
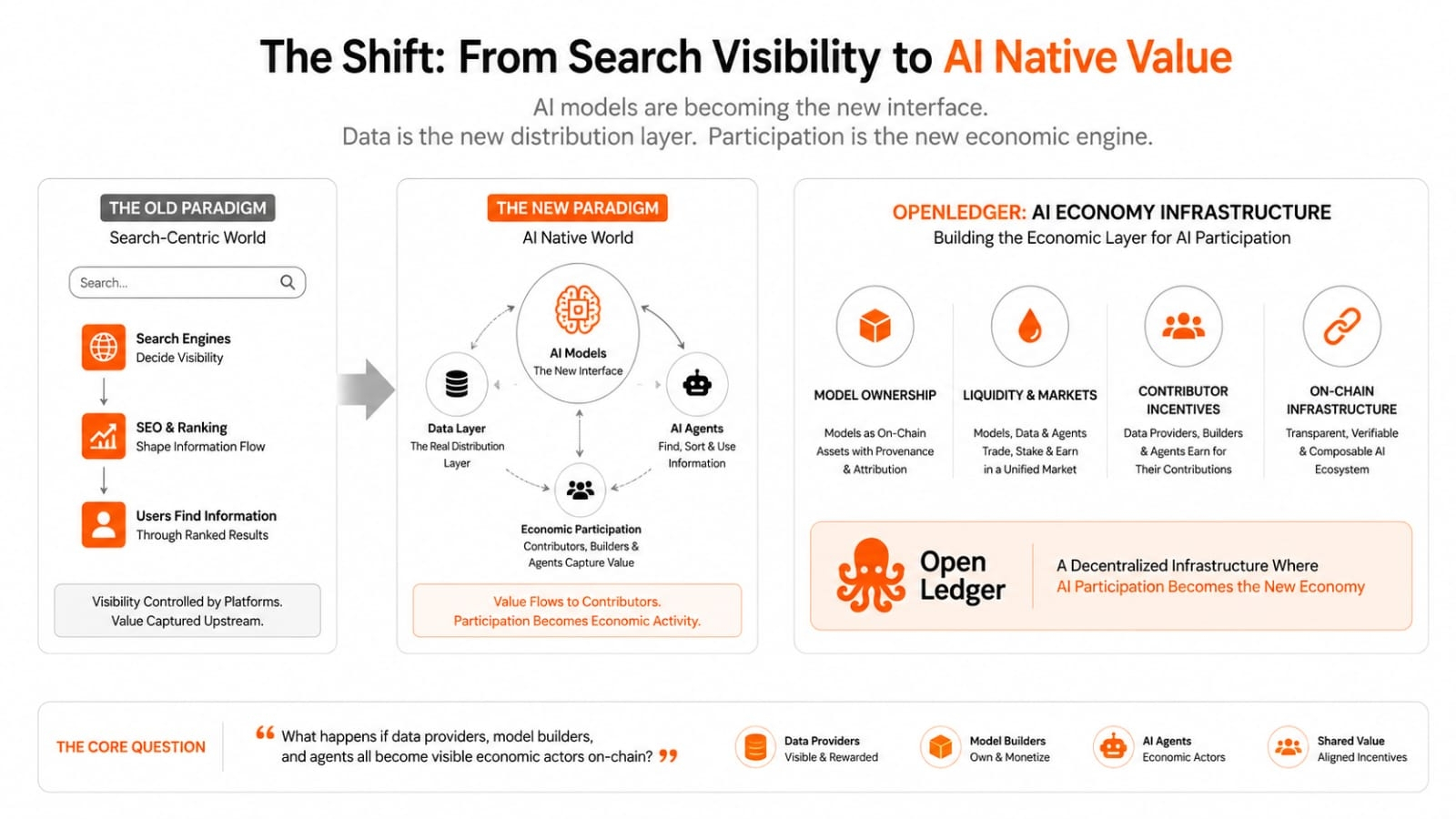
我注意到AI周圍有一個小變化,這感覺容易被忽略。以前搜索決定了可見度。SEO塑造了資訊的流動。現在感覺模型慢慢成為新的介面,而數據則成為它們背後真正的分發層。
這改變了激勵機制,比人們想的要多。如果AI代理成為發現、排序和使用資訊的主力,那麼在搜索頁面的排名就不那麼重要了。更重要的是誰擁有數據,誰訓練模型,以及當這些模型被使用時,誰能捕捉到價值。
這是我開始以不同的方式看待 OpenLedger 的地方。不僅僅是另一條 AI 鏈。更像是圍繞未來建立的基礎設施,未來 AI 參與本身成為經濟活動。
@OpenLedger 不斷吸引人們關注數據貨幣化和貢獻者激勵。我認為這部分很重要,因為 AI 不斷消耗人類輸入,而貢獻者通常保持隱形。該系統似乎在問一個不同的問題:如果數據提供者、模型構建者和代理人都成為鏈上可見的經濟行為者,會發生什麼?
其架構似乎是圍繞這一假設設計的。鏈上 AI 基礎設施不僅僅是托管模型。OpenLedger 不斷將模型擁有權、流動性和參與度連接到網絡本身。模型更像是具有經濟運動的資產,而非靜態輸出。
我也認為以太坊的兼容性很重要,即使人們忽略它。錢包集成和智能合約支持在今天聽起來很正常。但在 OpenLedger 內部,這感覺不僅僅是方便,而是讓 AI 活動可編程。代理人可以與擁有權系統和網絡激勵互動,而無需構建隔離的環境。
代理人部署方面可能是我開始更明顯地看到後 SEO 構想的地方。如果 AI 代理人越來越多地成為信息和服務的用戶,那麼網絡可能需要原生環境,讓代理人直接參與。OpenLedger 似乎在為這種可能性做準備,而不是在等待它。
不過,我仍在質疑激勵層。OpenLedger 獎勵貢獻者,並試圖通過經濟來調整參與。但激勵系統總是會吸引優化行為。人們往往會追隨獎勵而非理想。挑戰在於當激勵擴大時,有用的數據是否仍然保持其價值。
我也在想數據質量如何在長期內生存。將貢獻價值放在鏈上聽起來不錯,但維持質量卻更難。如果 AI 參與在網絡內部增長,OpenLedger 可能會面臨每個激勵經濟所面臨的相同壓力:數量增長速度超過質量。
模型擁有權的敘事也值得懷疑。我並不完全相信用戶今天會對擁有 AI 資產深感關心。許多人仍然是先追逐獎勵。OpenLedger 可能在押注,擁有權在 AI 更加嵌入日常系統後會變得重要。
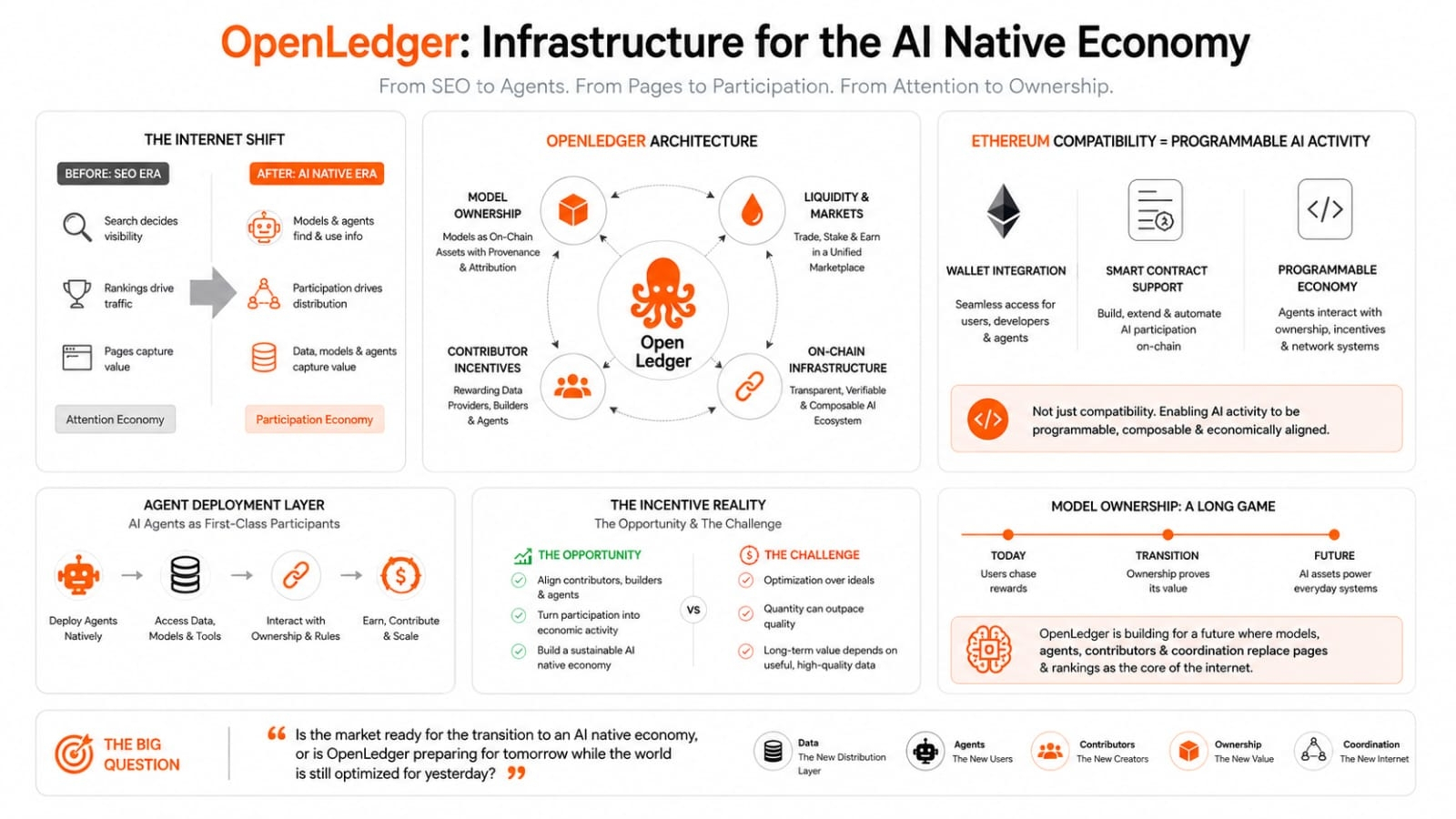
這就是為什麼這個項目現在感覺有趣。不只是因為 AI 再次成為熱潮。更多是因為 OpenLedger 似乎是基於一個安靜的假設而建立的,即 SEO 之後的互聯網可能圍繞模型、代理人、貢獻者和協調,而非頁面和排名。
我一直在思考市場是否真的準備好進行這種轉變。OpenLedger 可能在為一個 AI 原生經濟做準備,而人們卻還未完全意識到舊互聯網的激勵已經開始轉移。
