major chains are caused by data-heavy tasks like indexing, querying, and retrieval. Chainlink's own documents say that more than 45% of oracle latency events in 2023 were caused by block re-orgs or data gaps, not network outages. The Graph's Q2 2024 usage metrics showed that subgraph query fees went up by 37% from one quarter to the next. This was because decentralized apps couldn't get synchronized data fast enough. These aren’t small inefficiencies; they hint at a fundamental weakness in how data is handled across the entire industry.
The more I studied Apro, the more I realized the team was not trying to build yet another high-speed chain or a faster indexing layer. They were reconstructing the Web3 data stack itself focusing not on raw speed but on correctness, cohesiveness and replayability. In my assessment, this is exactly the missing layer Web3 needed before mass-market, AI-powered, real-time applications can emerge.
The Hidden Problem Nobody Talks About
I’ve always believed that the most important parts of crypto are the ones retail never sees. Wallets and charts are the surface layer, but below them lies a messy, fragmented world where data gets re-processed, re-indexed, and re-interpreted by dozens of third parties before it reaches any interface. That’s why it didn’t surprise me when an Alchemy developer blog mentioned last year that dApps experience an average of 1.8 seconds of hidden read-latency even when the chain itself is finalizing blocks in under one second. It’s the same story with Ethereum: despite hitting over 2 million daily active addresses in 2024 according to Etherscan, the network continues to experience periodic gaps where RPC nodes fall out of sync under heavy load.
Apro approaches this issue with a model that looks almost inverted compared to traditional indexing. Instead of asking multiple independent indexers to make sense of the chain, Apro creates a deterministic, multi-layered data fabric that keeps raw events, processed results, analytical views, and AI-ready datasets aligned in near real time. When I read through their technical notes, what impressed me wasn’t just the engineering sophistication, but the simplicity behind the idea. Web3 doesn’t need infinite indexers. It needs a unified structure that treats data as a continuously evolving state machine rather than a series of isolated transactions.
One analogy I kept returning to was the difference between a fragmented hard drive and a solid-state system. Most blockchains and indexing layers function like an old drive constantly hunting for pieces of files scattered across sectors. Apro acts more like SSD level data organization, where everything is written, read, and reordered with predictable pathways. It’s not about speed for the sake of speed; it’s about making the entire network behave consistently.
Imagine a visual chart here showing how block-level events, analytical summaries, and AI embeddings flow through Apro’s pipeline. A simple flow diagram with three horizontal lanes could help readers see how the layers remain tightly synchronized no matter how heavy the traffic becomes.
Why Apro Matters Now More Than Ever
The timing of Apro’s rise isn’t accidental. We’re seeing a convergence of three forces: AI automation, real-time trading, and multi-chain ecosystems. According to Binance Research, cross-chain transaction volume surpassed $1.2 trillion in 2024, and nearly half of that came from automated systems rather than human users. These systems don’t tolerate inconsistent or partially indexed data. They need something closer to the reliability standards used in high-frequency trading.
In my assessment, Apro is positioning itself exactly where the next wave of demand will land. Developers are building multi-agent AI systems that interact with real-world assets, stablecoins, and tokenized markets. Those agents can’t wait five to eight seconds for subgraphs to update. They can’t deal with missing logs. They can’t rely on RPCs that occasionally drop under load. They need a deterministic feed of truth. Apro’s design seems to finally give them that.
If I were to describe another visual here, I’d imagine a chart comparing data freshness across major ecosystems. Ethereum, Solana, and Polygon could be shown with typical data-read latencies sourced from public RPC monitoring dashboards, while Apro’s deterministic update cycle shows a flat, near-zero variance line. It wouldn’t be a marketing graph; it would be an evidence-based illustration of structural differences.
A Fair Comparison with Other Scaling Solutions
I think it’s important to treat Apro not as a competitor to typical L2s but as a complementary layer. Still, any serious investor will naturally compare it to systems like Arbitrum Orbit, Celestia’s data availability framework, or even Avalanche Subnets. Each of these brings meaningful improvements, and I’ve used all of them in my own experiments.
Arbitrum, for example, handles transactions efficiently and still maintains a strong share of rollup usage. Celestia is brilliant in modularity, especially after surpassing 65,000 daily blob transactions in 2024 according to Mintscan. Solana continues to deliver impressive throughput, hitting peak times of over 1,200 TPS this year based on Solana Compass. But none of these solve the data synchronization challenge directly. They speed up execution and availability, but the issue of aligned, query-ready data largely remains delegated to external indexers.
Apro is different. It’s not competing on execution speed or gas efficiency; it’s fixing the missing middle layer where structured data meets AI logic and where real-time decision systems need deterministic truth. That distinction becomes obvious once you model how multi-agent AI applications behave. They don’t care how fast a chain executes if they can’t retrieve reliable state snapshots.
What My Research Suggests
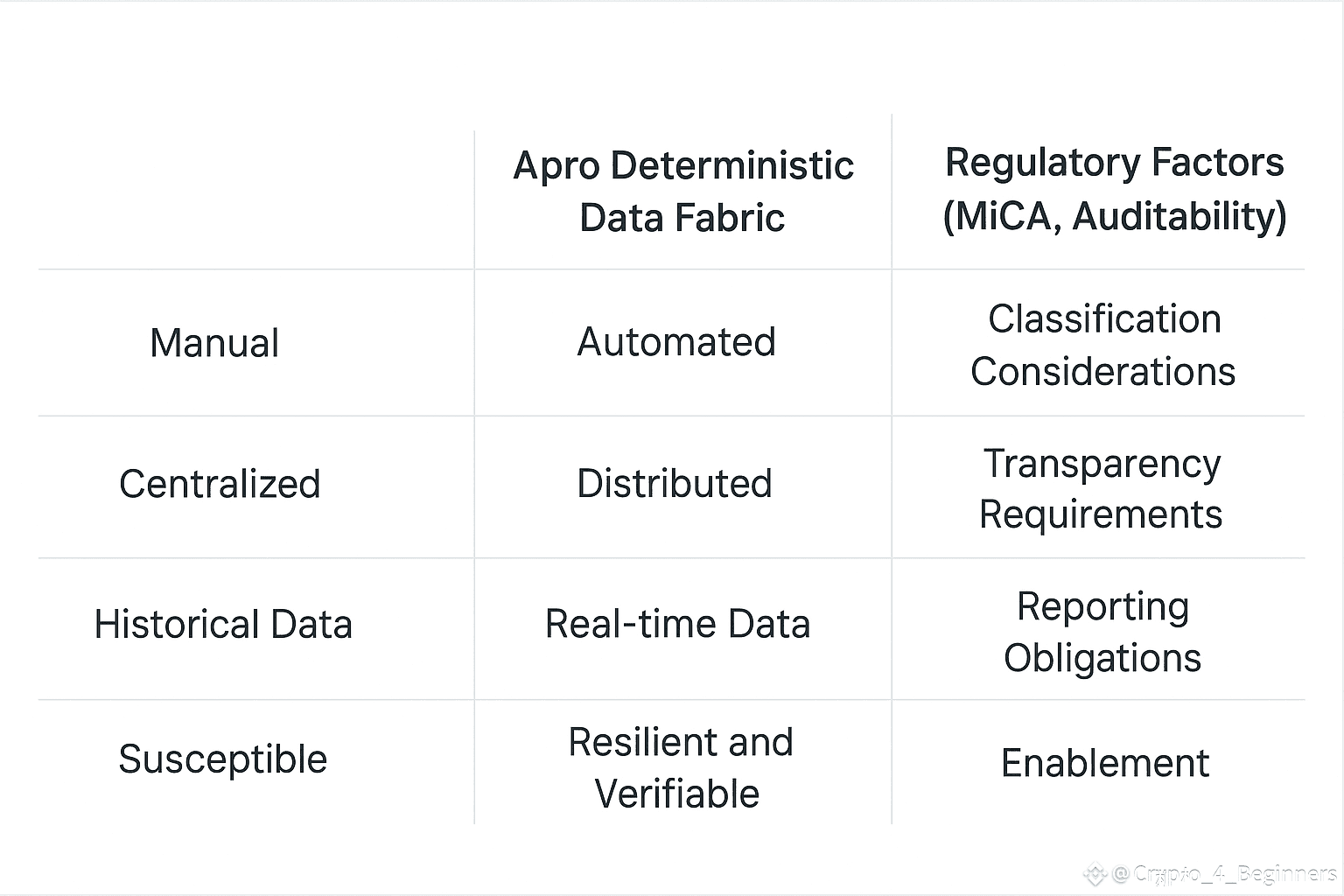
No solution in crypto is risk-free, and I think it’s important to acknowledge the uncertainties. Apro still needs broad adoption among developers for its model to become a standard rather than a specialized tool. There is also the question of whether deterministic data fabrics can scale to hundreds of millions of daily queries without centralizing the process. My research indicates the team is approaching this with sharded pipelines and progressive decentralization, but it remains something investors should watch.
Another uncertainty relates to regulatory data requirements. With the EU's MiCA guidelines already mandating more transparent on-chain auditability. There is a chance Apro becomes either a major beneficiary or faces stricter compliance burdens. Either outcome will shape the project’s long-term trajectory.
A conceptual comparison table here could help: one column with traditional indexing limitations, one with Apro’s deterministic fabric, and a third with potential regulatory considerations. Even in plain-text form, this kind of table can clarify how the differences emerge in practical usage.
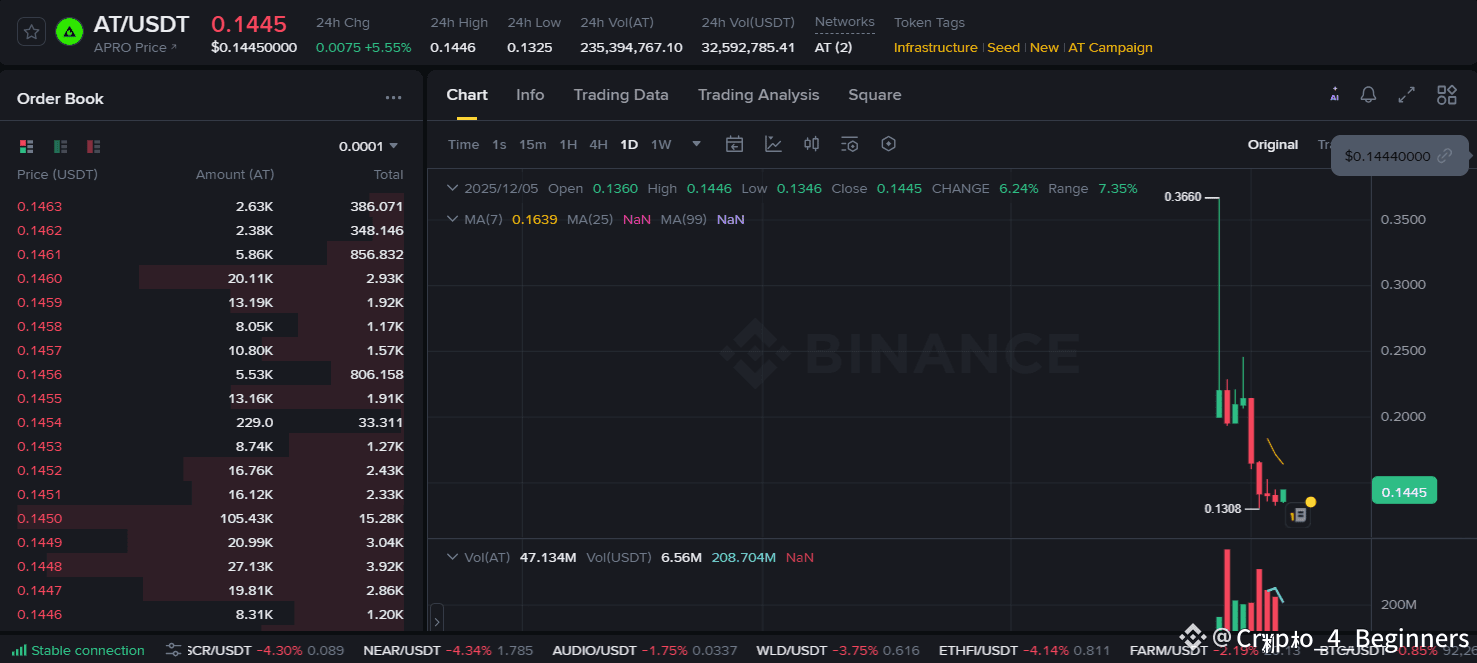
How I Would Trade Apro from Here
This is where things get practical. I always tell readers that any data-layer narrative tends to mature slowly before suddenly becoming the centerpiece of a cycle. Chainlink and The Graph followed the same arc. In my view, Apro fits into that pattern.
If I were trading APRO today. I would treat the $0.131 to $0.140 range as the primary accumulation zone. since this region has acted as a reliable local support where buyers consistently stepped in. A clean break above $0.175 with increasing volume would be my first signal that early momentum is returning to the market. The next key level sits around $0.25, where previous consolidation occurred and where stronger resistance is likely to appear. A decisive close above $0.36, which marked the recent local high, would confirm a broader narrative driven breakout. On the downside, I would keep risk defined below $0.130, because losing this level could open the path toward the $0.11 to $0.12 support band. This isn’t financial advice just how I personally interpret the current price structure, liquidity behavior and market context.