
Stability AI опубликовал в своем блоге новую статью о Stable Diffusion 2. В ней Stability AI предлагает новый алгоритм, который более эффективен и надежен, чем предыдущий, при этом сравнивая его с другими современными методами.

Оригинальная модель Stable Diffusion V1 от CompVis произвела революцию в природе моделей искусственного интеллекта с открытым исходным кодом и позволила создать сотни различных моделей и разработок по всему миру. Он стал свидетелем одного из самых быстрых восхождений к 10 000 звезд Github: менее чем за два месяца он набрал 33 000, что быстрее, чем у большинства программ на Github.
Первоначальный выпуск Stable Diffusion V1 возглавлял динамичная команда Робина Ромбаха (Stability AI) и Патрика Эссера (Runway ML) из группы CompVis в LMU Мюнхен под руководством профессора доктора Бьорна Оммера. Они опирались на предыдущую работу лаборатории с моделями скрытой диффузии и получили критическую поддержку от LAION и Eleuther AI.

 Чем Stable Diffusion v1 отличается от Stable Diffusion v2?
Чем Stable Diffusion v1 отличается от Stable Diffusion v2?
Stable Diffusion 2.0 включает в себя ряд существенных улучшений и функций по сравнению с предыдущей версией, поэтому давайте взглянем на них.
В выпуске Stable Diffusion 2.0 представлены надежные модели преобразования текста в изображение, обученные с помощью нового нового кодировщика текста (OpenCLIP), разработанного LAION при поддержке Stability AI, который значительно повышает качество создаваемых изображений по сравнению с предыдущими выпусками V1. Модели преобразования текста в изображение в этом выпуске могут выводить изображения с разрешением по умолчанию 512×512 пикселей и 768×768 пикселей.
Эти модели обучаются с использованием эстетического подмножества набора данных LAION-5B, созданного командой DeepFloyd компании Stability AI, который затем фильтруется для исключения контента для взрослых с помощью фильтра NSFW LAION.
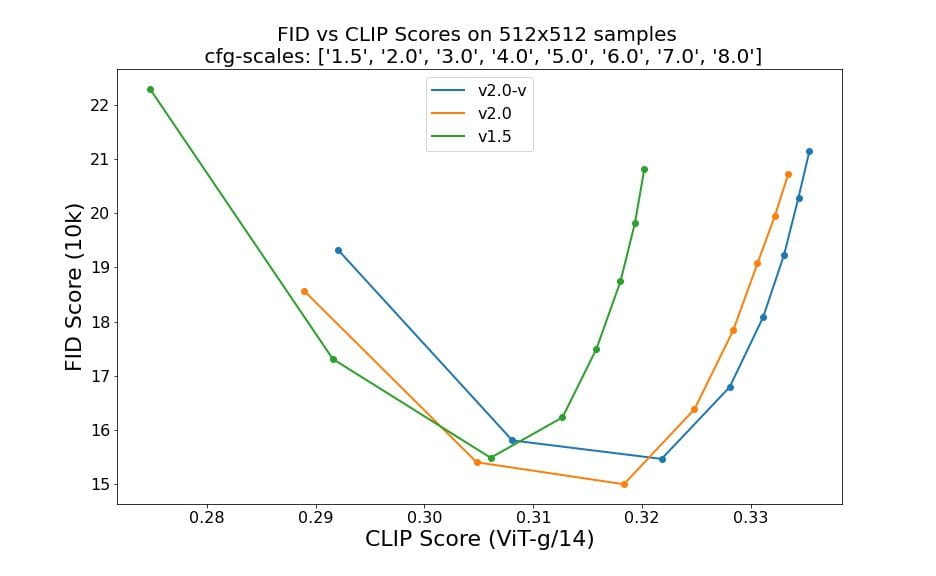
Оценки с использованием 50 выборочных шагов DDIM, 50 руководящих шкал без классификаторов и 1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0 и 8,0 указывают на относительное улучшение контрольных точек:
Stable Diffusion 2.0 теперь включает модель Upscaler Diffusion, которая увеличивает разрешение изображения в четыре раза. Ниже показан пример нашей модели, масштабирующей сгенерированное изображение низкого качества (128×128) до изображения с более высоким разрешением (512×512). Stable Diffusion 2.0 в сочетании с нашими моделями преобразования текста в изображение теперь может генерировать изображения с разрешением 2048×2048 или выше.

Новая модель стабильной диффузии с управлением по глубине, deep2img, расширяет предыдущую функцию преобразования изображения в изображение из версии V1, предоставляя совершенно новые творческие возможности. Depth2img определяет глубину входного изображения (используя существующую модель), а затем генерирует новые изображения на основе текста и информации о глубине. Depth-to-Image может предоставить множество новых творческих приложений, предлагая изменения, которые значительно отличаются от оригинала, сохраняя при этом целостность и глубину изображения.
Что нового в Stable Diffusion 2?
Новая модель стабильной диффузии предлагает разрешение 768×768.
U-Net имеет то же количество параметров, что и версия 1.5, но обучается с нуля и использует OpenCLIP-ViT/H в качестве кодировщика текста. Так называемая модель v-прогнозирования — SD 2.0-v.
Вышеупомянутая модель была скорректирована на базе SD 2.0, которая также доступна, и была обучена как типичная модель прогнозирования шума на изображениях 512×512.
Добавлена скрытая модель распространения текста с масштабированием x4.
Усовершенствованная модель стабильной диффузии с контролем глубины на основе SD 2.0. Модель может использоваться для сохраняющего структуру img2img и условного синтеза формы и обусловлена оценками монокулярной глубины, полученными с помощью MiDaS.
Улучшенная модель рисования с текстовым управлением, построенная на основе SD 2.0.
Разработчики усердно работали, как и в случае с первоначальной версией Stable Diffusion, над оптимизацией модели для работы на одном графическом процессоре — они хотели с самого начала сделать ее доступной как можно большему количеству людей. Они уже видели, что происходит, когда миллионы людей получают в свои руки эти модели и совместно создают совершенно замечательные вещи. В этом сила открытого исходного кода: использование огромного потенциала миллионов талантливых людей, у которых может не быть ресурсов для обучения передовой модели, но есть возможность делать с ее помощью невероятные вещи.

Это новое обновление в сочетании с новыми мощными функциями, такими как deep2img и улучшенными возможностями масштабирования разрешения, послужит основой для множества новых приложений и обеспечит взрыв нового творческого потенциала.
Узнайте больше о стабильной диффузии:
Stable Diffusion AI создает миры мечты для VR и Metaverse
Художник использует Stable Diffusion для создания первого анимационного фильма с искусственным интеллектом.
Знакомьтесь: рисование видео: редактирование текста с помощью Stable Diffusion и Neural Atlases
Сообщение Алгоритм Stability Diffusion 2 от Stability AI наконец-то стал общедоступным: новая модель deep2img, апскейлер сверхвысокого разрешения, никакой контент для взрослых впервые появился на Metaverse Post.