
Основные выводы
Binance использует управление мощностью для предотвращения незапланированных скачков трафика, вызванных высокой волатильностью, обеспечивая адекватную и своевременную инфраструктуру и вычислительные ресурсы для потребностей бизнеса.
Нагрузочные тесты Binance в производственной среде (а не в промежуточной среде), чтобы получить точные тесты обслуживания. Этот метод помогает проверить, достаточно ли выделенных ресурсов для обслуживания определенной нагрузки.
Инфраструктура Binance обрабатывает большие объемы трафика, и поддержание сервиса, от которого могут зависеть пользователи, требует надлежащего управления мощностью и автоматического нагрузочного тестирования.

Почему Binance нужен специализированный процесс управления мощностями?
Управление мощностями является основой стабильности системы. Это предполагает подбор правильного размера приложений и ресурсов инфраструктуры с учетом текущих и будущих потребностей бизнеса по правильной цене. Чтобы достичь этой цели, мы создаем инструменты и конвейеры управления мощностью, чтобы избежать перегрузки и помочь компаниям обеспечить бесперебойную работу пользователей.
Рынки криптовалют часто сталкиваются с более регулярными периодами волатильности, чем традиционные финансовые рынки. Это означает, что система Binance должна время от времени выдерживать такой всплеск трафика, поскольку пользователи реагируют на движения рынка. При правильном управлении мощностью мы поддерживаем мощность, достаточную для общих потребностей бизнеса и таких сценариев резкого увеличения трафика. Именно этот ключевой момент делает процессы управления мощностью Binance уникальными и сложными.
Давайте рассмотрим факторы, которые часто тормозят процесс и приводят к медленному или недоступному обслуживанию. Во-первых, у нас есть перегрузка, обычно вызванная внезапным увеличением трафика. Например, это может быть результатом маркетингового мероприятия, push-уведомления или даже DDoS-атаки (распределенный отказ в обслуживании).
Скачок трафика и недостаточная пропускная способность влияют на функциональность системы следующим образом:
Сервис берет на себя все больше и больше работы.
Время ответа увеличивается до такой степени, что ни на один запрос невозможно ответить в течение таймаута клиента. Такое ухудшение обычно происходит из-за перенасыщения ресурсов (ЦП, памяти, ввода-вывода, сети и т. д.) или длительных пауз GC в самом сервисе или его зависимостях.
В результате сервис не сможет оперативно обрабатывать запросы.
Разрыв процесса
Теперь, когда мы обсудили общий принцип управления мощностью, давайте посмотрим, как Binance применяет его в своем бизнесе. Вот краткий обзор архитектуры нашей системы управления мощностью с некоторыми ключевыми рабочими процессами.
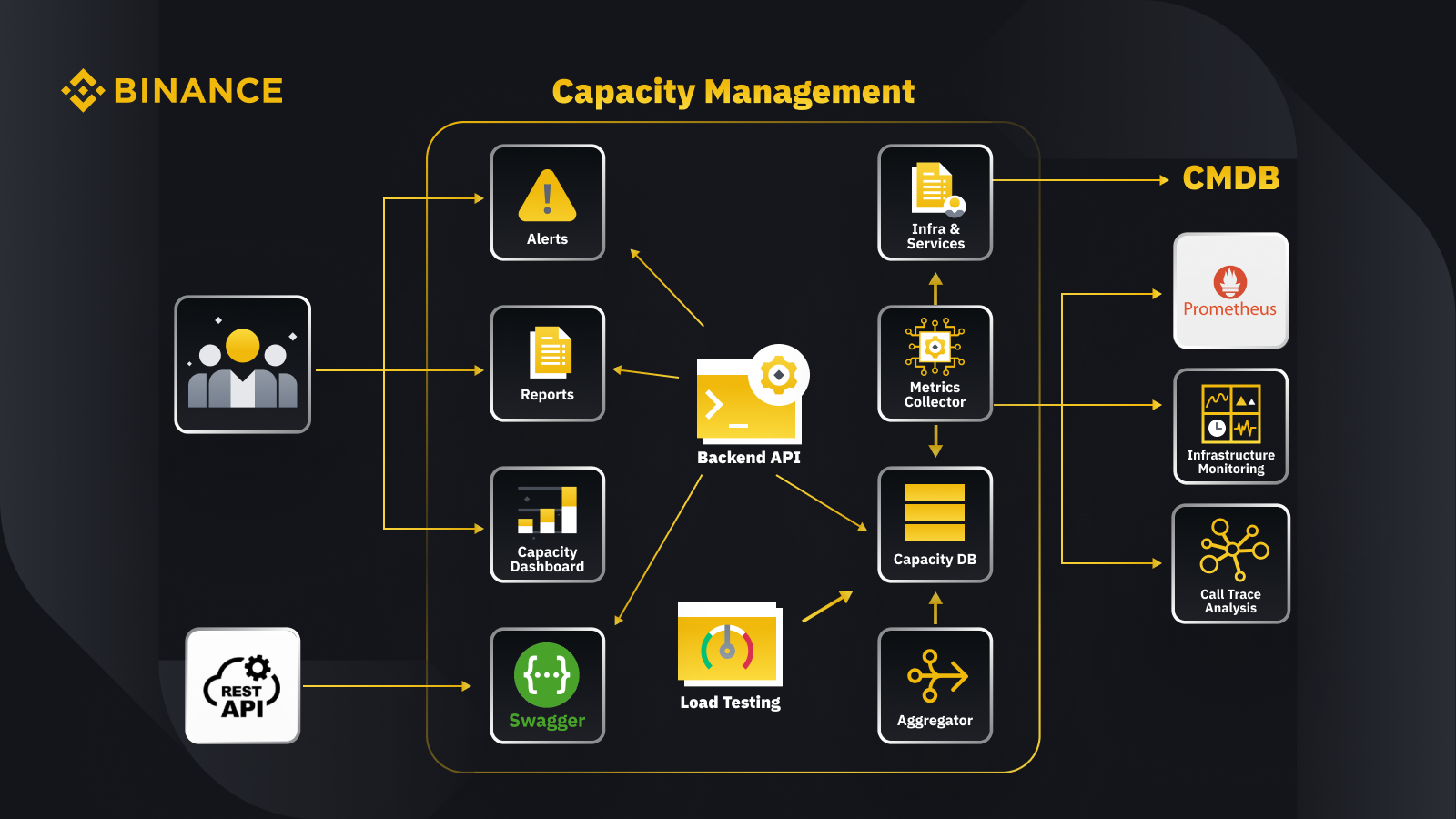
Получая данные из базы данных управления конфигурациями (CMDB), мы генерируем конфигурации инфраструктуры и служб. Элементы в этих конфигурациях являются объектами управления мощностью.
Сборщик метрик извлекает показатели мощности из Prometheus для данных бизнес-уровня и уровня обслуживания, мониторинга инфраструктуры для метрик уровня ресурсов и системы анализа трассировки вызовов для информации трассировки. Сборщик метрик сохраняет данные в базе данных емкости (CDB).
Система нагрузочного тестирования выполняет стресс-тесты сервисов и сохраняет контрольные данные в CDB.
Агрегатор получает данные о емкости из CDB и объединяет их для ежедневных и рекордно высоких измерений (ATH). После агрегации он записывает агрегированные данные обратно в CDB.
Обрабатывая данные из CDB, внутренний API предоставляет интерфейсы для панели мониторинга мощности, оповещений и отчетов, а также остальных API и связанных данных о мощности для интеграции.
Заинтересованные стороны получают информацию о емкости через панель мониторинга мощности, оповещения и отчеты. Они также могут использовать другие связанные системы, в том числе мониторинг получения данных о мощности сервисов с помощью rest API, предоставляемого системой управления мощностью с помощью Swagger.
Стратегия
Наша стратегия управления мощностями и планирования основана на обработке с учетом пиковой нагрузки. Пиковая обработка — это рабочая нагрузка, которую испытывают ресурсы службы (веб-серверы, базы данных и т. д.) во время пикового использования.
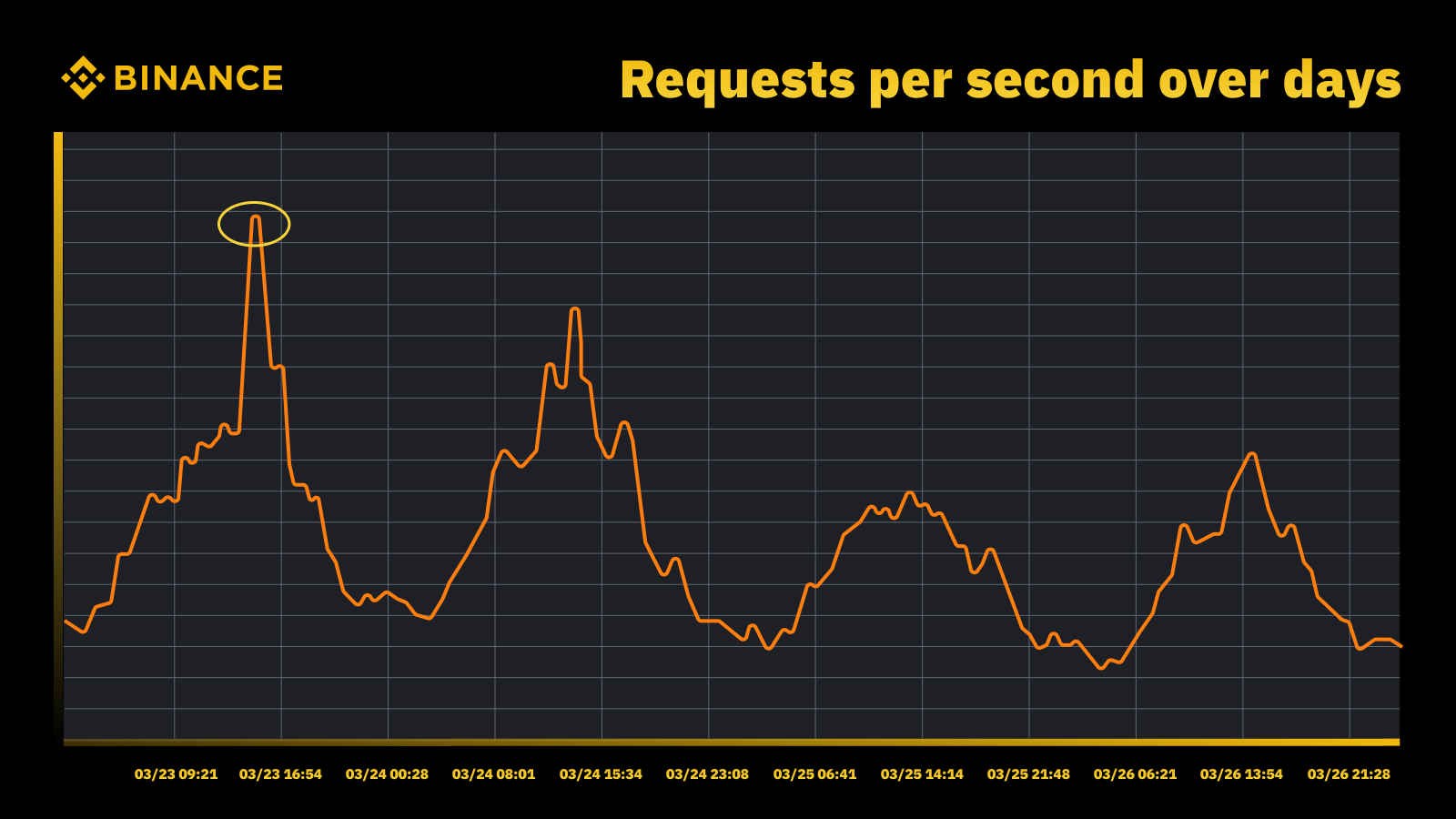
Рост трафика, когда ФРС повысила ставку в марте 2023 года
Мы анализируем периодические пики и используем их для определения траектории мощности. Как и в случае с любым ресурсом, управляемым пиками, мы хотим выяснить, когда происходят пики, а затем изучить, что на самом деле происходит во время этих циклов.
Еще одна важная вещь, которую мы учитываем наряду с предотвращением перегрузки, — это автомасштабирование. Автомасштабирование справляется с перегрузкой путем динамического увеличения емкости за счет большего количества экземпляров службы. Затем избыточный трафик распределяется, и трафик, который обрабатывает один экземпляр службы (или зависимости), остается управляемым.
Автомасштабирование имеет свое место, но не справляется с ситуациями перегрузки. Обычно он не может достаточно быстро реагировать на внезапное увеличение трафика и работает лучше всего только при постепенном увеличении.
Измерение
Измерение играет решающую роль в работе Binance по управлению мощностями, и сбор данных — наш первый шаг измерения. На основе стандартов Библиотеки инфраструктуры информационных технологий (ITIL) мы собираем данные для измерения в подпроцессах управления мощностью, а именно:
Ресурс — потребление ресурсов ИТ-инфраструктуры, обусловленное использованием приложений/услуг. Основное внимание уделяется внутренним показателям производительности физических и виртуальных вычислительных ресурсов, включая процессор сервера, память, дисковое хранилище, пропускную способность сети и т. д.
Услуга. Производительность на уровне приложения, соглашение об уровне обслуживания, задержка и показатели пропускной способности, возникающие в результате бизнес-операций. Фокусируется на внешних показателях производительности, основанных на том, как пользователи воспринимают услугу, включая задержку услуги, пропускную способность, пиковые нагрузки и т. д.
Бизнес. Собирает данные, которые измеряют бизнес-деятельность, обрабатываемую целевым приложением, включая заказы, регистрацию пользователей, платежи и т. д.
Управление мощностями, основанное только на использовании ресурсов инфраструктуры, приведет к неточному планированию. Это связано с тем, что они могут не отражать фактические объемы бизнеса и пропускную способность нашей инфраструктуры.
Запланированные мероприятия предоставляют прекрасную возможность для дальнейшего обсуждения этого вопроса. Примите участие в Watch Web Summit 2022 на Binance Live и поделитесь до 15 000 BUSD в кампании Crypto Box Rewards. Помимо базовых показателей уровня ресурсов и услуг, нам также необходимо было учитывать объемы бизнеса. Здесь мы основывали планирование мощности на бизнес-показателях, таких как предполагаемое количество зрителей прямых трансляций, максимальное количество запросов на Crypto Box, сквозная задержка и другие факторы.
После сбора данных наши процессы управления мощностью агрегируют и суммируют многочисленные данные, собранные по конкретному драйверу мощности. Агрегированное значение метрики — это единое значение, которое можно использовать в оповещениях о емкости, отчетах и других функциях, связанных с емкостью.
Мы можем применить несколько методов агрегирования данных к периодическим точкам данных, таким как сумма, среднее значение, медиана, минимум, максимум, процентиль и рекордно высокий уровень (ATH).

Выбранный нами метод определяет результаты процесса управления мощностью и принимаемые на его основе решения. Мы выбираем разные методы, исходя из разных сценариев. Например, мы используем метод максимума для критически важных сервисов и связанных с ними точек данных. Для записи максимального трафика мы используем метод ATH.
Для разных случаев использования мы используем разные типы детализации для агрегирования данных. В большинстве случаев мы используем минуты, часы, дни или ATH.
С точностью до минуты мы измеряем рабочую нагрузку службы для своевременного оповещения о перегрузке.
Мы используем почасовые агрегированные данные для создания ежедневных данных и агрегируем почасовые данные для регистрации дневного пика.
Обычно мы используем ежедневные данные для отчетов о мощности и используем данные ATH для моделирования и планирования мощности.
Одним из основных показателей управления мощностью является сравнительный анализ услуг. Это помогает нам точно измерять производительность и емкость сервиса. Мы получаем тест сервиса с помощью нагрузочного тестирования, и мы углубимся в это более подробно позже.
Управление мощностями на основе приоритета
До сих пор мы видели, как мы собираем показатели мощности и агрегируем данные с различными типами детализации. Еще одной важной областью для обсуждения является приоритет, который полезен в контексте оповещений и отчетов о мощности. После ранжирования ИТ-активов приоритизируется ограниченное использование инфраструктуры и вычислительные ресурсы, которые в первую очередь отдаются критически важным службам и видам деятельности.
Существует несколько способов определения критичности обслуживания и запроса. Полезная ссылка — Google. В книге СРЕ. Они определяют уровни критичности как CRITICAL_PLUS, CRITICAL, SHEDDABLE_PLUS и т. д. Аналогичным образом мы определяем несколько уровней приоритета, таких как P0, P1, P2 и т. д.
Мы определяем уровни приоритета следующим образом:
P0: Для наиболее важных сервисов и запросов — тех, которые в случае сбоя приведут к серьезным, видимым для пользователя последствиям.
P1: Для тех услуг и запросов, которые приведут к заметному пользователю воздействию, но влияние будет меньше, чем у P0. Ожидается, что услуги P0 и P1 будут предоставляться с достаточной пропускной способностью.
P2: это приоритет по умолчанию для пакетных и автономных заданий. Эти услуги и запросы могут не оказать заметного воздействия на пользователя, если они частично недоступны.
Что такое нагрузочное тестирование и почему мы используем его в производственной среде?
Нагрузочное тестирование — это нефункциональный процесс тестирования программного обеспечения, при котором производительность приложения проверяется при определенной рабочей нагрузке. Это помогает определить, как ведет себя приложение при одновременном доступе к нему нескольких конечных пользователей.
В Binance мы создали решение, позволяющее проводить нагрузочное тестирование в рабочей среде. Обычно нагрузочное тестирование проводится в промежуточной среде, но мы не могли использовать эту опцию из-за наших общих целей управления мощностью. Нагрузочное тестирование в производственной среде позволило нам:
Получите точную оценку качества наших услуг в реальных условиях нагрузки.
Повысьте доверие к системе, ее надежности и производительности.
Выявляйте узкие места в системе до того, как они возникнут в производственной среде.
Обеспечьте непрерывный мониторинг производственной среды.
Обеспечьте упреждающее управление емкостью с помощью нормализованных циклов тестирования, которые проводятся регулярно.
Ниже вы можете увидеть нашу структуру нагрузочного тестирования с некоторыми ключевыми выводами:

Инфраструктура микросервисов Binance имеет базовый уровень для поддержки маршрутизации трафика на основе конфигурации и флагов, что важно для нашего подхода TIP.
Для оценки тестируемого экземпляра используется автоматический канареечный анализ (ACA). Он сравнивает ключевые показатели, собранные в системе мониторинга, поэтому мы можем приостановить/прекратить тестирование в случае возникновения какой-либо непредвиденной проблемы, чтобы минимизировать воздействие на пользователя.
Контрольные показатели и метрики собираются во время нагрузочного тестирования для получения аналитических данных о поведении и производительности приложений.
API-интерфейсы позволяют обмениваться ценными данными о производительности в различных сценариях, например, при управлении емкостью и обеспечении качества. Это помогает создать открытую экосистему.
Мы создаем рабочие процессы автоматизации для координации всех шагов и точек контроля с точки зрения сквозного тестирования. Мы также обеспечиваем гибкость интеграции с другими системами, такими как конвейер CI/CD и операционный портал.
Наш подход к тестированию в производстве (TIP)
Традиционный подход к тестированию производительности (выполнение тестов в промежуточной среде с симулированным или зеркальным трафиком) действительно дает некоторые преимущества. Однако в нашем контексте развертывание промежуточной среды, аналогичной производственной, имеет больше недостатков:
Это почти удваивает затраты на инфраструктуру и затраты на ее обслуживание.
Обеспечить сквозную работу в производстве невероятно сложно, особенно в крупномасштабной среде микросервисов, охватывающей несколько бизнес-подразделений.
Это добавляет больше рисков для конфиденциальности и безопасности данных, поскольку нам неизбежно может потребоваться дублировать данные на этапе подготовки.
Имитируемый трафик никогда не будет повторять то, что на самом деле происходит в производстве. Контрольный показатель, полученный в промежуточной среде, будет неточным и будет иметь меньшую ценность.
Тестирование в рабочей среде, также известное как TIP, представляет собой методологию тестирования со смещением вправо, при которой новый код, функции и выпуски тестируются в производственной среде. Принятое нами нагрузочное тестирование в производстве очень полезно, поскольку оно помогает нам:
Проанализируйте стабильность и надежность системы.
Узнайте тесты и узкие места приложений при различных уровнях трафика, характеристиках серверов и параметрах приложений.
Маршрутизация на основе FlowFlag
Наша маршрутизация на основе FlowFlag, встроенная в базовую структуру микросервисов, является основой для возможности TIP. Это справедливо для конкретных случаев, включая приложения, использующие обнаружение службы Eureka для распределения трафика.
Как показано на диаграмме, веб-сервер Binance в качестве точек входа помечает некоторый процент трафика, как указано в конфигах, заголовками FlowFlag. Во время нагрузочного теста мы можем выбрать один хост определенного сервиса и пометить его как целевой экземпляр производительности в configs, то помеченные запросы perf в конечном итоге будут перенаправлены на экземпляр perf, когда они достигнут службы для обработки.
Он полностью управляется конфигурацией и имеет горячую загрузку, поэтому мы можем легко регулировать процент рабочей нагрузки с помощью автоматизации без необходимости развертывания новой версии.
Его можно широко применять к большинству наших сервисов, поскольку этот механизм является частью шлюзового и базового пакета.
Единая точка изменения также означает легкий откат для снижения рисков в производстве.

Трансформируя наше решение, чтобы сделать его более ориентированным на облако, мы также изучаем, как мы можем создать аналогичный подход для поддержки другой маршрутизации трафика, предлагаемой поставщиками общедоступных облаков или Kubernetes.
Автоматический канареечный анализ для минимизации рисков воздействия на пользователя
Canary-развертывание — это стратегия развертывания, позволяющая снизить риск развертывания новой версии программного обеспечения в рабочей среде. Обычно это предполагает развертывание новой версии программного обеспечения, называемой канареечной версией, для небольшой группы пользователей наряду со стабильно работающей версией. Затем мы разделяем трафик между двумя версиями, чтобы часть входящих запросов перенаправлялась на канарейку.
Затем качество канареечной версии оценивается с помощью так называемого канареечного анализа. При этом сравниваются ключевые метрики, описывающие поведение старой и новой версий. При значительном ухудшении показателей канарейка прерывается, и весь трафик перенаправляется на стабильную версию, чтобы минимизировать влияние неожиданного поведения.
Мы используем ту же концепцию для создания нашего решения для автоматического нагрузочного тестирования. Решение использует платформу Kayenta для автоматического канареечного анализа (ACA) через Spinnaker для обеспечения автоматического развертывания canary. Наш типичный процесс нагрузочного теста при использовании этого метода выглядит так:
В рамках рабочего процесса мы постепенно добавляем нагрузку трафика (например, 5%, 10%, 25%, 50%) на целевой хост, как указано, или до тех пор, пока он не достигнет своей критической точки.
При каждой загрузке с помощью Kayenta повторно запускается канареечный анализ в течение некоторого времени (например, 5 минут) для сравнения ключевых показателей тестируемого хоста с периодом предварительной загрузки в качестве базового уровня и текущим периодом после загрузки в качестве эксперимента.
Сравнение (модель канареечной конфигурации) фокусируется на проверке того, является ли целевой хост:
Достигает ограничений ресурсов, например загрузка ЦП превышает 90%.
Имеет значительное увеличение показателей сбоев, например журналов ошибок, исключений HTTP или отклонений ограничения скорости.
Имеет ли основные показатели приложения все еще разумные значения, например, задержка HTTP менее 2 секунд (настраивается для каждой службы)
Для каждого анализа Kayenta предоставляет нам отчет с указанием результата, и тест немедленно прекращается в случае неудачи.
Обнаружение сбоя обычно занимает менее 30 секунд, что значительно снижает вероятность влияния на работу наших конечных пользователей.

Включение анализа данных
Крайне важно собрать достаточную информацию обо всех ранее описанных процессах и выполнении тестов. Конечная цель — повысить надежность и надежность нашей системы, что невозможно без анализа данных.
В общей сводке теста указывается максимальный процент нагрузки, который хост мог выдержать, пиковая загрузка ЦП и количество запросов в секунду хоста. На основании этого он также оценивает количество экземпляров, которые нам, возможно, потребуется развернуть для выполнения резервирования мощности, учитывая рекордно высокий уровень количества запросов в секунду для сервисов.
Другая ценная информация для анализа включает версию программного обеспечения, характеристики сервера, количество развертываний и ссылку на панель мониторинга монитора, где мы можем просмотреть, что произошло во время теста.

Кривая производительности показывает, как изменилась производительность за последние три месяца, поэтому мы можем обнаружить любые возможные проблемы, связанные с конкретной версией приложения.

Тенденции ЦП и количества кадров в секунду показывают, как загрузка ЦП коррелирует с объемом запросов, которые должен был обработать сервер. Эта метрика может помочь оценить запас сервера для роста входящего трафика.
Поведение задержки API показывает, как меняется время ответа в зависимости от условий нагрузки для пяти основных API. Затем мы можем оптимизировать систему, если это необходимо, на уровне отдельного API.

Метрики распределения нагрузки API помогают нам понять, как состав API влияет на производительность сервиса, и дают больше информации об областях улучшения.
Нормализация и продуктизация
Поскольку наша система продолжает расти и развиваться, мы будем продолжать отслеживать и улучшать стабильность и надежность обслуживания. Мы продолжим это через:
Регулярный и установленный график нагрузочного тестирования критически важных сервисов.
Автоматическое нагрузочное тестирование как часть наших конвейеров CI/CD.
Повышенная производительность всего решения для подготовки к его широкомасштабному внедрению во всей организации.
Ограничения
Текущий подход к нагрузочному тестированию имеет некоторые ограничения:
Маршрутизация на основе FlowFlag применима только к нашей платформе микросервисов. Мы стремимся расширить решение для большего количества сценариев маршрутизации, используя общую функцию взвешенной маршрутизации облачных балансировщиков нагрузки или вход Kubernetes.
Поскольку мы основываем тест на реальном пользовательском трафике в рабочей среде, мы не можем выполнять тесты функций для конкретных API или сценариев использования. Кроме того, для услуг с очень небольшим объемом ценность будет ограничена, поскольку мы не сможем определить их узкое место.
Мы проводим эти тесты для отдельных сервисов, а не охватываем сквозные цепочки вызовов.
Тестирование в производстве иногда может повлиять на реальных пользователей в случае возникновения сбоев. Поэтому нам необходим анализ ошибок и автоматический откат с возможностью полной автоматизации.
Заключительные мысли
Нам крайне важно продумать сценарии резкого увеличения трафика, чтобы предотвратить перегрузку системы и обеспечить ее бесперебойную работу. Вот почему мы создали процессы управления мощностью и нагрузочного тестирования, описанные в этой статье. Обобщить:
Наше управление мощностью осуществляется в зависимости от пиковой нагрузки и встроено в каждый этап жизненного цикла услуги, предотвращая перегрузку такими действиями, как измерения, настройка приоритетов, оповещения и отчеты о мощности и т. д. В конечном итоге именно это делает процессы и потребности Binance уникальными по сравнению с типичной ситуацией управления мощностью. .
Контрольный показатель обслуживания, полученный в результате нагрузочного тестирования, является основой управления и планирования мощности. Он точно определяет ресурс инфраструктуры, необходимый для поддержки текущих и будущих потребностей бизнеса. В конечном итоге это пришлось реализовать в производстве с помощью уникального решения, созданного Binance, которое позволило бы нам удовлетворить наши конкретные потребности.
Мы надеемся, что, сложив все это вместе, вы увидите, что хорошее планирование и тщательная структура помогают создать сервис, который знают и любят пользователи Binancian.
Рекомендации
Доминик Огбонна, «Управление мощностью от А до Я: Практическое руководство по внедрению корпоративного ИТ-мониторинга и планирования мощности», глава 4, глава 6
Луис Кесада Торрес, Дуг Колиш, SRE: Передовые методы управления мощностями
Алехандро Фореро Куэрво, Сара Чавис, книга Google SRE, глава 21 — Управление перегрузкой
Дальнейшее чтение
(Блог) Как Binance Ledger улучшает ваш опыт работы с Binance
(Блог) Представляем Binance Oracle VRF: новое поколение проверяемой случайности
(Блог) Binance присоединяется к Альянсу FIDO в рамках подготовки к внедрению пароля