

Сравнительный анализ схем с использованием SHA-256

Мы хотели бы поблагодарить команды из Polygon Zero, проекта gnark в Consensys, Pado Labs и Delphinus Lab за ценные обзоры и отзывы в этом блоге.
Пантеон доказательства с нулевым разглашением
За последние несколько месяцев мы посвятили значительное количество времени и усилий разработке передовой инфраструктуры, использующей краткие доказательства zk-SNARK. В рамках наших усилий по разработке мы протестировали и использовали широкий спектр сред разработки с нулевым разглашением (ZKP). Хотя этот путь был плодотворным, мы понимаем, что обилие доступных платформ ZKP часто создает проблемы для новых разработчиков, которые пытаются найти наиболее подходящую для их конкретных случаев использования и требований к производительности. Принимая во внимание этот болевой момент, мы считаем, что необходима платформа оценки сообщества, способная предоставить исчерпывающие результаты тестов и которая очень поможет в разработке этих новых приложений.
Чтобы удовлетворить эту потребность, мы запускаем «Пантеон доказательства с нулевым разглашением» в качестве инициативы сообщества общественного блага. Первым шагом будет поощрение сообщества к обмену воспроизводимыми результатами сравнительного анализа из различных структур ZKP. Наша конечная цель — коллективно и совместно создать и поддерживать общепризнанный испытательный стенд, охватывающий низкоуровневые среды разработки схем, высокоуровневые zkVM и компиляторы, а также поставщиков аппаратного ускорения. Мы надеемся, что эта инициатива ускорит внедрение ZKP, облегчив принятие обоснованных решений, а также будет способствовать развитию и итерации самих структур ZKP, предоставляя набор общедоступных результатов сравнительного анализа. Мы стремимся инвестировать в эту инициативу и приглашаем всех членов сообщества-единомышленников присоединиться к нам и вместе внести свой вклад в эти усилия!
Первый шаг: сравнительный анализ схем с использованием SHA-256
В этом сообщении блога мы делаем первый шаг к созданию Пантеона ZKP, предоставляя воспроизводимый набор результатов тестов с использованием SHA-256 в ряде сред разработки низкоуровневых схем. Хотя мы признаем, что возможны другие степени детализации и примитивы сравнительного анализа, мы выбрали SHA-256 из-за его применимости к широкому спектру вариантов использования ZKP, включая системы блокчейнов, цифровые подписи, zkDID и многое другое. Также стоит отметить, что мы также используем SHA-256 в нашей собственной системе, поэтому для нас это тоже очень удобно! 😂
Наш тест оценивает производительность SHA-256 в различных средах разработки схем zk-SNARK и zk-STARK. Посредством этого сравнения мы стремимся предоставить разработчикам представление об эффективности и практичности каждой платформы. Наша цель состоит в том, чтобы эти результаты позволили разработчикам принимать обоснованные решения при выборе наиболее подходящей среды для своих проектов.
Доказательственные системы
В последние годы мы наблюдаем распространение систем доказательства с нулевым разглашением. Несмотря на то, что идти в ногу со всеми захватывающими достижениями в этой области сложно, мы тщательно отобрали следующие системы проверки с учетом их зрелости и признания разработчиками. Наша цель — представить репрезентативную выборку различных комбинаций внешнего и внутреннего интерфейса.
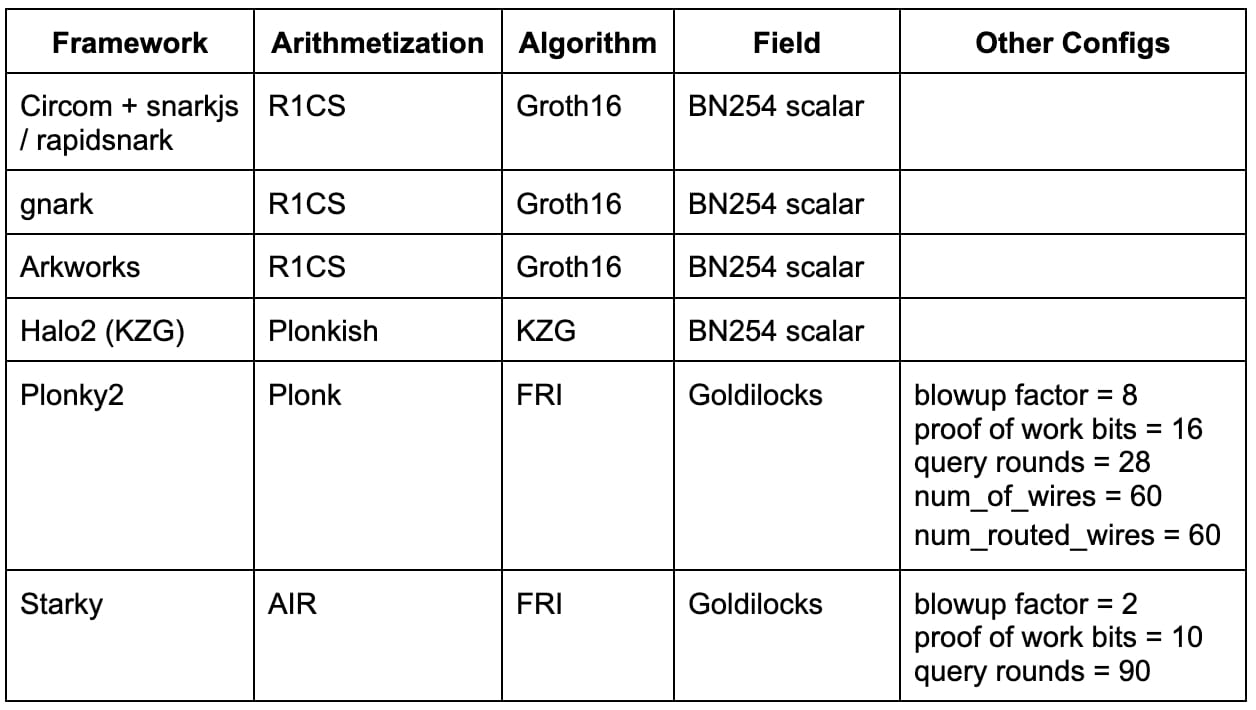
Circom + snarkjs/rapidsnark: Circom — популярный DSL для написания схем и генерации ограничений R1CS, тогда как snarkjs может генерировать доказательства Groth16 или Plonk для Circcom. Rapidsnark также является средством доказательства для Circcom, которое генерирует доказательства Groth16 и обычно работает намного быстрее, чем snarkjs, благодаря использованию расширения ADX, которое максимально распараллеливает генерацию доказательств.
gnark: gnark — это комплексная платформа Golang от Consensys, которая поддерживает Groth16, Plonk и многие другие расширенные функции.
Arkworks: Arkworks — это комплексная платформа Rust для zk-SNARK.
Halo2 (KZG): Halo2 — это реализация zk-SNARK от Zcash с Plonk. Он оснащен очень гибкой арифметизацией Plonkish, которая поддерживает множество полезных примитивов, таких как пользовательские элементы и таблицы поиска. Мы используем форк Halo2 при поддержке KZG от Ethereum Foundation и Scroll.
Plonky2: Plonky2 — это реализация SNARK, основанная на методах PLONK и FRI из Polygon Zero. Plonky2 использует небольшое поле Златовласки и поддерживает эффективную рекурсию. В нашем тестировании мы ориентировались на 100-битную предполагаемую безопасность и использовали параметры, которые обеспечили наилучшее время проверки для эталонного задания. В частности, мы использовали 28 запросов Меркла, коэффициент расширения 8 и 16-битную задачу проверки выполнения работы. Более того, мы устанавливаем num_of_wires = 60 и num_routed_wires = 60.
Starky: Starky — это высокопроизводительный фреймворк STARK от Polygon Zero. В нашем тестировании мы ориентировались на 100-битную предполагаемую безопасность и использовали параметры, которые обеспечили наилучшее время проверки. В частности, мы использовали 90 запросов Меркла, коэффициент масштабирования 2 и 10-битную задачу проверки выполнения работы.
В таблице ниже приведены вышеперечисленные платформы с соответствующими конфигурациями, использованными в нашем сравнительном тестировании. Этот список ни в коем случае не является исчерпывающим, и многие современные фреймворки/методы (например, Nova, GKR, Hyperplonk) оставлены для будущей работы.
Имейте в виду, что эти результаты тестов относятся только к средам разработки схем. В будущем мы планируем опубликовать отдельный блог, в котором будут сравниваться различные zkVM (например, Scroll, Polygon zkEVM, Consensys zkEVM, zkSync, Risc Zero, zkWasm) и фреймворки IR-компиляторов (например, Noir, zkLLVM).
Методика сравнительного анализа
Чтобы протестировать эти различные системы проверки, мы вычислили хэш SHA-256 для N байтов данных, где мы экспериментировали с N = 64, 128, ..., 64 КБ (за одним исключением является Starky, где схема повторяет SHA-256). вычисления для фиксированного ввода размером 64 байта, но сохраняют то же общее количество фрагментов сообщения). Тестовый код и реализации схемы SHA-256 можно найти в этом репозитории.
Кроме того, мы провели сравнительное тестирование каждой системы, используя следующие показатели производительности:
Время генерации доказательств (включая время генерации свидетелей)
Пиковое использование памяти во время создания доказательства
Средний процент использования ЦП во время создания доказательства. (Эта метрика отражает степень распараллеливания во время генерации доказательства)
Обратите внимание, что мы делаем некоторые предположения относительно размера доказательства и стоимости проверки доказательства, поскольку эти аспекты можно смягчить, связавшись с Groth16/KZG перед запуском цепочки.
Машины
Мы провели бенчмаркинг на двух разных машинах:
Linux-сервер: 20 ядер с частотой 2,3 ГГц, 384 ГБ памяти.
Macbook M1 Pro: 10 ядер @3,2 ГГц, 16 ГБ памяти
Сервер Linux использовался для моделирования сценария с большим количеством ядер ЦП и большим объемом памяти. В то время как Macbook M1 Pro, который обычно используется для исследований и разработок, имеет более мощный процессор с меньшим количеством ядер.
Мы включили многопоточность там, где это необязательно, но в этом тесте мы не использовали ускорение графического процессора. Мы планируем включить тестирование графических процессоров в нашу будущую работу.
Результаты тестов
Количество ограничений
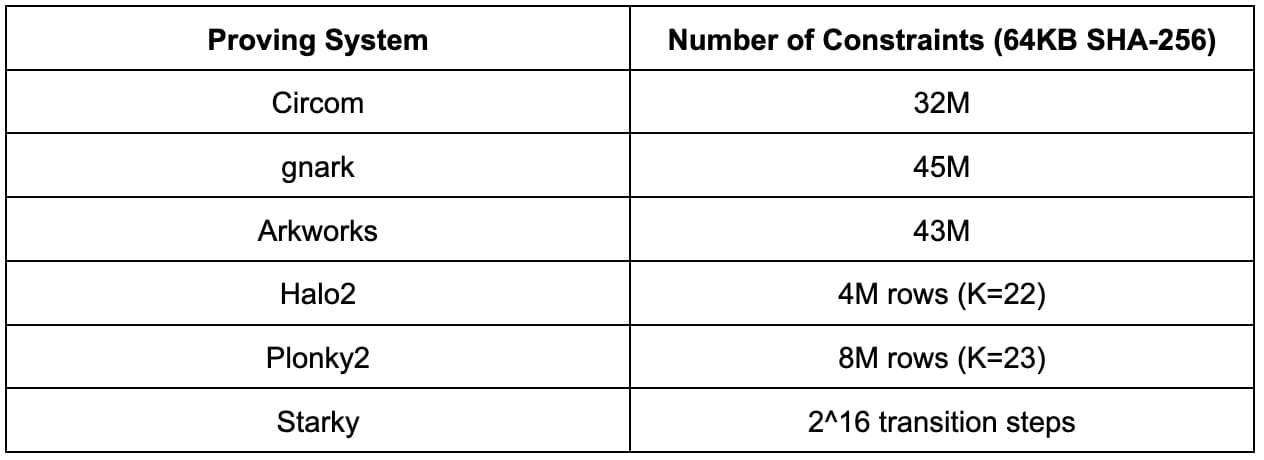
Прежде чем мы перейдем к подробным результатам сравнительного анализа, полезно сначала понять сложность SHA-256, взглянув на количество ограничений в каждой системе проверки. Важно помнить, что числа ограничений в различных схемах арифметизации не сопоставимы напрямую.
Результаты ниже соответствуют размеру предварительного изображения 64 КБ. Хотя результаты могут различаться в зависимости от других размеров прообразов, их можно масштабировать примерно линейно.
Circcom, gnark и Arkworks используют одну и ту же арифметизацию R1CS, а количество ограничений R1CS для вычисления SHA-256 размером 64 КБ составляет примерно от 30 до 45 миллионов. Разница между Circcom, Gnark и Arkworks, скорее всего, связана с различиями в реализации.
Halo2 и Plonky2 используют арифметику Plonkish, где количество строк варьируется от 2^22 до 2^23. Реализация SHA-256 в Halo2 намного эффективнее, чем в Plonky2, благодаря использованию справочных таблиц.
Старки использует арифметизацию AIR, где таблицы трассировки выполнения требуют 2^16 шагов перехода.
Время генерации доказательства
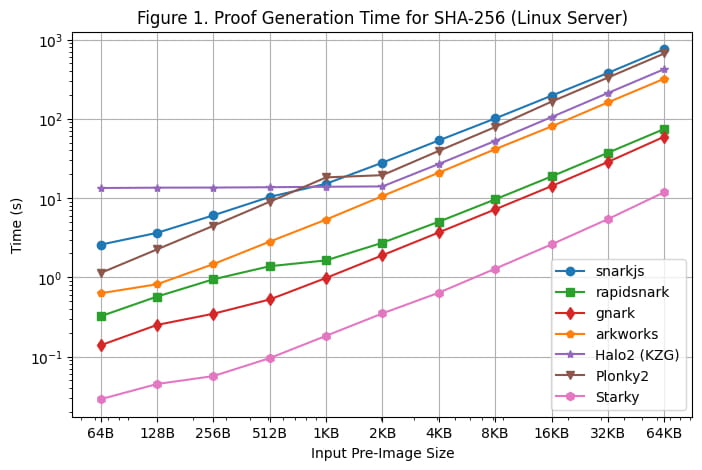
[Рисунок 1] иллюстрирует время создания доказательства каждой платформы для SHA-256 для различных размеров предварительных изображений с использованием Linux Server. Мы можем сделать следующие наблюдения:
Для SHA-256 фреймворки Groth16 (rapidsnark, gnark и Arkworks) генерируют доказательства быстрее, чем фреймворки Plonk (Halo2 и Plonky2). Это связано с тем, что SHA-256 в основном состоит из побитовых операций, где значения проводов равны 0 или 1. Для Groth16 это сокращает большую часть вычислений от скалярного умножения эллиптической кривой до сложения точек эллиптической кривой. Однако значения проводов не используются напрямую в вычислениях Plonk, поэтому специальная структура проводов в SHA-256 не уменьшает объем вычислений, необходимых в средах Plonk.
Среди всех фреймворков Groth16 gnark и Rapidsnark в 5–10 раз быстрее, чем Arkworks и snarkjs. Это происходит благодаря их превосходным возможностям использования нескольких ядер для распараллеливания генерации доказательств. Гнарк на 25% быстрее, чем Rapidsnark.
Для фреймворков Plonk Plonky2 на 50% медленнее, чем Halo2 для SHA-256, при использовании большего размера предварительного изображения >= 4 КБ. Это связано с тем, что реализация Halo2 активно использует таблицу поиска для ускорения побитовых операций, в результате чего строк получается в 2 раза меньше, чем в Plonky2. Однако, если мы сравним Plonky2 и Halo2 с одинаковым количеством строк (например, SHA-256 более 2 КБ в Halo2 и SHA-256 более 4 КБ в Plonky2), Plonky2 будет на 50% быстрее, чем Halo2. Если мы реализуем SHA-256 с таблицей поиска в Plonky2, мы должны ожидать, что Plonky2 будет быстрее, чем Halo2, хотя размер доказательства Plonky2 больше.
С другой стороны, когда размер входного прообраза небольшой (<=512 байт), Halo2 работает медленнее, чем Plonky2 (и другие фреймворки) из-за фиксированной стоимости установки таблицы поиска, на которую приходится большая часть ограничений. Однако по мере увеличения предварительного изображения производительность Halo2 становится более конкурентоспособной: время генерации доказательства остается постоянным для размеров предварительного изображения до 2 КБ, а затем масштабируется почти линейно, как видно на графике.
Как и ожидалось, время генерации доказательства в Starky значительно короче (в 5–50 раз), чем в любой системе SNARK, но за это приходится платить гораздо большим размером доказательства.
Дополнительное примечание: даже если размер схемы линеен по размеру прообраза, генерация доказательства для SNARK растет суперлинейно из-за O(nlogn) БПФ (хотя на графике это не очевидно из-за логарифмический масштаб).
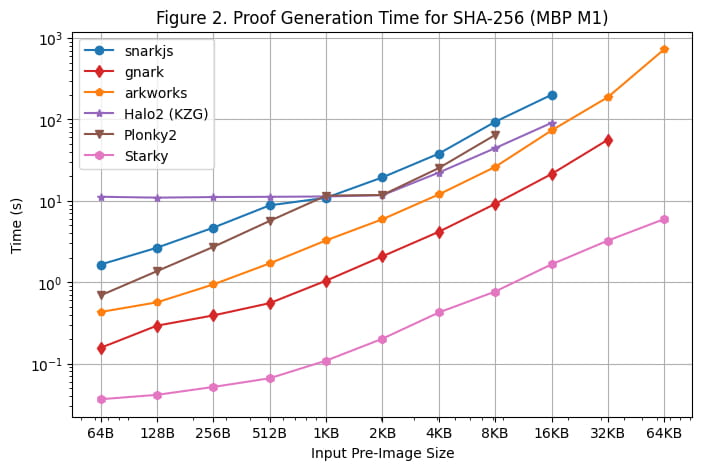
Мы также провели тест времени генерации доказательства на Macbook M1 Pro, как показано на [рис. 2]. Однако важно отметить, что RapidSnark не был включен в этот тест из-за отсутствия поддержки архитектуры Arm64. Чтобы использовать snarkjs на Arm64, нам пришлось сгенерировать свидетеля с помощью веб-сборки, что медленнее, чем генерация свидетеля C++, используемая на Linux-сервере.
При запуске теста на Macbook M1 Pro было обнаружено несколько дополнительных наблюдений:
За исключением Starky, все платформы SNARK сталкивались с ошибками нехватки памяти (OOM) или использовали память подкачки (что приводило к замедлению времени проверки), когда размер предварительного изображения становился большим. В частности, фреймворки Groth16 (snarkjs, gnark, Arkworks) начали использовать память подкачки, когда размер предварительного образа был больше или равен 8 КБ, а gnark столкнулся с OOM для 64 КБ. Halo2 столкнулся с ограничением памяти, когда размер предварительного изображения был больше или равен 32 КБ. Plonky2 начинает использовать память подкачки, когда размер предварительного изображения превышает или равен 8 КБ.
Фреймворки на основе FRI (Starky и Plonky2) работали примерно на 60 % быстрее на Macbook M1 Pro, чем на Linux Server, в то время как время проверки других фреймворков было примерно таким же, как и на Linux Server. В результате Plonky2 показал почти такое же время проверки, что и Halo2 на Macbook M1 Pro, даже несмотря на то, что таблица поиска не использовалась в Plonky2. Основная причина этого в том, что Macbook M1 Pro имеет более мощный процессор, но с меньшим количеством ядер. FRI в основном выполняет хэш-операции, которые более чувствительны к тактовой частоте процессора, но не так распараллеливаются, как KZG/Groth16.
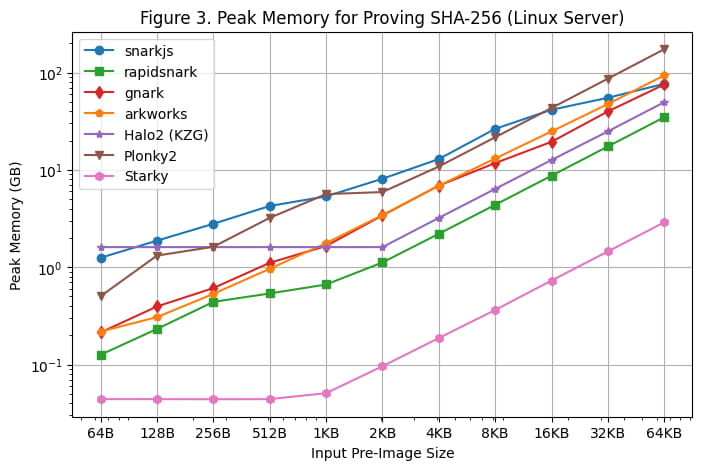
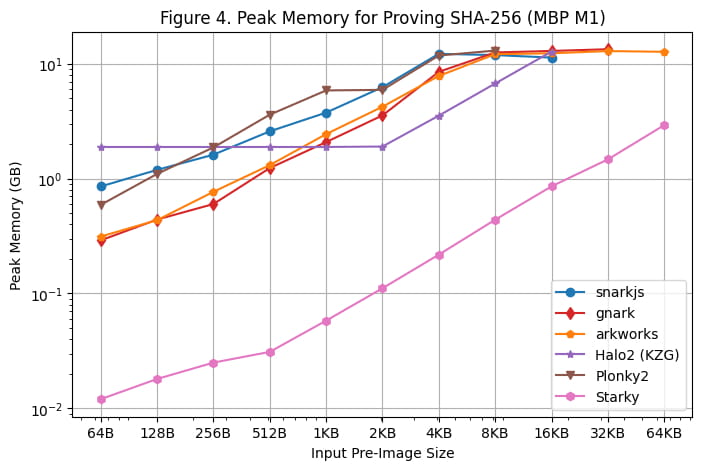
Пиковое использование памяти
Пиковое использование памяти во время создания доказательства на Linux Server и Macbook M1 Pro показано на [Рис. 3] и [Рис. 4] соответственно. На основе результатов сравнительного анализа можно сделать следующие наблюдения:
Среди всех фреймворков SNARK Rapidsnark является наиболее эффективным с точки зрения использования памяти. Мы также видим, что Halo2 использует больше памяти, когда размер предварительного изображения меньше из-за фиксированной стоимости настройки таблицы поиска, но в целом потребляет меньше памяти, когда размер предварительного изображения больше.
Starky более чем в 10 раз эффективнее использует память, чем фреймворки SNARK. Частично это связано с использованием меньшего количества строк.
Следует отметить, что пиковое использование памяти на Macbook M1 Pro остается относительно стабильным, поскольку размер предварительного изображения становится большим из-за использования памяти подкачки.
Загрузка ЦП
Мы оценили степень распараллеливания для каждой системы проверки, измерив среднюю загрузку ЦП во время генерации доказательства для SHA-256 на входном предварительном изображении размером 4 КБ. В таблице ниже показана средняя загрузка ЦП (и средняя загрузка каждого ядра в скобках). ) как на Linux Server (с 20 ядрами), так и на Macbook M1 Pro (с 10 ядрами).
Ключевые наблюдения заключаются в следующем:
Gnark и Rapidsnark демонстрируют самую высокую загрузку ЦП на Linux-сервере, что указывает на их способность эффективно использовать несколько ядер и распараллеливать генерацию доказательств. Halo2 также демонстрирует хорошую производительность распараллеливания.
Большинство фреймворков демонстрируют двукратную загрузку ЦП на Linux-сервере по сравнению с Macbook Pro M1, исключением является snarkjs.
Несмотря на первоначальные ожидания, что фреймворки на основе FRI (Plonky2 и Starky) могут с трудом эффективно использовать несколько ядер, в наших тестах они работают не хуже, чем некоторые фреймворки Groth16/KZG. Еще неизвестно, будут ли какие-либо различия в загрузке ЦП на машине с еще большим количеством ядер (например, 100 ядер).

Заключение и будущая работа
В этом сообщении блога представлено всестороннее сравнение производительности SHA-256 в различных платформах разработки zk-SNARK и zk-STARK. Благодаря результатам тестов мы получили представление об эффективности и практичности каждой платформы для разработчиков, которым требуются краткие доказательства операций SHA-256. Установлено, что фреймворки Groth16 (например, Rapidsnark, Gnark) генерируют доказательства быстрее, чем фреймворки Plonk (например, Halo2, Plonky2). Таблица поиска в арифметике Планкиша значительно уменьшает ограничения и время проверки для SHA-256 при использовании большего размера предварительного изображения. Более того, gnark и Rapidsnark демонстрируют отличную возможность использовать несколько ядер для распараллеливания. Старки, с другой стороны, показывает гораздо более короткое время создания доказательства, но за счет гораздо большего размера доказательства. С точки зрения эффективности использования памяти Rapidsnark и Starky превосходят другие фреймворки.
В качестве первых шагов к построению Пантеона ZKP мы признаем, что этот результат теста далек от того, чтобы стать окончательным комплексным испытательным стендом, к которому мы стремимся однажды. Мы приветствуем отзывы и критику, открыты для них и приглашаем всех внести свой вклад в эту инициативу, направленную на то, чтобы сделать ZKP более простым и доступным для использования разработчиками. Мы также готовы предоставить гранты отдельным участникам для покрытия затрат на вычислительные ресурсы для крупномасштабного сравнительного анализа. Вместе мы можем повысить эффективность и практичность ZKP на благо более широкого сообщества.