

主要要點
Binance 的 Ledger 存儲賬戶餘額和交易,同時還支持服務進行交易。
它爲高吞吐量、全天候可用性和位級數據準確性創造了必要的條件。
Binance Ledger 在幕後發揮的作用使其成爲 Binance 最重要的技術之一。在此瞭解它的工作原理以及它在全球最大的加密貨幣交易所運營中解決的問題。

有沒有想過幣安的運作原理是什麼?幣安需要每天處理龐大用戶羣的數百萬筆交易,因此值得我們瞭解一下幣安的運作原理。
幣安的技術運作以賬本爲基礎。賬本存儲賬戶餘額和交易,同時支持服務進行交易。
幣安對賬本的要求很高
可以想象,爲了滿足大量用戶的需求,對 Ledger 的要求很高。需要考慮三個主要點:
高吞吐量,在高峯時段能夠處理大量 TPS(每秒交易數)。
全天候可用,無停機時間。
位級數據準確性,不會出現資金損失或交易錯誤。
讓我們看一個賬本上基本條目的示例。這是一筆常見的交易,其中賬戶 1 將 1 BTC 轉移到賬戶 2。
交易前餘額:
表格1
交易後餘額:
表 2
在這個事務中,有兩個命令:
賬戶 1 -1 BTC
賬戶 2 +1 BTC
當交易完成時,將存儲兩個餘額日誌以供審計和對賬。
表3
標準行業解決方案
一個標準的行業 Ledger 解決方案是基於關係數據庫的。回到前面的例子,交易的兩個命令可以轉換成兩個 SQL 語句並在數據庫事務中執行(表 4)。
表 4
解決方案的優勢
實現起來非常簡單。
可以輕鬆應用常見的數據庫調整技術(例如讀/寫分割和分片)來提高性能。
對於 DevOps 來說,從故障轉移中恢復以及監控和維護商業數據庫並不難。
該解決方案的缺點
當由於行鎖而出現競爭條件時,TPS 將急劇下降。
很難水平擴展以提高性能。
熱門賬戶問題
不幸的是,對於幣安來說,上面演示的行業解決方案不能滿足其高要求。當發生交易時,它必須持有所涉及的每一行的行鎖。雖然有些賬戶需要處理的交易相對較少,但當然也有一些繁忙的賬戶有很多併發交易。在這種情況下,只有一個交易能夠持有賬戶的行鎖。
其他事務則只能等待鎖被釋放。我們稱這種情況爲熱賬戶問題,內部測試表明,在這種情況下 TPS 至少會下降 10 倍。您可以在下面的表 5 中看到這個問題。
熱門賬戶示例:
表 5
幣安的賬本解決方案
熱點賬號問題該如何解決?
解決我們這個問題的一個可能方案是創新性地將多線程模型轉換爲單線程模式。這樣就避免了競爭條件問題,從而不會出現熱賬戶問題。
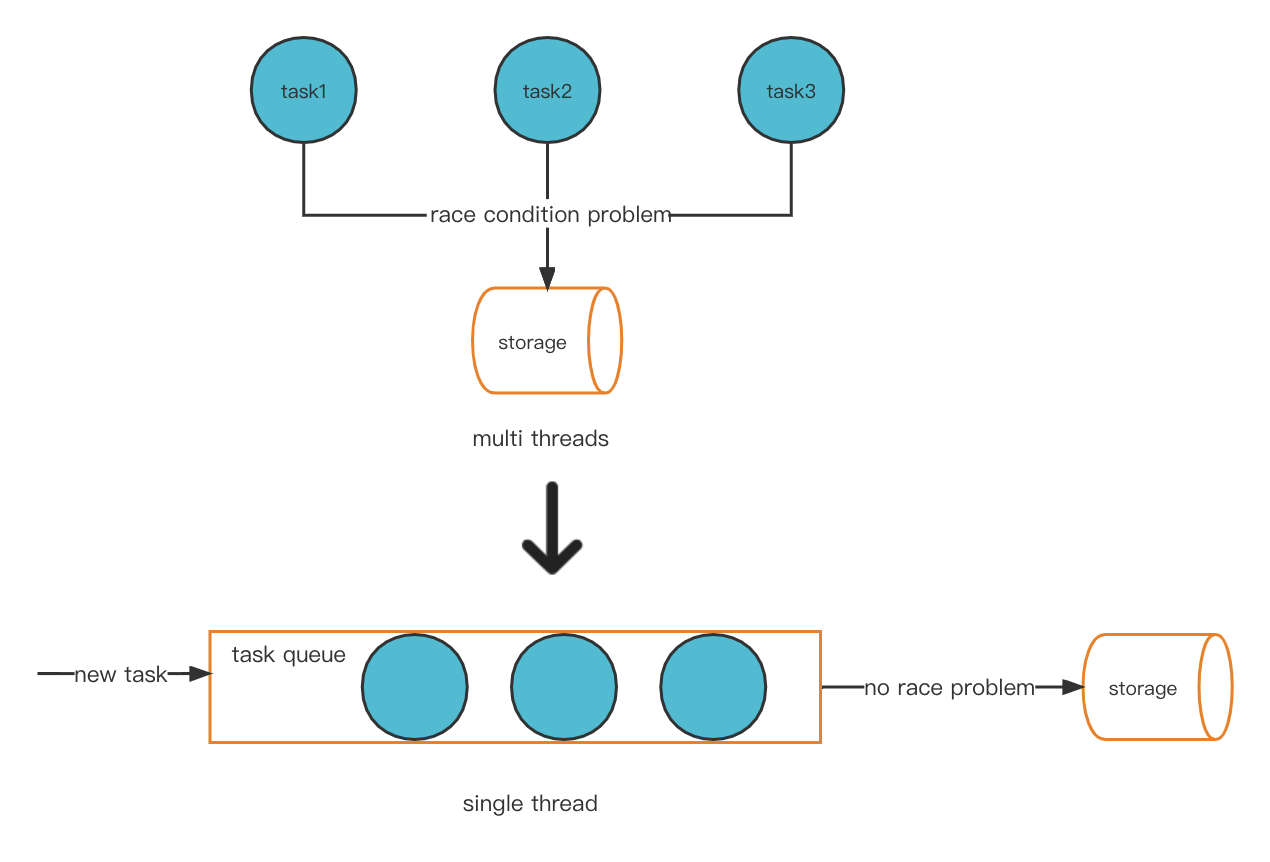
新的線程模型
基於消息的通信
實現我們的新線程模型後,需要解決一個通信問題。狀態機層是單線程的,而網絡層是多線程的,那麼我們如何在兩者之間有效地通信呢?
下一步是 Disruptor [1]。它基於環形緩衝區設計,創建無鎖、高性能隊列。
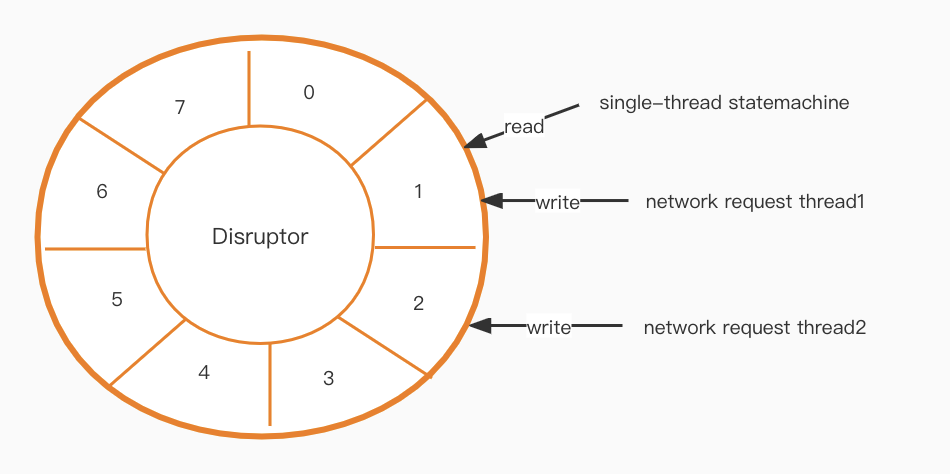
高可用性
到目前爲止,我們已經通過使用內存模型和 RocksDB [2] 本地存儲實現了高性能。但是,又出現了一個新的挑戰。現在我們需要考慮高數據可用性。
爲了確保節點之間的數據一致性,我們使用 Raft 共識算法 [3]。這意味着數據備份的數量等於存在的非領導節點的數量。該算法還確保系統在至少一半節點健康的情況下仍能正常工作,以幫助提供高服務可用性。
Raft 域角色:
Leader。Leader 處理所有客戶端請求,並將操作複製到所有跟隨者。
追隨者。追隨者在所有操作中都跟隨領導者。如果領導者發生故障,其中一位追隨者將被選爲新的領導者。
學習者。學習者是無投票權的追隨者,他們將每個冪等/交易變更記錄發送給其他服務。
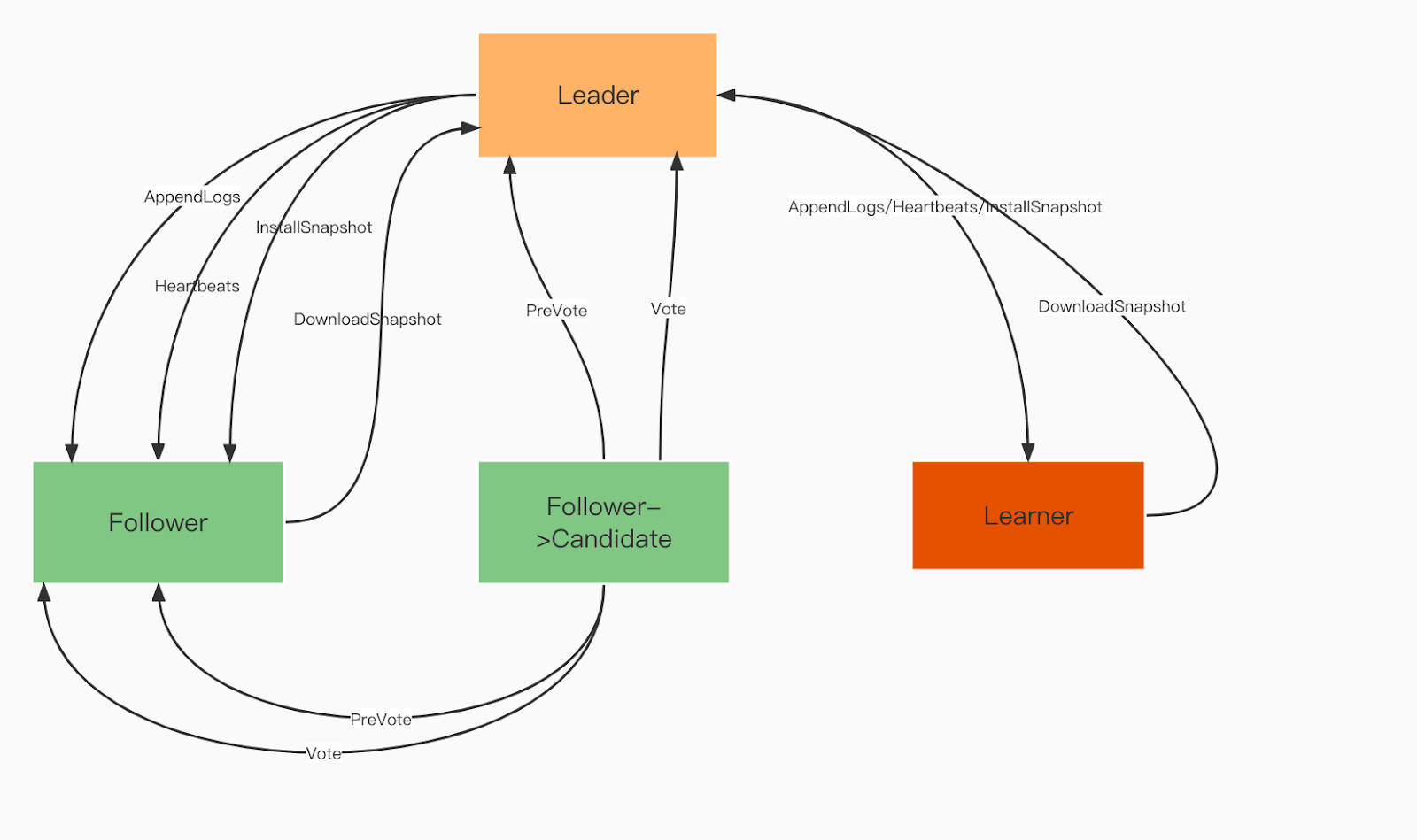
Raft 域角色
CQRS(命令查詢職責分離)
另一個我們要保證的關鍵標準是 Ledger 有更高的寫入性能和更多樣化的查詢條件。爲此,我們需要創建不同的域。raft 域基於 rocksdb+raft 提供更高效的寫入,view 域監聽 raft 域的消息並保存到關係型數據庫中,以供外部查詢。我們還可以在架構層面實現命令查詢職責分離。
賬本架構
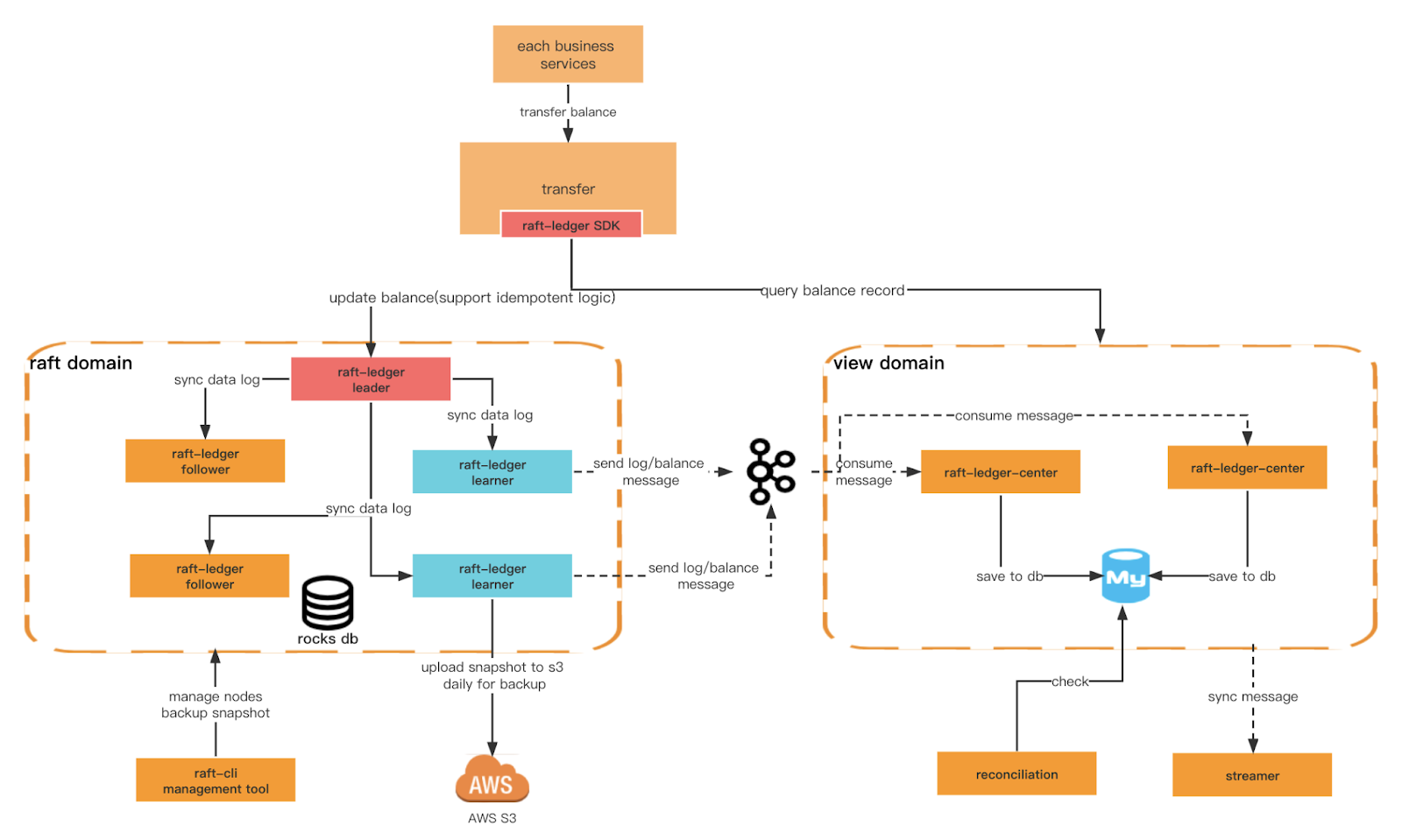
總體架構
Raft 和 Ledger 之間的術語:
表 6
查看域角色
Raft 賬本中心
使用學習者生成的消息並將交易和餘額數據存儲在 MySQL 中以供查詢。
請求處理
一筆交易請求會先經過網絡層、賬本層(請求處理器)、raft 層(raft log sync),然後再回到賬本層(狀態機)、網絡層(響應處理器),最後將響應返回給客戶端。
數據通過兩層之間的隊列傳遞。
網絡層 – 反序列化rpc請求並放入請求隊列。
賬本層——從隊列中獲取請求並準備上下文。然後將請求元數據放入 Raft 隊列中。
Raft 層 – 從 Raft 隊列中獲取請求元數據,並在所有追隨者之間進行同步。然後將結果放入應用隊列。
賬本層 – 從應用隊列中獲取數據並更新狀態機。然後將結果放入響應隊列。
網絡層 – 從響應隊列中獲取結果,並在返回給客戶端之前構建和序列化響應數據。
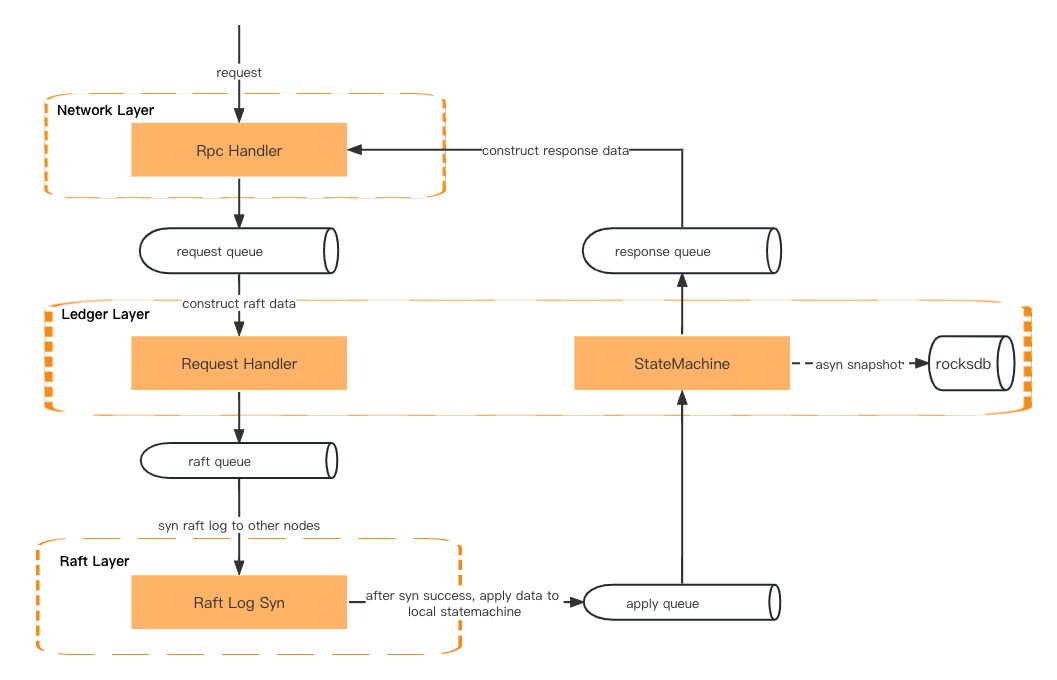
請求處理
數據恢復
每個 Ledger 節點會根據一個時間段觸發通用快照。此外,我們還實現了一致性快照。每個節點在相同的 raft 日誌索引處觸發,以確保每個節點觸發快照時的狀態機完全相同。然後快照將上傳到 S3 以供 Checker 驗證並作爲冷備份。
當 Ledger 重啓時,會讀取本地快照,重建狀態機,然後重放本地的 raft log,並從 leader 同步最新日誌,直到追上最新索引,如果本地快照或者 raft log 不存在,則會從 leader 獲取。
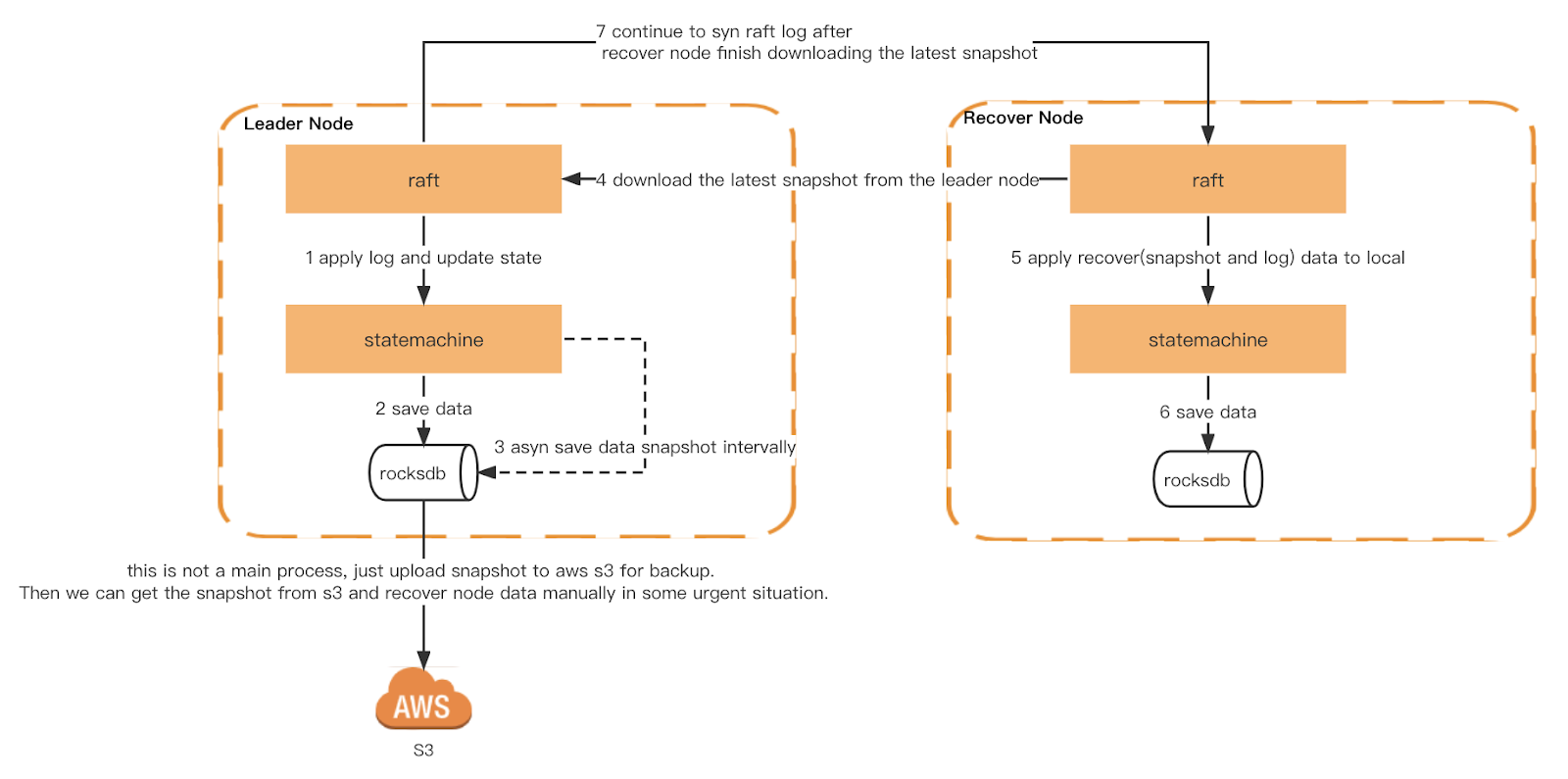
快照與恢復
容災
爲了提高可用性和容錯能力,Ledger 節點部署在不同的可用區,只要超過一半的節點是健康的,數據就不會丟失,故障轉移將在一秒內完成。
即使整個集羣發生故障,這種概率非常低,我們仍然可以通過存儲在 Amazon S3 中的一致性快照恢復集羣,並通過下游系統檢索最新丟失的數據。
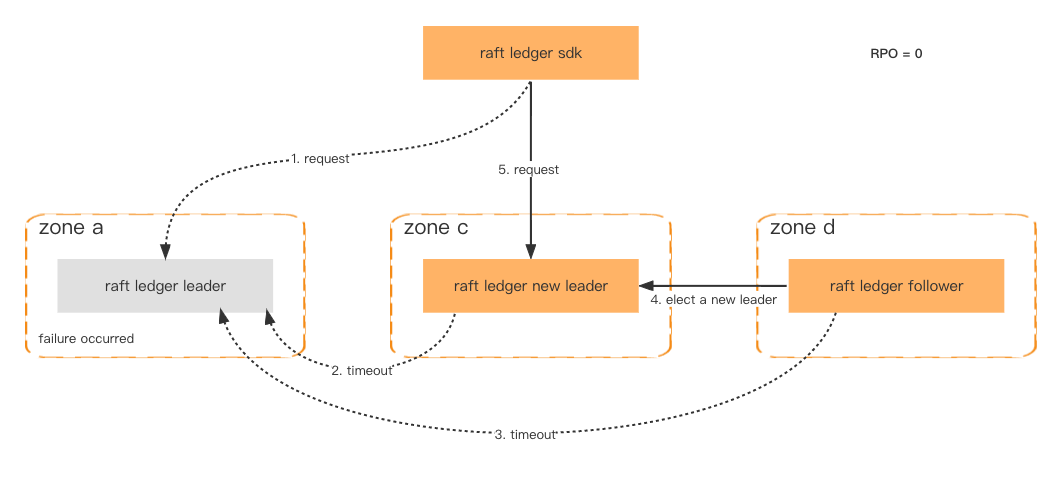
容錯
表現
下表顯示了性能測試的硬件規格
內部測試證明,一個 4 節點集羣(一個領導者,兩個追隨者和一個學習者)可以處理超過 10,000 TPS。根據設計,集羣逐一處理所有交易。完全沒有鎖定和競爭條件。因此在熱賬戶場景中,TPS 與正常場景一樣高。
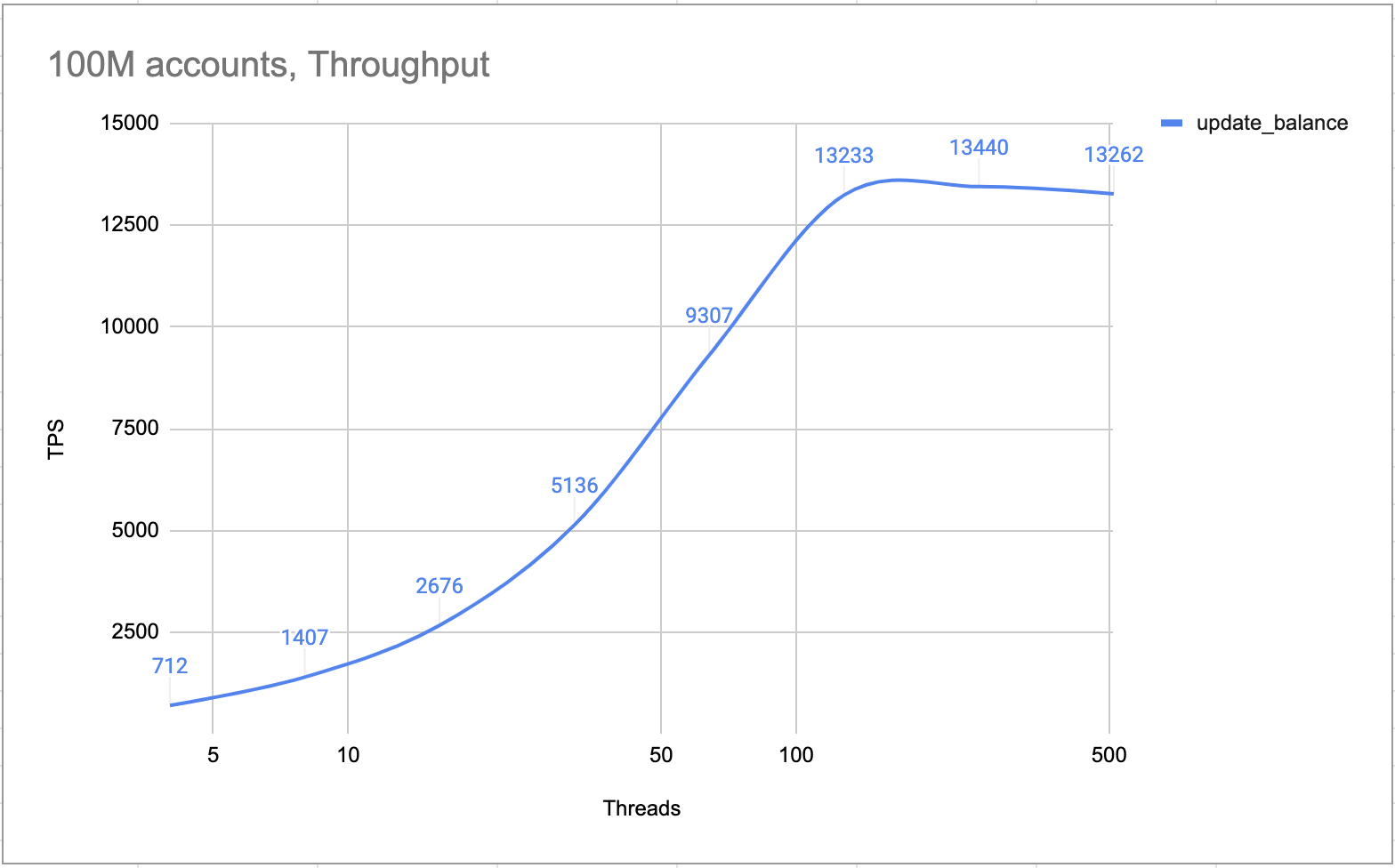
熱門賬戶TPS
下圖展示了每個事務的延遲,大部分事務可以在 10ms 內完成,較慢的事務可以在 25ms 內完成。
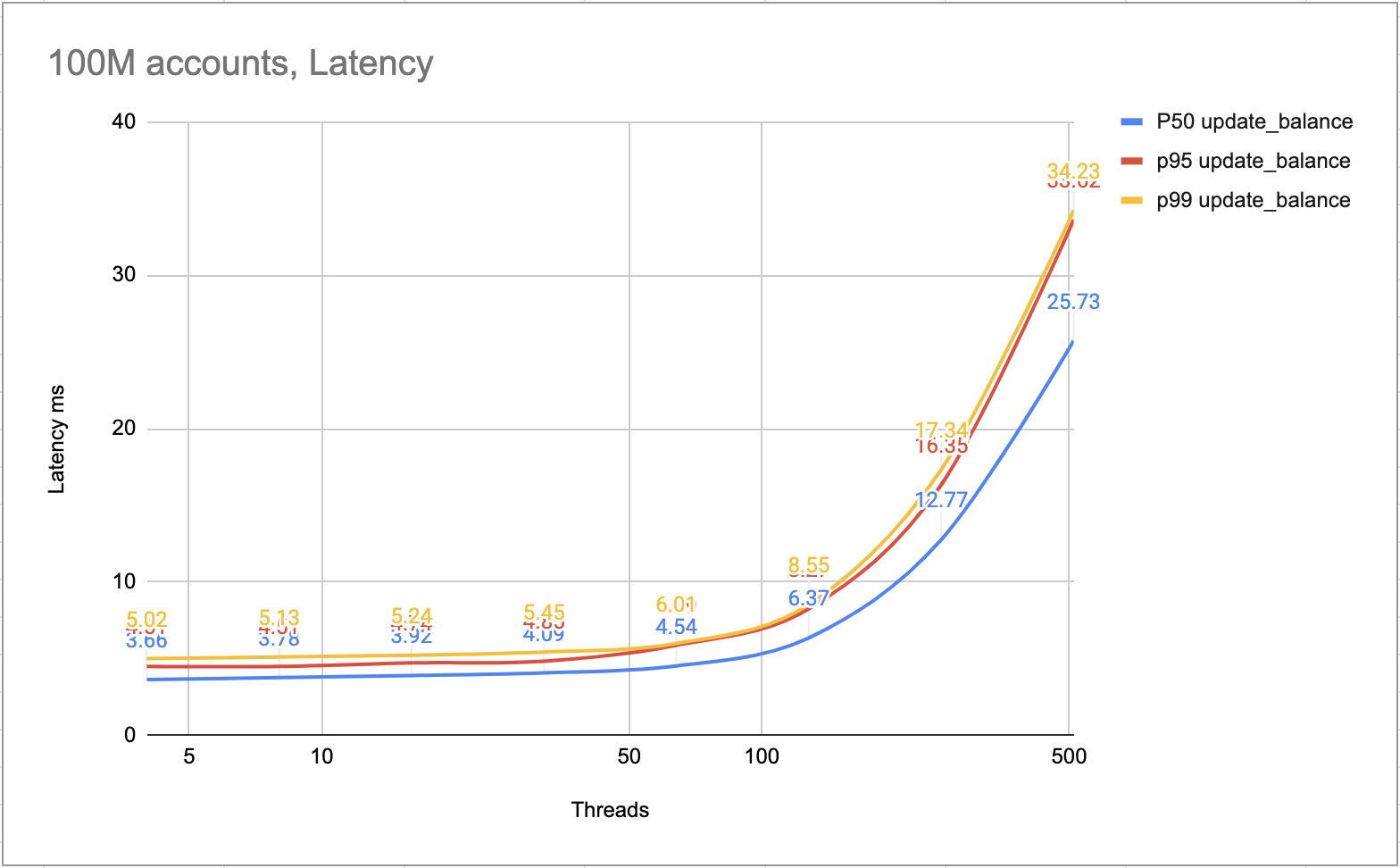
延遲毫秒
使用幣安賬本支持我們的服務
正如您所見,傳統行業對熱賬戶問題的回答並不能滿足幣安及其客戶的需求。通過使用專爲幣安基礎設施設計的方法,我們最終獲得了最順暢的交易和產品體驗之一。我們很高興現在與您分享我們的經驗,並希望您能更好地理解如何讓幣安這樣的服務發揮作用。
閱讀以下文章以獲取有關我們的技術基礎設施的更多信息:
(幣安博客)使用 MLOps 構建實時端到端機器學習管道
(幣安博客)會見首席技術官:Rohit 回顧加密貨幣、區塊鏈、Web3 以及他在幣安的第一個月
參考
[1] LMAX 破壞者
[2] RocksDB
[3] Raft 共識算法