
Cung cấp các tính năng machine learning chính xác, nhất quán và sẵn sàng cho sản xuất.

Phần này khám phá kho tính năng học máy (ML) của chúng tôi chi tiết hơn. Đây là phần tiếp theo của bài đăng trên blog trước đây của chúng tôi, cung cấp cái nhìn tổng quan rộng hơn về toàn bộ cơ sở hạ tầng đường ống ML.
Tại sao chúng ta sử dụng một cửa hàng tính năng?
Cửa hàng tính năng, một trong nhiều bộ phận trong hệ thống của chúng tôi, được cho là bánh răng quan trọng nhất trong hệ thống. Mục đích chính của nó là hoạt động như một cơ sở dữ liệu trung tâm quản lý các tính năng trước khi chúng được chuyển đi để đào tạo hoặc suy luận mô hình.
Nếu bạn không quen với thuật ngữ này thì các tính năng về cơ bản là dữ liệu thô được tinh chỉnh, thông qua một quy trình gọi là kỹ thuật tính năng, thành thứ gì đó hữu dụng hơn mà các mô hình ML của chúng tôi có thể sử dụng để tự huấn luyện hoặc tính toán dự đoán.
Tóm lại, các cửa hàng tính năng cho phép chúng tôi:
Tái sử dụng và chia sẻ các tính năng giữa các mô hình và nhóm khác nhau
Rút ngắn thời gian cần thiết cho các thử nghiệm ML
Giảm thiểu các dự đoán không chính xác do độ lệch phân phát đào tạo nghiêm trọng
Để hiểu rõ hơn về tầm quan trọng của cửa hàng tính năng, đây là sơ đồ của đường dẫn ML không sử dụng cửa hàng tính năng.
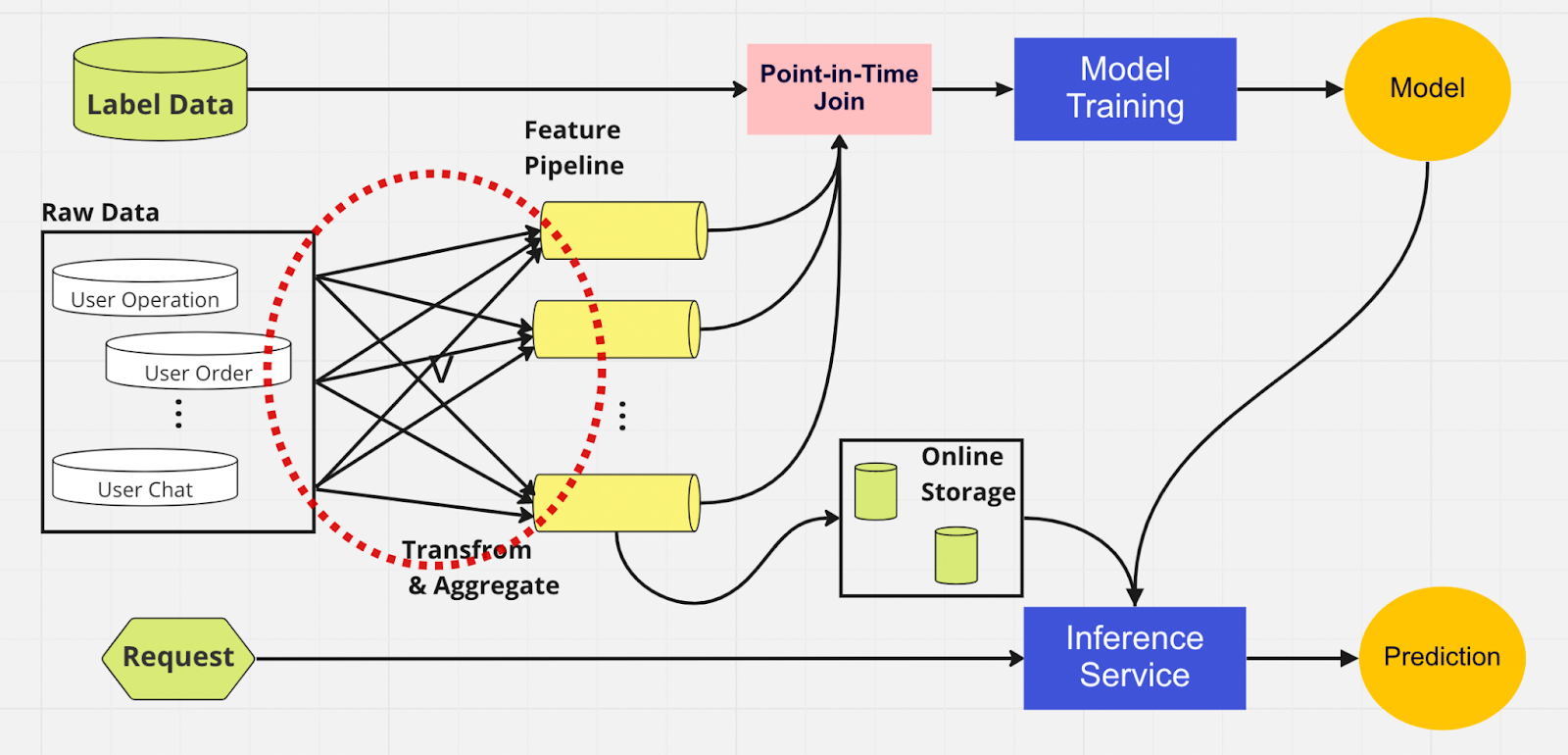
Trong quy trình này, hai phần — dịch vụ đào tạo mô hình và suy luận — không thể xác định tính năng nào đã tồn tại và có thể được sử dụng lại. Điều này dẫn đến quy trình ML sao chép quy trình kỹ thuật tính năng. Bạn sẽ nhận thấy trong vòng tròn màu đỏ trên sơ đồ rằng quy trình ML, thay vì sử dụng lại các tính năng, đã xây dựng một nhóm các tính năng trùng lặp và quy trình dự phòng. Chúng tôi gọi nhóm này là một nhóm tính năng mở rộng.
Việc duy trì nhiều tính năng này trở thành một tình huống ngày càng tốn kém và khó quản lý khi doanh nghiệp phát triển và ngày càng có nhiều người dùng tham gia vào nền tảng. Hãy suy nghĩ về nó theo cách này; nhà khoa học dữ liệu phải bắt đầu quy trình kỹ thuật tính năng vốn dài và tẻ nhạt, hoàn toàn từ đầu cho mỗi mô hình mới mà họ tạo ra.
Ngoài ra, việc triển khai lại logic tính năng quá nhiều sẽ dẫn đến một khái niệm gọi là độ lệch phục vụ đào tạo, đó là sự khác biệt giữa dữ liệu trong giai đoạn đào tạo và suy luận. Nó dẫn đến những dự đoán không chính xác và hành vi không thể đoán trước của mô hình, khó khắc phục sự cố trong quá trình sản xuất. Trước khi lưu trữ tính năng, các nhà khoa học dữ liệu của chúng tôi sẽ kiểm tra tính nhất quán của tính năng bằng cách sử dụng tính năng kiểm tra độ tỉnh táo. Đây là một quy trình thủ công, tốn thời gian giúp chuyển hướng sự chú ý khỏi các nhiệm vụ có mức độ ưu tiên cao hơn như lập mô hình và kỹ thuật tính năng chuyên sâu. Bây giờ, hãy cùng khám phá quy trình ML với một cửa hàng tính năng.

Tương tự như quy trình khác, chúng tôi có cùng nguồn dữ liệu và tính năng ở phía bên trái. Tuy nhiên, thay vì trải qua nhiều quy trình tính năng, chúng tôi coi cửa hàng tính năng là một trung tâm phục vụ cả hai giai đoạn của quy trình ML (dịch vụ suy luận và đào tạo mô hình). Không có tính năng trùng lặp; tất cả các quy trình cần thiết để xây dựng một tính năng, bao gồm cả chuyển đổi và tổng hợp, chỉ cần được thực hiện một lần.
Các nhà khoa học dữ liệu có thể tương tác trực quan với kho tính năng bằng cách sử dụng SDK Python được xây dựng tùy chỉnh của chúng tôi để tìm kiếm, tái sử dụng và khám phá các tính năng nhằm đào tạo và suy luận mô hình ML xuôi dòng.
Về cơ bản, kho tính năng là một cơ sở dữ liệu tập trung thống nhất cả hai giai đoạn. Và vì kho tính năng đảm bảo các tính năng nhất quán cho việc đào tạo và suy luận, nên chúng tôi có thể giảm đáng kể độ lệch phục vụ đào tạo.
Lưu ý rằng các cửa hàng tính năng còn làm được nhiều việc hơn những điểm chúng tôi đã đề cập ở trên. Tất nhiên, đây là bản tóm tắt sơ bộ hơn về lý do tại sao chúng tôi sử dụng kho tính năng và là bản tóm tắt mà chúng tôi có thể chia nhỏ thành một vài từ: chuẩn bị và gửi các tính năng vào mô hình ML theo cách nhanh nhất, dễ dàng nhất có thể.
Bên trong Cửa hàng Tính năng

Hình trên cho thấy bố cục cửa hàng tính năng điển hình của bạn, có thể là AWS SageMaker Feature Store, Google vertex AI (Feast), Azure (Feathr), Iguazio hoặc Tetcom. Tất cả các cửa hàng tính năng đều cung cấp hai loại lưu trữ: trực tuyến hoặc ngoại tuyến.
Các cửa hàng tính năng trực tuyến được sử dụng để suy luận theo thời gian thực, trong khi các cửa hàng tính năng ngoại tuyến được sử dụng để dự đoán hàng loạt và đào tạo mô hình. Do các trường hợp sử dụng khác nhau nên số liệu chúng tôi sử dụng để đánh giá hiệu suất cũng hoàn toàn khác nhau. Trong tính năng trực tuyến, chúng tôi tìm kiếm độ trễ thấp. Đối với các cửa hàng tính năng ngoại tuyến, chúng tôi muốn có thông lượng cao.
Các nhà phát triển có thể chọn bất kỳ cửa hàng tính năng doanh nghiệp nào hoặc thậm chí nguồn mở dựa trên kho công nghệ. Sơ đồ bên dưới nêu những điểm khác biệt chính giữa cửa hàng trực tuyến và ngoại tuyến trong Cửa hàng tính năng AWS SageMaker.

Cửa hàng trực tuyến: Lưu trữ bản sao tính năng mới nhất và phân phát chúng với độ trễ thấp tính bằng mili giây, tốc độ này phụ thuộc vào kích thước tải trọng của bạn. Đối với mô hình tiếp quản tài khoản (ATO) của chúng tôi, có tổng cộng 8 nhóm tính năng và 55 tính năng, tốc độ trễ là khoảng 30 ms p99.
Cửa hàng ngoại tuyến: Cửa hàng chỉ bổ sung cho phép bạn theo dõi tất cả các tính năng lịch sử và cho phép du hành thời gian để tránh rò rỉ dữ liệu. Dữ liệu được lưu trữ ở định dạng parquet với khả năng phân vùng theo thời gian để tăng hiệu quả đọc.
Về tính nhất quán của tính năng, miễn là nhóm tính năng được định cấu hình cho cả việc sử dụng trực tuyến và ngoại tuyến, dữ liệu sẽ được sao chép tự động và nội bộ vào cửa hàng ngoại tuyến trong khi tính năng này được cửa hàng trực tuyến tiếp thu.
Chúng tôi sử dụng Cửa hàng tính năng như thế nào?

Mã trong hình trên ẩn chứa rất nhiều sự phức tạp. Các cửa hàng tính năng cho phép chúng tôi chỉ cần nhập giao diện python để đào tạo và suy luận mô hình.
Bằng cách sử dụng kho tính năng, các nhà khoa học dữ liệu của chúng tôi có thể dễ dàng xác định các tính năng và xây dựng mô hình mới mà không phải lo lắng về quy trình kỹ thuật dữ liệu tẻ nhạt ở phần phụ trợ.
Các phương pháp hay nhất để sử dụng Cửa hàng tính năng
Trong bài đăng trên blog trước đây, chúng tôi đã giải thích cách chúng tôi sử dụng lớp cửa hàng để đưa các tính năng vào cơ sở dữ liệu tập trung. Ở đây, chúng tôi muốn chia sẻ hai phương pháp hay nhất khi sử dụng cửa hàng tính năng:
Chúng tôi không sử dụng các tính năng chưa thay đổi
Chúng tôi tách các tính năng thành hai nhóm logic: hoạt động của người dùng đang hoạt động và không hoạt động
Hãy xem xét ví dụ này. Giả sử bạn có giới hạn điều tiết 10K TPS cho PutRecord trên cửa hàng tính năng trực tuyến của mình. Sử dụng giả thuyết này, chúng tôi sẽ sử dụng các tính năng cho 100 triệu người dùng. Chúng tôi không thể sử dụng tất cả chúng cùng một lúc và với tốc độ hiện tại, sẽ mất khoảng 2,7 giờ để hoàn thành. Để giải quyết vấn đề này, chúng tôi chọn chỉ sử dụng các tính năng được cập nhật gần đây. Ví dụ: chúng tôi sẽ không nhập một tính năng nếu giá trị không thay đổi kể từ lần nhập cuối cùng.
Đối với điểm thứ hai, giả sử bạn đặt một tập hợp các tính năng vào một nhóm tính năng logic. Một số đang hoạt động, trong khi phần lớn không hoạt động, nghĩa là hầu hết các tính năng không thay đổi. Theo chúng tôi, bước hợp lý là chia hoạt động và không hoạt động thành hai nhóm tính năng để đẩy nhanh quá trình nhập.
Đối với các tính năng không hoạt động, chúng tôi giảm 95% dữ liệu cần đưa vào kho tính năng cho 100 triệu người dùng theo quy trình tính năng hàng giờ. Ngoài ra, chúng tôi vẫn giảm 20% dữ liệu cần thiết cho các tính năng đang hoạt động. Vì vậy, thay vì ba giờ, quy trình nhập hàng loạt xử lý các tính năng có giá trị 100 triệu người dùng trong 10 phút.
Bớt tư tưởng
Tóm lại, kho lưu trữ tính năng cho phép chúng tôi sử dụng lại các tính năng, đẩy nhanh quá trình kỹ thuật tính năng và giảm thiểu các dự đoán không chính xác - đồng thời duy trì tính nhất quán giữa đào tạo và suy luận.
Quan tâm đến việc sử dụng ML để bảo vệ hệ sinh thái tiền điện tử lớn nhất thế giới và người dùng của nó? Hãy xem Binance Engineering/AI trên trang tuyển dụng của chúng tôi để biết các tin tuyển dụng đang tuyển dụng.
Đọc thêm:
(Blog) Sử dụng MLOps để xây dựng quy trình học máy toàn diện theo thời gian thực