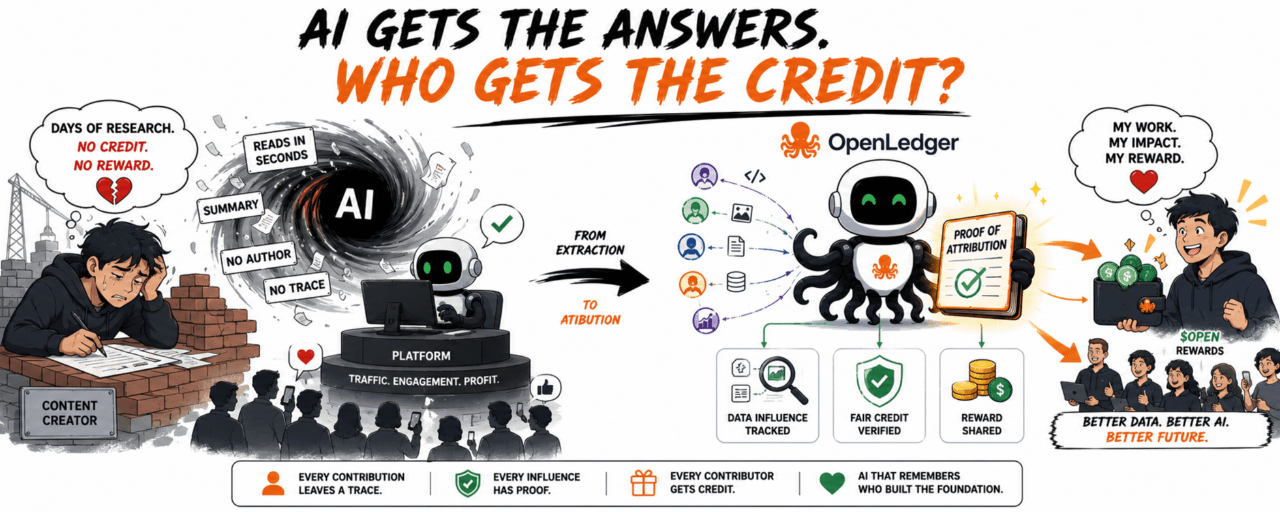
Giữa năm 2024, mình bắt đầu thấy nhiều creator than một chuyện khá khó chịu: bài họ viết mất vài ngày research, AI đọc vài giây, rồi biến thành một câu trả lời gọn gàng không còn dấu tác giả. Người đọc thấy tiện. Platform giữ traffic. Còn người làm nội dung thì giống ông thợ hồ xây cả căn nhà, xong tên trên sổ đỏ lại là người khác.
Lúc đó mình mới thấy vấn đề của AI không chỉ là “lấy data để train”.
Nó đang dùng công lao của người khác mà không có cuốn sổ ghi nợ tử tế.
Và thật lòng, lúc đầu nhìn @OpenLedger mình cũng hơi nghi ngờ. Crypto giờ cứ dự án nào gắn thêm chữ AI là nghe như quán bún bò đổi bảng thành “AI Kitchen” rồi gọi vốn. Nhưng càng đọc kỹ, mình thấy OpenLedger không chỉ kể chuyện thêm một AI chain.
Nó đang chạm vào câu hỏi rất đời:
Nếu dữ liệu giúp AI kiếm tiền, ai được ghi công?

Ethereum ghi lại ai chuyển tiền cho ai. Bittensor nghiêng nhiều về compute và network intelligence. Còn OpenLedger đi vào phần ít hào nhoáng hơn: dữ liệu nào đã ảnh hưởng tới output của AI, và người góp dữ liệu đó có được ghi nhận không.
Nói đời hơn, AI hiện tại giống một team làm video nhưng credit cuối clip chỉ ghi tên mỗi platform. Script người khác viết, footage người khác quay, nhạc người khác chọn, feedback user góp từng chút một. Cuối cùng sản phẩm lên sóng, người đứng sau biến mất như chưa từng tồn tại.
OpenLedger muốn kéo phần credit đó trở lại bằng Proof of Attribution.
Ví dụ một nhóm chuyên soi scam on-chain ở Đông Nam Á có bộ dữ liệu nhỏ thôi: ví lừa đảo, contract giả airdrop, mẫu phishing, mấy chiêu KOL rác hay dùng để dụ retail. Bình thường data kiểu này rất dễ bị copy, đem đi train, rồi mất dấu. Nhưng nếu một security agent dùng chính dữ liệu đó để cảnh báo user trước khi ký giao dịch, contribution có thể được ghi nhận và reward qua $OPEN.
Nghe nhỏ, nhưng với retail thì một cảnh báo đúng lúc có thể cứu cả ví.
Vấn đề là hệ thống không chỉ cần biết “ai upload data”. Cái khó hơn là biết data đó có thật sự giúp model trả lời tốt hơn không. Nếu chỉ upload là được tính công, game này sẽ nát rất nhanh.
Có reward là có farmer.
Có attribution là có người giả làm contributor.
Data rác sẽ mặc áo “domain knowledge”.
Thread copy sẽ cosplay research.
Spam sẽ được đóng gói như dataset sạch.
Điểm yếu nữa là influence score. Nếu điểm ảnh hưởng này không đủ minh bạch, contributor sẽ rất khó tin hệ thống. Người góp data tốt mà nhận ít reward sẽ hỏi tại sao. Data rác được điểm cao thì khỏi hỏi, vì nó đang hưởng lợi rồi.
Một bộ dữ liệu nhỏ nhưng sạch có thể đáng giá hơn cả triệu dòng nội dung tái chế.
Và đây là góc mình thấy đáng theo dõi nhất: AI sau này có thể không thắng chỉ vì trả lời hay hơn, mà vì chứng minh được nó học từ đâu.
Model nào phân biệt được data thật với tiếng ồn mới có cửa sống lâu.
Đó là bài toán OpenLedger đang cố chạm vào.
