
Stability AI vừa phát hành một bài báo mới trên blog của mình về Stable Diffusion 2. Trong bài báo, Stability AI đề xuất một thuật toán mới hiệu quả và mạnh mẽ hơn thuật toán trước đó, đồng thời so sánh nó với các phương pháp tiên tiến khác.

Mô hình Stable Diffusion V1 ban đầu của CompVis đã cách mạng hóa bản chất của các mô hình AI nguồn mở và tạo ra hàng trăm mô hình và tiến bộ khác nhau trên toàn thế giới. Nó đã chứng kiến một trong những lần leo lên nhanh nhất tới 10.000 sao trên Github, đạt 33.000 trong vòng chưa đầy hai tháng, nhanh hơn nhiều chương trình khác trên Github.
Bản phát hành Stable Diffusion V1 ban đầu được dẫn dắt bởi nhóm năng động Robin Rombach (Stability AI) và Patrick Esser (Runway ML) từ CompVis Group tại LMU Munich, do Giáo sư Tiến sĩ Björn Ommer dẫn đầu. Họ xây dựng dựa trên công trình trước đây của phòng thí nghiệm với Latent Diffusion Models và nhận được sự hỗ trợ quan trọng từ LAION và Eleuther AI.

 Điểm khác biệt giữa Stable Diffusion v1 và Stable Diffusion v2 là gì?
Điểm khác biệt giữa Stable Diffusion v1 và Stable Diffusion v2 là gì?
Phiên bản Stable Diffusion 2.0 bao gồm một số cải tiến và tính năng đáng kể so với phiên bản trước, chúng ta hãy cùng xem xét chúng.
Bản phát hành Stable Diffusion 2.0 có các mô hình văn bản thành hình ảnh mạnh mẽ được đào tạo bằng bộ mã hóa văn bản mới (OpenCLIP) do LAION phát triển với sự hỗ trợ của Stability AI, giúp nâng cao đáng kể chất lượng hình ảnh được tạo ra so với các bản phát hành V1 trước đó. Các mô hình văn bản thành hình ảnh của bản phát hành này có thể xuất hình ảnh với độ phân giải mặc định là 512×512 pixel và 768×768 pixel.
Các mô hình này được đào tạo bằng cách sử dụng tập hợp con thẩm mỹ của bộ dữ liệu LAION-5B do nhóm DeepFloyd của Stability AI tạo ra, sau đó được lọc để loại trừ nội dung dành cho người lớn bằng bộ lọc NSFW của LAION.
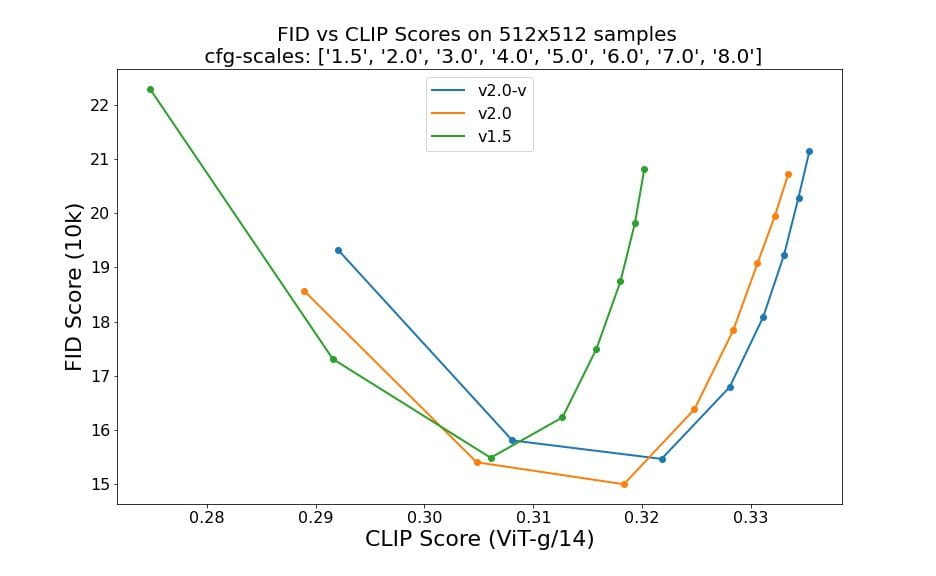
Đánh giá sử dụng 50 bước mẫu DDIM, 50 thang hướng dẫn không phân loại và 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 và 8,0 cho thấy sự cải thiện tương đối của các điểm kiểm tra:
Stable Diffusion 2.0 hiện kết hợp mô hình Upscaler Diffusion, giúp tăng độ phân giải hình ảnh lên gấp bốn lần. Một ví dụ về mô hình của chúng tôi nâng cấp hình ảnh được tạo ra có chất lượng thấp (128×128) thành hình ảnh có độ phân giải cao hơn được hiển thị bên dưới (512×512). Stable Diffusion 2.0, khi kết hợp với các mô hình chuyển đổi văn bản thành hình ảnh của chúng tôi, hiện có thể tạo ra hình ảnh có độ phân giải 2048×2048 hoặc cao hơn.

Mô hình khuếch tán ổn định hướng theo độ sâu mới, depth2img, mở rộng tính năng image-to-image trước đó từ V1 với các khả năng sáng tạo hoàn toàn mới. Depth2img xác định độ sâu của hình ảnh đầu vào (sử dụng mô hình hiện có) và sau đó tạo ra hình ảnh mới dựa trên cả văn bản và thông tin độ sâu. Depth-to-Image có thể cung cấp vô số ứng dụng sáng tạo mới, cung cấp những thay đổi có vẻ khác biệt đáng kể so với bản gốc trong khi vẫn giữ được tính mạch lạc và độ sâu của hình ảnh.
Có gì mới trong Stable Diffusion 2?
Mô hình khuếch tán ổn định mới cung cấp độ phân giải 768×768.
U-Net có cùng số lượng tham số như phiên bản 1.5, nhưng được đào tạo từ đầu và sử dụng OpenCLIP-ViT/H làm bộ mã hóa văn bản. Một mô hình được gọi là v-prediction là SD 2.0-v.
Mô hình nói trên được điều chỉnh từ cơ sở SD 2.0, cũng có sẵn và được đào tạo như một mô hình dự đoán nhiễu điển hình trên hình ảnh 512×512.
Đã thêm mô hình khuếch tán hướng dẫn văn bản tiềm ẩn với tỷ lệ x4.
Mô hình khuếch tán ổn định hướng độ sâu SD 2.0 tinh chỉnh. Mô hình có thể được sử dụng để bảo toàn cấu trúc img2img và tổng hợp có điều kiện hình dạng và được điều kiện hóa trên ước tính độ sâu đơn sắc do MiDaS suy ra.
Một mô hình tô màu hướng dẫn bằng văn bản được cải tiến dựa trên nền tảng SD 2.0.
Các nhà phát triển đã làm việc chăm chỉ, giống như lần lặp lại ban đầu của Stable Diffusion, để tối ưu hóa mô hình chạy trên một GPU duy nhất—họ muốn làm cho nó dễ tiếp cận với càng nhiều người càng tốt ngay từ đầu. Họ đã thấy điều gì xảy ra khi hàng triệu cá nhân có được những mô hình này và hợp tác để xây dựng những thứ hoàn toàn đáng chú ý. Đây chính là sức mạnh của mã nguồn mở: khai thác tiềm năng to lớn của hàng triệu người tài năng, những người có thể không có đủ nguồn lực để đào tạo một mô hình tiên tiến nhưng có khả năng làm những điều đáng kinh ngạc với một mô hình.

Bản cập nhật mới này, kết hợp với các tính năng mới mạnh mẽ như depth2img và khả năng nâng cấp độ phân giải tốt hơn, sẽ trở thành nền tảng cho vô số ứng dụng mới và tạo ra sự bùng nổ tiềm năng sáng tạo mới.
Đọc thêm về khuếch tán ổn định:
Trí tuệ nhân tạo khuếch tán ổn định tạo ra thế giới trong mơ cho VR và Metaverse
Nghệ sĩ sử dụng Stable Diffusion để sản xuất bộ phim hoạt hình AI đầy đủ đầu tiên
Làm quen với video inpainting: chỉnh sửa theo văn bản với Stable Diffusion và Neural Atlases
Bài đăng Thuật toán khuếch tán ổn định 2 của Stability AI cuối cùng đã được công bố: mô hình depth2img mới, trình nâng cấp độ phân giải siêu cao, không có nội dung dành cho người lớn xuất hiện đầu tiên trên Metaverse Post.