

Vào đầu tháng 9, Yandex đã tổ chức một hội nghị nhỏ riêng về AI tổng hợp, cung cấp nền tảng để tìm hiểu sâu hơn về thế giới AI. Tuy nhiên, hội nghị đã đưa ra những tiết lộ quan trọng, đặc biệt liên quan đến YandexGPT 2 rất được mong đợi.
Việc Yandex ra mắt YandexGPT 2 đã khiến cộng đồng AI xôn xao mong đợi. Những người tạo ra mô hình này đã khám phá nhiều tính năng khác biệt, bao gồm một mô-đun chuyên biệt được thiết kế để tìm kiếm và cung cấp câu trả lời dựa trên dữ liệu kết quả tìm kiếm. Đáng chú ý, những tiết lộ của nhóm đã tiết lộ một khía cạnh nổi bật: ngay cả khi được đào tạo trên kho dữ liệu Yandex nội bộ khổng lồ kéo dài hơn một thập kỷ làm việc về các cơ chế tìm kiếm thần kinh, mô hình độc quyền này vẫn không thể so sánh với GPT-4 đáng gờm. Sự phát triển đáng kể này nhấn mạnh những bước tiến đáng chú ý mà GPT-4 đạt được. Quan sát này nhấn mạnh tính ưu việt của GPT-4 đối với cả các phát triển độc quyền và các lần lặp lại nguồn mở trước đó.
Mở rộng dựa trên những hiểu biết cơ bản như vậy, Google đã thực hiện một nghiên cứu để đánh giá tính chính xác của các phản hồi từ Mô hình ngôn ngữ lớn (LLM) được hỗ trợ quyền truy cập công cụ tìm kiếm. Mặc dù khái niệm tích hợp một công cụ bên ngoài với LLM không phải là mới, nhưng Google nhận thấy rằng sự phức tạp nằm ở việc đánh giá và xác thực các mô hình này theo nhiều sắc thái. Các yếu tố quan trọng hình thành nên sự tích hợp này bao gồm việc lựa chọn lời nhắc được chế tạo cẩn thận và khả năng nội tại của LLM.
Phương pháp kiểm tra LLM của Google
Một kho dữ liệu tuyển chọn gồm 600 câu hỏi được chia thành bốn nhóm riêng biệt. Mỗi nhóm ưu tiên độ chính xác thực tế, nhưng một nhóm nổi bật nhờ đưa vào các câu hỏi bắt nguồn từ những tiền đề sai lầm. Ví dụ: những câu hỏi như “Trump đã viết gì sau khi được gỡ cấm trên Twitter?” chứa một tiền đề không chính xác, vì Trump vẫn chưa bị cấm. Ba nhóm còn lại đưa ra các biến số về lỗi thời của câu trả lời: không bao giờ, hiếm khi và thường xuyên. Trong nhóm “không bao giờ”, LLM được kỳ vọng sẽ trả lời hoàn toàn từ trí nhớ, trong khi các câu hỏi về các sự kiện gần đây yêu cầu tìm kiếm theo thời gian thực. Mỗi nhóm bao gồm 125 câu hỏi.
Các câu hỏi được đưa ra cho nhiều mô hình khác nhau. Điều thú vị là, các câu hỏi chứa tiền đề sai đã tiết lộ sự thống trị của GPT-4 và ChatGPT, vốn đã bác bỏ một cách thành thạo những tiền đề đó, cho thấy họ đã được đào tạo cụ thể để xử lý những thách thức đó.
Một phân tích so sánh được thực hiện sau đó, so sánh ChatGPT, GPT-4, tìm kiếm Google (dựa trên đoạn văn bản hoặc câu trả lời trên trang đầu tiên) và PPLX.AI (một nền tảng tận dụng ChatGPT để tổng hợp các phản hồi của Google, nhắm đến các nhà phát triển) với nhau. Trong bối cảnh này, LLM chỉ cung cấp câu trả lời từ trí nhớ của họ.
Trong một quan sát đáng chú ý, tìm kiếm của Google cung cấp câu trả lời đúng trung bình trong 40% trường hợp trong bốn nhóm. Độ chính xác của các câu hỏi “vĩnh viễn” đứng ở mức 70%, trong khi các câu hỏi tiền đề sai giảm mạnh xuống chỉ còn 11%. Hiệu suất của ChatGPT đạt trung bình 26%, trong khi GPT-4 đạt 28%, phản hồi một cách ấn tượng với các câu hỏi tiền đề sai trong 42% trường hợp. PPLX.AI đã chứng minh tỷ lệ thành công là 52%.
Nghiên cứu đã đào sâu hơn bằng cách tích hợp một cách tiếp cận mới. Mỗi câu hỏi đều nhắc nhở một tìm kiếm trên Google, với các kết quả được đưa vào lời nhắc. LLM sau đó được yêu cầu “đọc” thông tin này trước khi soạn câu trả lời của họ. Kỹ thuật này cho phép học ít lần (trong đó các ví dụ được trình bày trong lời nhắc để hướng dẫn mô hình) và cân nhắc kỹ lưỡng từng bước trước khi trả lời.
Kết quả không có gì đáng ngạc nhiên. GPT-4 thể hiện xếp hạng chất lượng đáng chú ý là 77%, trả lời các câu hỏi “vĩnh viễn” với độ chính xác 96% và giải quyết các câu hỏi tiền đề sai với độ chính xác đáng khen ngợi là 75%. Mặc dù ChatGPT cung cấp các số liệu kém ấn tượng hơn một chút nhưng nó lại hoạt động tốt hơn cả PPLX.AI và tìm kiếm Google.
Nắm vững thiết kế nhắc nhở AI: Thông tin chi tiết chính từ PPLX.AI và các chuyên gia Google
Khả năng hướng dẫn các Mô hình Ngôn ngữ Lớn (LLM) một cách hiệu quả thông qua mê cung thông tin là một kỳ công không hề nhỏ. Tuy nhiên, một cuộc khám phá gần đây về các gợi ý của AI đã làm sáng tỏ các chiến lược chính hứa hẹn nâng cao chất lượng phản hồi do LLM tạo ra, mang đến cái nhìn thoáng qua về cơ chế hỗ trợ AI đa sắc thái.
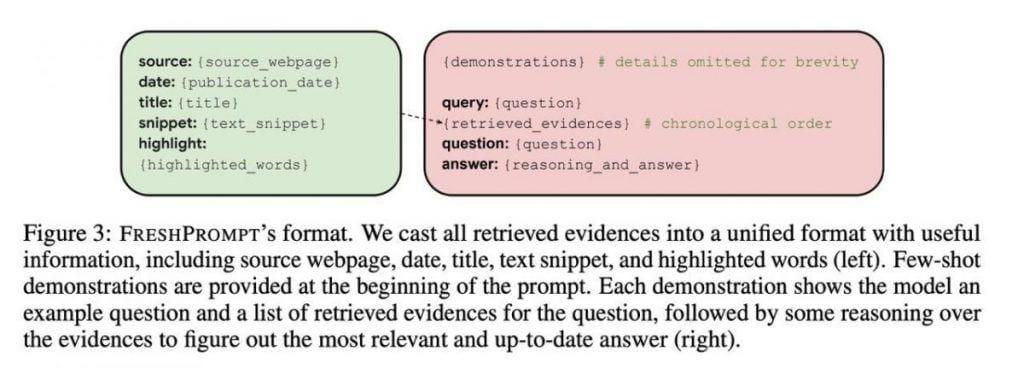
Nền tảng cho sự mặc khải này được thiết lập thông qua cấu trúc kịp thời cẩn thận. Phương pháp này bao gồm nhiều thành phần, đưa ra một lộ trình rõ ràng để đạt được câu trả lời chính xác, có nền tảng vững chắc trong việc hiểu ngữ cảnh. Khía cạnh ban đầu bao gồm các ví dụ minh họa, đóng vai trò là điểm đánh dấu hướng dẫn, hướng LLM đến câu trả lời đúng dựa trên manh mối theo ngữ cảnh.
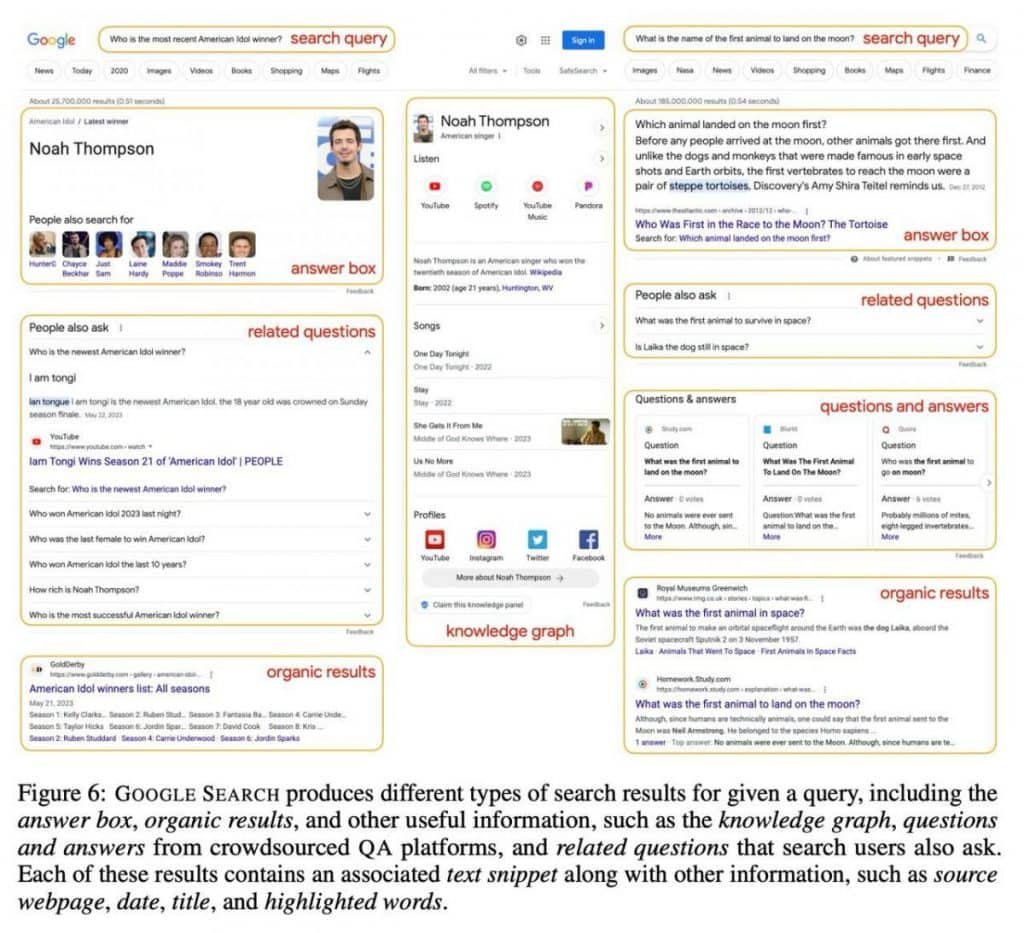
lớp thứ hai hiển thị truy vấn thực tế cùng với 10-15 kết quả tìm kiếm. Những kết quả này vượt xa các liên kết trang web đơn thuần, bao gồm rất nhiều thông tin, bao gồm nội dung văn bản, truy vấn, câu hỏi, câu trả lời và biểu đồ kiến thức có liên quan. Cách tiếp cận này trang bị cho AI một thư viện kiến thức toàn diện.
Sự tinh vi của hệ thống này còn đi xa hơn nữa. Một khám phá quan trọng đã xuất hiện khi sắp xếp các liên kết theo trình tự thời gian trong lời nhắc, đặt những phần bổ sung gần đây nhất ở cuối. Sự sắp xếp theo trình tự thời gian này phản ánh bản chất phát triển của thông tin, cho phép mô hình phân biệt dòng thời gian của những thay đổi. Việc đưa ngày tháng vào mỗi ví dụ đóng một vai trò then chốt trong việc nâng cao hiểu biết về ngữ cảnh.
Mặc dù mã sử dụng cấu trúc lời nhắc đầy sắc thái này được nhiều người háo hức mong đợi nhưng sự vắng mặt của nó đã thúc đẩy những người đam mê mạo hiểm viết lại các mẫu lời nhắc dựa trên hình ảnh được cung cấp.
Một số điểm rút ra quan trọng xuất hiện từ bước đột phá này vào cơ chế của lời nhắc AI:
1) PPLX.AI, một nền tảng tận dụng ChatGPT để tổng hợp các phản hồi của Google, đã nổi lên như một lựa chọn đầy hứa hẹn. Ngay cả nhân viên của Google cũng bóng gió về tính ưu việt của nó.
2) Thử nghiệm với nhiều yếu tố khác nhau đã mang lại những cải tiến về số liệu phản hồi. Có vẻ như sự chính xác trong việc xây dựng nhanh chóng đã là một nghệ thuật.
3) GPT-4 thể hiện trình độ đáng khen ngợi trong việc xử lý nhiều bộ tin tức và văn bản. Mặc dù nó có thể không được coi là “xuất sắc”, nhưng chất lượng của nó ngay cả trong các tình huống tin tức thay đổi nhanh chóng vẫn dao động quanh mốc 60%. Cộng đồng AI được khuyến khích đánh giá các số liệu đó một cách nghiêm túc.
4) Khi hệ sinh thái AI tiếp tục mở rộng, LLM được tích hợp vào các công cụ tìm kiếm sẽ sẵn sàng trở nên phổ biến, phục vụ nhiều đối tượng người dùng. Sự hiện diện của AI trong trải nghiệm tìm kiếm hàng ngày đang có xu hướng đi lên, biểu thị sự thay đổi mang tính biến đổi trong cách truy cập và xử lý thông tin.
Cách tiếp cận nhiều mặt mang đến một cách đầy hứa hẹn để có được câu trả lời chính xác từ các mô hình ngôn ngữ phức tạp này vì nó bao gồm các ví dụ minh họa, truy vấn được xác định rõ ràng và vô số thông tin theo ngữ cảnh. Sự sắp xếp theo thứ tự thời gian của các liên kết trong các gợi ý đã mang lại sự hiểu biết sâu sắc, nhấn mạnh tầm quan trọng của việc thích ứng với tính chất năng động của thông tin. LLM có thể điều hướng dòng thời gian của những thay đổi nhờ vào nhận thức tạm thời này, giúp cải thiện khả năng hiểu ngữ cảnh của họ.
Bài đăng Phân tích của Google tiết lộ những hiểu biết đáng ngạc nhiên về LLM và Độ chính xác của Công cụ Tìm kiếm xuất hiện đầu tiên trên Metaverse Post.