
Bài học chính
Tại Binance, chúng tôi sử dụng máy học (ML) để giải quyết nhiều vấn đề kinh doanh khác nhau, bao gồm nhưng không giới hạn gian lận chiếm đoạt tài khoản (ATO), lừa đảo P2P và đánh cắp thông tin thanh toán.
Bằng cách sử dụng các hoạt động học máy (MLOps), các nhà khoa học dữ liệu AI của Binance Risk AI của chúng tôi đã xây dựng một quy trình ML toàn diện theo thời gian thực, liên tục cung cấp các dịch vụ ML sẵn sàng sản xuất.

Tại sao chúng ta sử dụng MLOps?
Đối với người mới bắt đầu, việc tạo dịch vụ ML là một quá trình lặp đi lặp lại. Các nhà khoa học dữ liệu liên tục thử nghiệm để cải thiện một số liệu cụ thể, ngoại tuyến hoặc trực tuyến, dựa trên mục tiêu mang lại giá trị cho doanh nghiệp. Vậy làm cách nào chúng tôi có thể giúp quá trình này hiệu quả hơn - ví dụ: rút ngắn thời gian đưa ra thị trường của mô hình ML?
Thứ hai, hành vi của dịch vụ ML không chỉ bị ảnh hưởng bởi mã mà chúng tôi, những nhà phát triển, xác định mà còn bởi dữ liệu mà nó thu thập. Ý tưởng này, còn được gọi là khái niệm trôi dạt, được nhấn mạnh trong bài báo của Google có tiêu đề Nợ kỹ thuật ẩn trong hệ thống học máy.
Lấy gian lận làm ví dụ; kẻ lừa đảo không chỉ là một cỗ máy mà còn là một con người có thể thích nghi và liên tục thay đổi cách chúng tấn công. Do đó, việc phân phối dữ liệu cơ bản sẽ phát triển để phản ánh những thay đổi trong vectơ tấn công. Làm thế nào chúng ta có thể đảm bảo mô hình sản xuất xem xét mẫu dữ liệu mới nhất một cách hiệu quả?
Để vượt qua những thách thức nêu trên, chúng tôi sử dụng một khái niệm gọi là MLOps, thuật ngữ được Google đề xuất lần đầu vào năm 2018. Trong MLOps, chúng tôi tập trung vào hiệu suất của mô hình và cơ sở hạ tầng hỗ trợ hệ thống sản xuất. Điều này cho phép chúng tôi xây dựng các dịch vụ ML có khả năng mở rộng, tính sẵn sàng cao, đáng tin cậy và có thể bảo trì.
Phá vỡ đường ống ML từ đầu đến cuối theo thời gian thực của chúng tôi
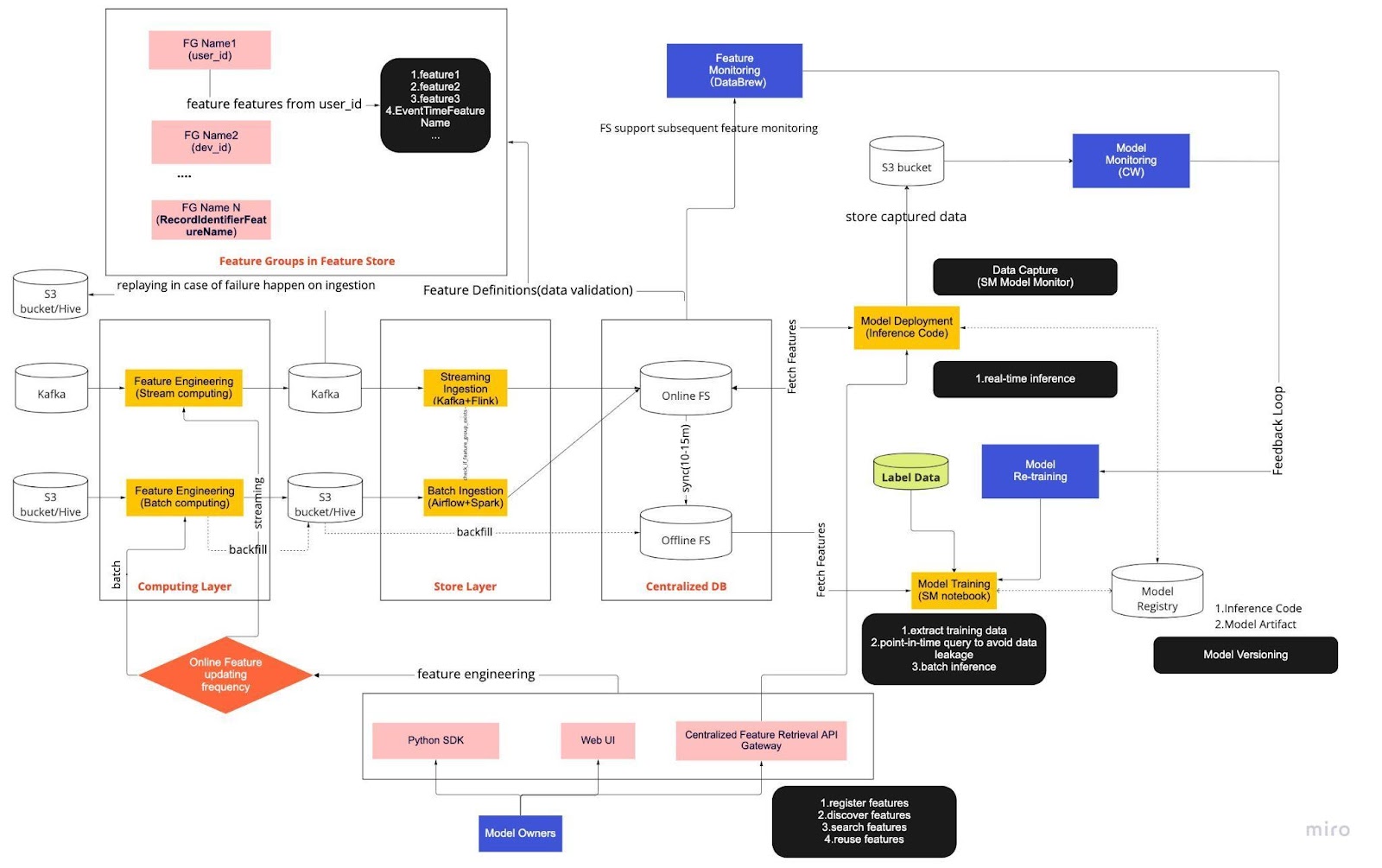
Hãy coi sơ đồ trên là quy trình vận hành (SOP) tiêu chuẩn của chúng tôi để phát triển mô hình thời gian thực với một cửa hàng tính năng. Quy trình ML từ đầu đến cuối chỉ ra cách nhóm của chúng tôi áp dụng MLops và được xây dựng với hai loại yêu cầu: chức năng và phi chức năng.
chức năng
Xử lí dữ liệu
Đào tạo người mẫu
Phát triển mô hình
Triển khai mô hình
Giám sát
những yêu cầu phi lý
Có thể mở rộng
Tính sẵn sàng cao
Đáng tin cậy
Có thể bảo trì
Đường ống được chia thành sáu thành phần chính:
Lớp tính toán
Lớp lưu trữ
Cơ sở dữ liệu tập trung
Đào tạo người mẫu
Triển khai mô hình
Giám sát mô hình
1. Lớp tính toán

Lớp điện toán chịu trách nhiệm chính về kỹ thuật tính năng, quá trình chuyển đổi dữ liệu thô thành các tính năng hữu ích.
Chúng tôi phân loại lớp điện toán thành hai loại dựa trên tần suất chúng cập nhật: tính toán luồng trong khoảng thời gian một phút/giây và tính toán hàng loạt trong khoảng thời gian hàng ngày/hàng giờ.
Dữ liệu đầu vào của lớp điện toán thường đến từ cơ sở dữ liệu dựa trên sự kiện, bao gồm Apache Kafka và Kinesis hoặc cơ sở dữ liệu OLAP, bao gồm Apache Hive cho nguồn mở và Snowflake cho các giải pháp đám mây.
2. Lớp lưu trữ
Lớp cửa hàng là nơi chúng tôi đăng ký các định nghĩa đối tượng và triển khai chúng vào kho đối tượng cũng như thực hiện chèn lấp, một quy trình cho phép chúng tôi xây dựng lại các đối tượng thông qua dữ liệu lịch sử bất cứ khi nào một đối tượng địa lý mới được xác định. Chèn lấp thường là công việc một lần mà các nhà khoa học dữ liệu của chúng tôi có thể thực hiện trong môi trường máy tính xách tay. Vì Kafka chỉ có thể lưu trữ các sự kiện trong bảy ngày qua nên nó sử dụng cơ chế sao lưu vào bảng s3/hive để tăng khả năng chịu lỗi.
Bạn sẽ nhận thấy lớp trung gian, Hive và Kafka, được cố tình đặt giữa lớp tính toán và lớp lưu trữ. Hãy coi vị trí này như một vùng đệm giữa tính năng tính toán và viết. Một sự tương tự sẽ tách biệt nhà sản xuất với người tiêu dùng. Điện toán luồng là nhà sản xuất, trong khi việc nhập luồng là người tiêu dùng.
Việc tách riêng tính toán và nhập dữ liệu mang lại nhiều lợi ích cho quy trình ML của chúng tôi. Đầu tiên, chúng ta có thể tăng cường độ bền của đường ống trong trường hợp có lỗi. Các nhà khoa học dữ liệu của chúng tôi vẫn có thể lấy giá trị tính năng từ cơ sở dữ liệu tập trung, ngay cả khi lớp nhập hoặc tính toán không khả dụng do sự cố vận hành, phần cứng hoặc mạng.
Hơn nữa, chúng tôi có thể mở rộng quy mô các phần khác nhau của cơ sở hạ tầng một cách riêng lẻ và giảm năng lượng cần thiết để xây dựng và vận hành đường ống. Ví dụ: nếu lỗi vì bất kỳ lý do gì thì lớp nhập sẽ không chặn lớp điện toán. Về mặt đổi mới, chúng tôi có thể thử nghiệm và áp dụng công nghệ mới, chẳng hạn như phiên bản mới của ứng dụng Flink mà không ảnh hưởng đến cơ sở hạ tầng hiện có của chúng tôi.

Cả lớp điện toán và lớp cửa hàng đều là những gì chúng tôi gọi là các đường dẫn tính năng tự động. Các đường dẫn này độc lập, chạy theo các lịch trình khác nhau và được phân loại thành các đường dẫn truyền trực tuyến hoặc theo đợt. Đây là cách hai quy trình hoạt động khác nhau: một nhóm tính năng trong quy trình hàng loạt có thể làm mới hàng đêm trong khi nhóm khác được cập nhật hàng giờ. Trong đường truyền phát trực tuyến, nhóm tính năng cập nhật theo thời gian thực khi dữ liệu nguồn đến luồng đầu vào, chẳng hạn như chủ đề Apache Kafka.
3. Cơ sở dữ liệu tập trung
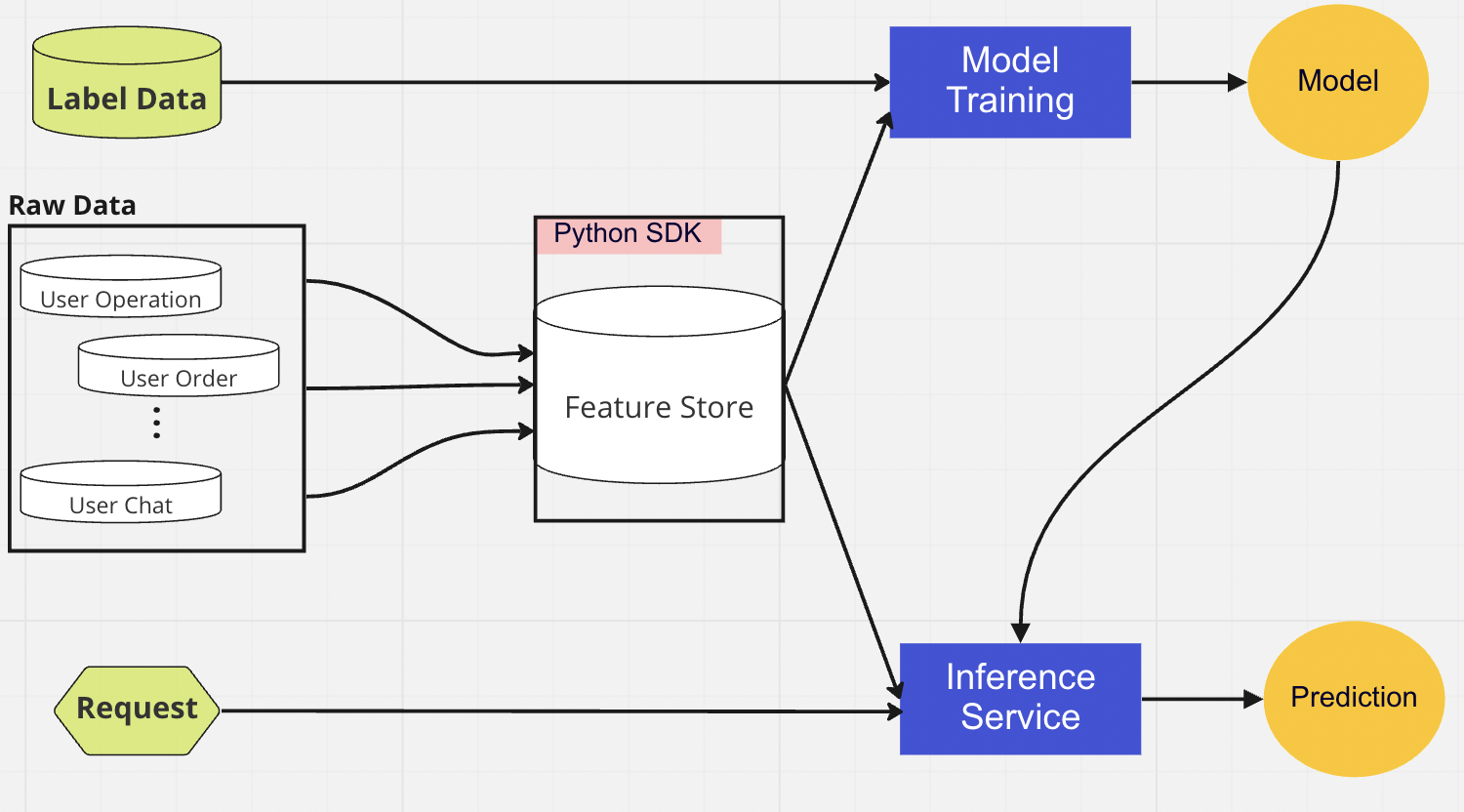
Lớp DB tập trung là nơi các nhà khoa học dữ liệu của chúng tôi trình bày dữ liệu sẵn sàng cho tính năng của họ vào kho tính năng trực tuyến hoặc ngoại tuyến.
Cửa hàng tính năng trực tuyến là cửa hàng có độ trễ thấp, tính sẵn sàng cao cho phép tra cứu hồ sơ theo thời gian thực. Mặt khác, kho tính năng ngoại tuyến cung cấp kho lưu trữ an toàn và có thể mở rộng cho tất cả dữ liệu tính năng. Điều này cho phép các nhà khoa học tạo các tập dữ liệu đào tạo, xác thực hoặc chấm điểm hàng loạt từ một tập hợp các nhóm đối tượng được quản lý tập trung với bản ghi lịch sử đầy đủ về các giá trị đối tượng trong hệ thống lưu trữ đối tượng.
Cả hai tính năng lưu trữ đều tự động đồng bộ hóa với nhau sau mỗi 10-15 phút để tránh tình trạng lệch pha khi phục vụ tập luyện. Trong bài viết sau, chúng tôi sẽ tìm hiểu sâu hơn về cách chúng tôi sử dụng các cửa hàng tính năng trong quy trình.
4. Đào tạo người mẫu
Lớp đào tạo mô hình là nơi các nhà khoa học của chúng tôi trích xuất dữ liệu đào tạo từ kho tính năng ngoại tuyến để hoàn thiện các dịch vụ ML của chúng tôi. Chúng tôi sử dụng các truy vấn tại thời điểm để ngăn dữ liệu bị rò rỉ trong quá trình trích xuất.
Ngoài ra, lớp này bao gồm một thành phần quan trọng được gọi là vòng phản hồi đào tạo lại mô hình. Đào tạo lại mô hình giảm thiểu nguy cơ sai lệch khái niệm bằng cách đảm bảo các mô hình được triển khai thể hiện chính xác các mẫu dữ liệu mới nhất - ví dụ: tin tặc thay đổi hành vi tấn công của chúng.
5. Triển khai mô hình
Để triển khai mô hình, chúng tôi chủ yếu sử dụng dịch vụ tính điểm dựa trên đám mây làm xương sống cho việc phân phối dữ liệu theo thời gian thực. Đây là sơ đồ cho thấy cách mã suy luận hiện tại tích hợp với kho tính năng.

6. Giám sát mô hình
Trong lớp này, nhóm của chúng tôi giám sát số liệu sử dụng để chấm điểm các dịch vụ như QPS, độ trễ, bộ nhớ và tốc độ sử dụng CPU/GPU. Bên cạnh các số liệu cơ bản này, chúng tôi sử dụng dữ liệu đã thu thập để kiểm tra việc phân bổ tính năng theo thời gian, độ lệch phục vụ đào tạo và độ lệch dự đoán để đảm bảo độ lệch khái niệm ở mức tối thiểu.
Bớt tư tưởng
Tóm lại, việc phân chia lỏng lẻo cơ sở hạ tầng quy trình của chúng tôi thành lớp điện toán, lớp lưu trữ và cơ sở dữ liệu tập trung mang lại cho chúng tôi ba lợi ích chính so với kiến trúc được liên kết chặt chẽ hơn.
Đường ống mạnh mẽ hơn trong trường hợp có sự cố
Tăng tính linh hoạt trong việc lựa chọn công cụ nào để triển khai
Các thành phần có khả năng mở rộng độc lập
Quan tâm đến việc sử dụng ML để bảo vệ hệ sinh thái tiền điện tử lớn nhất thế giới và người dùng của nó? Hãy xem Binance Engineering/AI trên trang tuyển dụng của chúng tôi để biết các tin tuyển dụng đang tuyển dụng.