Sáng nay, mình đang sắp xếp một bảng ghi chú cũ về các mô hình AI từng gây ồn ào, và một cảm giác quen thuộc quay trở lại, những thứ thị trường ca ngợi lớn tiếng thường không phải là những thứ hiểu sâu sắc nhất. Đó chính xác là nơi Openledger thu hút sự chú ý của mình, không phải vì nó nói to hơn những cái khác, mà vì nó nhắm đến một vấn đề nhỏ hơn, khó hơn và thực tế hơn, cách mà những túi kiến thức chuyên môn cao, dày đặc bối cảnh, vẫn có thể giữ một chỗ đứng riêng thay vì biến mất vào đám đông hiểu biết trung bình.
Điều khiến mình ở lại lâu hơn nằm ở Datanets. Nhiều dự án nói về dữ liệu theo những cách rất rộng, như thể tập hợp đủ dữ liệu đã là đủ. Cách suy nghĩ đó hoạt động trên bề mặt, nhưng bỏ lỡ bản chất của kiến thức ngách, nơi độ chính xác không đến từ quy mô, mà từ cấu trúc, bối cảnh và nhãn. Openledger đi theo một hướng khác bằng cách cố gắng bảo tồn ranh giới của dữ liệu, với nguồn gốc, người đóng góp, điều kiện sử dụng và thời gian ghi lại nguyên vẹn. Kiến thức hẹp thường không biến mất vì thiếu giá trị, mà biến mất vì bị hòa tan quá sớm.
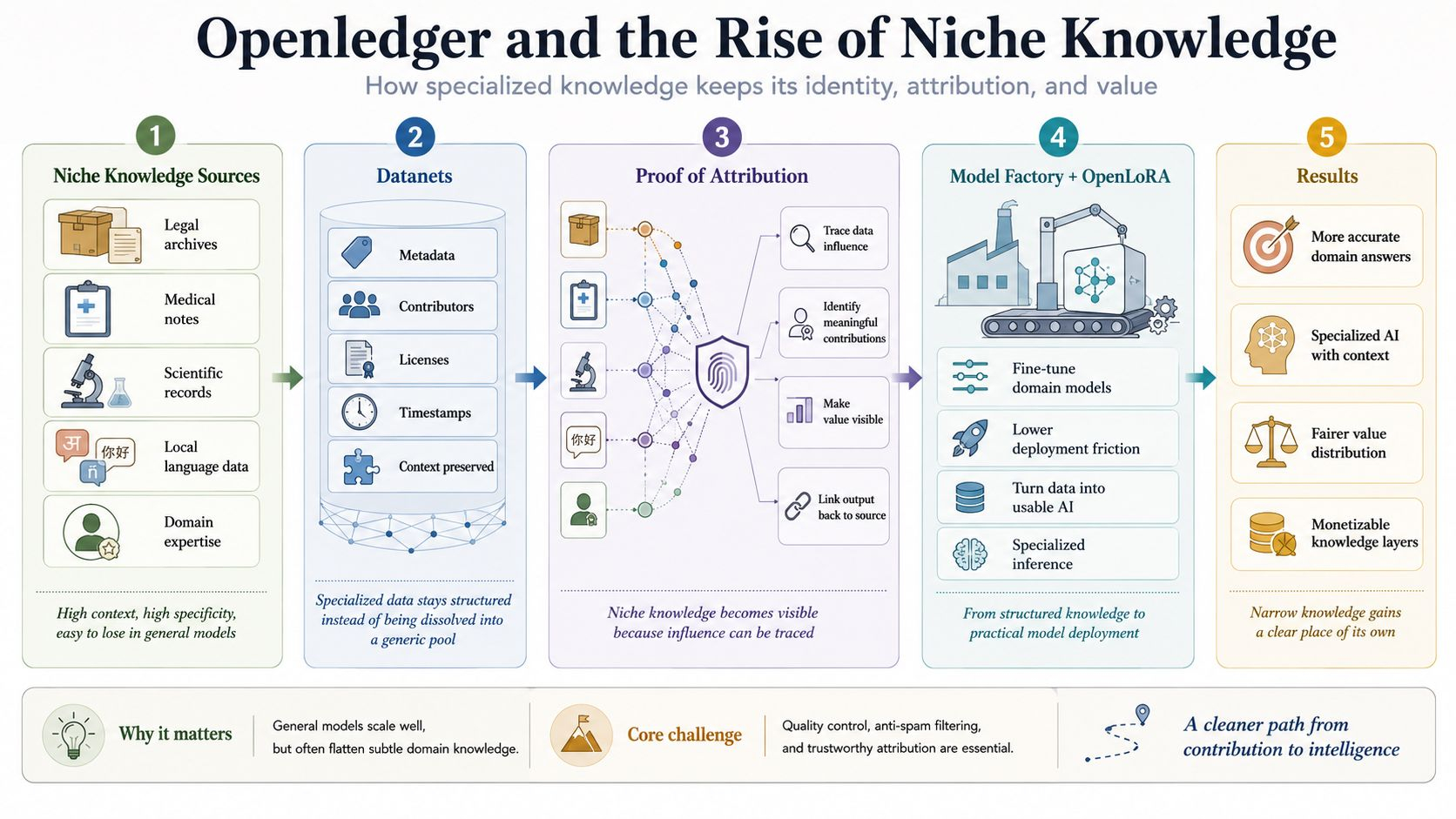
Đó là lý do tại sao dự án này không thể được đọc đơn giản như một nơi tập hợp dữ liệu và sau đó đưa nó vào đào tạo mô hình. Điều quan trọng hơn nhiều là Openledger đang cố gắng biến dữ liệu chuyên môn thành một lớp có quyền tồn tại riêng. Khi dữ liệu được tổ chức như một đơn vị có thể tính toán, câu hỏi về đóng góp không còn nằm ở cấp độ đạo đức, mà chuyển sang cấp độ kiến trúc. Mình đã trải qua đủ vòng đời để thấy rằng thị trường luôn thích nói về mô hình hoặc sản phẩm cuối cùng, trong khi phần thực sự tạo ra độ chính xác lại bị đẩy lùi vào bóng tối.
Đó chính xác là lý do tại sao Proof of Attribution là phần mình đánh giá cao nhất. Nhiều người nghe thấy thuật ngữ đó và cho rằng nó chỉ là một lớp phụ thêm vào để làm cho câu chuyện nghe hay hơn, nhưng thực tế đây là nơi Openledger đặt cược vào sự thay đổi khó khăn nhất, truy tìm các tập dữ liệu nào ảnh hưởng đến một đầu ra và những đóng góp nào mang trọng số thực sự. Bất kỳ ai đã xây dựng hệ thống dữ liệu chắc chắn hiểu điều này, theo dõi ảnh hưởng chưa bao giờ dễ dàng, đặc biệt khi các đầu ra được tạo ra thông qua nhiều lớp xử lý chồng chất. Nhưng chính sự khó khăn đó mới tạo ra giá trị.
Đi một bước xa hơn, mình nghĩ ý tưởng này chỉ đứng vững nếu việc ghi nhận không tách rời khỏi việc triển khai mô hình. Đó là nơi Model Factory và OpenLoRA xuất hiện như hai phần không thể coi là thứ yếu. Openledger không chỉ muốn bảo tồn dấu vết của kiến thức chuyên môn, mà còn muốn mở ra một con đường cho dữ liệu di chuyển vào các mô hình tinh chỉnh và sau đó vào hoạt động thực tế mà không chết giữa chừng vì chi phí quá cao hoặc quá trình quá nặng nề. Nhiều ý tưởng đúng thất bại đơn giản vì khoảng cách từ dữ liệu đến ứng dụng dài hơn sức chịu đựng của người xây dựng.
Mình cũng không nhìn câu chuyện này với sự mềm mại nào. Bất kỳ hệ thống nào gắn thưởng với ảnh hưởng dữ liệu cuối cùng sẽ gặp phải mặt tối của động lực. Mọi người có thể đổ dồn dữ liệu vào chỉ để chen chân vào chuỗi ghi nhận. Họ cũng có thể học cách tối ưu hóa để được tính là có ảnh hưởng thay vì thực sự cải thiện độ chính xác. Chính vì lý do đó, Openledger cần nhiều hơn một ý tưởng đúng, nó cần một kỷ luật rất nghiêm ngặt trong việc lọc và lựa chọn. Thật lòng mà nói, đây là nơi nhiều dự án cuối cùng tiết lộ bản chất thật của chúng.
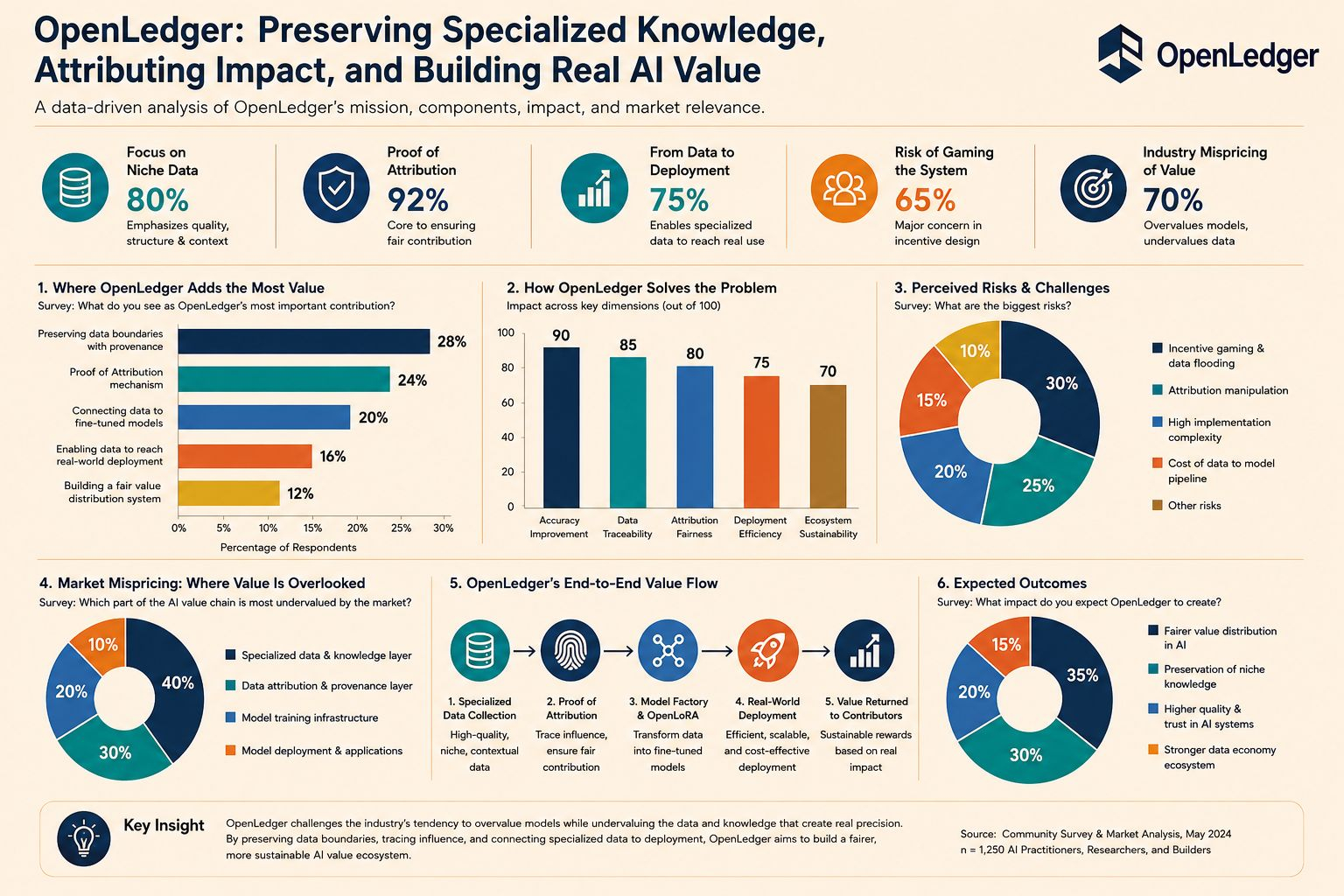
Điều làm mình trân trọng nỗ lực này là nó đi ngược lại với bản năng quen thuộc của ngành. Thay vì xây dựng một lớp mô hình khác tuyên bố hiểu mọi thứ, Openledger ngầm thừa nhận rằng có những lĩnh vực kiến thức không nên bị ép vào logic trung bình. Chuyên môn sâu trong các lĩnh vực hẹp không cần phải được thổi phồng thành một câu chuyện lớn, nó cần một đường ống đủ sạch để bảo tồn bối cảnh và đóng góp tạo ra độ chính xác. Đó là một sự khác biệt về lập trường, không chỉ là một lựa chọn kỹ thuật.
Điều mình thấy đáng suy nghĩ nhất sau khi nhìn kỹ vào cấu trúc này là thị trường có thể đã định giá sai giá trị ngay từ đầu, thưởng cho lớp tổng hợp cuối cùng hào phóng trong khi đánh giá thấp lớp kiến thức yên ắng tạo ra độ chính xác. Khi một hệ thống cố gắng bảo tồn ranh giới dữ liệu, theo dõi ảnh hưởng, kết nối dữ liệu chuyên môn với các mô hình tinh chỉnh, và đưa vào sử dụng thực tế, Openledger đang cố gắng điều chỉnh cách giá trị được phân phối trong AI theo một cách nghiêm ngặt hơn. Và nếu Openledger thực sự có thể giữ kiến thức hẹp không chìm vào sự mờ nhạt giữa đóng góp và sản phẩm đầu ra, liệu thị trường vẫn tiếp tục thờ phượng trí tuệ rộng nhưng nông như một tiêu chuẩn đủ tốt không?