
3D Avatar Diffusion — это алгоритм машинного обучения, который может взять одно 2D-изображение человеческого лица и создать трехмерный (3D) аватар. Затем аватар можно использовать для создания виртуальной реальности (VR) или дополненной реальности (AR) или просто для обеспечения реалистичного трехмерного изображения человека для игр или других целей.
Модель диффузии была разработана командой исследователей Microsoft Research и описана в статье, опубликованной в журнале arXiv.

3D-аватар Diffusion основан на алгоритме машинного обучения, называемом моделью диффузии. Модели диффузии являются генеративными моделями, что означает, что они могут генерировать новые данные, аналогичные обучающим данным. Модели диффузии использовались и раньше для создания 3D-изображений из 2D-изображений, но ADM является первой моделью диффузии, которая может генерировать реалистичный 3D-аватар из одного 2D-изображения.
Для обучения модели исследователи использовали набор данных из более чем 200 000 3D-моделей лиц. Набор данных включал в себя самые разные лица с разными оттенками кожи, прическами и чертами лица. Затем ADM смог изучить взаимосвязь между 2D-изображением и 3D-моделью лица и создать реалистичный 3D-аватар из одного 2D-изображения.
Модель также можно использовать для создания аватара из фотографии, сделанной под другим углом.
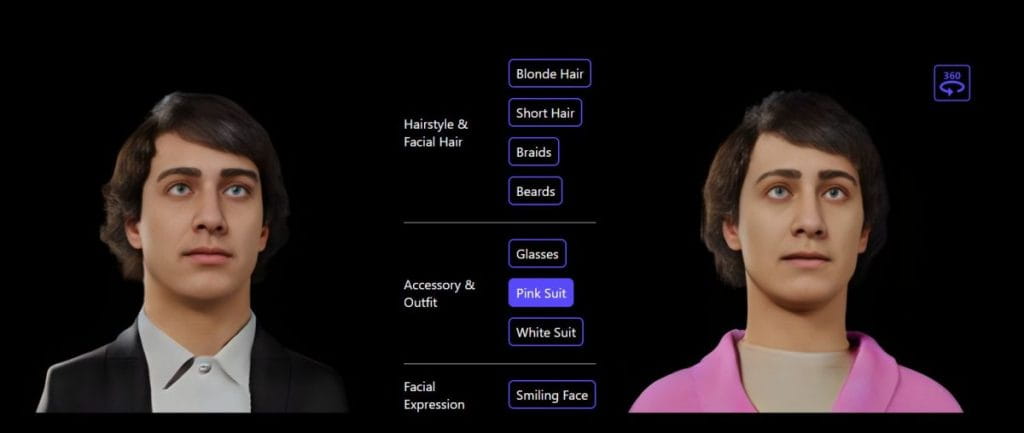 Для персонализированного 3D-аватара модель Родена предлагает манипуляции с текстом. Редактирование естественного языка — это интуитивно понятный способ изменить множество различных функций 3D-аватара.
Для персонализированного 3D-аватара модель Родена предлагает манипуляции с текстом. Редактирование естественного языка — это интуитивно понятный способ изменить множество различных функций 3D-аватара.
В этом исследовании предлагается 3D-генеративная модель, которая автоматически создает трехмерные цифровые аватары, которые представляются в виде полей нейронного излучения с использованием диффузионных моделей. Из-за непомерно высоких требований к памяти и обработке, связанных с 3D, создание богатых функций, необходимых для высококачественных аватаров, является огромной проблемой. Разработчики предлагают использовать развертываемую диффузионную сеть (Rodin) для решения этой проблемы.
 С точки зрения пола, возраста, расы, выражения лица, аксессуаров на лице и т. д. модель демонстрирует выдающееся разнообразие поколений.
С точки зрения пола, возраста, расы, выражения лица, аксессуаров на лице и т. д. модель демонстрирует выдающееся разнообразие поколений.
Эта сеть развертывает многочисленные 2D-карты объектов поля нейронного излучения в единую 2D-плоскость объектов, где модель затем выполняет диффузию с учетом 3D. Модель Родена использует свертку с учетом 3D, которая обрабатывает проецируемые элементы в 2D-плоскости объектов в соответствии с их исходными отношениями в 3D, чтобы обеспечить столь необходимую вычислительную эффективность, сохраняя при этом целостность диффузии в 3D.
Подробнее об ИИ:
ВАЛЛ-И: новая модель преобразования текста в речь от Microsoft с нулевым значением может дублировать голос каждого человека за три секунды
VALL-E от Microsoft оказался самым опасным мошенническим ПО за всю историю
Художник создает скрипт защиты от кражи для защиты произведений искусства и использует тот же водяной знак, что и генераторы ИИ.
Microsoft и Google в 2023 году: главное противостояние года между титанами искусственного интеллекта
Сообщение Microsoft выпустила диффузионную модель, которая может построить 3D-аватар из одной фотографии человека, впервые появившейся на Metaverse Post.