
Основные выводы
В Binance мы используем машинное обучение (ML) для решения различных бизнес-проблем, включая, помимо прочего, мошенничество с захватом учетных записей (ATO), P2P-мошенничество и кражу платежных реквизитов.
Используя операции машинного обучения (MLOps), наши исследователи данных Binance Risk AI создали сквозной конвейер машинного обучения, работающий в режиме реального времени, который постоянно предоставляет готовые к использованию сервисы машинного обучения.

Почему мы используем MLOps?
Начнем с того, что создание службы машинного обучения — это итеративный процесс. Ученые, работающие с данными, постоянно экспериментируют, чтобы улучшить конкретный показатель, как оффлайн, так и онлайн, исходя из цели повышения ценности бизнеса. Так как же мы можем сделать этот процесс более эффективным — например, сократив время вывода модели ML на рынок?
Во-вторых, на поведение сервисов ML влияет не только код, который мы, разработчики, определяем, но и данные, которые он собирает. Эта идея, также известная как дрейф концепций, подчеркивается в статье Google под названием «Скрытый технический долг в системах машинного обучения».
Возьмем, к примеру, мошенничество; мошенник — это не просто машина, а человек, который адаптируется и постоянно меняет способы атаки. Таким образом, базовое распределение данных будет развиваться, отражая изменения в векторах атак. Как мы можем эффективно гарантировать, что производственная модель учитывает новейшие шаблоны данных?
Чтобы преодолеть упомянутые выше проблемы, мы используем концепцию под названием MLOps — термин, первоначально предложенный Google в 2018 году. В MLOps мы фокусируемся на производительности модели и инфраструктуре, поддерживающей производственную систему. Это позволяет нам создавать масштабируемые, высокодоступные, надежные и удобные в обслуживании сервисы машинного обучения.
Разрушение нашего сквозного конвейера машинного обучения в режиме реального времени
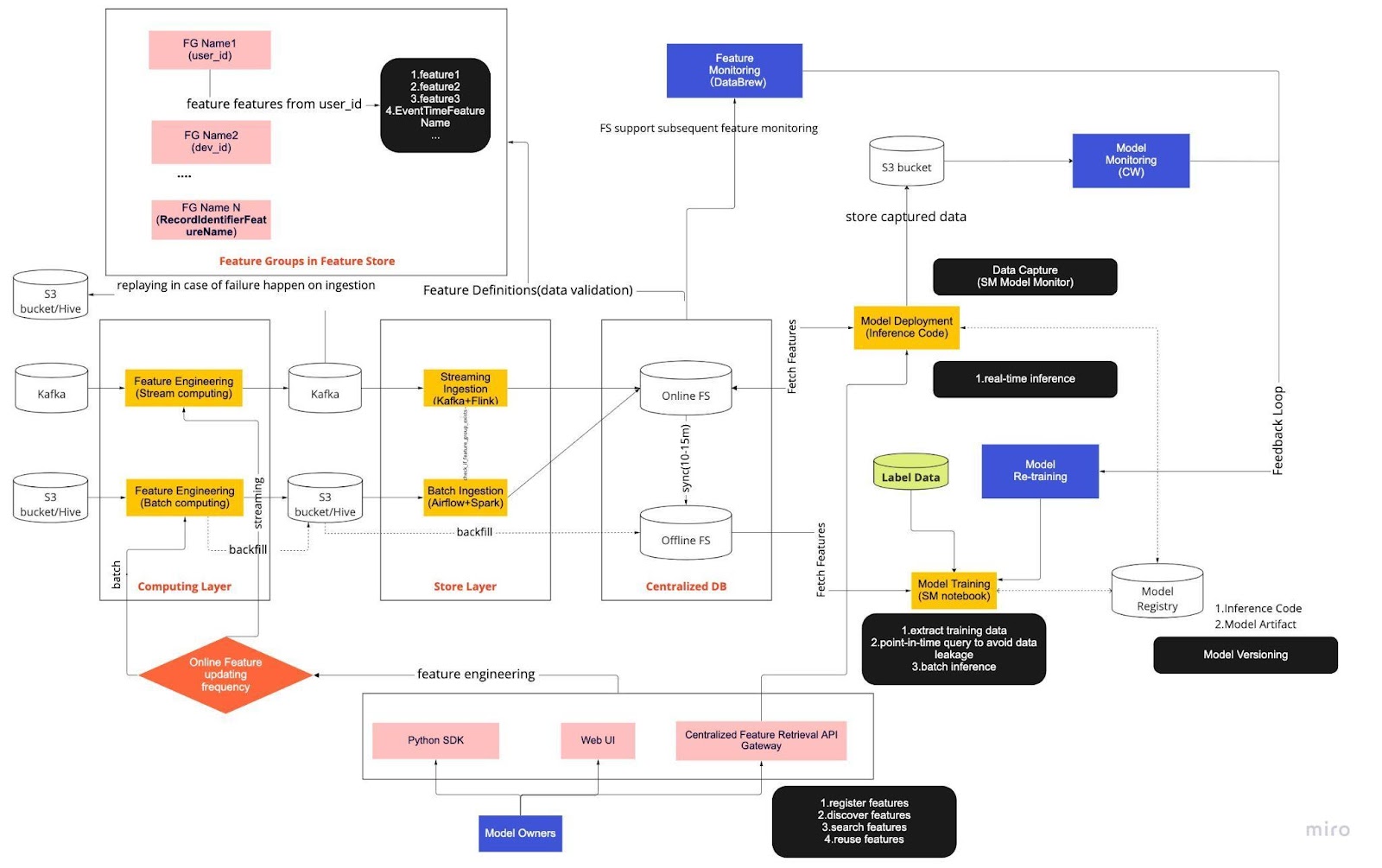
Рассматривайте приведенную выше диаграмму как нашу стандартную рабочую процедуру (СОП) для разработки моделей в реальном времени с хранилищем функций. Сквозной конвейер машинного обучения определяет, как наша команда применяет Mlops, и он построен с учетом двух типов требований: функциональных и нефункциональных.
Функциональный
Обработка данных
Модельное обучение
Разработка модели
Развертывание модели
Мониторинг
Нефункциональные требования
Масштабируемый
Высокая доступность
Надежный
Ремонтопригодность
Далее трубопровод разделен на шесть ключевых компонентов:
Вычислительный уровень
Слой магазина
Централизованная БД
Модельное обучение
Развертывание модели
Мониторинг модели
1. Вычислительный уровень

Вычислительный уровень в основном отвечает за разработку функций, процесс преобразования необработанных данных в полезные функции.
Мы разделяем вычислительный уровень на два типа в зависимости от частоты их обновления: потоковые вычисления для интервалов в одну минуту/секунду и пакетные вычисления для ежедневных/часовых интервалов.
Входные данные вычислительного уровня обычно поступают из базы данных событий, в которую входят Apache Kafka и Kinesis, или из базы данных OLAP, в которую входит Apache Hive для решений с открытым исходным кодом и Snowflake для облачных решений.
2. Уровень магазина
Уровень хранилища — это место, где мы регистрируем определения объектов и развертываем их в нашем хранилище объектов, а также выполняем обратное заполнение — процесс, который позволяет нам перестраивать объекты с использованием исторических данных всякий раз, когда определяется новый объект. Обратная засыпка — это, как правило, разовая работа, которую наши специалисты по обработке данных могут выполнить в среде записной книжки. Поскольку Kafka может хранить события только за последние семь дней, он использует механизм резервного копирования в таблице s3/hive для повышения отказоустойчивости.
Вы заметите, что промежуточный уровень Hive и Kafka намеренно размещен между уровнями вычислений и хранения. Думайте об этом размещении как о буфере между функциями вычислений и записи. Можно провести аналогию с отделением производителя от потребителя. Потоковые вычисления являются производителем, а прием потока — потребителем.
Разделение вычислений и приема данных обеспечивает множество преимуществ для наших конвейеров машинного обучения. Для начала мы можем повысить устойчивость трубопровода в случае сбоев. Наши специалисты по обработке данных по-прежнему могут получать значения функций из централизованной базы данных, даже если уровень приема или вычислений недоступен из-за проблем с эксплуатацией, оборудованием или сетью.
Более того, мы можем индивидуально масштабировать различные части инфраструктуры и снижать энергопотребление, необходимое для строительства и эксплуатации трубопровода. Например, если по какой-либо причине произойдет сбой, уровень приема не заблокирует вычислительный уровень. Что касается инноваций, мы можем экспериментировать и внедрять новые технологии, такие как новая версия приложения Flink, не затрагивая существующую инфраструктуру.

И вычислительный уровень, и уровень хранилища — это то, что мы называем автоматизированными конвейерами функций. Эти конвейеры независимы, работают по разным расписаниям и делятся на потоковые или пакетные конвейеры. Вот как эти два конвейера работают по-разному: одна группа функций в пакетном конвейере может обновляться каждую ночь, а другая группа обновляется ежечасно. В потоковом конвейере группа функций обновляется в режиме реального времени по мере поступления исходных данных во входной поток, например, в тему Apache Kafka.
3. Централизованная БД
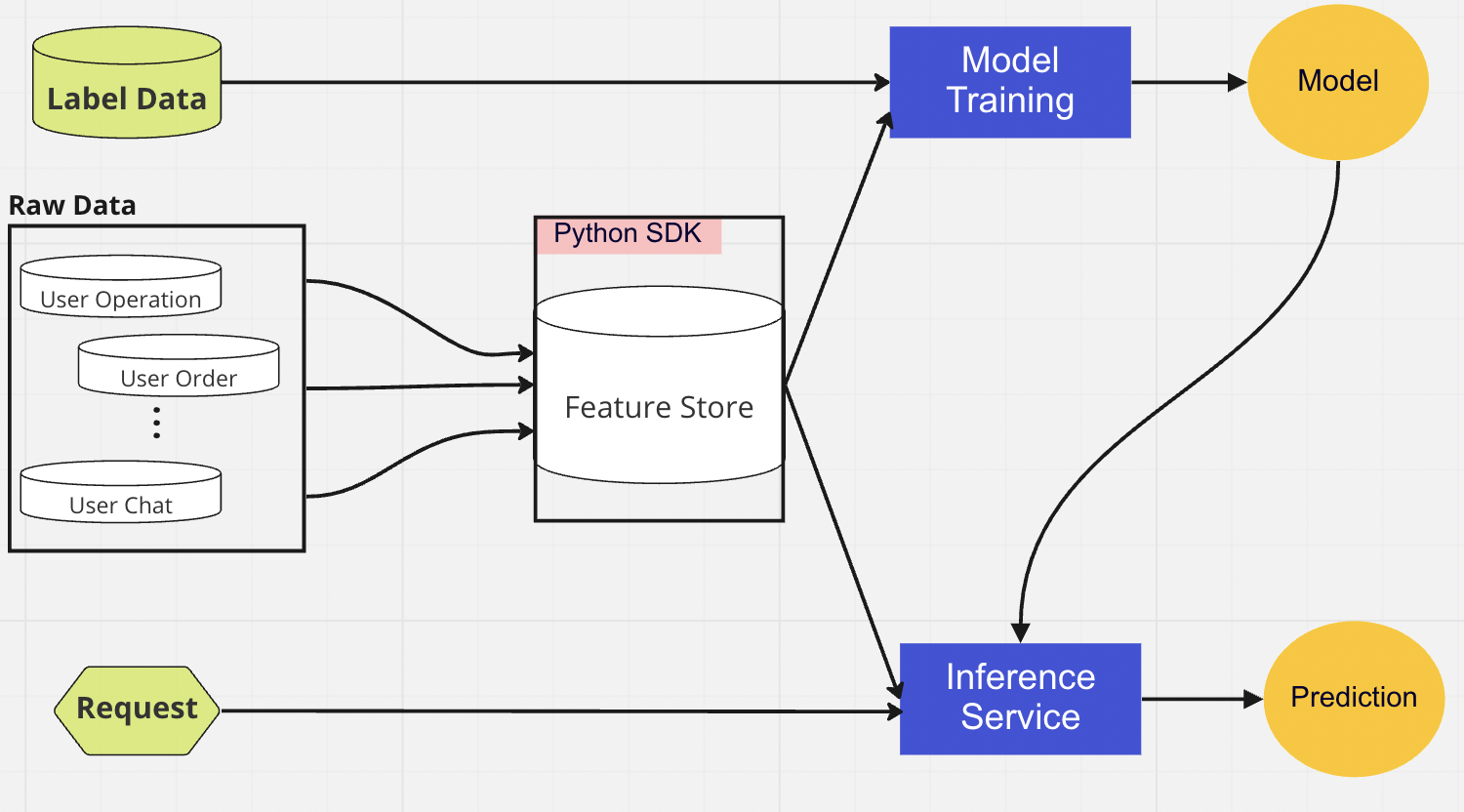
На уровне централизованной базы данных наши специалисты по обработке данных представляют свои готовые к использованию данные в онлайн- или автономном хранилище функций.
Интернет-хранилище функций — это хранилище с низкой задержкой и высокой доступностью, которое позволяет осуществлять поиск записей в режиме реального времени. С другой стороны, автономное хранилище функций обеспечивает безопасный и масштабируемый репозиторий всех данных объектов. Это позволяет ученым создавать наборы данных для обучения, проверки или пакетной оценки из набора централизованно управляемых групп признаков с полной исторической записью значений признаков в системе хранения объектов.
Оба хранилища функций автоматически синхронизируются друг с другом каждые 10–15 минут, чтобы избежать перекоса в обслуживании обучения. В следующей статье мы подробно рассмотрим, как мы используем хранилища функций в конвейерах.
4. Модельное обучение
Уровень обучения модели — это место, где наши ученые извлекают данные обучения из автономного хранилища функций для точной настройки наших сервисов машинного обучения. Мы используем запросы на определенный момент времени, чтобы предотвратить утечку данных в процессе извлечения.
Кроме того, этот уровень включает в себя важный компонент, известный как цикл обратной связи переобучения модели. Переобучение модели сводит к минимуму риск отклонения концепции, гарантируя, что развернутые модели точно отражают новейшие шаблоны данных — например, хакер меняет свое поведение при атаке.
5. Развертывание модели
Для развертывания модели мы в основном используем облачную службу оценки в качестве основы для предоставления данных в реальном времени. Вот диаграмма, показывающая, как текущий код вывода интегрируется с хранилищем функций.

6. Мониторинг модели
На этом уровне наша команда отслеживает показатели использования для оценки сервисов, такие как количество запросов в секунду, задержка, память и коэффициент использования ЦП/ГП. Помимо этих базовых показателей, мы используем собранные данные для проверки распределения функций во времени, неравномерности обслуживания обучения и отклонения прогнозов, чтобы обеспечить минимальное отклонение концепции.
Заключительные мысли
Подводя итог, можно сказать, что свободное разделение нашей конвейерной инфраструктуры на вычислительный уровень, уровень хранилища и централизованную базу данных дает нам три ключевых преимущества по сравнению с более тесно связанной архитектурой.
Более надежные трубопроводы в случае сбоев
Повышенная гибкость в выборе инструментов для внедрения.
Независимо масштабируемые компоненты
Заинтересованы в использовании машинного обучения для защиты крупнейшей в мире криптоэкосистемы и ее пользователей? Посетите Binance Engineering/AI на нашей странице вакансий, чтобы найти открытые объявления о вакансиях.