
Источник: Зик, NWU Capital.

Предисловие
С момента появления GPT-3 генеративный ИИ открыл взрывной поворотный момент в области искусственного интеллекта с его потрясающей производительностью и широкими сценариями применения, и технологические гиганты начали собираться вместе, чтобы перейти на путь ИИ. Но также возникают проблемы для обучения и вывода больших языковых моделей (LLM). При итеративном обновлении модели требования к вычислительной мощности и затраты растут в геометрической прогрессии. На примере GPT-2 и GPT-3 разница в количестве параметров между GPT-2 и GPT-3 составляет 1166 раз (GPT-2 — 150 миллионов параметров, а GPT-3 — 175 миллиардов параметров. Сеанс обучения). GPT-3 Стоимость была рассчитана на основе ценовой модели общедоступного облака графических процессоров того времени, которая составляла до 12 миллионов долларов США, что в 200 раз превышало стоимость GPT-2. В реальных условиях каждый вопрос пользователя требует расчетов. Учитывая 13 миллионов уникальных посещений пользователей в начале этого года, соответствующий спрос на чипы составляет более 30 000 графических процессоров A100. Тогда первоначальная инвестиционная стоимость достигнет ошеломляющих 800 миллионов долларов США, а предполагаемая ежедневная стоимость вывода модели составит 700 000 долларов США.
Недостаточная вычислительная мощность и высокие затраты стали проблемой, с которой столкнулась вся индустрия искусственного интеллекта, но та же проблема, похоже, преследует и индустрию блокчейнов. С одной стороны, не за горами четвёртый халвинг биткоина и одобрение ETF. По мере роста цены в будущем, спрос майнеров на вычислительное оборудование неизбежно значительно возрастёт. С другой стороны, технология доказательства с нулевым разглашением (Zero-Knowledge Proof, сокращённо ZKP) переживает бум, и Виталик неоднократно подчёркивал, что влияние ZK на сферу блокчейнов в следующем десятилетии будет таким же важным, как и сам блокчейн. Хотя будущее этой технологии высоко оценивается индустрией блокчейнов, ZK, из-за своего сложного процесса вычислений, потребляет много вычислительной мощности и времени в процессе генерации доказательств, как и ИИ.
В обозримом будущем дефицит вычислительных мощностей станет неизбежным, поэтому будет ли рынок децентрализованных вычислительных мощностей выгодным бизнесом?
Определение рынка децентрализованных вычислительных мощностей
Рынок децентрализованных вычислительных мощностей фактически эквивалентен рынку децентрализованных облачных вычислений, но, по сравнению с децентрализованными облачными вычислениями, я лично считаю, что этот термин более уместен для описания нового проекта, упомянутого ниже. Рынок децентрализованных вычислительных мощностей должен относиться к подмножеству DePIN (децентрализованной сети физической инфраструктуры), и его цель — создать открытый рынок вычислительных мощностей. Благодаря стимулированию в виде токенов любой, у кого есть свободные вычислительные мощности, может предоставить свои ресурсы на этом рынке, в основном обслуживая пользователей B-стороны и группы разработчиков. Из более известных проектов, таких как децентрализованная сеть решений для рендеринга на базе графических процессоров Render Network и распределенный одноранговый рынок облачных вычислений Akash Network, относятся к этому рынку.
В данной статье мы начнём с основных концепций, а затем рассмотрим три развивающихся рынка в этом направлении: рынок вычислительных мощностей AGI, рынок вычислительных мощностей Bitcoin и рынок вычислительных мощностей AGI на рынке аппаратного ускорения ZK. Последние два будут рассмотрены в разделе «Перспективы потенциальных направлений: рынок децентрализованных вычислительных мощностей (часть 2)».
Обзор хешрейта
Истоки понятия вычислительной мощности восходят к началу изобретения компьютеров. Изначально компьютеры представляли собой механические устройства, выполнявшие вычислительные задачи, а вычислительная мощность определяется вычислительной мощностью механических устройств. С развитием компьютерных технологий понятие вычислительной мощности также претерпело изменения. Сегодня вычислительная мощность обычно определяется способностью аппаратного обеспечения компьютера (процессора, графического процессора, ПЛИС и т. д.) и программного обеспечения (операционной системы, компилятора, приложения и т. д.) работать совместно.
определение
Вычислительная мощность определяется объёмом данных, который может обработать компьютер или другое вычислительное устройство, или количеством вычислительных задач, которые оно может выполнить за определённый период времени. Вычислительная мощность обычно используется для описания производительности компьютера или другого вычислительного устройства. Это важный показатель для измерения вычислительной мощности вычислительного устройства.
Метрики
Вычислительную мощность можно измерить различными способами, например, скоростью вычислений, энергопотреблением, точностью вычислений и параллелизмом. В компьютерной сфере обычно используются такие показатели, как FLOPS (количество операций с плавающей запятой в секунду), IPS (количество инструкций в секунду), TPS (количество транзакций в секунду) и т. д.
FLOPS (операций с плавающей точкой в секунду) характеризует способность компьютера выполнять операции с плавающей точкой (математические операции с числами с десятичной точкой, требующие учета таких факторов, как точность и ошибки округления). FLOPS — это показатель высокопроизводительных вычислительных возможностей компьютера, обычно используемый для измерения вычислительной мощности суперкомпьютеров, высокопроизводительных вычислительных серверов и графических процессоров (GPU). Например, если производительность вычислительной системы составляет 1 TFLOPS (1 триллион операций с плавающей точкой в секунду), это означает, что она может выполнять 1 триллион операций с плавающей точкой в секунду.
IPS (Instructions per Second) — это скорость, с которой компьютер обрабатывает инструкции. Она измеряет, сколько инструкций компьютер может выполнить в секунду. IPS — это показатель производительности одной инструкции компьютера и обычно используется для измерения производительности центрального процессора (ЦП). Например, процессор с IPS 3 ГГц (300 миллионов инструкций в секунду) может выполнять 300 миллионов инструкций в секунду.
Показатель TPS (транзакций в секунду) характеризует способность компьютера обрабатывать транзакции. Он измеряет, сколько транзакций компьютер может выполнить в секунду. Он часто используется для измерения производительности серверов баз данных. Например, если сервер базы данных имеет показатель TPS 1000, это означает, что он может обрабатывать 1000 транзакций в секунду.
Кроме того, существуют некоторые показатели вычислительной мощности для конкретных сценариев применения, такие как скорость вывода, скорость обработки изображений и точность распознавания речи.
Типы хешрейта
Вычислительная мощность графического процессора (GPU) определяется вычислительной мощностью графического процессора (GPU). В отличие от центрального процессора (CPU), графический процессор (GPU) — это аппаратное обеспечение, специально разработанное для обработки графических данных, таких как изображения и видео. Он обладает большим количеством процессорных блоков и эффективными параллельными вычислительными возможностями, а также может выполнять большое количество операций с плавающей запятой одновременно. Поскольку графические процессоры изначально использовались для обработки игровой графики, они обычно имеют более высокие тактовые частоты и большую пропускную способность памяти, чем центральные процессоры, для поддержки сложных графических операций.
Разница между центральным процессором и графическим процессором
Архитектура: вычислительная архитектура центрального и графического процессоров различается. Центральный процессор обычно использует одно или несколько ядер, каждое из которых представляет собой универсальный процессор, способный выполнять множество различных операций. Графический процессор имеет большое количество потоковых процессоров и шейдеров, которые используются специально для выполнения операций, связанных с обработкой изображений.
Параллельные вычисления: графические процессоры, как правило, обладают более высокой вычислительной мощностью. У центральных процессоров ограниченное количество ядер, каждое из которых может выполнять только одну инструкцию, в то время как графические процессоры могут иметь тысячи потоковых процессоров, способных выполнять множество инструкций и операций одновременно. Поэтому графические процессоры, как правило, лучше, чем центральные процессоры, подходят для выполнения параллельных вычислительных задач, таких как машинное обучение и глубокое обучение, которые требуют большого объёма параллельных вычислений.
Программирование: Программирование на графических процессорах сложнее, чем на центральных процессорах, и требует использования специальных языков программирования (таких как CUDA или OpenCL) и специальных методов программирования для использования возможностей параллельных вычислений на графических процессорах. Программирование на центральных процессорах, напротив, проще и может использовать универсальные языки программирования и инструменты программирования.
Важность вычислительной мощности
В эпоху промышленной революции нефть была кровью мира, проникая во все отрасли. Вычислительные мощности заложены в блокчейне, а в грядущую эпоху искусственного интеллекта вычислительные мощности станут мировой «цифровой нефтью». От борьбы крупных компаний за ИИ-чипы и преодоления триллионной отметки акций Nvidia до недавней блокады США высокопроизводительных китайских чипов, в которой подробно описываются их вычислительная мощность, площадь кристалла и даже планы по отключению облачных вычислений на графических процессорах, её важность очевидна. Вычислительные мощности станут товаром следующей эпохи.

Обзор общего искусственного интеллекта
Искусственный интеллект (ИИ) — это новая техническая наука, которая изучает и разрабатывает теории, методы, технологии и прикладные системы для моделирования, расширения и совершенствования человеческого интеллекта. Она зародилась в 1950-х и 1960-х годах. После более чем полувековой эволюции она пережила переплетенное развитие трех волн символизма, коннекционизма и поведенческих субъектов. Сегодня, как новая общая технология, она вносит большие изменения в социальную жизнь и все сферы жизни. Более конкретное определение генеративного ИИ на данном этапе таково: искусственный общий интеллект (ИИО), система искусственного интеллекта с широкими возможностями понимания, которая может демонстрировать интеллект, аналогичный или превосходящий человеческий, в различных задачах и областях. ИИО в основном требует трех элементов: глубокое обучение (ГО), большие данные и масштабную вычислительную мощность.
Глубокое обучение
Глубокое обучение — это подраздел машинного обучения (МО), а алгоритмы глубокого обучения представляют собой нейронные сети, построенные по образцу человеческого мозга. Например, человеческий мозг содержит миллионы взаимосвязанных нейронов, которые работают вместе для изучения и обработки информации. Аналогично, нейронные сети глубокого обучения (или искусственные нейронные сети) состоят из нескольких слоёв искусственных нейронов, работающих вместе внутри компьютера. Искусственные нейроны — это программные модули, называемые узлами, которые используют математические вычисления для обработки данных. Искусственные нейронные сети — это алгоритмы глубокого обучения, которые используют эти узлы для решения сложных задач.
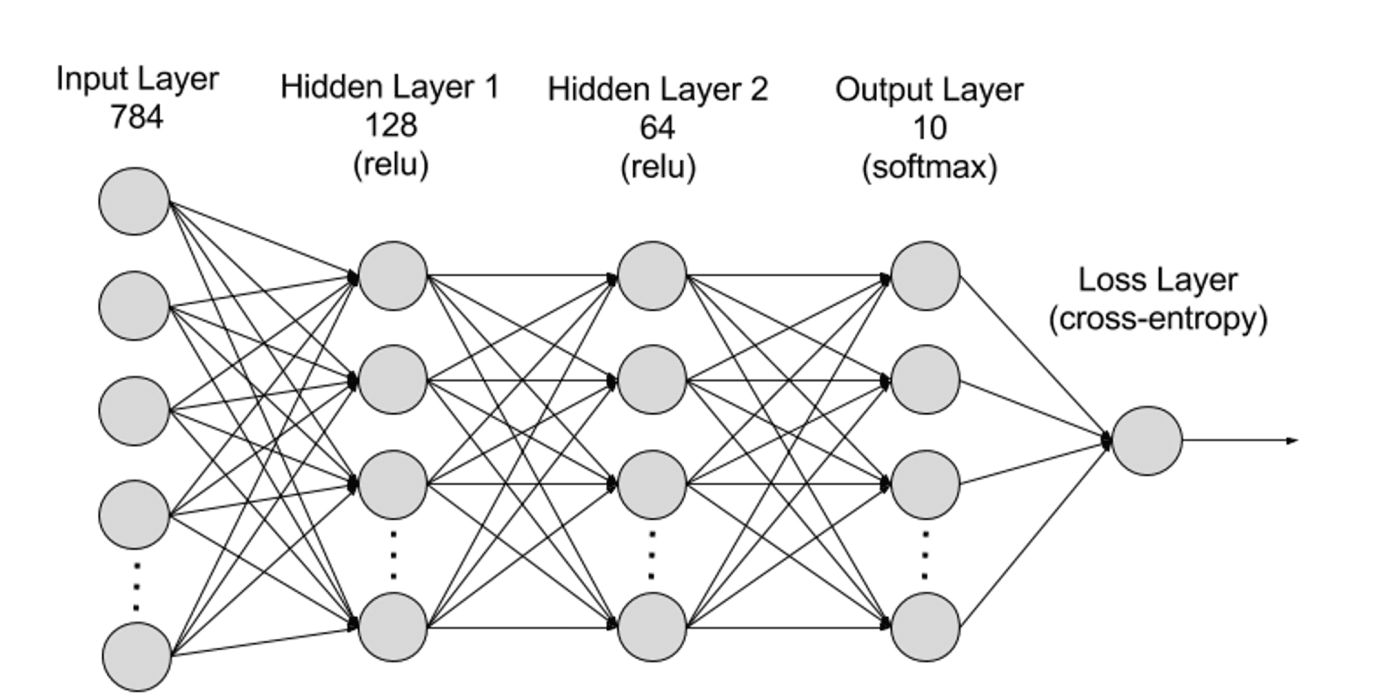
С иерархической точки зрения нейронные сети можно разделить на входной слой, скрытый слой и выходной слой, а связи между различными слоями являются параметрами.
Входной слой: Входной слой — это первый слой нейронной сети, отвечающий за получение внешних входных данных. Каждый нейрон входного слоя соответствует определённому признаку входных данных. Например, при обработке изображений каждый нейрон может соответствовать значению пикселя изображения;
Скрытые слои: входной слой обрабатывает данные и передает их следующим слоям нейронной сети. Эти скрытые слои обрабатывают информацию на разных уровнях, корректируя свое поведение по мере получения новой информации. Сети глубокого обучения имеют сотни скрытых слоев, которые можно использовать для анализа проблем с самых разных сторон. Например, если вам дано изображение неизвестного животного, которое необходимо классифицировать, вы можете сравнить его с животными, которых вы уже знаете. Например, форма ушей, количество ног, размер зрачков и т. д. могут определить, что это за животное. Скрытые слои в глубокой нейронной сети работают таким же образом. Если алгоритм глубокого обучения пытается классифицировать изображение животного, каждый из его скрытых слоев будет обрабатывать различные особенности животного и пытаться точно классифицировать его;
Выходной слой: выходной слой — это последний слой нейронной сети, отвечающий за генерацию выходных данных. Каждый нейрон выходного слоя представляет собой возможную выходную категорию или значение. Например, в задаче классификации каждый нейрон выходного слоя может соответствовать определённой категории, тогда как в задаче регрессии выходной слой может содержать только один нейрон, значение которого представляет собой прогнозируемый результат.
Параметры: В нейронной сети связи между различными слоями представлены весами и смещениями, которые оптимизируются в процессе обучения, чтобы сеть могла точно выявлять закономерности в данных и делать прогнозы. Увеличение параметров может повысить ёмкость модели нейронной сети, то есть её способность обучаться и представлять сложные закономерности в данных. Однако соответствующее увеличение параметров увеличит требования к вычислительной мощности.
Большие данные
Для эффективного обучения нейронным сетям обычно требуются большие объёмы разнообразных и высококачественных данных из различных источников. Это основа для обучения и валидации моделей машинного обучения. Анализируя большие данные, модели машинного обучения могут выявлять закономерности и взаимосвязи в данных для построения прогнозов и классификаций.
Большие вычислительные мощности
Многослойная и сложная структура нейронной сети, большое количество параметров, необходимость обработки больших данных, итеративный метод обучения (на этапе обучения модель должна многократно итерироваться, а прямое распространение и обратное распространение каждого слоя должны быть рассчитаны в процессе обучения, включая расчет функции активации, расчет функции потерь, расчет градиента и обновление веса), требования к высокоточным вычислениям, возможности параллельных вычислений, методы оптимизации и регуляризации, а также процесс оценки и проверки модели - все это привело к спросу на высокую вычислительную мощность. С развитием глубокого обучения требования AGI к крупномасштабной вычислительной мощности увеличиваются примерно в 10 раз каждый год. На данный момент последняя модель GPT-4 содержит 1,8 триллиона параметров, стоимость одного сеанса обучения превышает 60 миллионов долларов США, а требуемая вычислительная мощность составляет 2,15e25 FLOPS (215 триллионов вычислений с плавающей точкой). Спрос на вычислительную мощность для последующего обучения моделей продолжает расти, а количество новых моделей также увеличивается.
ИИ-вычисления в экономике
Будущий размер рынка
Согласно самому авторитетному расчету, Отчету об оценке индекса глобальной вычислительной мощности за 2022–2023 годы, совместно составленному IDC (International Data Corporation), Inspur Information и Глобальным институтом промышленных исследований Университета Цинхуа, объем мирового рынка вычислений на основе ИИ вырастет с 19,50 млрд долларов США в 2022 году до 34,66 млрд долларов США в 2026 году, из которых объем рынка генеративных вычислений на основе ИИ вырастет с 820 млн долларов США в 2022 году до 10,99 млрд долларов США в 2026 году. Доля генеративных вычислений на основе ИИ в общем рынке вычислений на основе ИИ увеличится с 4,2% до 31,7%.
Экономическая монополия на вычислительные мощности
Производство графических процессоров для ИИ монополизировано компанией NVIDA, что крайне дорого (последний H100 был продан по цене 40 000 долларов за чип). Гиганты Кремниевой долины раскупили все графические процессоры сразу после их выпуска. Некоторые из этих устройств используются для обучения их собственных новых моделей. Другие сдаются в аренду разработчикам ИИ через облачные платформы. Например, платформы облачных вычислений Google, Amazon и Microsoft располагают большим количеством вычислительных ресурсов, таких как серверы, графические процессоры и тензорные процессоры (TPU). Вычислительная мощность стала новым ресурсом, монополизированным гигантами. Многие разработчики, работающие с ИИ, не могут даже купить выделенный графический процессор без дополнительной платы. Чтобы использовать новейшее оборудование, разработчикам приходится арендовать облачные серверы AWS или Microsoft. Согласно финансовому отчету, этот бизнес имеет чрезвычайно высокую прибыль. Валовая рентабельность облачного сервиса AWS составляет 61%, в то время как у Microsoft она еще выше — 72%.

Так должны ли мы принять эту централизованную власть и контроль и платить 72% прибыли за вычислительные ресурсы? Сохранят ли гиганты, монополизировавшие Web2, монополию и в следующем веке?
Проблема децентрализации вычислительной мощности AGI
Когда речь заходит о антимонопольном праве, децентрализация обычно является наилучшим решением. Можем ли мы, исходя из существующих проектов, достичь масштабной вычислительной мощности, необходимой для ИИ, с помощью проектов хранения данных в DePIN и протокола использования простаивающих графических процессоров, такого как RDNR? Ответ — нет. Путь к победе над драконом не так прост. Ранние проекты не были специально разработаны для вычислительной мощности ИИ и были нереализуемы. Вычислительная мощность в блокчейне должна была решать как минимум следующие пять задач:
1. Проверка работы: Чтобы построить действительно не требующую доверия вычислительную сеть и обеспечить экономические стимулы для участников, сеть должна иметь способ проверки того, что работа по глубокому обучению вычислений действительно выполняется. Суть этой проблемы заключается в зависимости от состояния моделей глубокого обучения; в моделях глубокого обучения вход каждого слоя зависит от выхода предыдущего слоя. Это означает, что вы не можете проверить только один слой в модели, не рассматривая все слои до него. Вычисления каждого слоя основаны на результатах всех слоев до него. Поэтому, чтобы проверить работу, выполненную в определенной точке (например, определенный слой), должна быть выполнена вся работа от начала модели до этой конкретной точки;
2. Рынок: Будучи развивающимся рынком, рынок вычислительной мощности ИИ подвержен дилеммам спроса и предложения, таким как проблема холодного старта. Ликвидность спроса и предложения должна быть примерно согласована с самого начала, чтобы рынок мог успешно расти. Чтобы охватить потенциальное предложение вычислительной мощности, участникам должно быть предоставлено четкое вознаграждение в обмен на их вычислительные ресурсы. Рынку необходим механизм для отслеживания выполненной вычислительной работы и своевременной выплаты соответствующих комиссий поставщикам. На традиционных рынках посредники отвечают за выполнение таких задач, как управление и адаптация, одновременно снижая операционные расходы за счет установления минимальных сумм платежей. Однако этот подход является дорогостоящим при расширении размера рынка. Только небольшая часть предложения может быть эффективно охвачена экономически, что приводит к пороговому состоянию равновесия, при котором рынок может только захватывать и поддерживать ограниченное предложение и не может расти дальше;
3. Проблема остановки: проблема остановки — фундаментальная проблема теории вычислений, которая заключается в определении того, будет ли данная вычислительная задача завершена за конечное время или никогда не остановится. Эта проблема неразрешима, а это означает, что не существует универсального алгоритма, способного предсказать, остановятся ли все вычислительные задачи за конечное время. Например, выполнение смарт-контрактов на Ethereum также сталкивается с аналогичной проблемой остановки. То есть невозможно заранее определить, сколько вычислительных ресурсов потребуется для выполнения смарт-контракта, или будет ли он завершен за разумное время;
(В контексте глубокого обучения эта проблема еще больше усложнится, поскольку модели и фреймворки перейдут от статического построения графов к динамическому построению и выполнению.)
4. Конфиденциальность: Проектирование и разработка, ориентированные на конфиденциальность, являются обязательным условием для проекта. Хотя большой объём исследований в области машинного обучения может быть проведён на общедоступных наборах данных, для повышения производительности модели и её адаптации к конкретным приложениям обычно требуется её тонкая настройка на закрытых данных пользователей. Этот процесс тонкой настройки может включать обработку персональных данных, поэтому необходимо учитывать требования к защите конфиденциальности.
5. Распараллеливание: Это ключевой фактор, делающий текущий проект нереализуемым. Модели глубокого обучения обычно обучаются параллельно на больших аппаратных кластерах с собственной архитектурой и чрезвычайно низкой задержкой. Графические процессоры в распределённых вычислительных сетях должны часто обмениваться данными, что приводит к задержкам и ограничивает возможности графического процессора с самой низкой производительностью. В условиях ненадёжности и нестабильности источника вычислительной мощности задача достижения гетерогенного распараллеливания остаётся актуальной. В настоящее время распараллеливание реализуется с помощью модели Transformer, например, Switch Transformers, которая теперь обладает высокой степенью распараллеливаемости.
Решение: Хотя попытки децентрализации рынка вычислительных мощностей для AGI всё ещё находятся на ранней стадии, существует два проекта, которые изначально решили проблему консенсусного проектирования децентрализованных сетей и внедрения сетей децентрализованных вычислительных мощностей для обучения моделей и рассуждений. В данной статье на примере Gensyn и Together будут проанализированы методы проектирования и проблемы рынка децентрализованных вычислительных мощностей для AGI.
Воссоединение

Gensyn — это рынок вычислительных мощностей для искусственного интеллекта (ИИ), который всё ещё находится в стадии формирования. Он нацелен на решение различных задач децентрализованных вычислений с глубоким обучением и снижение текущей стоимости глубокого обучения. Gensyn, по сути, представляет собой протокол первого уровня с доказательством доли владения (PosS), основанный на сети Polkadot, который напрямую вознаграждает решателей посредством смарт-контрактов в обмен на их неиспользуемые графические процессоры для вычислений и выполнения задач машинного обучения.
Итак, возвращаясь к вопросу выше, суть построения по-настоящему бездоверительной вычислительной сети заключается в верификации выполненной работы машинного обучения. Это чрезвычайно сложная задача, требующая поиска баланса между теорией сложности, теорией игр, криптографией и оптимизацией.
Gensyn предлагает простое решение, при котором решатели отправляют результаты выполненных ими задач машинного обучения. Для проверки точности этих результатов другой независимый проверяющий пытается повторно выполнить ту же работу. Этот метод можно назвать одинарной репликацией, поскольку повторное выполнение будет выполнять только один проверяющий. Это означает, что для проверки точности исходной работы требуется только одна дополнительная работа. Однако, если проверяющий работу не является заказчиком исходной работы, то проблема доверия сохраняется. Поскольку сами проверяющие могут быть недобросовестными, и их работа должна быть проверена. Это приводит к потенциальной проблеме: если проверяющий работу не является заказчиком исходной работы, для проверки их работы требуется другой проверяющий. Но этот новый проверяющий также может быть ненадёжным, поэтому для проверки их работы требуется другой проверяющий, что может продолжаться бесконечно, образуя бесконечную цепочку репликаций. Здесь необходимо ввести и переплести три ключевых понятия, чтобы построить систему с четырьмя участниками для решения проблемы бесконечной цепочки.
Доказательства вероятностного обучения: используйте метаданные о процессе градиентной оптимизации для создания сертификатов выполненной работы. Эти сертификаты можно быстро проверить, воспроизведя определенные этапы, что гарантирует, что работа была выполнена в соответствии с ожиданиями.
Протокол точного позиционирования на основе графа: использует многогранный протокол точного позиционирования на основе графа и обеспечивает согласованность данных с помощью перекрестной оценки. Это позволяет повторно выполнять проверку и сравнивать результаты для обеспечения согласованности, а в конечном итоге подтверждать её самим блокчейном.
Поощрительная игра в стиле Truebit: использование ставок и сокращений для создания поощрительной игры гарантирует, что каждый экономически разумный участник будет действовать честно и выполнять свои ожидаемые задачи.
Система участников состоит из подающих заявления, решающих лиц, проверяющих и осведомителей.
Авторы:
Заявители — конечные пользователи системы, которые предоставляют задания для вычисления и оплачивают выполненные единицы работы;
Решатели:
Решатели — основные работники системы, выполняющие обучение моделей и генерирующие доказательства, проверяемые верификаторами;
Проверяющие:
Верификатор является ключом к соединению недетерминированного процесса обучения с детерминированным линейным вычислением, копируя часть доказательства решателя и сравнивая расстояние с ожидаемым порогом;
Информаторы:
Информаторы — это последняя линия обороны, они проверяют работу валидаторов и подают иски в надежде получить щедрое вознаграждение.
Работа системы
Работа игровой системы, разработанной по данному протоколу, будет включать восемь этапов, охватывающих четыре основные роли участников, для завершения всего процесса от отправки задания до окончательной проверки.
Представление задачи: Задача состоит из трех конкретных фрагментов информации:
Метаданные, описывающие задачу и гиперпараметры;
Двоичный файл модели (или базовая архитектура);
Общедоступные, предварительно обработанные данные обучения.
Чтобы отправить задачу, отправитель указывает её детали в машиночитаемом формате и отправляет их в цепочку вместе с двоичным файлом модели (или машиночитаемой схемой) и общедоступным расположением предобработанных обучающих данных. Публичные данные могут храниться в простом объектном хранилище, таком как S3 от AWS, или в децентрализованном хранилище, таком как IPFS, Arweave или Subspace.
Профилирование: Процесс профилирования устанавливает базовый порог расстояния для проверки доказательств обучения. Верификатор периодически сканирует задачи профилирования и генерирует пороговые значения мутаций для сравнения доказательств обучения. Для определения порогового значения верификатор детерминированно запускает и повторно запускает часть обучения, используя различные случайные начальные значения, генерируя и проверяя собственные доказательства. В процессе верификатор устанавливает общий ожидаемый порог расстояния для недетерминированной работы, который может быть использован в качестве решения для верификации.
Обучение: После анализа задача попадает в публичный пул задач (аналогичный мемпулу Ethereum). Для её выполнения выбирается решатель, который затем удаляется из пула задач. Решатели выполняют задачи на основе метаданных, предоставленных отправителем, а также предоставленной модели и данных для обучения. При выполнении учебных задач решатель также генерирует доказательство обучения, периодически создавая контрольные точки и сохраняя метаданные (включая параметры) в процессе обучения, чтобы верификатор мог максимально точно воспроизвести последующие этапы оптимизации.
Генерация доказательств: решатели периодически сохраняют веса или обновления модели и соответствующие индексы в обучающем наборе данных для идентификации образцов, используемых для генерации обновлений весов. Частота контрольных точек может быть скорректирована для обеспечения более высоких гарантий или экономии места на диске. Доказательства могут быть «сложены», то есть доказательство может начинаться со случайного распределения, используемого для инициализации весов, или с предварительно обученных весов, сгенерированных с помощью собственного доказательства. Это позволяет протоколу создавать набор проверенных, предварительно обученных базовых моделей (т.е. базовых моделей), которые можно настраивать для более конкретных задач.
Проверка доказательства: После завершения задачи решатель регистрирует её выполнение в цепочке и отображает своё доказательство обучения в общедоступном месте, к которому проверяющий может получить доступ. Верификатор извлекает задачу проверки из общедоступного пула задач и выполняет вычислительные операции для повторного выполнения части доказательства и вычисления расстояния. Затем цепочка использует полученное расстояние (вместе с пороговым значением, вычисленным на этапе анализа), чтобы определить, соответствует ли проверка доказательству.
Точечный вызов на основе графа: после проверки доказательства обучения информатор может повторить работу валидатора, чтобы проверить, была ли сама проверка выполнена правильно. Если информатор считает, что проверка была выполнена неправильно (злонамеренно или незлонамеренно), он может оспорить арбитраж контракта за вознаграждение. Это вознаграждение может поступать из депозитов решателя и валидатора (в случае истинного положительного результата) или из лотерейного пула (в случае ложного положительного результата), и использовать саму цепочку для проведения арбитража. Информаторы (в их случае, валидаторы) будут проверять и впоследствии оспаривать работу только в том случае, если рассчитывают на получение соответствующей компенсации. На практике это означает, что ожидается, что информаторы будут присоединяться к сети и покидать ее в зависимости от количества других активных информаторов (т. е. с активными депозитами и вызовами). Таким образом, ожидаемая стратегия по умолчанию для любого информатора — присоединиться к сети, когда число других информаторов невелико, внести депозит, случайным образом выбрать активную задачу и начать процесс верификации. После завершения первой задачи информатор выбирает следующую случайную активную задачу и повторяет процесс, пока число информаторов не превысит установленный порог выплат. После этого информатор покидает сеть (или, что более вероятно, переключается на другую роль в сети — валидатора или решателя — в зависимости от возможностей своего оборудования), пока ситуация не изменится.
Арбитраж по контракту: когда валидатору задаётся вопрос осведомителем, он вступает в процесс с цепочкой, чтобы выяснить место проведения оспариваемой операции или ввода, и цепочка в конечном итоге выполняет последнюю базовую операцию и определяет, обоснован ли вопрос. Чтобы сохранить честность и авторитетность осведомителя и решить дилемму валидатора, здесь вводятся регулярные вынужденные ошибки и выплаты джекпота.
Расчёт: В процессе расчёта участники получают вознаграждение в соответствии с результатами вероятностных и детерминированных проверок. В разных сценариях выплаты различаются в зависимости от результатов предыдущих проверок и испытаний. Если работа считается выполненной правильно и все проверки пройдены, решатель и валидатор получают вознаграждение в соответствии с выполненными действиями.
Обзор проекта
Gensyn разработала замечательную игровую систему на уровнях верификации и стимулирования. Находя точки расхождения в сети, она может быстро выявлять ошибки, но существующей системе всё ещё не хватает деталей. Например, как задать параметры, чтобы гарантировать разумность вознаграждений и наказаний, не устанавливая слишком высокие пороговые значения? Учитывали ли игровые связи проблему экстремальных случаев и разной вычислительной мощности решателей? В текущей версии технического документа нет подробного описания гетерогенной параллельной работы. В настоящее время, похоже, Gensyn предстоит пройти ещё долгий путь до её реализации.
Together.ai
Together — компания, специализирующаяся на разработке больших моделей с открытым исходным кодом и стремящаяся к разработке децентрализованных вычислительных решений на основе искусственного интеллекта. Компания надеется, что доступ к ИИ и его использование будет доступен любому человеку и в любом месте. Строго говоря, Together не является блокчейн-проектом, но изначально проект решил проблему задержек в децентрализованной вычислительной сети с искусственным интеллектом. Поэтому в данной статье мы только анализируем решение Together и не комментируем сам проект.
Как обеспечить обучение и вывод больших моделей, если децентрализованные сети в 100 раз медленнее центров обработки данных?
Давайте представим, как устройства GPU, участвующие в сети, будут распределены в децентрализованной среде. Эти устройства будут разбросаны по разным континентам и городам. Устройства необходимо соединить, а задержка и пропускная способность соединения различаются. Как показано на рисунке ниже, моделируется распределенная ситуация, в которой устройства распределены по Северной Америке, Европе и Азии, а пропускная способность и задержка между устройствами различаются. Что же нужно сделать, чтобы соединить их последовательно?
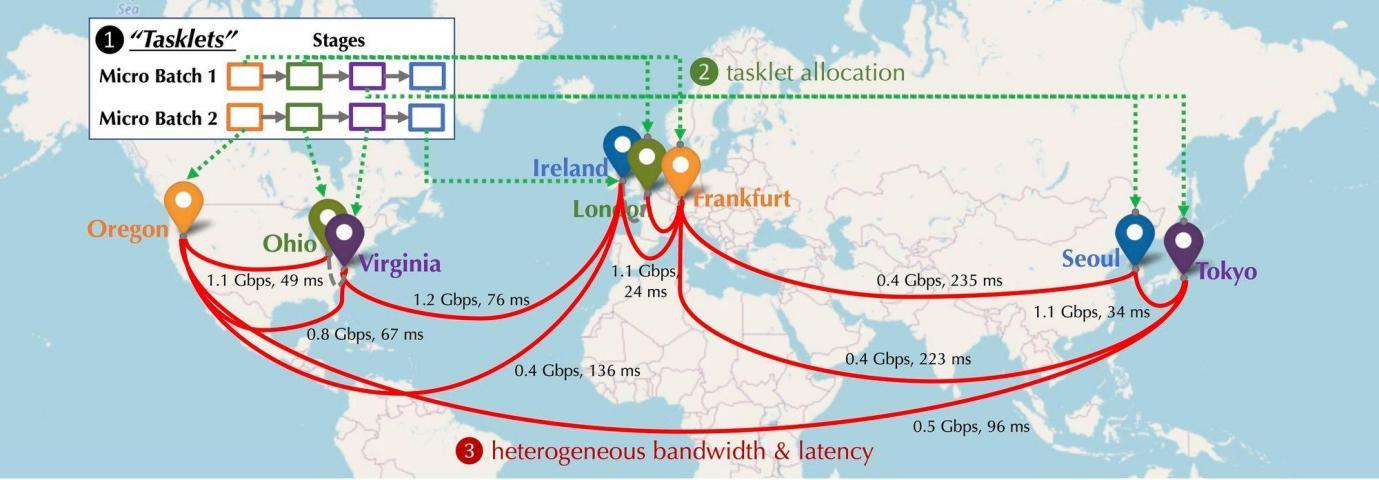
Распределённое обучение вычислительного моделирования: На следующем рисунке показано обучение базовой модели на нескольких устройствах. С точки зрения типа коммуникации существует три типа коммуникации: прямая активация, обратный градиент и латеральная коммуникация.
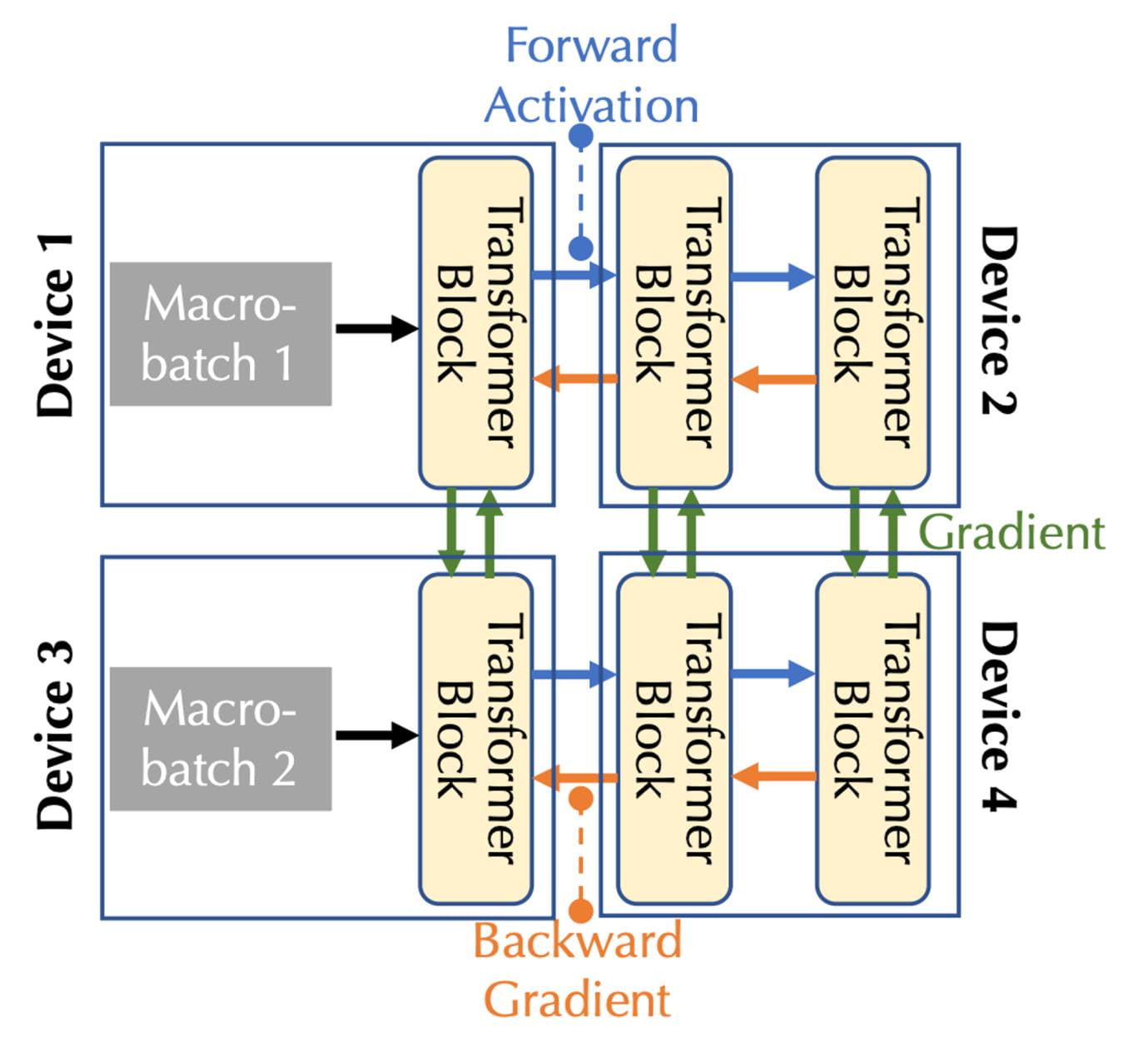
Объединяя пропускную способность связи и задержку, следует рассмотреть две формы параллелизма: конвейерный параллелизм и параллелизм данных, соответствующие трем типам связи в случае нескольких устройств:
При конвейерном параллелизме все слои модели делятся на несколько этапов, где каждое устройство обрабатывает один этап, который представляет собой непрерывную последовательность слоев, например, несколько блоков Transformer; при прямом проходе активации передаются на следующий этап, а при обратном проходе градиенты активаций передаются на предыдущий этап.
При параллелизме данных устройства независимо вычисляют градиенты для разных микропакетов, но им необходимо взаимодействовать для синхронизации этих градиентов.
Оптимизация планирования:
В децентрализованной среде процесс обучения часто ограничен коммуникационными затратами. Алгоритмы планирования обычно назначают задачи, требующие большого объёма обмена данными, устройствам с более быстрым подключением. Учитывая зависимости между задачами и гетерогенность сети, необходимо сначала смоделировать стоимость конкретной стратегии планирования. Чтобы учесть сложные коммуникационные затраты на обучение базовой модели, Together предложили новую формулу и разложили модель стоимости на два уровня с помощью теории графов:
Теория графов — раздел математики, изучающий свойства и структуру графов (сетей). Графы состоят из вершин (узлов) и рёбер (линий, соединяющих узлы). Основная цель теории графов — изучение различных свойств графов, таких как связность графов, цвета графов, а также свойства путей и циклов в графах.
Первый уровень — это задача сбалансированного разбиения графа, которая соответствует коммуникационным затратам параллелизма данных.
Второй слой — это задача о совместном сопоставлении графов и задача о коммивояжере (задача о совместном сопоставлении графов и задача о коммивояжере — это задача комбинаторной оптимизации, которая сочетает в себе элементы задач о сопоставлении графов и коммивояжера. Задача о сопоставлении графов заключается в поиске в графе такого сопоставления, которое минимизирует или максимизирует определенную стоимость. Задача о коммивояжере заключается в поиске кратчайшего пути для посещения всех узлов в графе), что соответствует коммуникационной стоимости параллельного конвейера.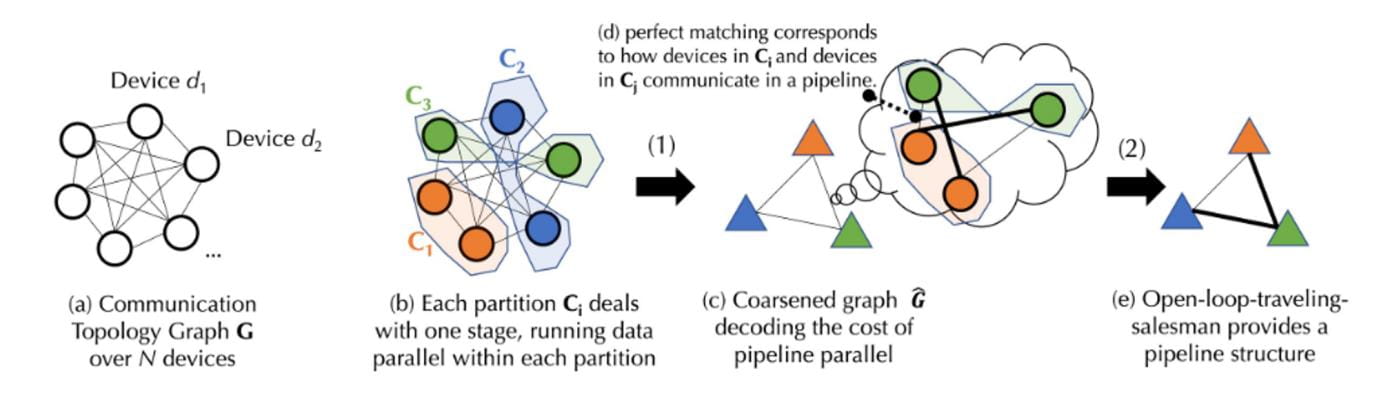
На рисунке выше представлена схема процесса. Поскольку сам процесс внедрения включает в себя сложные расчётные формулы, для простоты понимания ниже представлен более доступный способ его объяснения. Подробную информацию о процессе внедрения можно найти в документах на официальном сайте Together.
Предположим, что имеется набор устройств D, содержащий N устройств, и связь между ними имеет неопределённую задержку (матрица A) и пропускную способность (матрица B). На основе набора устройств D сначала генерируется сбалансированный граф. Количество устройств в каждом разделе или группе устройств примерно одинаково, и все они обрабатывают один и тот же этап конвейера. Это гарантирует, что каждая группа устройств выполняет одинаковый объём работы при параллельной передаче данных. (Параллелизм данных означает, что несколько устройств выполняют одну и ту же задачу, в то время как этапы конвейера означают, что устройства выполняют разные этапы задачи в определённом порядке). Исходя из задержки и пропускной способности связи, «стоимость» передачи данных между группами устройств можно рассчитать по формуле. Каждая сбалансированная группа устройств объединяется для создания полносвязного грубого графа, где каждый узел представляет этап конвейера, а ребро — стоимость связи между двумя этапами. Для минимизации стоимости связи используется алгоритм сопоставления для определения того, какие группы устройств должны работать вместе.
Для дальнейшей оптимизации эту задачу можно смоделировать как задачу коммивояжёра без обратной связи (без обратной связи, что означает отсутствие необходимости возвращаться в начальную точку маршрута) для поиска оптимального пути передачи данных между всеми устройствами. Наконец, Together использует инновационный алгоритм планирования для поиска наилучшей стратегии распределения для заданной модели стоимости, тем самым минимизируя затраты на связь и максимизируя производительность обучения. Согласно реальным измерениям, даже если сеть работает в 100 раз медленнее при такой оптимизации планирования, производительность обучения от начала до конца снижается всего примерно в 1,7–2,3 раза.
Оптимизация сжатия связи:
Для оптимизации сжатия данных компания Together представила алгоритм AQ-SGD (подробный процесс расчёта см. в статье «Точная настройка языковых моделей в медленных сетях с использованием гарантированного сжатия активации»). Алгоритм AQ-SGD — это новая технология сжатия активности, разработанная для решения проблемы эффективности передачи данных при параллельном обучении конвейера в низкоскоростных сетях. В отличие от предыдущих методов, которые напрямую сжимали значения активности, AQ-SGD фокусируется на сжатии изменений значений активности одной и той же обучающей выборки в разные моменты времени. Этот уникальный метод представляет интересную «самоисполняющуюся» динамику. Ожидается, что по мере стабилизации обучения производительность алгоритма будет постепенно улучшаться. Алгоритм AQ-SGD был тщательно проанализирован теоретически и продемонстрировал хорошую скорость сходимости при определённых технических условиях и ограниченных функциях квантования ошибок. Алгоритм не только эффективно реализуется, но и не увеличивает сквозные накладные расходы, хотя и требует больше памяти и SSD для хранения значений активности. Благодаря обширной экспериментальной проверке на наборах данных классификации последовательностей и моделирования языка, AQ-SGD позволяет сжимать значения активности до 2–4 бит без ущерба для производительности сходимости. Кроме того, AQ-SGD может быть интегрирован с самым современным алгоритмом градиентного сжатия для достижения «сквозного сжатия данных», то есть все данные, передаваемые между машинами, включая градиенты моделей, значения активности в прямом направлении и в обратном направлении, сжимаются до низкой точности, что значительно повышает эффективность передачи данных при распределенном обучении. По сравнению со сквозным обучением без сжатия в централизованной вычислительной сети (например, 10 Гбит/с), в настоящее время оно всего на 31% медленнее. В сочетании с данными оптимизации планирования, хотя некоторое отставание от централизованной вычислительной сети все еще сохраняется, есть большая надежда на преодоление отставания в будущем.
Заключение
В период дивидендов, вызванных волной развития искусственного интеллекта, рынок вычислительных мощностей AGI, несомненно, обладает наибольшим потенциалом и самым высоким спросом среди многих рынков вычислительных мощностей. Однако сложность разработки, требования к оборудованию и капиталу также являются самыми высокими. Учитывая два вышеупомянутых проекта, у нас ещё есть время до реализации рынка вычислительных мощностей AGI. Реальная децентрализованная сеть также гораздо сложнее идеальной. Очевидно, что её недостаточно, чтобы конкурировать с гигантами облачных технологий в настоящее время.
При написании этой статьи я также заметил, что некоторые небольшие проекты, находящиеся на начальной стадии (стадия PPT), начали исследовать новые точки входа, например, сосредоточившись на менее сложной стадии рассуждений или обучении небольших моделей. Всё это хорошие попытки. В долгосрочной перспективе децентрализация и отсутствие ограничений важны. Право доступа к вычислительным мощностям ИИ и их обучения не должно быть сосредоточено в руках нескольких централизованных гигантов. Людям не нужна новая «религия» или новый «папа», и они не должны платить высокие членские взносы.