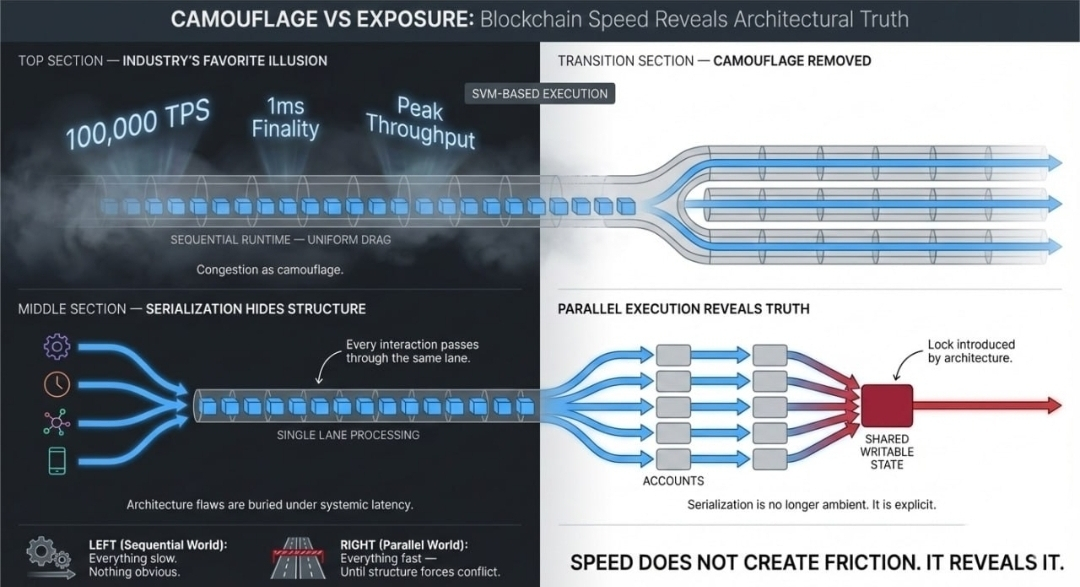
I. Industry's Favorite Illusion
For a long time, the performance of a blockchain has been promoted as a figure. Peak TPS. Millisecond finality. Laboratory benchmarks under ideal conditions captured. While these figures are enticing, they hide an incredible truth: throughput is not the measure of the system's architecture.
Speed is not a virtue in isolation. It is a stress test.
When looking at sequential runtimes, the structural weaknesses are well-obscured. Transactions line up. Blocks fill in order. Every interaction goes through the same narrow processing lane. And because everything is serialized by default, every application seems to be subjected to the same systemic drag. Ambient Latency is an accepted property of the environment rather than a diagnostic signal.
When users are kept in the dark because developers do not see clearly, they cannot see what the problem is. Is the network saturated? Is the contract poorly designed? Is a shared state object becoming a hidden choke point? Everything is processed one after another in sequential order, and system architecture flaws are buried by distributing slowness evenly across the system.
Congestion is camouflage, in these situations.
Now, imagine applying the same program on an SVM-based Layer 1 like Fogo - the camouflage goes - transactions do not queue randomly anymore because they execute, independently. This means there will be no assumed conflicts unless they are declared through a shared writable state.
Parallel arrows move cleanly across the system - that is, until they intersect a single account.
At that point, the chain returns to serialization not because the chain is slow, but because the architecture has demanded a lock.
The bottleneck is no longer abstract, but explicit.
And speed, does not introduce friction, but exposes it.
II. State as a Concurrency Surface
In a parallel runtime, state is not passive storage. It is concurrency policy.
Every writable account represents a lock boundary. When a transaction declares that it intends to mutate an account, the runtime must ensure exclusive access. If two transactions attempt to modify the same account simultaneously, one must wait. This is not inefficiency, it is correctness.
The architectural implication is severe: each shared writable object becomes a serialization surface. A global counter that is updated on every trade, a protocol-wide metric that is recalculated per interaction.There is one liquidity pool account for all the swaps. When traffic is low, these design choices seem reasonably safe. When traffic is high, they represent the upper limit of scalability.
For parallel execution to work, the modifications that occur must be independent.
Isolated state modifications can be made by users to individual accounts, partitioned pools, or separate order books. In these scenarios, system runtime can schedule the modification of those states without interfering with each other. This naturally increases throughput.
When all activity is directed towards one mutable state, the system is forced into sequential processing at that state. Regardless of how many cores are present or how low the latencies are, the shared state becomes a bottleneck.
This is the core of the problem that the demand for parallelism creates.
In a sequential system, a global state is useful. In parallel systems, a global state is an expensive resource.
When designing for concurrency, an analysis of every variable is needed:
Does this value truly need to be mutated synchronously?
Can it be partitioned by user, market, or epoch?
Can reporting be separated from correctness?
Can critical execution paths be free of analytics?
This isn't micro-optimization — these are structural commitments.
Once the system has been deployed, parallelism cannot be added as an afterthought. It must be built into the design of the state topology from the beginning.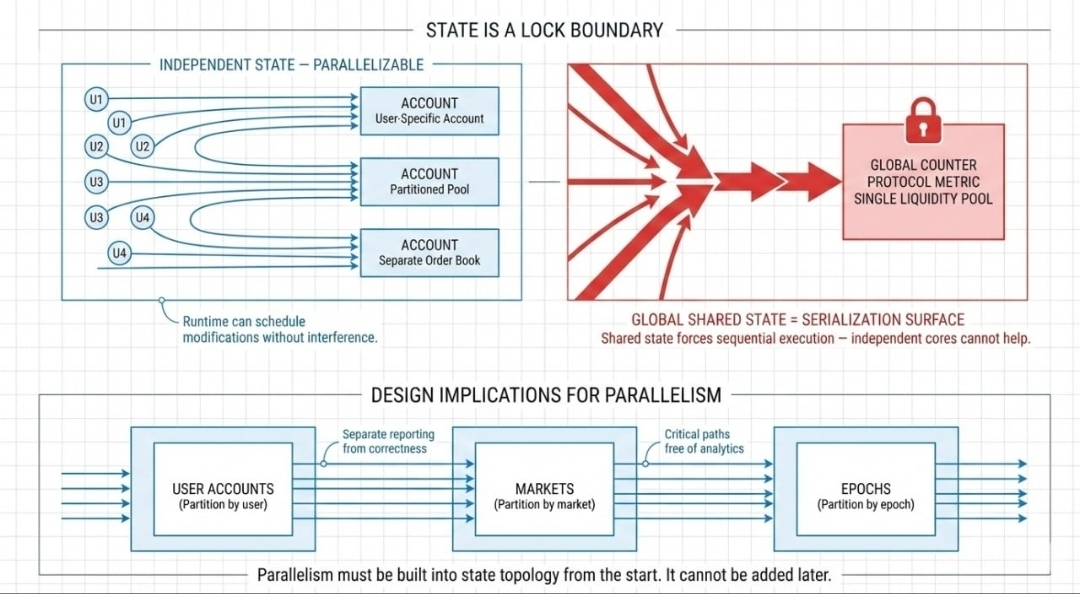
III. Engines and Frames
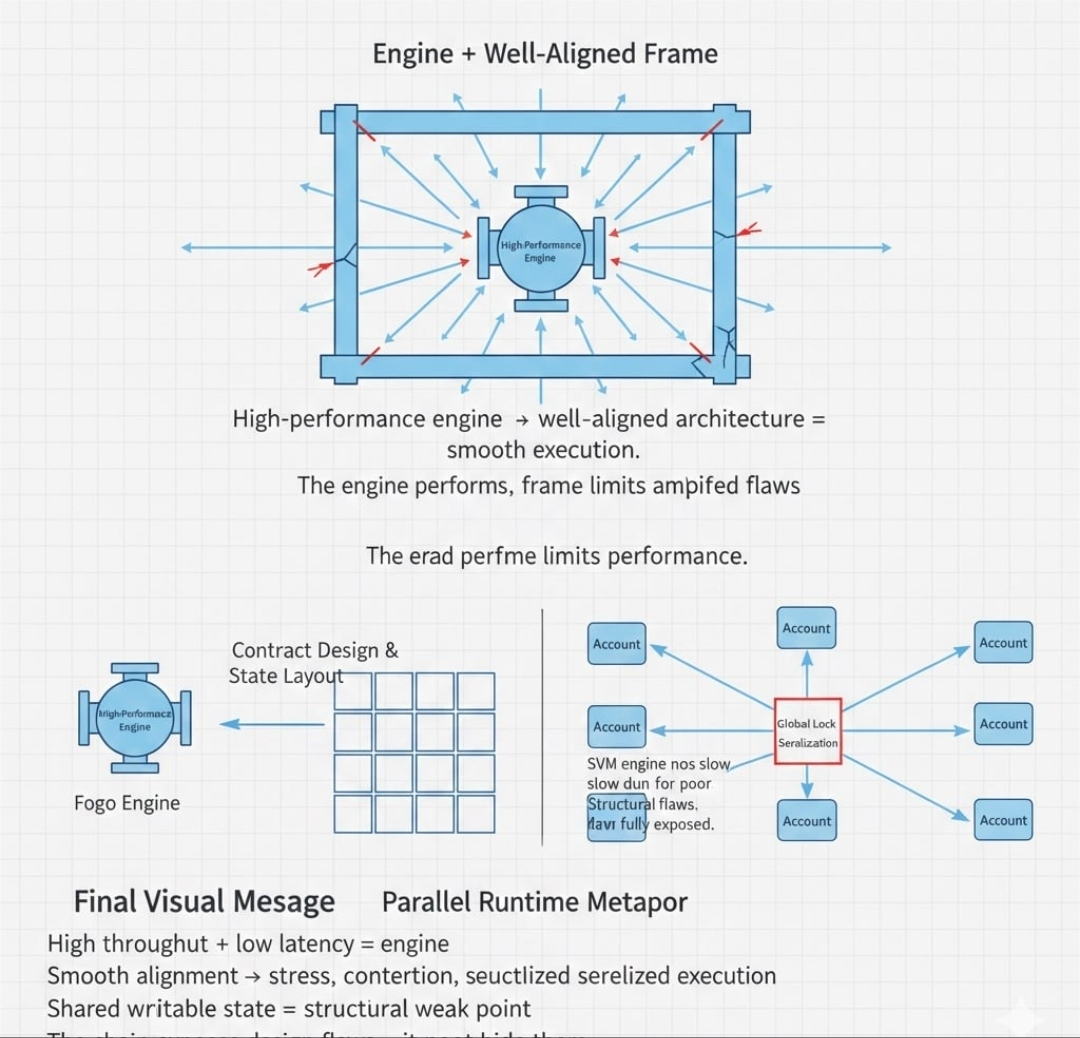
High performance engines generate power. Adjusting the engine’s placement will not change that capability.
Put the engine into a well-aligned frame. With the right geometry and a good distribution of all the forces, the frame will also perform well and acceleration will be smooth. The frame and engine will perform in symmetry with one another and the conversion of energy into motion will not be wasted.
But if that same engine is placed into a misaligned frame with focus on weak joints, the low paths are going to change and the performance will also change. The vibration will be amplified. The components will be strained. Fractures will be created by the pressure. The engine is not failing. The structure is not able to take the output.
This is how parallel runtimes work.
An SVM engine like Fogo offers low latency and high throughput with concurrent execution. It will not reduce its performance to accommodate flaws in the architecture. The engine will not be locked because of generalized congestion.
This will increase the flaws of the structure.
If a contract directs all of the writes to a single account, there will be serialization. A protocol that depends on a synchronous global update will be stalled on the anticipated points of contention. The runtime will not lessen the outcomes. It will be clear what the exact outcome will be.
Your sentence was confusing. I changed the order of some of the words but I did not change the meaning.
IV. Fifth. A Case For Integrative Design.
The goal is not to punish. The goal is to measure.
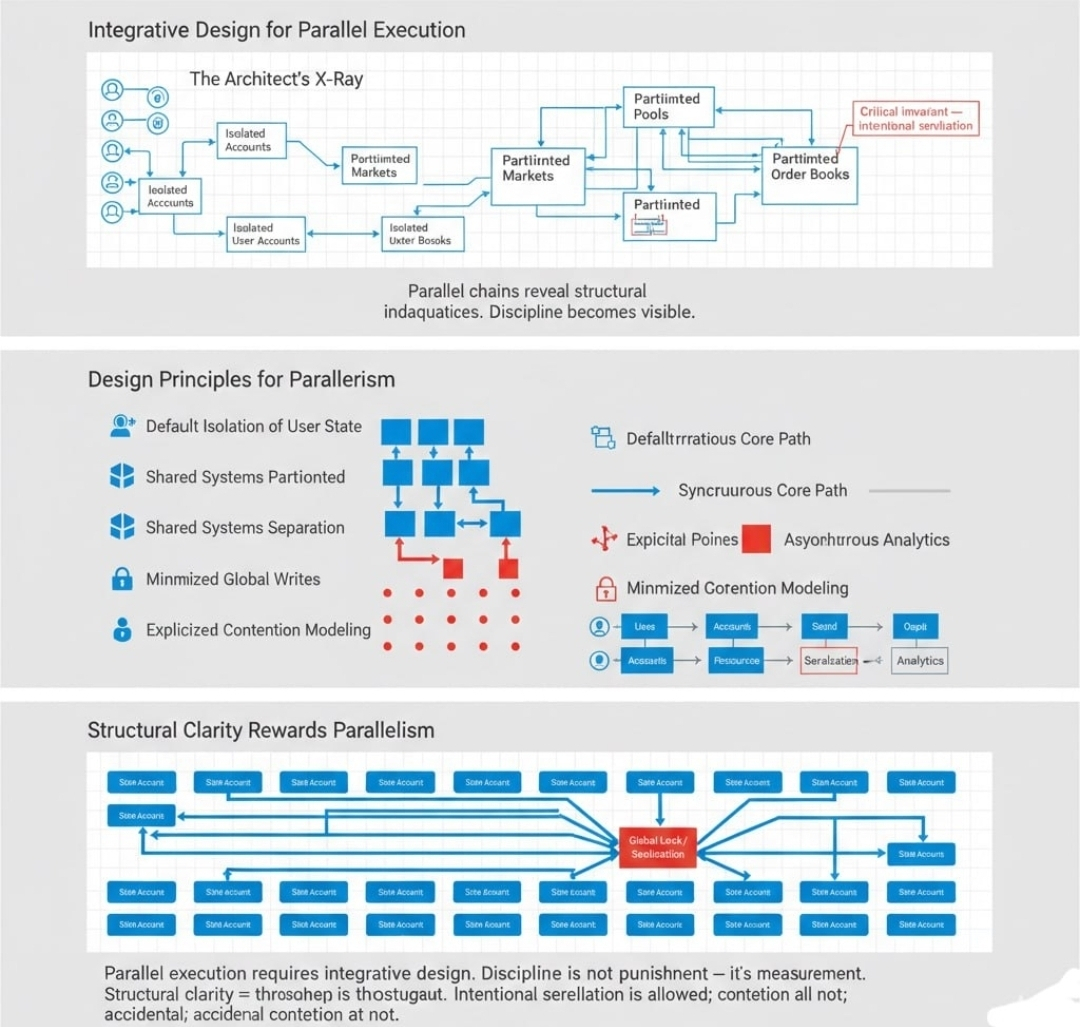
When integrated with vertical limiters, a fixed sequential chain can conceal inadequacies for a long time. A rapid parallel chain just can’t.
Once the first X-ray shows up, the architect's duty can no longer be avoided.
Discipline for holding parallel.
Designing for parallel execution necessitates order at the level of states:
Default isolation of user states. Independence as a state of being is a baseline, not a later adjustment.
Shared systems should be divided. Users of shared systems like markets, pools, or order books should be split when possible to decrease the surfaces of contention.
Keep correctness and reporting apart. The on-chain invariants that must hold true should be synchronous, while analytics and metrics can be asynchronous.
Global writes should be minimized. Every shared, writable account should be treated as a scarce resource.
Contention should be modeled explicitly. If ca user serialization, design to offset the cost of containment while assuming no serialization.
The goal is not the complete elimination of shared states and systems. Invariances that are critical require some level of coordination. The goal should be the intentional and minimal serialization.
Structural clarity is rewarded with parallelism.
V. What Speed Ultimately Reveals
Fast infrastructure isn’t a guarantee for applications. What it guarantees is openness. *When parallel run times hit performance ceilings, it’s usually not a mystery why. These are direct results of shared writable state, centralized points of mutation, and architectural choices made early and unexamined.
In that sense, speed is not a marketing feature, it’s an X-ray.
It removes the blur that once disguised contention. It distinguishes network limitations from application design flaws. It makes lock boundaries visible.
And once visible, they can be redesigned.
The future of high-performance blockchains will not be determined solely by faster runtimes. It will be determined by whether developers internalize the lesson those runtimes enforce: independence is scalability.
Throughput is not inherited from the chain. It is earned through architecture.
